
基于A R IM A 和LST M 的组合模型对寿险保费收入的预测
2021-12-13 07:31冯一铂
科学技术创新 2021年33期
冯一铂
(喀什大学数学与统计学院,新疆喀什 844000)
随着我国经济的繁荣发展,保险行业在国家的政策下发展迅速,人们对于保险了解的更加深入,这使得越来越多人愿意给自己及家人一份保障。因此寿险保费收入的预测,在国家、地区、公司对于下一阶段政策的制定具有重要的指导意义。
基于传统的保费收入预测方法,使用单一预测模型对保费收入进行预测。孙景云等[1]对2004-2010 年两家保险公司的寿险和财险保费收入进行预测和分析,证明了ARIMA 乘积季节模型在保费收入预测上有良好的适宜性;尹成远等[2]对1980-2010 年我国保费收入进行预测分析,通过模型预测我国“十二五”期间每年保费收入,并结合《中国保险业发展“十二五”规划纲要》做出展望;张鑫等[4]基于灰色最优化模型以东北三省为例,对保费收入进行预测,证明了经过创新改进的灰色最优模型极大地提高了预测准确度;何淑菁等[5]运用BP 神经网络对我国人身保费收入进行预测,表明神经网络模型与计量经济模型相比具有更高的预测精度。
通过查阅相关文献以及学习,发现传统模型的预测虽然有着操作简单、运行速度快的优点,但未考虑保费收入时间序列数据是线性和非线性的组合,仅是单一的进行线性或非线性预测。传统的时间序列模型只能拟合保费收入的线性时间序列部分,而神经网络算法可以任意地逼近非线性数据,所以本文将传统的时间序列模型与神经网络算法进行组合,构建线性模型和非线性模型的组合模型对保费收入进行预测,并证明组合模型的预测准确率比使用单个模型更准确。神经网络算法可以很好地拟合非线性数据,在众多深度学习模型中,LSTM 神经网络[5-6]在时序数据分析中较BP 神经网络[5-6]表现出更强的适应性,所以本文提出ARIMA 与LSTM 组合预测的方法,并利用银保监会公布的北京、天津、上海三个地区2006 年1月至2020 年12 月,共180 个月的寿险保费收入月度数据证明模型的有效性。
1 相关的模型理论及简介
1.1 ARIMA 模型
ARIMA(p,d,q)模型[1-3]叫差分自回归移动平均模型,AR 是自回归,p 是自回归项,MA 是移动平均,q 为移动平均项,d 为时间序列成为平稳时所需做的差分次数。ARIMA 模型就是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA 模型的通用表达[8]式为:
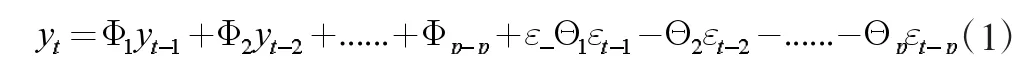
其中yt为时间序列y 的当期值,yt-1为yt前一期的值,yt-2则为yt-1前一期的值,依次类推,Φ1,Φ2,……,Φp是自回归系数,p 是自回归阶数,Θ1,Θ2,……,Θp是移动平均系数,q 是移动平均阶数,{εt}是白噪声序列。
1.2 LSTM 模型
长短期记忆网络(Long Short-Term Memory,LSTM),是递归神经网络(Recurrent Neural Network,RNN)的变型。RNN 进行训练时采用通过时间反向传播算法,为了解决在处理长期依赖时的消失梯度问题,Hochreiter&Schmidhuber 提出长短期记忆网络模型,LSTM(长短期记忆网络)相比传统的RNN,有着更为精细的信息传递机制,能有效的解决长时间的依赖问题。同时,作为Encoder-Decoder 框架中的基本细成单元,也能实现时间序列数据的编码和解码,用记忆单元代替RNN 中隐含层的LSTM 神经元实现对过去信息的记忆,每个记忆单元中包含一个或多个记忆细胞和三个门控制器,LSTM 的核心是一个记忆单元,由遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)组成,“门”结构能够控制信息在网络中的状态。“门”结构依赖于Sigmoid 激活函数,当输出为0 时,表示丢弃信息,当输出为1时,表示完全保留信息,其他情况表示保留部分信息。
1.3 组合模型
由于寿险保费收入时间序列数据比较复杂,既有线性趋势又有非线性趋势,使用单一的ARIMA 模型或LSTM 神经网络预测误差都会比较大。所以,先利用ARIMA 模型预测各地区寿险保费收入的时间序列线性部分,时间序列的非线性部分就包含在了ARIMA 模型的误差部分,然后利用LSTM 神经网络对ARIMA 的误差序列进行预测,将ARIMA 的预测值和LSTM 神经网络的预测值求和,则可得到最终的组合模型预测值。
2 实验过程
2.1 ARIMA 模型的建立
ARIMA 模型以2017 年1 月至2020 年12 月48 个月的数据作为测试集,其他月份的数据为训练集,该模型利用Python构建。
2.1.1 寿险保费收入时间序列平稳化
在使用ARIMA 模型对数据进行预测前,先通过ADF 检验即单位根检验来判断差分前后的序列是否平稳。在0.05 的显著性水平下,原始序列不平稳。分别对不同地区数据进行差分,可以看出北京、天津和上海的数据都在进行12 阶差分后数据趋于平稳,故d北京=2、d天津=2、d上海=2。随后利用自相关(ACF)图和偏自相关(PACF)图,以及AIC 最小的准则来确定p 和q 的值。
最终通过实验确定三个地区的ARIMA 模型,北京寿险保费收入的模型为ARIMA(0,2,1),天津寿险保费收入的模型为ARIMA(1,2,1),上海寿险保费收入的模型为ARIMA(0,2,1)。
2.1.2 参数估计及模型的检验
利用最大似然法进行各个阶数的参数估计,得到各阶的系数估计以及标准误差。估计结果如表1 所示。

