
信息熵控制的流场动态间距流线放置算法
2021-12-08 00:20秦绪佳程宇轩左少华郑红波张美玉
小型微型计算机系统 2021年12期
秦绪佳,程宇轩,左少华,郑红波,张美玉
(浙江工业大学 计算机科学与技术学院,杭州 310023) E-mail:zhb@zjut.edu.cn
1 引 言
流场可视化是科学计算可视化领域的一个重要且最具挑战性的研究热点,涉及到对流场数据的转换,绘制和操作,流场可视化领域应用范围广泛,因此受到广泛关注.流场存在于我们现实生活中的任何地方,例如水流,气流等物理现象,我们无法直接观察流场的内部结构,因此需要借助科学的方法对流场进行特殊处理,通过可视化技术将其复杂的数据结构以一种简洁直观的方式展示,有效地获得流场的内部规律,这就是流场可视化作为可视化研究中重要领域的意义.流场可视化在许多学科领域例如空气动力学,流体力学,气象学,海洋科学等有着重要的作用.
流线可视化方法是使用流线来表达流场中的信息,可以准确直观地反映出流场的结构特征,被广泛应用于许多工程领域.近些年来,随着工程需求的不断增强,许多研究人员对流线可视化方法进行了大量研究,并在实践中取得了很大的进展与成果.Turk等[1]提出了一种基于图像引导的流线放置方法,首先定义一个能量函数,通过该函数对流线进行一系列操作,然后反复迭代直到能量函数收敛,就能的得到分布均匀的流线,但该方法计算时间过长,效率较低,产生的流线中也存在较多无效值的短流线.Jobard等[2]提出了一种均匀放置算法,该方法先随机生成一条初始流线,并在流线周围放置种子点,然后计算种子点到已生成的流线的欧氏距离,判断欧氏距离是否大于所给定的距离阈值,若大于则是有效种子点,可以生成新流线,若小于则抛弃该种子点,流线停止生成,该方法在所有流线的生成过程中不断地检测并判断已放置的流线之间的距离,使流线能均匀分布,但计算时间较长,运行速度较慢,之后作者对该方法进行了优化,加快了运行速度并推向了非稳定场[3].Mebarki等[4]提出了一种最远种子点放置算法,该方法每次生成流线时选择距离其他流线最远的空白区域,结果是使得生成的流线较长,具有较好的连续性.Verma等[5]提出一种基于流引导的种子点放置算法,首先计算流场的特征点,然后选取适合的模板放置种子点,生成的流线能更好地表现流场的特征类型.Chen等[6]提出了一种相似度引导的流线放置方法,在计算流线及种子点之间的欧氏距离外又引入几何体的相似性,通过结合这两种方法度量不同流线间的相似度距离,能有效地判断流场中冗余的流线并去除.郭雨蒙等[7]在Chen等提出的方法上增加了并行相似度引导的方法,提高了可视化效率.孔龙星等[8]提出了一种特征保持的视点相关三维矢量场流线简化方法,通过对流线视觉效果进行度量,有效地简化了流线集,保持了流场特征且具有较好的视觉效果.鲁大营等[9]提出三维流场的流线提取算法,采用了迭代最邻近点(ICP)和K均值聚类,有效地简化了三维流场的流线.巴振宇等[10]提出一种基于特征信息种子点选取的多层次流线可视化,在计算信息熵时对流场进行区域划分,加快了特征点的计算速度,并在放置种子点时选择合适的特征模板.Han等[11]提出了一种基于深度学习的矢量场重构方法,通过跟踪原始矢量场中每个时间步的流线,并输入到两阶段矢量场重建方法中,有效地简化了矢量场.高天成等[12]提出了一种基于CVT的动态流场可视化方法,通过继承不同时间步的生成元提高了计算效率,同时引入短流线解决了流线相交的问题,提高了可视化效果.
本文主要采用了几何可视化中基于流线的可视化方法来研究二维流场,传统的二维流场可视化方法中使用固定间距放置流线,虽然能达到均匀布置流线的可视化效果,但却依赖于固定间距的大小,间距过小会导致流线分布较密集,过大则容易丢失特征信息.本文提出了基于信息熵控制的流场动态间距流线放置算法,在传统算法的基础上引入信息熵来动态计算流线间隔,根据流场不同区域的不同特征合理布置种子点,通过该算法可以实现在流场的重要区域放置密集的流线,突出特征细节,在其他非重要区域放置稀疏的流线,减少不必要的计算,提高可视化效率.
