
云存储网络映射密文搜索的恶意域名检测仿真
2021-12-10 09:07陈晓飞
计算机仿真 2021年11期
陈晓飞,姚 翔,贾 勇
(1.新疆工程学院信息工程学院,新疆乌鲁木齐830023;2.新疆师范大学化学化工学院,新疆乌鲁木齐830054)
1 引言
“恶意域名”是指传播蠕虫、病毒、木马,或从事钓鱼欺诈等违法活动的网站域名。有些网站的恶意域名可能会出现在邮件,短信或者广告中,通过让人迷惑的文字和图片来吸引用户点击。如果用户设备访问这些恶意域名,则可能导致木马植入、病毒感染或泄露个人信息等风险。由于安全设备和安全软件只能保护自己免受外部威胁,所以如果内部设备受到感染,所有内部设备都会直接暴露给攻击者。如不及时处理,将会造成严重后果。
基于目前存在的问题,已有许多学者进行了关于恶意域名检测方法的研究,彭成维[1]等人研究了一种基于域名请求伴随关系的恶意域名检测方法,该方法主要通过挖掘域名请求之间潜在的时空伴随关系进行恶意域名检;臧小东[2]等人研究了基于AGD的恶意域名检测方法,该方法通过聚类关联,提取每一个聚类集合中算法生成域名,以对恶意域名进行检测。
上述方法虽然具有一定的恶意域名检测效果,但是存在检测准确性低的问题,为此设计一个云存储网络映射密文搜索的恶意域名检测方法,以解决目前恶意域名检测上存在的问题。
2 云存储网络映射密文搜索的恶意域名检测方法设计
2.1 获取基础数据
在对云存储网络映射密文搜索的恶意域名检测前,获取基础数据[3]。全局历史数据获取内容如下所示:

表1 全局历史数据获取
然后对原始流量数据包进行过滤筛选,预处理过程如图1所示。
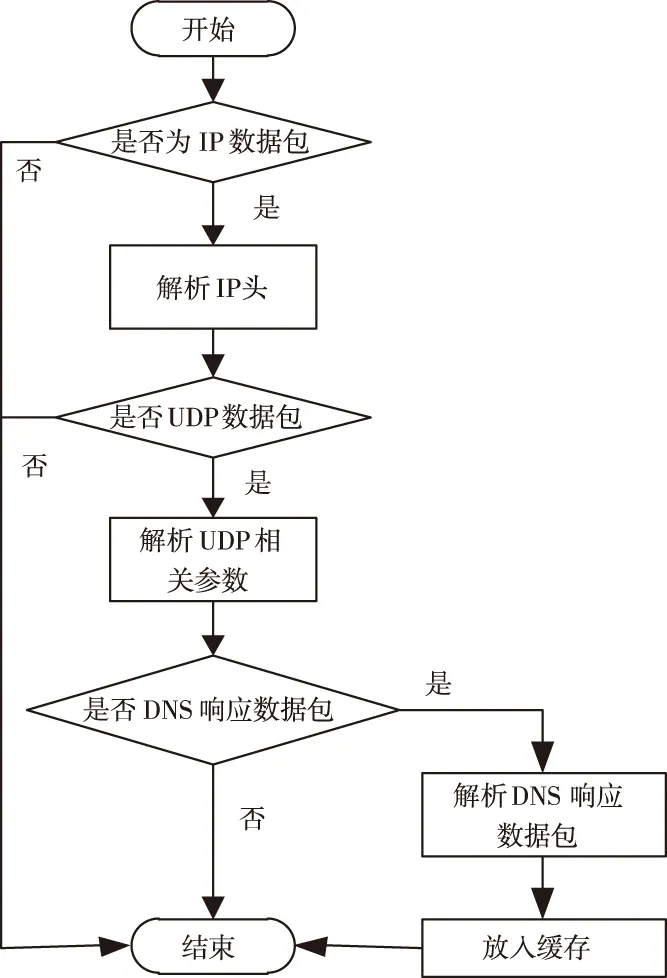
图1 预处理模块处理流程
2.2 数据特征提取
在上述基础数据获取的基础上,对数据特征进行提取。特征量的提取就是把无法识别的原始数据转化成可以识别的特征量,其是恶意域名[4]检测中非常重要的一步,主要内容如下所示。
2.2.1 时间特征提取
在时间特征提取上,为分析域名状态随时间的变化情况,将某一时间段设置为观叉窗口,是指数据分析前后的一段时间,每个域名都会在观察窗口中选择数据。每一字段的数据可以按照时间顺序形成一个观测序列[5]。将观测序列分成固定的时间段(小时),对同一域名在固定的时间段内的状态变化进行统计[6]。并提取了3个特征:
第一个特征是活跃期。在观察窗口中,域名第一次查询到最后一次查询的时间间隔称为活动时间,它反映了域名在观察窗口中的活跃时间的长短;
