
用于智能驾驶的动态场景视觉显著性多特征建模方法
2021-12-08 13:23詹智成董卫华
测绘学报 2021年11期
詹智成,董卫华
1. 北京师范大学地理科学学部,北京 100875; 2. 根特大学地理学院,比利时 根特 9000
对环境的感知和理解是智能驾驶领域的一个重大挑战。视觉是驾驶过程中驾驶员感知和理解道路场景信息的主要途径。在驾驶过程中,驾驶员会选择性地关注场景中感兴趣的信息,而忽略不重要的信息,这种机制称为驾驶过程的视觉选择性注意机制,选择性注意的区域称为视觉显著区域。在智能驾驶系统开发中,引入人类的视觉选择性注意机制能够降低处理的信息量,提高智能驾驶系统对驾驶环境的理解效率,并有助于预测和定位潜在的风险。视觉显著性建模方法能够模拟人类的视觉注意机制提取场景中的显著区域,从而支持信息处理和决策。对驾驶员在驾驶过程中的视觉注意机制进行研究,开展真实道路场景下动态道路场景的视觉显著性建模,能够准确和快速地提取动态驾驶场景的视觉显著区域,从而提高智能驾驶系统的环境理解效率和能力。
目前,国内外对道路场景视觉显著性的研究已有不少的经验,特别是在行人导航领域。人类的视觉注意机制被归结为场景的低级视觉特征和高级视觉特征[1]。低级视觉特征是图像对视觉的直接刺激,这类特征包括颜色、亮度和纹理等[2]。高级视觉特征一般指语义特征,这种特征与人类的认知相关,比如在某些场景中人脸等物体对视觉具有引导作用[3]。道路场景的视觉显著性分析可以用来评价导航任务下场景中地标的有效性[4]、用户的寻路策略[5]、地图的可用性[5]等。视觉显著性的测量流程主要包括设计眼动跟踪实验,收集眼动数据和分析注视点的分布[6]。视觉显著性模型可以模拟人类的视觉注意机制自动计算和提取场景的视觉显著区域,在导航系统设计[7]、用户导航任务推理[8]和地标设计[9]等方面具有广泛的应用。
虽然场景的视觉显著性在遥感影像检测[10]和行人导航领域等地理信息领域研究比较成熟,但驾驶环境下道路场景的视觉显著性建模的研究相对较少,主要原因是驾驶场景相对复杂。首先,驾驶过程具有动态性[11]。动态性包括3个方面:场景的动态变化、驾驶关注区域的变化和车辆的运动。