2 流线生成方式
流线是速度矢量场的场线,流线上任意一点的速度矢量都与该流线相切,流线方程定义如公式(1)所示:
(1)
其中μ(τ)代表点的位置,ν(μ(τ))表示点μ(τ)在流线上的切线方向,τ可以表示时间、弧长等参数,则流线的求解公式如公式(2)所示:
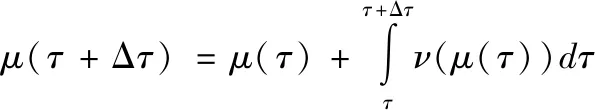
(2)
流线生成过程如图1所示,使用公式(1)定义流线方程,通过公式(2)求解,最终生成流线图.
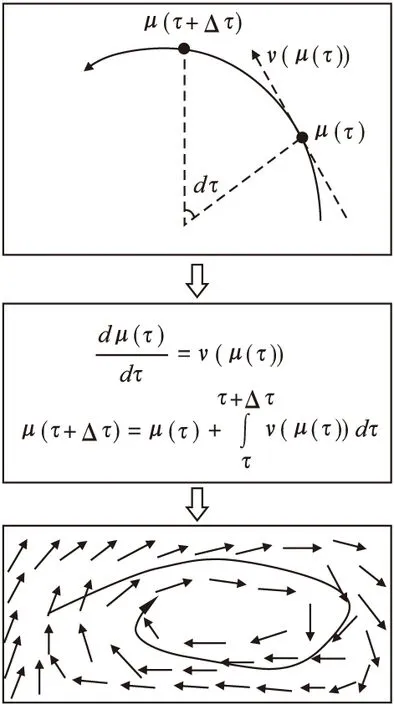
图1 流线生成示意图Fig.1 Diagram of streamline generation
流场数据集中的数据通常是离散的,在没有解析表达式的情况下不能直接通过积分来计算流线,一般采用离散数值积分方法使流线逐步生长.
常见的积分方法有一阶欧拉法和四阶龙格库塔法,不同的方法生成的流线精度不同.其中欧拉法计算速度较快,但生成的流线精度较低;四阶龙格库塔计算量较大,速度较慢,但生成的流线精度较高.
欧拉方法计算公式如公式(3)所示,其中Δt是积分步长,pi是流线上当前点,pi+1是流线追踪的下一点,ν(pi)是pi处的矢量值.
pi+1=pi+Δt×ν(pi)
(3)
四阶龙格库塔方法计算公式如公式(4)所示,公式中使用了k1-k4这4个采样点来计算,因此生成的流线精度更高.
(4)
3 信息熵控制的动态间隔流线放置算法
3.1 流场信息熵定义
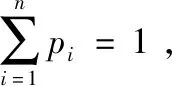
(5)
信息熵度量了一个系统的复杂程度,如果这个系统越混乱,它的复杂程度越高,不确定的信息也越多,信息熵就越大.反之这个系统越有序,复杂程度越低,不确定信息也越少,它的信息熵就越小.从香农计算公式可以看出,当变量x的每个可能值出现的概率p相等时,变量x的信息熵H(x)达到最大值,表示此时出现不同情况的种类最多,系统最复杂,不确定性最大.
通过引入信息熵可以量化流场中矢量信息变化的程度,研究者可以借此有效地确定流场中变化程度不同的区域.Xu[13]等人将信息论中的信息熵概念引入到流场可视化中,并提出了一种流场信息熵的定义与信息熵计算的理论框架.首先将二维流场中的矢量方向区间(0°,360°)划分成n个同等大小的子区间,记为xi,i∈1,2,…,n,然后计算流场中每个矢量的方向,并根据计算后的方向将每个矢量放入对应的子区间中,通过统计每个子区间中矢量数量Si,i∈1,2,…,n,获得一个矢量分布统计直方图,则可以通过公式(6)计算每个子区间出现的概率pi,然后根据公式(5)可计算出流场的信息熵值,通过该值可以反映流场的稳定程度.
(6)
迭代数据信息直到条件熵值收敛并迭代布置种子点,直到满意的结果,这样生成的流线具有较好的可视化效果,并且该框架能够有效地可视化二维和三维流动数据.Cheng等[14]在上述方法中加入了对流线的相似分组,优化了遮挡问题.黄冬梅等[15]提出一种基于信息熵种子点选取的流线可视化方法,通过基于贪婪策略和蒙特卡洛的两种种子点选取方法,优化了流线生成的数量以及分布,解决了流线过多导致的遮挡与杂乱问题,具有良好的可视化效果与显著的可用性.