另一个特征是平均每日访问量,能够反映域名的“自由”状态[7](即域名没有被查询到)或已被访问过(即热门域名);
最后一个特征是其日常行为具有相似性,一天中对域名的查询量随时间而变化,这种特点能够反映出域名是否每天都有类似的时序[8]。
基于上述分析,以天为单位,将观测窗口中时间序列设置为每天00:00开始,23:59结束。当一个域名被查询了n天时,其计算表达式为

(1)
式中,di,j代表第i天和第j天之间的欧式距离。
在此基础上对时间序列进行标准化处理,得到时间序列的均值与方差,表达式为
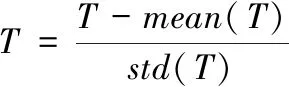
(2)
式中,std(T)代表时间序列T的标准差,mean(T)代表时间序列T的均值。
2.2.2 响应报文特征提取
在此基础上,对响应报文特征提取[9],预先解析的IP地址集的分散程度[10]。其表达式为
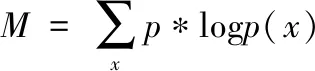
(3)
基于上述过程完成对网络中数据特征的提取,为恶意域名检测仿真提供基础。
2.2.3 域名的特征提取
相对于良性域名,恶意域名的字符串组成一般比较杂乱,常常包含数字和特殊符号“-”和“_”,并会出现间隔,恶意域名字符串通常不匹配良性域名。主要提取内容如表2所示。
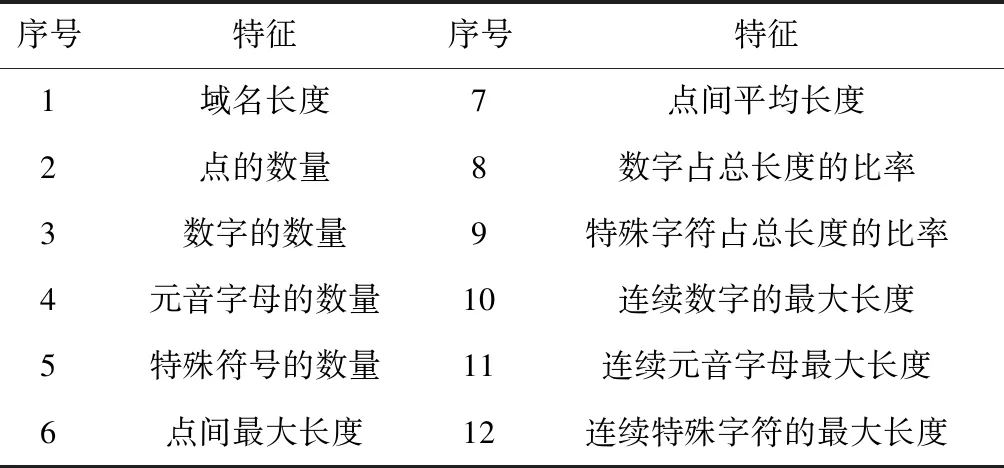
表2 词汇特征
在此基础上,主要分析子域名中制度的平均随机程度,其表达式为
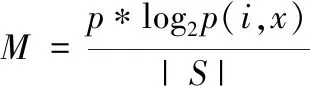
(4)
式中,S代表子域名集合,p(i,x)代表字符x在第i个子域在子域名S中占得比例。
依据上述过程完成特征数据的提取。
2.3 恶意域名检测实现
依据上述特征提取结果,采用随机森林方法[11]获取恶意停靠域名,以实现对恶意域名的检测[12]。具体过程如下所示:
Step1:在对停靠域名处理过程中,对全部域名进行过滤处理,其过滤函数为
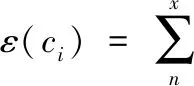
(5)
式中,ε(ci)代表函数过滤值,ω代表过滤系数。
Step2:依据上述过滤函数的计算,获得待分类的域名数据。采用随机森林算法对恶意域名与正常域名[13]进行分类,分类过程如图2所示。

图2 恶意域名与正常域名分类过程