场景的动态指车辆位置的改变使得驾驶场景不断变化,驾驶关注区域的变化是指驾驶员的视觉注意区域的改变,车辆的运动指车辆的速度,加速度和位置随时间的改变。场景动态特征通常用光流图表征[12],定义为后一个时刻场景像素相对于前一个时刻场景像素位移的方向和强度。其次,驾驶场景的复杂性来自道路场景的多样性[13],主要表现在道路类型、道路结构、交通状况和空旷度等方面,而这些道路属性也是自动驾驶所需要的基本信息[14]。再次,驾驶环境下驾驶员具有双重任务,驾驶员不仅要保证行驶方向的正确,更要确保行车过程的安全。研究表明,驾驶环境下道路场景的动态性[15]、道路场景特征[16]和任务[17]都是影响驾驶员视觉行为的重要因素。
驾驶员的视觉注意力会受到多种因素的影响。其中驾驶速度是一个关键因素。有研究显示高速行驶时驾驶员的视线更集中[18],同时驾驶员的视觉认知负荷也越大[19]。道路结构也影响驾驶员的视觉注意和认知负担。文献[20]通过模拟器试验发现,驾驶员在交叉口驾驶时注意力分散是导致事故多发的主要原因;文献[21]通过设计40名受试者观察100张静态交通图的眼动试验发现受试者倾向于观察道路消失点;文献[19]发现道路曲率越大,驾驶员的视觉负载越重。不同的语义信息也会导致驾驶员的视觉注意差异。道路场景中出现的车辆、行人和路标等目标都能不同程度地吸引驾驶员的注意,因此现有的辅助驾驶系统大都包含行人检测模块[22]、车辆检测模块[23-24]、道路和车道检测[25-26]及交通信号识别模块[27]。上述分析表明,建立驾驶员的视觉注意机制模型需要考虑多种因素的影响。目前对于驾驶环境道路场景视觉显著性建模的研究大多是在静态桌面环境和虚拟环境为试验平台下进行,见表1。对于文献[18]开展的真实环境中道路场景显著性的模型研究,虽然考虑了车辆速度的作用,但没有考虑道路结构对驾驶员视觉注意机制的影响。
本文在分析驾驶员视觉特征的基础上,引入了表征动态性的驾驶速度和表征场景类型复杂性的道路结构为建模要素,提取了道路场景的低级视觉特征、以语义信息为主的高级视觉特征和动态特征,构建了驾驶环境下动态场景的视觉显著性计算模型。
1 数据预处理
1.1 数 据