3.2 局部熵场计算
牛婵等[16]提出了一种基于局部最大熵值的特征点检测方法,解决在提取数据时特征点被遗漏的问题,其次又提出了一种基于特征区域信息熵值变化规律的界定算法,提高流场特征信息提取的准确度.通过计算流场的信息熵可以对流场整体的稳定程度进行量化度量,但为了突出流场中局部区域的变化程度,还需要将流场进行区域划分,分别计算局部位置的熵值.在流场中取多个网格点,计算以其为中心的一个L×L邻域的信息熵作为该点处的熵值,通过计算所有网格点的熵值,可以得到一个与原流场数据规模一样的熵场数据.
计算局部信息熵值需要给定邻域范围和区间数量.选定的邻域范围过小会导致该区域的稳定程度较模糊,邻域范围过大会导致各区域相似度较高,网格点的熵值差距较小,计算量较大且影响计算结果的准确性.对于区间数量,选的过小导致计算结果不准确,相似度和偶然性较高,过多会增加熵场的计算量,使得效率下降.根据测试分析以及经验总结,最合适的邻域范围L为13,区间数量为60,详细计算过程如下:
1)计算矢量方向角
获取二维流场数据的u,v分量并使用公式(7)计算其方向角度dir.
(7)
2)建立概率统计模型
在流场中的局部邻域建立统计模型,通过模型获得概率密度函数计算该区域的信息熵.流场中矢量方向在(0°,360°)之间,将该范围等分为60个区间,使用公式(8)计算dir所在区间I.
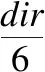
(8)
划分完区间后需要根据每个区间内的矢量个数统计局部邻域内的区间数.设i为流场中的网格点,取以点i为中心的局部邻域,根据统计直方图获取该邻域中矢量数不为0的区间总数,设为bin[i],i∈1,2,…,N,设bin[i][j],j∈1,2,…,bin[i]为统计直方图中以点i为中心的局部邻域范围内第j个区间中的矢量个数,sumBin[i]表示以网格点i为中心的局部邻域中矢量个数,这里取为13×13,通过公式(9)可以计算出以点i为中心的局部邻域中第j个区间的概率pj.
(9)
3)计算局部熵值生成熵场
对每个网格点i通过上述方式计算概率pj,以此建立概率统计模型,则每个网格点所在的局部邻域的信息熵可由公式(10)计算得出.
(10)
图2是使用上述信息熵计算方法生成的熵场,并通过颜色映射直观反映计算结果.图2(a)、图2(b)中左侧为流场图,右侧为该流场数据生成的熵场图,最右侧为颜色映射条,越靠上的颜色代表的熵值越大,通过给不同熵值设定不同的颜色值来反映不同区域的熵值变化.通过对比可以看出在流场变化剧烈的区域熵值较大,如图2中圆形框处的区域,对应颜色映射中顶端的颜色;变化平缓的区域熵值较小,如图2中矩形框处的区域,对应颜色映射表中底端的颜色.

图2 熵场颜色映射结果Fig.2 Color mapping result of information entropy field
3.3 流线间距控制
在流场中生成过多的流线时,如果只是考虑到流线脱离网格边界或速度减小到零就终止生长却没有对流线间的距离加以控制,其结果就是生成的流线相互之间较紧密,距离较小,视觉上表现得较拥挤.图3是在无流线间距控制的情况下生成的流线效果,可以明显地看到流线间距离较小,过于靠近,尤其是在流线的汇聚点,使得视觉效果较差.
为了解决流线过于密集的问题,很多的流场都采用基于欧式距离的流线间距控制来生成流线,将流线间距作为流线的终止判定条件之一.给定一个常量ds为流线间距,设p为当前流线生长过程中的下一个采样点,计算p到其周围某条已存在的流线的距离,因为流线是由一连串离散的采样点组合而成,因此在计算距离时只需要计算p到流线上采样点的距离,若p到其它流线上的某一采样点距离小于ds,则认定当前正在生成的流线与已生成的流线间的距离过小,流线停止生长.
然而随着流场中生成的流线越来越多,这种方法在计算距离时所选取的现存流线上的采样点没有受到约束,会产生大量不必要的计算比较,导致算法效率较低.因此,需要在流场区域建立一个横竖间隔为ds的虚拟网格,将已生成的流线的采样点存储在相应的网格单元中,每次生成新流线的采样点时,通过网格来建立约束条件.
如图4所示,上方与下方的方块点所在的线条为已生成完毕的流线,中间的圆点所在的线条为正在生长的新流线,线上有已生成的采样点,圆点p为当前最新的采样点,方块点为已存在的流线上的采样点,根据该区域建立的虚拟控制网格,在计算采样点距离时,只需要对以p所在网格为中心,选取周围8个网格中其它流线上的采样点进行距离计算,若存在某一个采样点与p的距离小于给定的最小间距,则流线停止生长.