具体内容如下,假设待训练的样本集为E,其表达式为

(6)
式中,Gini(E)代表样本集的基尼系数度量值,pl代表样本集隶属类别于l的样本数量。
Step3:通过关键字的数字值来确定关键字落在哪个分区上[14],然后通过数字范围来确定数据库中哪些记录可能满足搜索条件,从而获得基础数据。
在此基础上,计算数据属性的最优分裂点[15],并生成对应的决策树,计算公式为
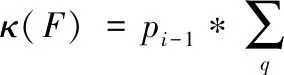
(7)
式中,κ(F)代表对应的分类树,Nf代表决策树生成参数。
Step4:恶意域名检测,一般情况下,正常域名不会与多个域名共享相同的IP地址,而恶意域名则有所不同,很多域名经常会共享同一个 IP地址。对于whois信息的完整性,一般情况下正常域名是全面描述的,恶意域名基本上不会填写whois信息。利用同一 IP的 IP域数之和与其自身whois信息完整性的比值作为特征,可以区分正常域和恶意域。根据以上的分析,进行分类,表达式为
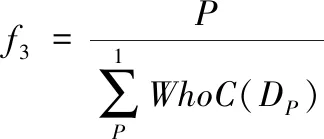
(8)
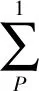
与此同时,正常域名和恶意域名的 IP地址随时间的增长而变化,而正常域名的 IP地址变化不大,恶意域名的 IP地址变化不大。随着时间的推移,正常域名的这种特征值逐渐减小,恶意域名的特征值逐渐增大并趋于1,设置该特征的表达式为
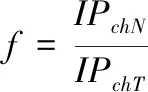
(9)
式中,IPchT代表域名的变化速度,IPchN代表域名的变化时间。
依据上述过程,完成恶意域名的分类。
Step4:在此基础上,对分类结果进行测试,测试函数如下所示
ι(U)=testκ(F)*f
(10)
式中,ι(U)代表测试函数值。
通过上述计算完成该算法的计算,获得恶意域名,以此完成云存储网络映射密文搜索的恶意域名检测。
3 实验分析
3.1 实验环境
为验证此次研究方法的有效性,进行此次实验,本实验的实验环境如下:
1)虚拟机:10.0.0 VMware工作站;
2)OS:Ubuntu14.0464位;
3)编译程序、Eclipse3.8;
4)网络仿真:Mininet2.2。
通过Mininet 虚拟网络平台和 Floodlight 控制器搭建的实验环境来验证恶意域名检测方法的有效性该试验的具体部署和配置如下:
1)将64位 Ubuntu14.04 LTS安装到64位win7操作系统的 VMware虚拟机上,创建两个网卡,其中一个连接外部网络,另一个则作为空闲资源备用。
2)在 Ubuntu系统中,使用 Python调用 Mininet库来创建虚拟网络拓扑结构。
3)在 DNS重定向服务器上作为 DNS解析器运行 Python程序,以向发送 DNS查询包的主机返回 DNS响应包。
3.2 实验数据来源以及实验对比指标
从网络安全联盟和PhishTank等网站获取已知恶意域名,鉴于恶意域名的持续时间较长,选取500个具有以上特征的恶意域名作为黑名单。将 Alexa排名较高的域名用作普通域名是合理的,因为 Alexa是基于三个月积累的域名访问信息的,将该数据用作白名单是合理的。白名单是以 Alexa排名的1162个域名为标准构建的,使用 dig,nslookup,whois,bgp表示每个域名的网络属性特征。为节省实验时间,对实验数据预处理,其表达式如下所示
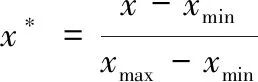
(11)
式中,x*代表归一化的数据,x代表当前原始数据,xmin代表当前数据属性中最小数据值,xmax代表当前属性中最大数据值。
经归一化处理后的数据进行整理,共整理出1050条数据,将其分为50、100、150、200、250、300条数据,共进行6次进行实验。
实验主要将文献[1]中的基于域名请求伴随关系的恶意域名检测方法、文献[2]中的基于AGD的恶意域名检测方法与此次研究的方法对比,对比三种方法的准确率、召回率与检测时间。
准确率用以下公式进行计算:

(12)
式中,TP样本分类准确率,FP代表将负样本分类到正样本的参数。
召回率的计算方法如下所示
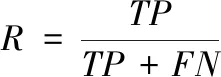
(13)
式中,FN代表假负类,将正样本分类错误的参数。
3.3 检测准确率对比
分别采用此次研究的检测方法与文献[1]方法、文献[2]方法对恶意域名检测准确率进行分析,得到对比结果如图3所示。
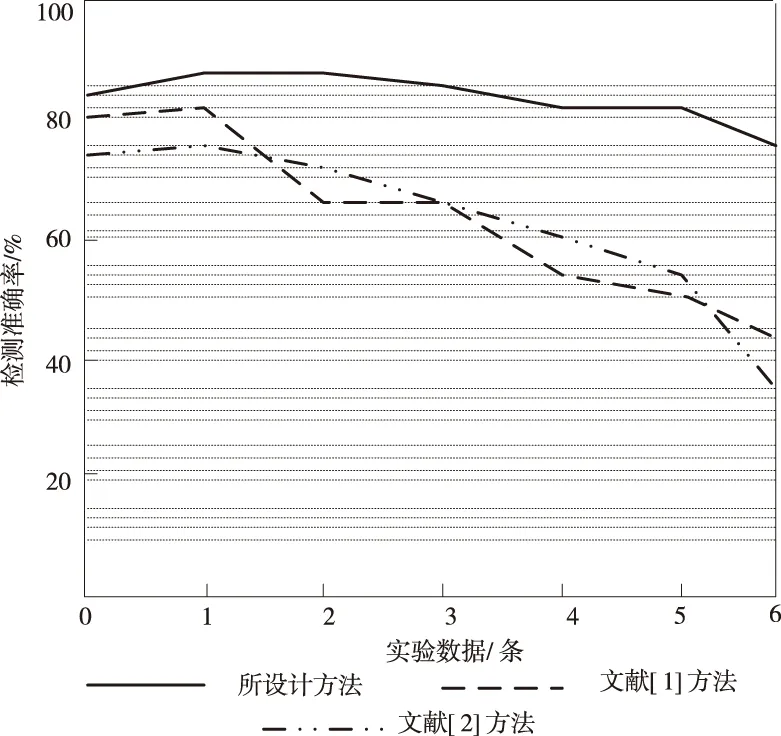
图3 检测准确率对比
分析图3可知,此次研究的云存储网络映射密文搜索的恶意域名检测方法与文献方法的检测准确率均随着检测数据量的增加而降低。经过对比可知,此次研究得检测方法的准确率虽然有下降的趋势,但是变化较小。而文献方法的检测准确率下降较快,没有此次研究的检测方法的检测效果好。