本文所使用的数据为意大利摩德纳大学发布的DR(eye) VE驾驶场景数据集[18]。该数据集记录了8名驾驶员(7男1女)74次驾驶过程,每个驾驶过程持续5 min。这组数据包含了驾驶员的注视点、行车录像、GPS轨迹和驾驶速度等信息。驾驶员位置每秒更新一次,驾驶速度每秒记录25次。数据收集的硬件配置和数据格式如图1所示。车顶摄像头Garmin配置为1080p/25 fps,用于固定观察视角,车辆配有GPS。驾驶员驾驶过程中佩戴眼镜式眼动仪ETG,该眼动仪注视点采集频率为60 Hz,眼动仪的摄像头配置为720p/30 fps,可同步记录驾驶员视角下的场景。

表1 驾驶场景视觉显著性模型研究

图1 视频与眼动数据采集Fig.1 The equipment and process of movement collection
1.2 标准显著图
标准显著图是由眼动数据生成的用于训练视觉显著性模型和检验模型精度的显著性真值。本文研究使用了驾驶员1 s内的注视点构造道路场景的标准显著图。该过程首先用二维高斯函数对注视点进行平滑,然后累加注视点的平滑结果得到标准显著图。该过程的描述如下
(1)
(2)
式中,(x,y)为像素坐标;(xi,yi)为第i个注视点坐标;gi(x,y)表示第i个注视点对于像素(x,y)显著性的贡献大小;σ为表示高斯函数的影响范围的参数,本文根据经验取值70 px。n表示1 s内注视点的数量;I(x,y)表示像素(x,y)的显著值。主要的数据格式如图2所示。

图2 标准显著图Fig.2 Standard visual saliency image
1.3 道路曲率提取
道路曲率由原始的GPS点位数据计算得到(图3)。GPS定位的偏差使得轨迹无法直接用于计算道路曲率,因此本文采用了指数多项式平滑算法(PAEK)来平滑原始轨迹点然后将平滑后的线条重新采样成点,最后用三次B样条法[37]计算曲率,计算方法为
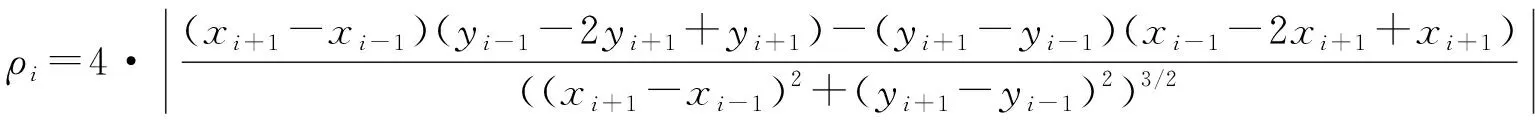
(3)
式中,ρi为第i个点的曲率;(xi+1,yi+1)为前一个点的坐标;(xi-1,yi-1)为后一个点的坐标。
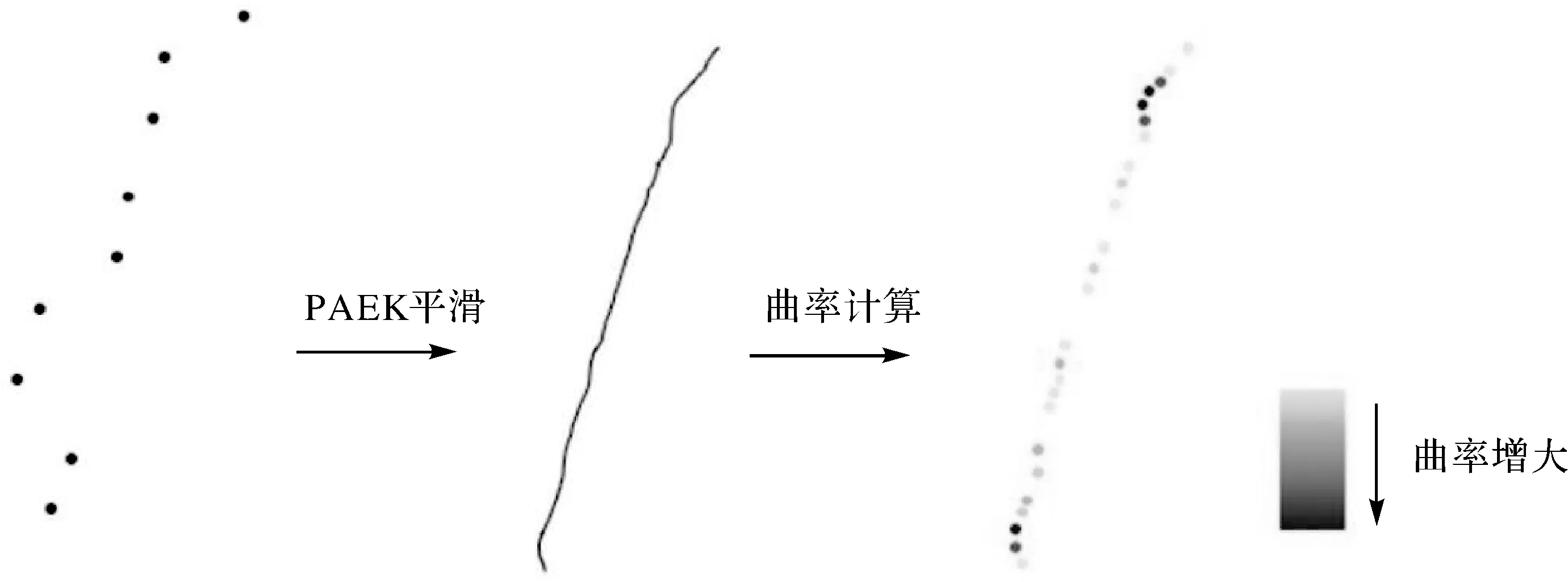
图3 道路曲率计算过程Fig.3 Calculation of road curvature