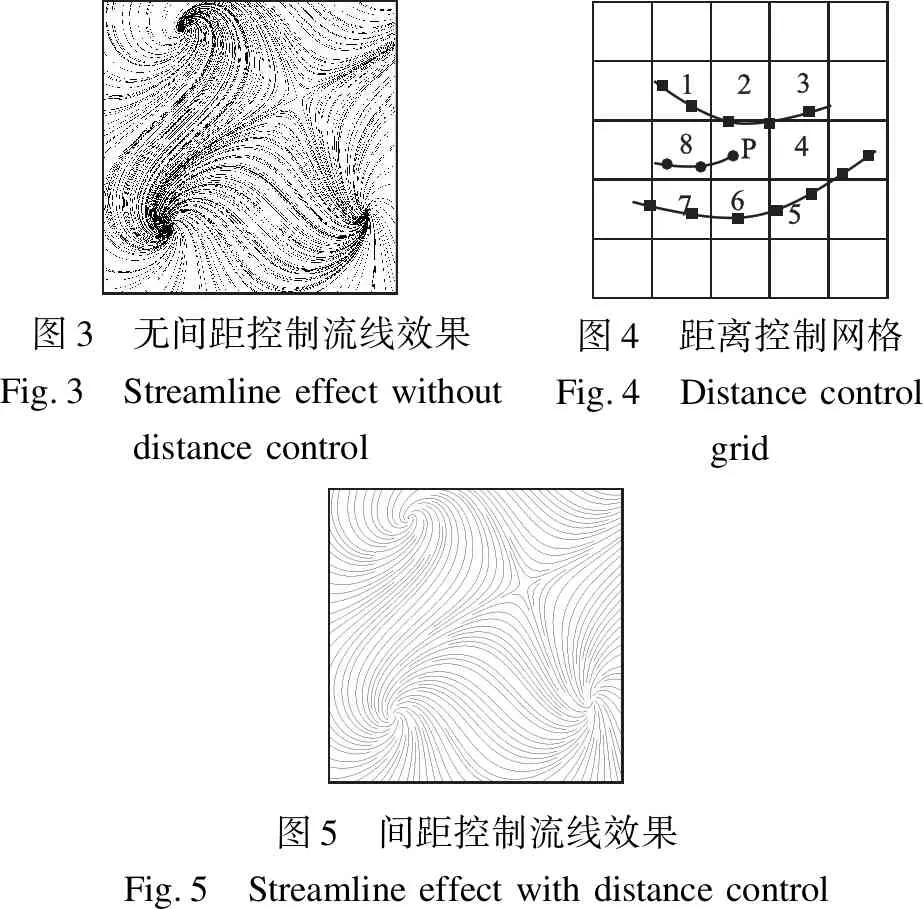
图3 无间距控制流线效果Fig.3 Streamlineeffectwithoutdistancecontrol图4 距离控制网格Fig.4 Distancecontrolgrid图5 间距控制流线效果Fig.5 Streamlineeffectwithdistancecontrol
图5是采用了间距控制后流线放置的效果,与图3进行对比,流线的种子点仍相同,并且可以明显地看到原本流线过于密集的地方通过间距控制后,使得该处流线因距离较小而停止生长,优化了流线的放置,在视觉上有较好的效果.
3.4 信息熵控制的动态间距控制
新生成的流线上的采样点会通过流线间距控制算法计算与周围已生成流线上的采样点的距离,并与给定距离ds进行判断,从而控制新采样点的生成,达到流线均匀放置的效果.但存在的问题是,这种给定的流线间距离ds是固定的,流线分布的位置完全依赖于流线间距ds的大小,若给定的ds较小,就会导致流线数量过大,间距过小,分布过于密集,使得算法运算效率低下;若ds较大,则流线分布较稀疏,容易丢失流场中特征区域的细节,难以表现流场的所有特征,因此这种使用固定间距来控制流线生成的方法并不具有良好的适应性.在前几章中已经详细介绍了流场信息熵以及场熵如何计算,通过在流场中引入信息熵可以对流场稳定程度进行量化度量,可以突出流场中的特征细节.本文使用信息熵对流线的间距进行动态控制,通过计算每个区域的局部信息熵,并在计算流线间距时引入,使得流线间距不再是固定值而是根据流场特征进行动态调整,根据流场信息熵的计算,流场中非重要区域的信息熵值较小,则该区域计算后的流线间距较大,生成的流线较稀疏,流向较稳定;流场中重要特征区域的信息熵值较大,则该区域计算后的流线间距较小,生成流线较密集,流场中不同区域的流线密度不一致能够使得特征区域更加突出,在视觉上有更好的效果.