表1 ARIMA 系数估计结果(注:括号内数值为标准误差)
对三个模型的残差序列进行Ljung_Box 检验,得到北京、天津、上海三个地区ARIMA 模型得残差序列的Ljung_Box 检验结果的p 值分别为0.983、0.369、0.479,在0.05 的显著性水平下,可以判断三个残差序列均为白噪声,表明所构建的模型是有效的。
2.2 LSTM 神经网络的建立
通过Python 的keras 库实现LSTM 神经网络的构建。使用LSTM 神经网络对各地区残差序列进行预测,同样使用2017 年1 月至2020 年12 月的数据作为测试集,并对数据进行归一化处理。选用滚动式的神经网络,将数据的时间步长(time step)都设置为12,即以前某年的12 个月为输入,第二年的第一个月为输出。考虑到寿险保费收入序列较简单,所以本文构建的LSTM神经网络,在隐藏层中使用双曲正切函数(tanh)为激活函数,迭代次数为400 次,批大小(batch size)统一设置为10。
为验证LSTM 神经网络在时序数据上的拟合效果优于BP神经网络,BP 神经网络的参数设置与LSTM 神经网络一致。通过计算指标的均方误差(RMSE)和平均误差百分比(MAPE)来判断,其结果越小越好。结果如表2 所示。

表2 LSTM 神经网络和BP 神经网络的预测结果对照
通过表3 可知LSTM 神经网络中的RMSE 和MAPE 都比BP 神经网络中的值低,表明了LSTM 神经网络在时序预测中较BP 神经网络更精确。故使用LSTM 神经网络对北京、天津、上海三个地区寿险保费收入的ARIMA 模型的残差序列进行训练和预测。

表3 ARIMA 模型和组合模型的预测结果对照
2.3 组合模型的建立与对比分析
组合模型先利用北京、天津、上海三个地区ARIMA 模型进行预测,再利用LSTM 神经网络对三个残差序列进行预测,将ARIMA 模型的预测结果与LSTM 神经网络对残差的预测结果进行相加得到最终的预测结果,预测结果如表3 所示。
通过表3 可知,组合模型较传统ARIMA 模型在RMES 和MAPE 都有明显的下降:北京地区MAPE 下降了9.8%、RMSE 下降了51.97;天津地区分别下降了4.5%、28.49;上海地区分别下降了18.7%、57.56。同时组合模型的拟合的精确度得到了提升:北京、天津、上海三个地区分别提升了33.79%、28.7%、18.77%。
3 结论
本文主要运用ARIMA 模型以及LSTM 神经网络构建了对时序数据进行预测的组合模型。利用北京、天津、上海三个地区寿险保费收入数据对模型进行验证,主要结论如下:动态神经网络LSTM 较静态网络BP 神经网络在时序预测上更精确;组合模型保持ARIMA 模型实操简单、运行速度快的基础上提升了模型的预测精度;组合模型是基于处理线性与非线性问题提出的,具有一定的可适用性,也可处理其他时序预测。
本文将传统的统计方法与深度学习技术融合,在保险金融方向利用深度学习前沿技术进行了积极探索。但本文也有值得改进的方向,包括建立的ARIMA 模型较简单,未考虑季节因素;在对ARIMA 模型和LSTM 神经网络进行组合时,组合方法不够创新,后来学者可在模型的组合上做更好的优化。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
北京航空航天大学学报(2020年10期)2020-11-14
投资与理财(2020年6期)2020-06-09
北京航空航天大学学报(2019年9期)2019-10-26
中国外汇(2019年10期)2019-08-27