1.4 道路消失点提取
道路消失点的计算方法主要有直线交点法和纹理特征法两种。直线相交法检测场景中所有直线,并统计直线相交点从而得到道路消失点[38]。此法适用于具有明显边界线和车道线的结构化道路,如城市道路、高速路等。基于纹理特征的提取方法[39-40]计算所有点的纹理方向,并统计纹理方向以获得最佳消失点。基于纹理特征的方法适用于几乎所有的道路场景,但相对于直线相交法计算更为复杂。鉴于本文研究的数据中含有非结构化道路(乡下道路),直线法难以精确地提取场景中的直线,本文引用文献[41]基于Gabor计算纹理和使用投票机制得到道路消失点的方法。提取结果表明,大部分的道路消失点提取准确(图4),少数提取错误的场景采用人工方法进行了修正。

图4 道路消失点提取示例Fig.4 Examples of vanishing point detection
1.5 场景语义分割
场景语义信息属于视觉高级特征。人工提取注视点语义信息耗时耗力,计算机视觉技术的发展使自动提取场景语义信息成为可能。本文引入了由Google公司开发的Deeplab V3+图像语义分割模型[42],该模型将深度卷积神经网络和概率图模型相结合,融合多尺度信息,并引入了encoder-decoder架构,对图像和场景的分割有很强的效果。该模型的训练数据集为CityScape[43],模型的Iou精确度可达82.1%。Deeplab V3+模型对本文道路场景的分割结果例子如图5所示,其精度可以满足本文研究的使用要求。
2 视觉显著性建模
2.1 视觉特征选取
本文结合3种类别的特征构建动态道路场景的视觉显著性:低级视觉特征、由驾驶环境和驾驶任务决定的高级特征和人眼对动态场景感知的动态特征。表2列出了本文特征的选取及其描述。低级视觉特征中,除了颜色,纹理和亮度之外,还选取了Itti,SUN和GBVS 3种显著性模型的显著图。高级视觉特征包括语义特征和道路消失点。动态特征则为光流图的方向和强度分量的组合。
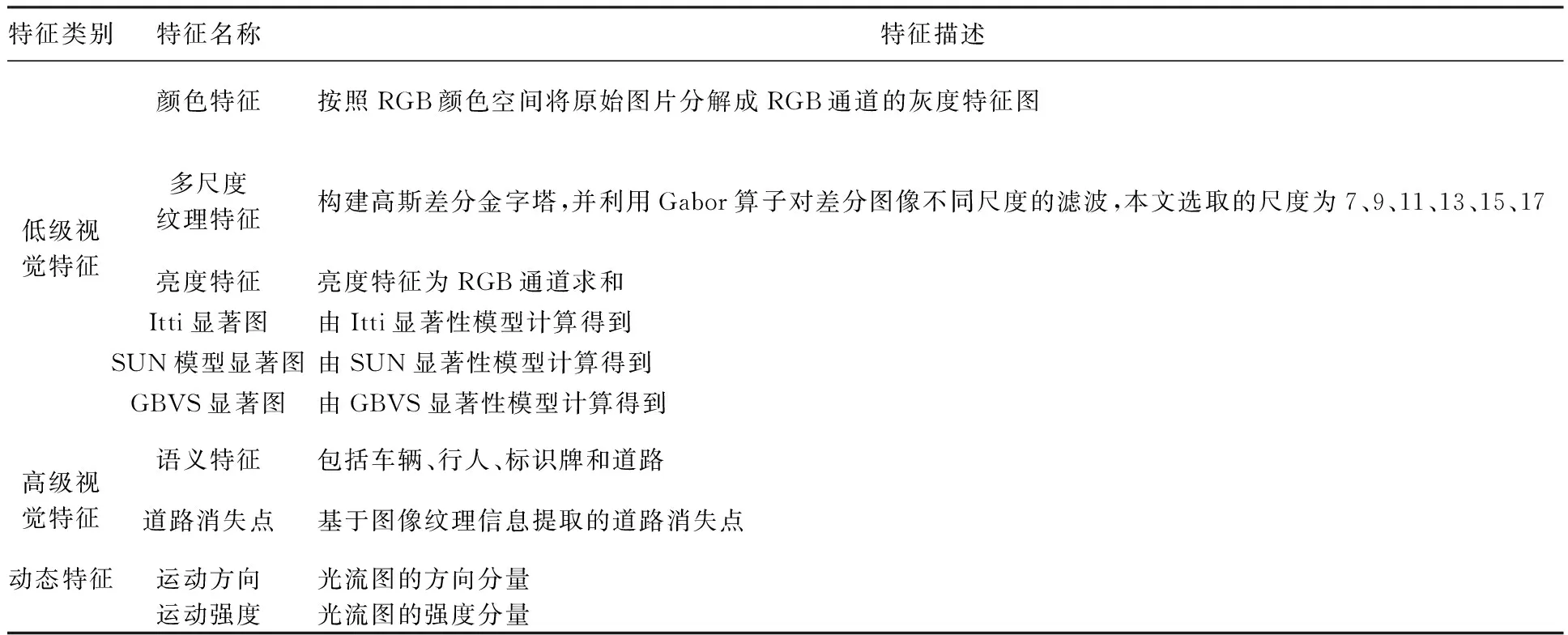
表2 视觉特征列表
2.2 模型设计
场景的视觉显著性是多特征共同作用的结果,本文采用了机器学习中的逻辑回归(LR)模型[44]计算场景显著性,处理流程如下。