给定流线间距的最大值为dmax,最小值为dmin,在流场中建立大小为dmax×dmax的虚拟控制网格.在流线生成过程中,流线控制间距值ds根据采样点所在区域的信息熵值来动态计算,计算如公式(11)所示.
(11)
其中emax为信息熵最大值,emin为信息熵最小值,ei为当前点信息熵值,完整的信息熵控制的动态间距流线放置算法如表1所示.

表1 信息熵控制的动态间距控制算法Table 1 Dynamic distance control algorithm based on information entropy
4 实验结果与分析
实验结果生成的不同流线间距的流场效果对比如图6所示.图6(a)-图6(d)是使用相同数据生成的流场,其中图6(a)、图6(b)、图6(c)采用了固定间距的流线生成算法,给定的间距依次增大.分析图6(a)和图6(b),可以看出在间距较小时,生成的流线排列过于紧密,较混乱,视觉效果上较差;如图6(c)所示,间距逐渐增大后,可视化效果上得到了优化,但丢失了流线特征区域的细节,如流场中的涡流与鞍点处.图6(d)则是采用了本文基于信息熵的动态流线间距放置生成的效果图,在优化可视化效果的基础上,保持了流场中的特征细节与变化规律.

图6 不同流线间距的流场效果对比Fig.6 Comparison of flow field effects with different streamline spacing
详细的流线放置效果对比如图7所示,图7(a)是采用传统的固定流线间距生成的效果图,图7(b)是采用本文算法生成的效果图,图7(b)中给定的流线间距最大值与图7(a)中的固定间距一致.图中圆形框处为流场的特征区域,通过对比可以明显地看出图7(b)中该区域生成的流线间距小于图7(a),流线密度高于图7(a),矩形框处为平稳区域,在该区域图7(b)的流线密度与图7(a)基本保持一致.
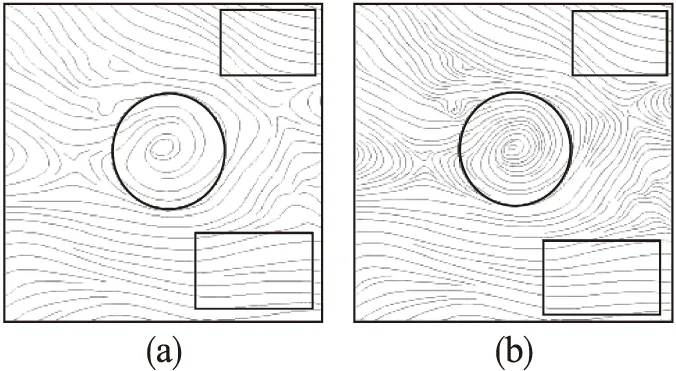
图7 流线放置效果对比Fig.7 Comparison of streamline placement
综合实验结果分析,在使用传统的固定间距算法生成流线时,给定的固定间距较大则容易丢失重要区域细节,固定间距较小则流线密度较大导致计算效率较低且可视化效果较差,通过本文基于信息熵的动态间距控制可以合理分配区域流线密度,在提高了流线生成的速率的同时又保持了流场重要特征.
5 结 论
流场可视化是可视化领域的重要课题,合理地放置流线能突出流场的特征与全局规律,流场中流线的间距是影响流线放置效果的重要因素.本文研究了二维流场的流线放置算法,传统的均匀放置算法采用的固定的流线间隔,生成的流线具有较好地均匀分布效果,但采用的固定间隔较小时流线整体密度大,算法耗时;采用的固定间隔较大时流线整体密度低,容易丢失流场中特征区域的重要信息.本文提出了基于信息熵控制的动态间距流线放置算法,在流线生成过程中引入信息熵来度量流场区域的稳定程度,并以此为依据动态地控制流线间距,使得流线分布具有较好的自适应性,在变化剧烈的特征区域放置较多较密集的流线来完整地表达重要信息;在平稳区域放置较少较稀疏的流线来提高可视化效率.
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
农业工程学报(2022年12期)2022-09-09
军民两用技术与产品(2022年1期)2022-06-01
中国新通信(2022年3期)2022-04-11
汽车工程师(2021年11期)2021-12-21
VOGUE服饰与美容(2019年10期)2019-12-02
中国房地产业·中旬(2019年2期)2019-10-21
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中小企业管理与科技·下旬刊(2017年10期)2017-11-15
中国水运(2016年11期)2017-01-04
