
基于AI与传统风险度量模型下房地产企业信用风险度量分析
2021-11-28 14:57王晓菲刘继端詹梓雯刘彦清张燕玲周燕
商讯·公司金融 2021年21期
王晓菲 刘继端 詹梓雯 刘彦清 张燕玲 周燕
作者简介:王晓菲(1993— ),女,汉族,广东广州人。主要研究方向:企業信用管理。
摘 要:由于房地产企业是属于高负债企业,对财务金融杠杆的依赖性极高,具有长周期性等高风险特征。再加上如今国家宏观调控紧、地方微观调控严,房地产企业步入了资金收紧、盈利减少的阶段,面临难融资、融资少的问题,导致房地产企业风险进一步放大,阻碍了房地产企业的发展。所以,房地产企业要想持续发展,就要加强风险管控和防范。本文通过专业的信用管理知识将机器学习AI模型与传统信用风险度量模型结合来度量房地产企业的信用违约风险。因为机器学习AI模型能够补充传统信用风险度量模型在财务数据方面外的空白,而传统信用风险度量模型能够通过其在金融领域的研究经验为机器学习提供研究方向,所有将两者进行结合能通过多角度对房地产企业的信用违约风险进行更加精准的度量。
关键词:机器学习;房地产;风险度量;模型融合
中国的房地产行业经历几十年的发展,已经成为国民经济和金融体系中不可或缺的一部分。房地产企业在这个过程中也在不断调整和改变,但房地产企业高负债和长周期的经营模式一直是房地产企业的一个特点。高负债和长周期的经营模式不但带来了高杠杆、高回报,也带来了高风险。而企业风险度量一直是当前不断探索和解决的问题,尤其是房地产企业。但当前企业使用的风险度量模型还是基于传统的一些风险度量模型,比如KMV、Z模型、CreditVaR系列模型等,而传统风险度量模型由于年限较长,再加上大部分来自于国外学者研究,对当今复杂多变的市场度量信用风险时,难免会有较大的偏差。本文将大数据技术和机器学习AI技术与传统的风险度量模型结合,从而打破仅仅通过财务数据的单一角度来度量风险的传统思维,使用更新、更多角度、更与时俱进的方法和思维来设计和打造出适用于当下市场环境的风险度量模型。
一、信用违约风险建模
本文采用的算法模型有遗传算法、KMV模型、LGB模型、SnowNLP模型、LR回归模型,其中遗传算法模型负责解出最优解;KMV模型作为传统风险度量模型负责解出企业违约概率和违约距离;LGB模型和LR回归模型负责拟合样本数据,对样本进行预测分类;SnowNLP模型负责对文本数据进行情感分析。根据以上四个模型,进行风险度量建模。
(一)遗传算法KMV模型
首先,采用遗传算法对全国所有行业的上市公司训练出适合我国国情的KMV模型,即训练出适合我国国情的长期负债系数和短期负债系数。