(1) 分析了速度、曲率与驾驶员视觉注意的关系(见附录),以考虑驾驶场景的动态性和路面结构特性。分析结果表明,速度和曲率对人的视觉注意的位置和语义信息具有重要的影响。为此,本文在LR模型中引入速度和道路曲率2个因素。
LR模型的基本原理是将特征线性组合,然后根据Sigmoid函数对组合结果进行二分类。本文以像素为单位计算显著图,其公式如下
(4)
θTx=θ0+θ1x1+…+θnxn
(5)
式中,hθ(x)为目标函数;g为Sigmoid函数;x为像素的特征向量;xn表示第n个特征;θ为特征向量的系数,表示特征的线性组合。
(2) 对上述经典逻辑回归模型中的系数增加以下的定义
θ=VK1+CK2+K3
(6)
式中,V为驾驶场景的速度;C为驾驶场景道路曲率;K1、K2、K3分别为速度系数、道路曲率系数和常数项。
(3) 运用训练数据对模型进行最小二乘法拟合,求得各特征系数。残差平方和成本函数用于拟合度的评估为
(7)
式中,SSres为残差平方和;n为测试样本数;f为训练模型;xi为测试像素特征;yi为像素的显著性。
2.3 LR模型计算框架
LR模型运行流程如图6所示,主要包括特征提取,随机像素抽样、模型训练和模型测试评价。
本文从74段视频中共提取出22 200个场景,由图片和注视点生成的标准显著图大小为1920×1080像素,为方便计算重采样成大小为480×360像素的图片。训练数据集占全部数据集的70%,即15 540个场景。本文数据场景数量太多,为了保证每一个场景都能参与模型训练,且训练的样本足够,本文在每一场景中随机选取10个显著的像素点和10个不显著的像素点作为模型的输入。此外本文选用了广为接受的指标ROC(receiver operating characteristic curve)和AUC(area under curve)来评估模型的预测结果。
3 结 果
3.1 模型结果
验证数据集占全部数据集的30%,即6660个场景。本文提取验证数据集的3类特征,并逐像素地输入训练好的LR模型,将输出的像素值组合成预测显著图。LR模型计算得到的显著图是一张连续的灰度图像,灰度的大小表示像素的显著程度。部分视觉显著图计算结果如图7所示。灰度值高的区域能够与注视点生成的标准显著图显著区域对应。在不同的驾驶情况下,LR模型对道路消失点、车辆和指示牌等目标的显著性都能准确预测,模型的AUC值达到90.43%。

