
语音识别中的隐马尔可夫(HMM)模型和编码解码(encoder-decoder)模型
2021-12-02 07:24黄万武付煜琪熊素娟
科学与生活 2021年25期
关键词:语音识别
黄万武 付煜琪 熊素娟

摘要:本文分析了语音識别中的两个经典模型的算法原理——传统的隐马尔可夫模型(HMM)和基于神经网络的解码编码模型(encoder-decoder)模型。
关键词:语音识别;隐马尔可夫;解码编码
语音识别是将自然语言中的语音序列转换为文本序列的一个过程,它的基本思路是:给定一个声学输入序列O=o1,o2 ,o3 ,o4 ……,ot ,把该序列转化成一个由单词序列构成的句子S=w1,w2,w3,w4,w5,……wn 。该转换过程中,经典的技术应用包括传统的基于统计的隐马尔可夫模型和现代的基于神经网络模型。本文将对两种模型的基本原理进行分析。
1基于隐马尔可夫算法的语音识别原理
语音识别过程涉及到两个序列:一个可观察到的声学序列O和一个隐藏的状态序列Q:声学序列背后隐藏的文本序列。
基于隐马尔可夫算法的语音识别本质上是一种基于统计的算法,其基本思路是给定的一个语音序列O,计算出在所有的状态序列Q中,可能性最大的那一个。先求出每个可能的状态序列的概率P(Q|O),从中挑选概率最大的状态序列。
对于单个的序列的概率计算,用简单的马尔科夫链算法即可以轻松地算出该序列的概率。但是对于类似语音识别、词性标注这样存在一个可观察的序列和一个隐藏的序列的现象进行概率计算,要比单序列更复杂,更适合使用隐马尔可夫模型。
隐马尔可夫的基本参数包含5个方面:
(1)隐藏序列状态的集合Q=(q1,q2,q3,…… ,qn)。在语音识别里,就是语音相对应的词语的发音组合,包含某个语言里所有词汇的所有的发音组合,可以通过发音词典来查找。
(2)隐藏序列状态Q=(q1,q2,q3,……,qn)之间的转换概率集合,也叫转移矩阵A=(a01,a02,a03,…… an1,……,ann)。该矩阵是一个n*n的列和行均为隐藏序列状态的矩阵。
(3)观察似然度集合B=bi(ot),表示从状态i生成观察t的概率,也构成一个矩阵。
(4)初始状态分布,表示每个状态在开始时候的概率。
(5)合法的接收状态集合。
如图1就是单词need的HMM模型(Jurafsky,2009):
在该模型中,存在两个序列:观察序列(由声谱特征矢量构成)和单词状态模型(状态转移模式序列)。单词need发音组合有五个状态构成:初始状态start,n,iy,d,和接收状态end。每个状态之间的连线标记的是状态之间的转换概率。其中start和end为非发射状态,其它为发射状态。每个发射状态上都有一个自反圈,模拟状态的可变音延。例如o1和o2就是状态n的音延,o3,o4,o5就是状态iy的音延。在状态iy后还增加了可选的路径,模拟状态d弱化或者消失从而直接进入到end状态。该模型还记录了每个状态下每个观察发生的概率b(o)。
在隐马尔可夫模型中,根据贝叶斯规则,可能的状态序列的概率P(Q | O)= P(O | Q)*P(Q),计算出这些可能的状态的概率,对他们进行比较,找出最大的概率的那个序列,就是最后转换的目标。其中,P(Q)就是隐藏状态之间的转换概率,记录在HMM模型的矩阵A中,P(Q | O)就 是观察的似然度,记录在HMM模型的矩阵B中。
2编码解码模型(encoder-decoder)
随着基于人工神经网络的深度学习技术的兴起,利用深度学习技术进行语音识别逐渐成为主流的路径,其中的编码解码模型(encoder-decoder)表现尤其突出。
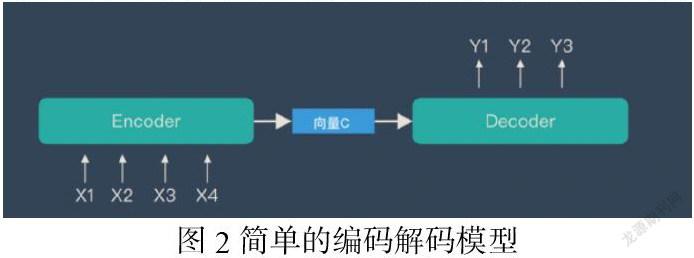
如图2所示,一个编码解码模型由一个编码器和一个解码器构成,向一个编码器encoder输入序列X1,X2,X3,X4……(在语音识别中就是输入带有声学特征的声谱片段向量),编码器对输入序列通过多层神经网络(RNN或者Transformer等)进行编码,生成一个向量表征C,这个向量表征C被传递到解码器,由解码器里边的神经网络进行解码,最后生成输出序列Y1,Y2,Y3……(在语音识别中就是生成单词序列或者字母序列)。
编码解码模型适合语音识别在于以下几点:(1)语音识别是把有着声学特征的声谱片段序列转化为单词序列。因为声谱片段大多是以10毫秒为单位的切片,大约每100个左右的声谱片段最后才能映射为一个单词,这样输入序列的长度和输出序列的长度差异很大,传统的隐马尔可夫模型要求输入序列和输出序列等长,但是编码解码模型并不要求输入输出序列等长,因此计算方便。(2)在隐马尔可夫模型中,需要分别计算转换概率和观察的似然度,计算量大,操作复杂,中间环节多。但是在编码解码模型中,这些中间环节的计算都不必要,只需要将输入输出数据对喂给编码解码器,对编码解码器进行训练,编码解码器能经过神经网络自动从数据对中提取特征进行学习,从而实现对输入的音频进行文本转换。
整个编码解码模型利用交叉熵损失函数在训练数据集上进行训练,对每一个迭代计算损失,利用反向传播优化整个网络,经过多次迭代训练以后模型达到最优状态。
3总结
利用隐马尔可夫模型进行语音识别,是统计算法时代的经典技术,复杂却有效。而基于深度学习技术的解码编码模型是深度学习技术的应用,简单、快捷而高效。两种方法背后都体现了数学算法在解决实际问题中的应用。
参考文献:
[1]Jurafsky D.,Speech and Language Processing —— An Introduction to Natural Language Processing,Computational Linguistics,and Speech Recognition,Prentice Hall,2009.
[2]Chan,W.,Jaitly,N.,Le,Q.,andVinyals,O. (2016). Listen,attend andspell: A neural network for large vocabulary conversational Speech Recognition. ICASSP.
作者简介:
黄万武,教授,湖北工业大学外国语学院,研究方向:计算语言学,自然语言处理
付煜琪,学生,湖北工业大学外国语学院英语专业学生
熊素娟,副教授,湖北工业大学外国语学院,研究方向,应用语言学
(*本文为湖北工业大学大学生创新创业项目“智能语音识别技术在大学英语口语考试自动评分中的应用”的成果之一,项目编号:S201910500090;本文为湖北省教育厅人文社科重点项目“英语作文自动评分系统中“算法+语言规则”相结合的理论与实践研究”项目成果之一,项目编号:18Y069)
猜你喜欢
科技创新与应用(2017年3期)2017-02-18
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年12期)2016-06-14
物联网技术(2015年9期)2015-09-22
现代电子技术(2015年11期)2015-07-28
现代电子技术(2015年8期)2015-07-09
电子技术与软件工程(2015年6期)2015-04-20
无线互联科技(2015年2期)2015-04-02
物联网技术(2015年3期)2015-03-31
软件导刊(2015年1期)2015-03-02
