
区块链容错机制与算法研究
2021-12-14 01:37赵会群
计算机应用与软件 2021年12期
赵会群 任 杰
(北方工业大学信息学院 北京 100144)(北方工业大学大规模流数据集成与分析技术北京市重点实验室 北京 100144)
0 引 言
自从2008年Nakamoto[1]提出了比特币这种可以在点对点的交易平台使用的数字货币,其底层技术区块链[2]引起了业界和政府的广泛关注。区块链技术[3]具有去中心化、不可篡改和数据本地化存储等特性,为下一代互联网技术包括匿名在线交易的数字资产提供基础支持[4-5]。
超级账本(Hyperledger)是Linux基金会的区块链项目,致力于发展跨行业的商用区块链平台技术[6-7]。超级账本项目自创立伊始便吸引了众多行业的领头羊,包括金融业、银行、互联网行业、运输业等。其旗下的Hyperledger Fabric子项目是以IBM早期捐献出的Open Blockchain为主体搭建而成。Hyperledger Fabric是一个带有可插入各种功能模块结构的区块链实施方案,目标就是打造成一个有全社会共同维护的开源超级账本[8]。
对于Fabric区块链而言,其结构中存在两大类节点:一类是peer节点,一个网络实体,维护ledger并运行Chaincode容器来对ledger执行read-write操作;另一类是orderer节点,以先到先得的方式为网络上所有的channel做交易排序,并将交易序列放入block[9]中。对于2019年7月开源的Fabric区块链而言,其排序服务的模式共有kafka、solo和raft三种,其中kafka模式是orderer集群将交易信息发送给第三方kafka[10]服务,由其对交易进行排序;solo模式为单点orderer支撑排序服务;raft模式为orderer集群通过共识机制选举主orderer来进行交易排序。然而在后两种排序服务中,存在着一个问题,也就是本文所要解决的问题,同时也是Fabric区块链其本身体系结构存在的问题,即主orderer节点作为排序交易,并打包交易成为区块的重要节点,一旦主orderer节点受到恶意攻击或者自主宕机,其主orderer要负责排序的交易数据以及已完成打包但未及时发送出去的区块都将丢失。虽然交易数据可以重新传输,但也造成了大量时间的耗费,然而Fabric区块链系统并没有对于这样的体系结构问题作出相应的保障措施。
Fabric区块链的这种体系结构问题,属于容错问题。容错是指如何保证在出现错误时系统仍可以提供正常服务[11],通常是以牺牲系统一定的资源(包括时间、存储、计算等)为代价[12]。容错问题可以通过容错技术[13]来解决,容错技术对于系统而言是重要的可靠性保障手段[14],容错技术主要包含三个内容:故障诊断技术、故障屏蔽技术、动态冗余技术[15]。将容错技术应用到Fabric区块链中仍然存在着一些挑战。首先,在区块链领域中目前还没有容错技术的使用;其次,在一般的含有容错技术的系统中故障诊断[16]的作用都只是利用心跳机制[17-18]检测节点是否存活,缺少检测节点是否遭受恶意攻击的机制。
本文针对Fabric区块链的容错问题,设计了备用orderer节点对主orderer节点实时检测并备份恢复其业务的容错算法。在原Fabric 区块链系统的基础之上增加了可靠性机制,力争使原系统在可靠性方面得到增强。
1 相关工作
目前还未有区块链领域的容错机制,因此本文的相关工作主要选取的是容错机制在其他领域的应用。
赵镇辉等[18]对CLAIMS这个内存数据系统引入了容错机制,并提出了Fail-fast、Fail-over,以及Fail-back三种算法,即Fail-fast算法实现系统中快速发现故障节点并标记,Fail-over算法则是在标记故障节点之后,实现对受影响任务的重启,而Fail-back算法则是实现对故障节点中内存状态的恢复。对于CLAIMS系统的容错机制,测试故障节点只是通过简单的心跳机制来完成,并未对其有恶意攻击的测试方案。
Nagarajan等[19]设计一种名为Screwdriver的异常检测工具,主要的作用就是在系统被注入如高CPU、高内存利用率,磁盘已满和网络占用率高等故障之后,可以通过异常检测模块发现错误,之后利用通知服务模块生成测试报告。Screwdriver工具并未对故障模块有恢复保障机制,而只是测试异常。