图5 语义分割结果Fig.5 Result of the image segmentation

图6 LR模型显著图计算框架Fig.6 Framework of LR model for calculating visual saliency

图7 注视点分布和预测显著图的比较Fig.7 Comparison of the gaze point distribution and visual saliency prediction
3.2 视觉特征分析
LR模型将视觉显著性看作是特征的线性组合,因此LR模型的系数能较好地反映各特征对场景显著性图的贡献大小(表3)。
在所有特征中,消失点对视觉显著图的贡献最大;红色通道的系数明显大于绿色和蓝色通道;在经典显著性模型生成的特征显著图中,GBVS特征系数远大于Itti和SUN特征,仅次于红色通道的系数;高级视觉特征中的4种语义特征均为正值,其中行人特征图对显著图的贡献最大,其次为车辆特征图。运动强度的系数为正值。
综而观之,《回忆与随想》一书详细论述了陆徵祥一生的思想转变历程,向读者清晰地展示了他的思想与实践轨迹。

表3 LR模型特征系数
对特征系数进行分析,亮度特征对驾驶环境下的场景视觉显著性为负,主要原因可能是整个场景中天空的亮度值最大,然而驾驶员在驾驶过程中并不关注天空。红色通道系数大于绿色和蓝色通道的系数,一个主要的原因在于颜色通道特征和语义特征的关联性。在所有场景中植被区域的绿色通道比重大,天空区域的蓝色通道比重大。而这2类语义信息并不显著,从而导致了RGB 3通道系数的差异。GBVS模型显著图的显著区域集中于图像的中心区域如图8所示,与道路消失点特征有一定的关联,所以GBVS模型显著图对场景的视觉显著性的贡献较大。Itti模型显著图和SUN显著图对最终显著图的贡献不大,这可能是因为这2个模型侧重于检测边缘信息,然而这类信息在驾驶过程中对视觉引导作用很弱。