在适合中国国情的KMV模型中,其短期负债系数和长期负债系数分别为0.948和0.264。根据遗传算法训练出来的KMV模型简称为“QG_KMV”模型,本文通过QG_KMV模型去度量全国109个行业的信用违约风险。
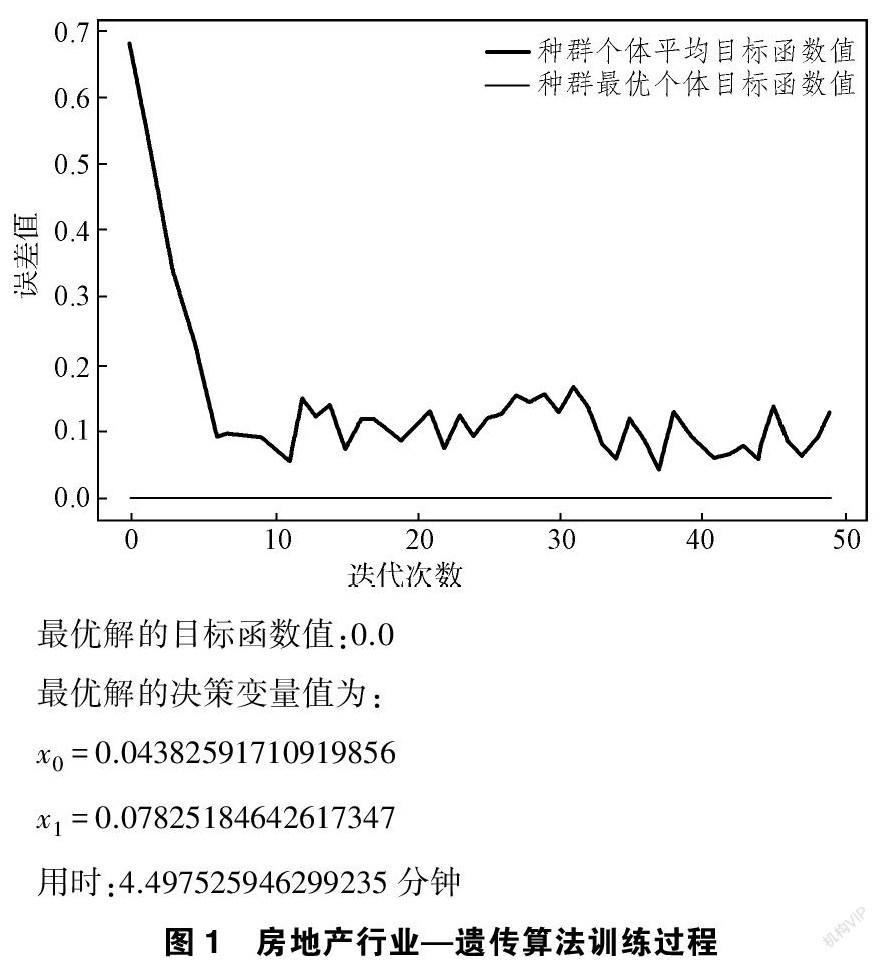
由于房地产行业高负债的特点,导致应用QG_KMV模型度量房地产行业风险时,房地产的违约风险偏高,所以本文将放弃使用全国所有行业的上市公司去训练KMV模型,而改用全国所有房地产行业的上市公司去训练KMV模型,如图1所示:
从图 1中可知,利用全国所有房地产行业的上市公司训练KMV模型训练出的短期负债系数和长期负债系数分别为0.0438和0.0783,本文将该模型简称为“FDC_KMV”模型。
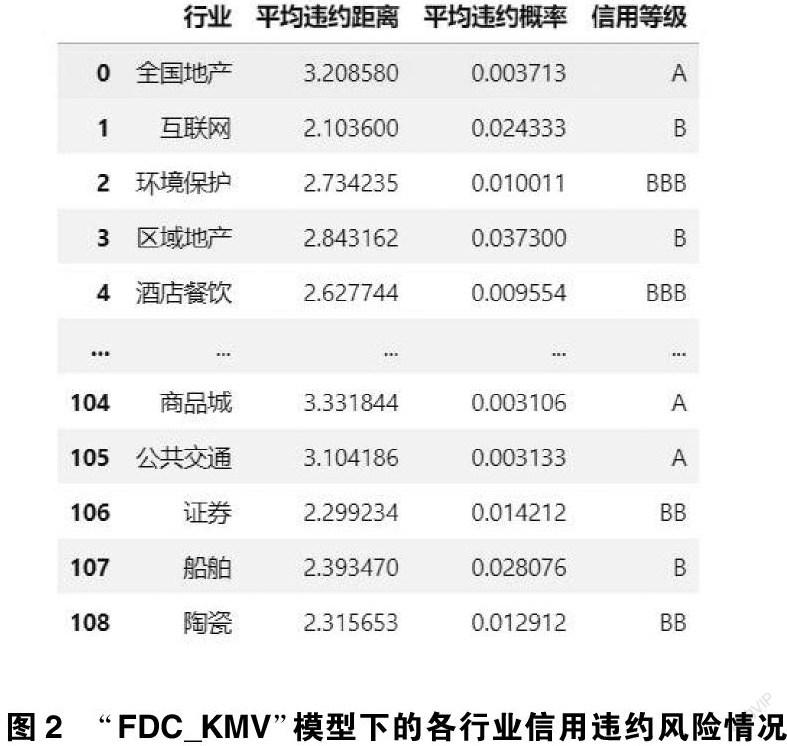
通过“FDC_KMV”模型计算出各行业违约概率如下:
由图 2中可知,相较之前的KMV模型,“FDC_KMV”模型在房地产企业的平均违约距离和概率大幅下降,信用等级从D上升到A,更加适用于房地产企业,且全国地产的信用等级明显优于区域地产。
(二)LGB_KMV模型
同时通过将机器学习LIGHTGBM模型与KMV模型结合,采取全国3541家上市公司(其中3355家非ST公司和186家ST公司)作为训练数据。其中ST公司是指连续两年亏损或者净资产低于股票面值的公司,非ST则相反。但由于两类公司数量不一致,导致数据不平衡,经过SMOTE算法进行上采样之后,共计6710条数据样本,其中包含ST公司和非ST公司样本各3355条。
围绕着这6710条数据样本进行建模,将数据集以8:2的比例切分为训练集和测试集,采用的数据特征有流动负债、非流动负债、总市值、收益率波动率、总负债,以及通过KMV模型计算得出的违约距离及违约概率。同时将样本数据特征分为两组,一组是加入KMV模型计算出来的违约概率和违约距离特征,称为LGB模型;另一组是没有加入KMV模型计算出来的违约概率和违约距离特征,称为LGB_KMV模型。通过对两组数据进行建模分析。LGB_KMV模型在测试数据集中的表现优于LGB模型,其中LGB_KMV模型预测的准确度达88%,而LBG模型的准确度为83.9%,所以融合了KMV模型之后的LGB_KMV模型比没有融合KMV模型的LGB模型准确度提高了4.1%。
(三)SNOWNLP模型