孔超等[20]对Bigtable、HBase、Dynamo、Cassandra,以及PNUTS五个典型的NoSQL系统的容错机制及其实现进行分析与对比,使用的故障检测都只是单纯的心跳机制,并且在节点发生故障的时候,也是通过冗余的资源完成故障恢复,使系统具备容忍故障的能力[21],即一个master节点,三个副本节点来进行备份。同样,在此故障检测中并未含有恶意攻击的测试流程。
刘添添[22]对移动Agent系统提出了一种基于消息机制和日志记录的容错协议,即利用了容错技术中的冗余技术,实现了一个Backup agent对Agent进行故障检测及故障恢复。但此容错机制只是对于主节点进行故障检测和数据备份,一旦主节点故障,并没有及时的服务恢复机制。
段泽源[23]对大数据流式处理系统的容错机制做了研究,其系统主要依靠Zookeeper这种较成熟的分布式系统协调系统利用心跳机制对节点运行状态进行检测,之后使用定期同步节点信息到数据库的方式冗余节点信息,以便在节点失效重启时恢复节点数据。此容错机制的设计不足与文献[18]一样,都是缺乏恶意攻击的测试手段。
李军国[24]对基于软件体系结构的容错机制动态配置技术做了深入研究,其中的错误检测模块就划分多类,有心跳探测、异常捕获、接受性测试等,恢复模块也有多种,如定向器、状态重置器,以及分发器和收集器等,其整个容错模块的调用则是通过一个容错管理服务。该文将这种可动态调整的容错机制应用到了北京大学的反射式JEE应用服务器PKUAS中。这种动态调整的容错机制的确考虑到了多种故障问题的容错机制调整策略,但其并未将其容错机制应用到区块链系统中。
本文设计的容错机制不仅让其首次应用到Fabric区块链系统中,而且在其主节点故障检测模块中,在传统的心跳探测之上添加了恶意攻击的测试,为主节点增加了一道保障,并可以通过测试结果快速判断出主节点是否故障,若主节点故障之后会立即进入服务恢复模块,启动备用节点恢复主节点丢失的数据,继续保证系统正常运作。
2 算法研究
本文在Fabric中为负责排序服务的orderer,增加了备用orderer,让备用orderer主动监听主orderer的运行状态,并发送一些对应的特征测试用例,通过监听状态以及这些特征测试结果,从而判断出主orderer是否宕机或者被恶意攻击。
算法1安全可靠性测试算法
输入:主orderer的IP。
输出:主orderer的运行状态。
主orderer端:
1. 读取本地IP,并监听本地端口port;
2. REPEAT
3. IF 接收到连接请求 THEN
4. 建立连接;
5. IFreceiveMessage==特征测试用例THEN
6.Send(特征测试结果);
7.Sleep(t1);
8. ELSE
9. 等待备用节点连接;
备用orderer端:
1. 获取主orderer IP;
2. REPEAT
3. IF 连接成功 THEN
4.Send(特征测试用例);
5.Receive(特征测试结果);
6. IF(测试结果==恶意攻击特征) THEN
7. 主orderer被恶意攻击,MasterOrdererStatus=“Attack”;
8. UNTIL !MasterOrdererStatus;
9. ELSE
10. 主orderer 工作正常;
11. ELSE
12. 停止等待t2,尝试连接;
13. IF 连接失败 THEN
14. 主orderer宕机,MasterOrdererStatus=“Down”;
15. UNTIL!MasterOrdererStatus;
通过安全可靠性测试算法,备用orderer可以获取主orderer的运行状态,一旦判断出主orderer故障,那么备用orderer就要对其进行业务数据方面的恢复,后面的算法就是针对其做的可靠性保障,将其分为数据同步备份算法和服务恢复算法。
算法2数据同步备份算法
输入:主orderer的业务数据。
输出:备份主orderer业务数据的数据库。
主orderer端:
1. REPEAT
2. IF 缓存消息数量>MaxMessagesCountTHEN
//数量大于设置值