图8 Itti、GBVS和SUN模型显著特征图对比Fig.8 Comparison of significant features of Itti, GBVS and SUN models
行人特征图的系数在各系数中最大,其次是车辆语义系数,这2个系数较高的原因可能是2者都是动态的,驾驶员需要判断这2个语义类别是否对自己的驾驶过程有影响;而道路由于覆盖范围较广,只是在消失点处显著,因此总体系数值不大;交通标志贡献不大的主要原因在于有经验的驾驶员熟悉驾驶环境之后并不会特别关注交通标志。运动强度对视觉显著性有正向影响,反映了在驾驶环境下人们对移动目标有一定程度的敏感性。
3.3 不同速度和曲率下的精度对比分析
为了探索不同速度和曲率下模型的显著性计算结果,本文验证了模型在不同的速度和曲率下的精度。
不同曲率下的ROC曲线如图9所示,其预测精度在不同曲率下相差很大,当曲率大于1000时,ROC曲线比曲率小于1000的ROC曲线低。各种曲率下的AUC见表4。
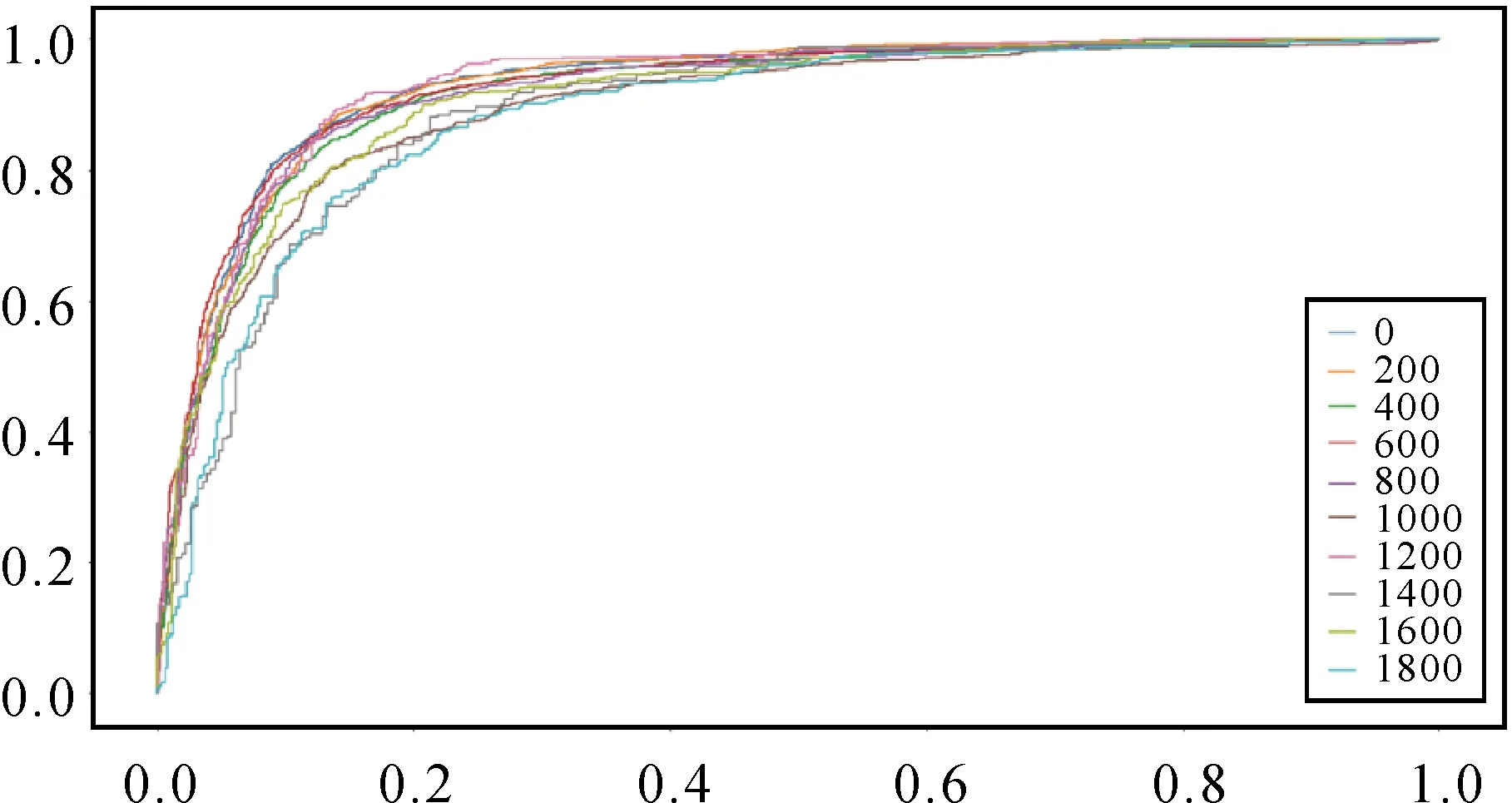
图9 不同的曲率下的ROC曲线比较Fig.9 Comparison of ROC under different road curvature
不同速度下的ROC曲线如图10所示。当速度为0时,ROC曲线最高,而其他速度下的ROC曲线比较接近。各种速度的AUC值见表5。
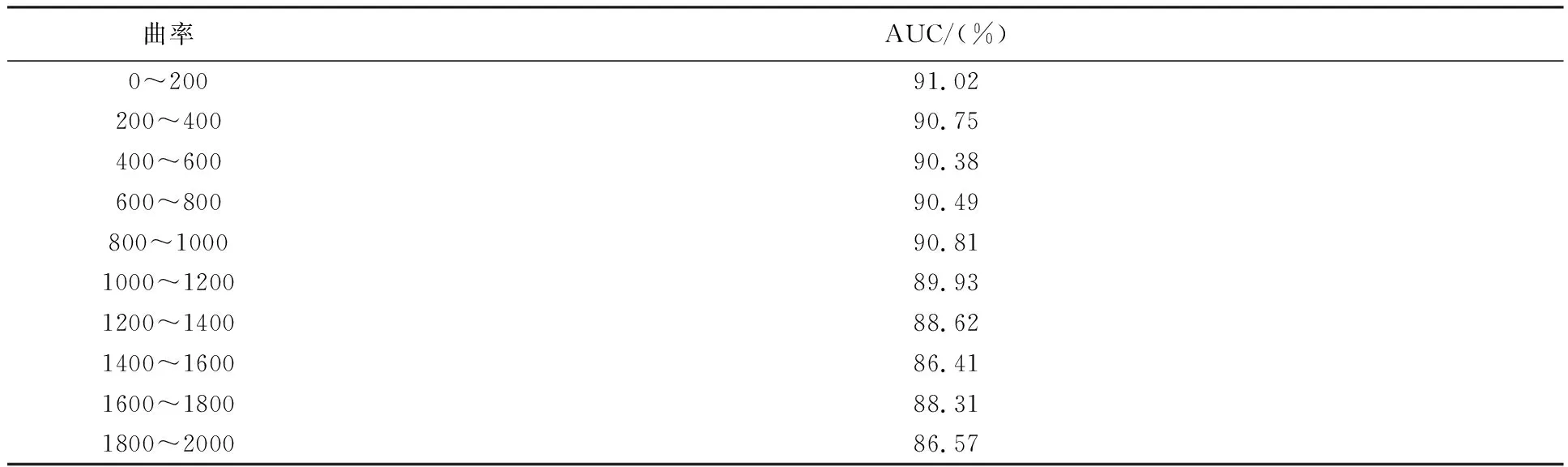
表4 不同曲率下的AUC
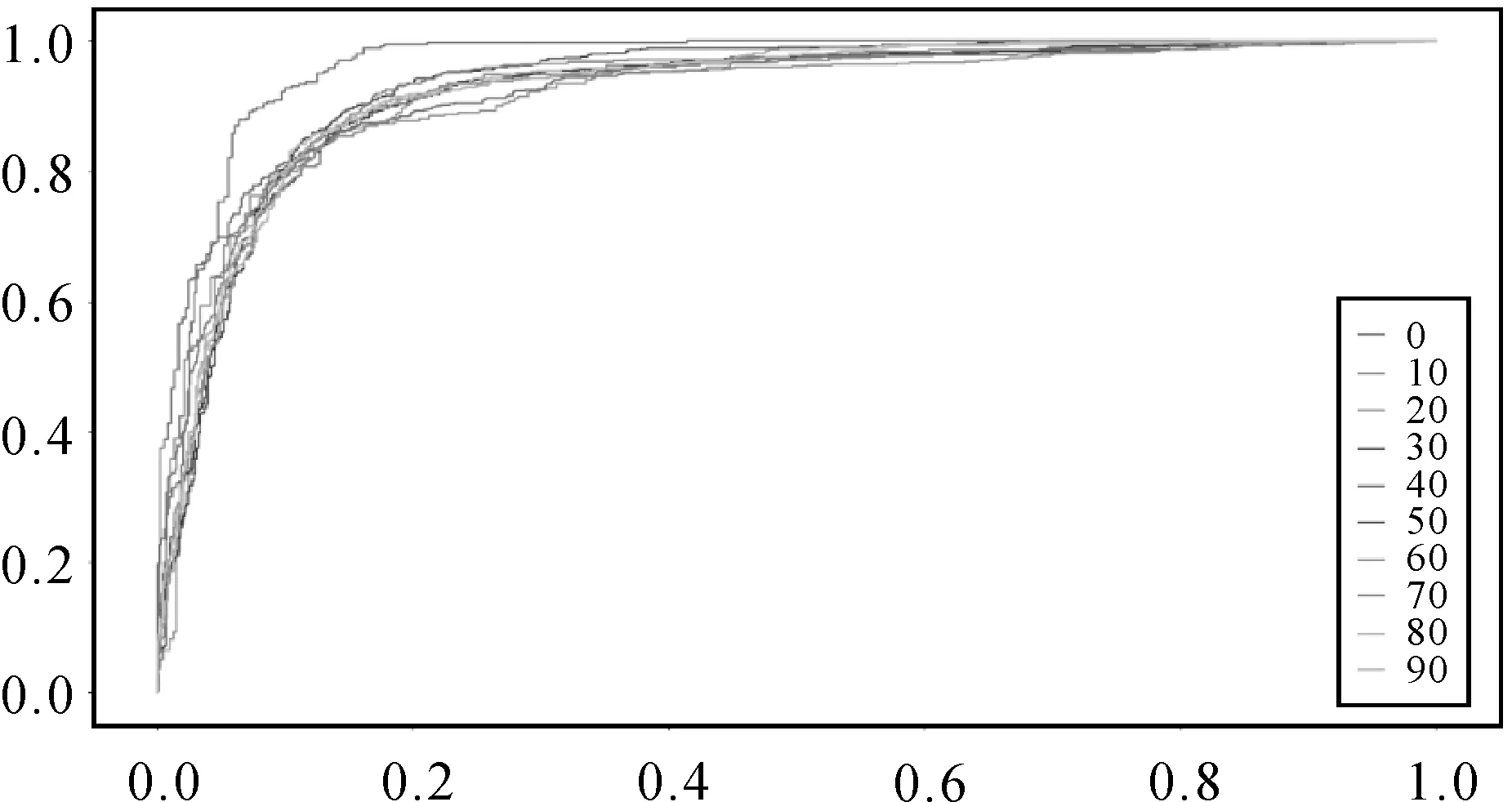
图10 不同速度下的ROC曲线比较Fig.10 Comparison of ROC under different speeds
3.4 模型对比分析
与Itti、GBVS、SUN,传统LR模型相比较,本文的扩展的LR模型精度最高(表6),而Itti和SUN模型预测精度均小于0.5。结果表明,本文所提出的模型预测道路场景视觉显著性具有可行性和优越性。
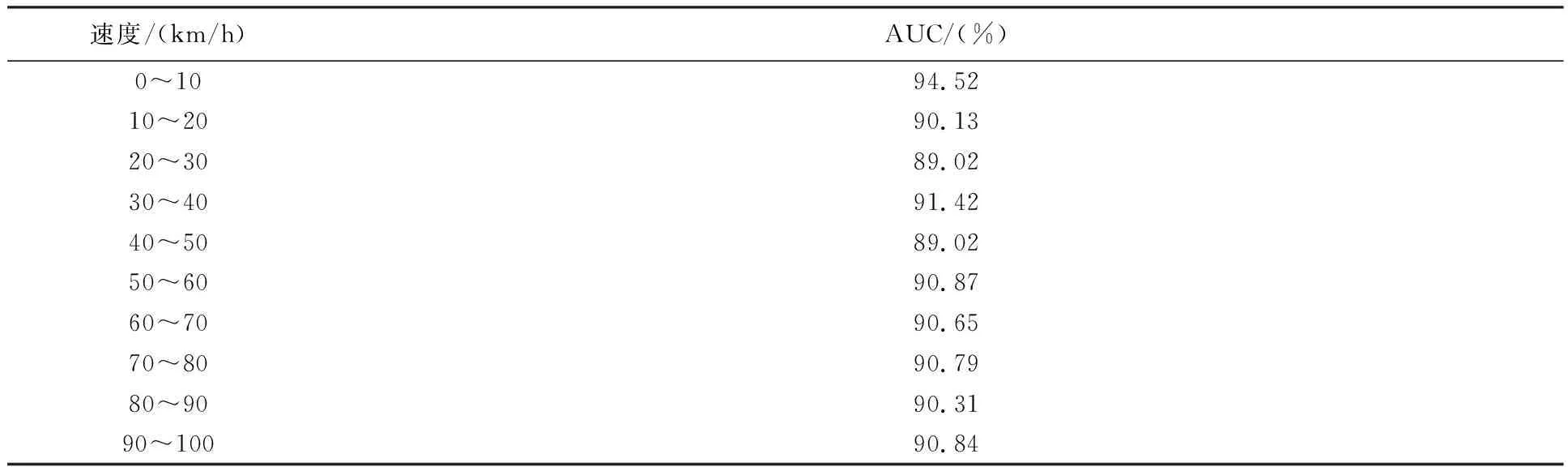
表5 不同速度下的AUC

表6 各模型AUC值比较
4 结论与讨论