3.4 召回率对比
图4为三种方法的召回率对比结果。
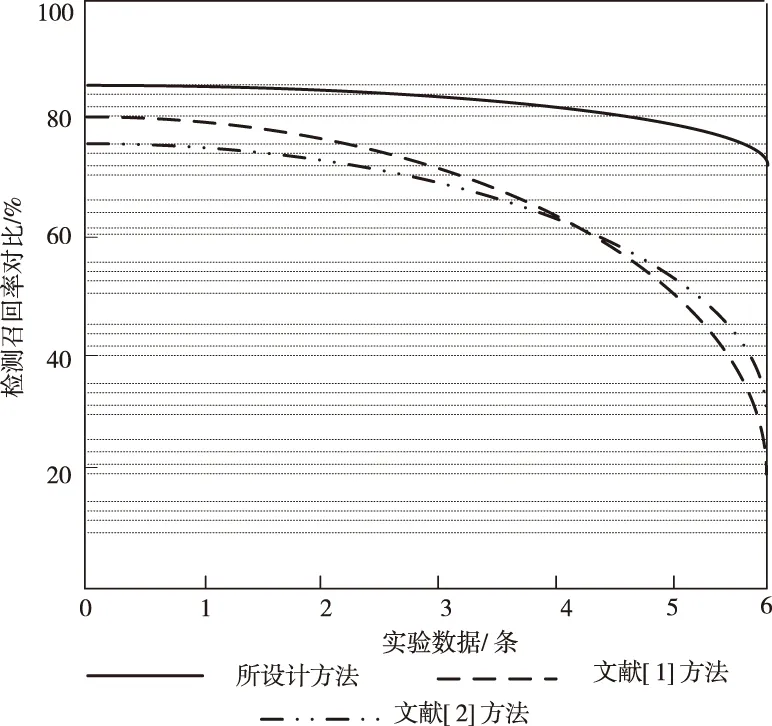
图4 召回率对比
通过图4可知,此次研究的云存储网络映射密文搜索的恶意域名检测方法的召回率效果均保持在较好的水平,受到数据多少的影响较小。而两种文献方法的召回率受到数据多少影响较大,随着数据量的增多,召回率下降速度也变快。由此可见,设计方法的召回率更高,检测精确度较好。
3.5 检测时间对比
分析三种方法对恶意域名的检测耗时,得到对比结果如图5所示。
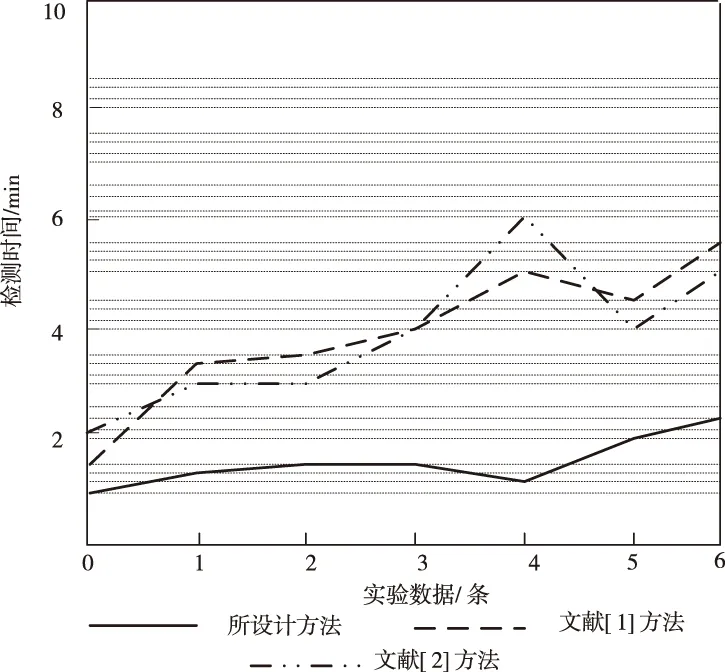
图5 检测时间对比
通过图5可知,文献[1]、文献[2]检测方法的检测时间在数据量多与少的情况下,都较此次研究检测方法的检测时间长。
综上所述,此次研究的检测方法有效提高了检测准确性与召回率,并减少了检测时间,较传统方法的应用效果更好。原因是,此次研究的检测方法预先对数据进行了采集与预处理,并采用随机森林算法对恶意域名进行了检测,从而获得了较好的检测效果,具备一定的实际应用意义。
4 结束语
为了提升网站抵御病毒攻击的能力,设计了一个云存储网络映射密文搜索的恶意域名检测方法,通过实验验证得出,所提方法不仅提高了检测的准确性以及召回率,还减少了检测时间。通过恶意域名检测,可以发现网络上的恶意域以及与这些域通信的客户端主机。研究结果可以帮助安全团队理解当前网络中的安全威胁,并采取有针对性的措施,应对主机可能感染的恶意软件。通过对恶意域名的关联分析,进一步发现僵尸网络信息和攻击者信息,这对于保护网络安全具有很好的参考价值。
但是,由于研究时间的限制,试验拓扑过程过于简单,不具备复杂的网络环境和真实的通信流。外来可以建立一个复杂的网络拓扑,引入一些实际的网络流量来验证系统的性能和防御效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年2期)2021-11-17
江苏教育研究(2020年2期)2020-04-10
江苏教育研究(2020年1期)2020-04-10
无线互联科技(2019年13期)2019-10-17
现代电子技术(2018年20期)2018-10-24
电机与控制学报(2018年9期)2018-05-14
计算机应用(2016年10期)2017-05-12