通过python的SNOWNLP自然语言情感分析库对房地产上市公司公告进行情感分析,对每一年中发布的每一条上市公司公告进行打分,分值为[0-1],其中得分越接近1,说明该公告携带的信息表现为越积极,反之,得分越接近0,说明该公告携带的信息表现为越消极,将公告得分大于0.5分判断为积极公告,小于0.5分判断为消极公告,等于0.5分的判断为中立公告。
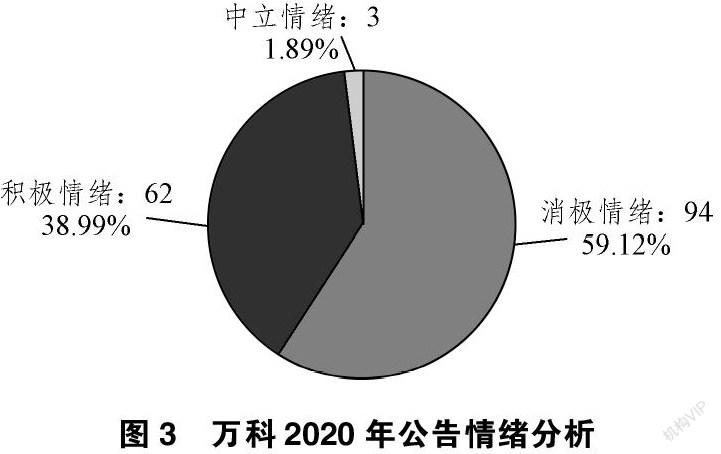
以万科2020年公告做一个情感判断为例,结果如图 3所示:
如图 3所示,SNOWNLP模型能够对每条公告信息进行一个情感分析并且进行情感评分。
(四)LGB_LR模型
股市是一个消息市,股票市场中股民会参考公司披露的公告信息来投资股票,所以上市公司的公司公告发布会对股价造成一定程度的影响,股价的变动会影响公司的市值。正如KMV模型中通过公司的市值,从而计算出公司的价值来度量风险,那么公司的股票价格的变动就会与公司的风险相关联。
将公告的文本信息进行数据处理,再采用词嵌入的方法,即应用TF_IDF方案。TF是指单词词频,即一个词在文章中出现的频率,从客观的角度出发一些词出现的频率越高,说明这个词的重要性可能是比较高的。IDF是指逆文本频率,即该词越少越能代表该篇文章,因为一篇文章中可能有大多的介词或者代词,这些词都没有特别大的意义,例如‘的、‘将、‘通过、‘你、‘我、‘他等等词语。将处理后的公告信息通过LGB_LR模型进行预测出下一天股价的变化趋势。
二、风险量化
综上,本文将通过定量的方法,对房地产行业中的10家房地产企业风险进行量化处理,其中包括5家ST公司,5家非ST公司。将引入一个信用风险值,这个值涵盖各个模型所得结果及影响因素。通过信用风险值来衡量房地产公司的风险大小,信用风险值与信用风险成正比关系。
信用风险值的计算公式如下:
其中和分别为KMV模型输出的违约概率和违约距离,为LGB_KMV模型的准度,为LGB_KMV模型预测值,为LGB_LR模型的准度,为LGB_LR模型预测值,为SNOWNLP模型输出的情绪值,常数项1.7147是违约距离的临界值。
Sigmoid函数计算公式如下:
Sigmoid函数能够将连续变量映射到(0,1)范围内,0.5为企业违约的阈值,风险值达到0.5表明企业可能发生违约事件,风险值越接近1表明发生违约事件的可能性越高。本文中的风险等级分为低风险、中低风险、中高风险、高风险四个等级,对应的信用风险值为(0,0.25]、[0.25,0.5]、[0.5,0.75],[0.75,1)。
通过4个模型的输出结果,进行计算10家房地产企业的信用风险值的大小,如表 1所示:
如表1所示,通过对比ST和非ST两类企业信用风险值可知,本文的模型能够更加具体的度量出两类企业的信用风险值,并且ST企业的信用风险值明显高于非ST企业。
通过两类企业的对比,验证了本文模型在房地产企业的信用风险度量上的效果,证实了本文模型的可信度。
三、结语
本文主要研究房地产公司信用风险的度量,主要研究结果和结论如下所示:
(1)从度量结果可知,ST房地产企业的信用风险值属于中高、高风险区域,违约可能性大,相比之下非ST房地产企业的信用风险值属于中低、低风险区域,履约能力较强。
(2)加入传统风险度量模型能够提高机器学习预测的准确率,在本文中准确率提高了4.1%。
(3)传统的KMV模型不适用于房地产行业。
(4)“全国地产”行业信用水平高于“区域地产”行业。
参考文献:
[1]冯雅情.基于改进的KMV-LBGoost的信用债风险度量[D].2020.
[2]王慧,张国君.KMV模型在我国上市房地产企业信用风险度量中的应用[J].经济问题,2018(03):36-40.
[3]袁琦富.基于Logistic模房地产上市公司违约风险度量研究[D].天津财经大学,2018.
[4]潘义.我国上市公司信用风险度量研究[D].安徽工业大学,2010.
[5]余佳坤.制造业上市公司信用违约风险度量[D].山东大学,2020.
[6]周志华.机器学习[M].北京:清华大学出版社,2016:12-16.
[7]邱偉栋.基于LightGBM模型的P2P网贷违约预测研究[D].江西财经大学,2020:6.
[8]罗欣.中国房地产市场融资现状分析[J].现代商业,2011(33):48-49.
[9]高国华.严调控趋势下房企信用风险分析[J].债券,2017(07):61-66.
[10]刘君红.我国房地产行业信用风险评价研究[D].北京交通大学,2012.
[11]刘敏.基于判别分析法的房地产企业信用风险度量研究[J].财会通讯,2013(20):107-108.
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科技视界(2016年22期)2016-10-18
中国市场(2016年33期)2016-10-18
商(2016年27期)2016-10-17
商(2016年27期)2016-10-17
科学与财富(2016年28期)2016-10-14
人民论坛(2016年27期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