对场景重要的物体和区域检测对智能驾驶系统至关重要。本文提取了低级视觉特征、高级视觉特征和动态特征,构建带有速度和曲率系数的LR视觉显著性检测模型。研究结果表明提出的LR模型的ROC曲线AUC值为90.43%,模型预测区域和视觉关注区域匹配准确。通过特征系数分析发现,消失点对视觉显著性贡献最大,场景的红色通道和GBVS显著图次之,同时亮度、纹理、Itti和运动方向特征在LR模型中的系数值为负值,说明这些特征与视觉显著性呈负相关。本文提出的模型有助于智能驾驶系统的环境理解,并在特定对象跟踪检测、驾驶训练,安全警告和交通标志检测等方面有重要作用。
数据可用性是本文的一个限制。每段驾驶场景仅包含单个驾驶员的注视点,个体偏差会影响模型的预测准确性。另外,注视时长和注视点均为视觉显著性评价的重要眼动指标,由于数据集没有提供注视时长数据,所以本文仅根据注视点的个数和分布进行建模。而加入注视时长数据能更加准确地表达视觉显著性。驾驶员的年龄、性别和驾龄等因素也是影响道路场景视觉显著性建模的重要因素,本文所收集的数据仅来自8名驾驶员,其中7名为男性,没有年龄和驾龄等信息,因此无法发掘个体信息对视觉注意机制的影响。试验并探究不同环境下的视觉显著性,其主要原因是在光线较暗的下雨天和晚上采集的图像语义分割效果不理想。今后还会完善驾驶数据收集过程,增加驾驶员数量和注视点自身的注视时长信息,发布全面的驾驶数据集,还需要深入探讨驾驶员个体差异对真实驾驶环境中道路场景视觉显著性的影响,并对不同驾驶环境的差异进行探索,包括道路类型、驾驶时间、天气条件等。这些将服务于构建结合人的属性、环境属性和车辆状态构建人-车-环境一体化的道路场景视觉注意模型。
猜你喜欢
中国港湾建设(2022年12期)2022-12-28
智能建筑与智慧城市(2022年9期)2022-09-28
数学物理学报(2022年4期)2022-08-22
汽车实用技术(2022年14期)2022-07-30
汽车实用技术(2022年4期)2022-03-07
兰州理工大学学报(2021年5期)2021-11-02
数学物理学报(2019年5期)2019-11-29
体育时空(2017年6期)2017-07-14
复旦学报(自然科学版)(2016年4期)2016-09-21
公民与法治(2016年4期)2016-05-17