3. IF 产生新的消息队列 THEN
4.TimeBatch:=time.Now();
5.Send(batch,TimeBatch);
//发送消息队列给备用orderer
6. IF 产生新的区块 THEN
7.TimeBlock:=time.Now();
8.Send(block,TimeBlock);
//发送区块给备用orderer
9. IF 消息处理时间>BatchTimeOutTHEN
//处理时间大于设置值
10. IF 产生新的消息队列 THEN
11.TimeBatch:=time.Now();
12.Send(batch,TimeBatch);
13. IF 产生新的区块 THEN
14.TimeBlock:=time.Now();
15.Send(batch,TimeBlock);
备用orderer端:
1. REPEAT
2. IFReceive(batch,TimeBatch)==trueTHEN
3.envelope:=toByte(batch);
4.envelopeDB(TimeBatch,Msg);
//levelDB数据库,主键:TimeBatch值:envelope
5. IFReceive(block,TimeBlock)==trueTHEN
6.block:=toByte(block);
7.blockDB(TimeBlock,block);
//levelDB数据库,主键:TimeBlock,值:block
8. IFMasterOrdererStatus!=null THEN
9.TimeEnd:=time.Now();
10. IFMasterOrdererStatus==“Down” THEN
11.TimeKey:=TimeEnd-t1-t2;
//t1、t2分别为算法1的休眠时间和等待时间
12. ELSE
13.TimeKey:=TimeEnd-t1;
14. UNTIL !MasterOrdererStatus;
算法3服务恢复算法(数据库遍历查找)
输入:主orderer故障指令,数据库查找时间TimeKey。
输出:需要还原的备份数据。
备用orderer端:
1.ID:=SelectNewOrdererID();
//共识算法外接函数,从多个备用orderer中选新主orderer
2.SendTakeOverCmd(ID);
//将新主ID,发送服务接管函数,建立与peer之间的通信
3.db:=OpenFile(“DB”);
//打开DB数据库即envelopeDB 或blockDB数据库
4.dbiter:=db.NewIterator;
//建立数据库迭代器
5.i:=0;
6. REPEAT
7. IFdbiter.key>=TimeKeyTHEN
8.Copy(tmpStruct[i].key,dbiter.key);
//将备份数据暂存结构体数组中
9.Copy(tmpStruct[i].value,dbiter.value);
10.i++;
11. UNTILdbiter.next==null
12. 将tmpStrcut数据发送给peer;
算法4服务恢复算法(建立B树索引查找)
输入:主orderer故障指令,数据库查找时间TimeKey。
输出:需要还原的备份数据。
备用orderer端:
1.ID:=SelectNewOrdererID();
2.SendTakeOverCmd(ID);
3.db:=OpenFile(“DB”);
4.dbiter:=db.NewIterator;
5.BTree:=newBT(M);
//构建一个空的B树, 定义B树的阶数为M
6. REPEAT
//构建B树索引
7.Flag:=BTree.Search(dbiter.key);
//查找此key是否已经存在B树中
8. IFFlag==falseTHEN
9.BTree.Insert(dbiter.key);
//将key值插入索引
10. ELSE
11. CONTINUE;
12. UNTILdbiter.next==null
13.i:=0;
14. REPEAT
15. REPEAT
16. UNTILi>BTree.num
//i小于结点内关键字的个数
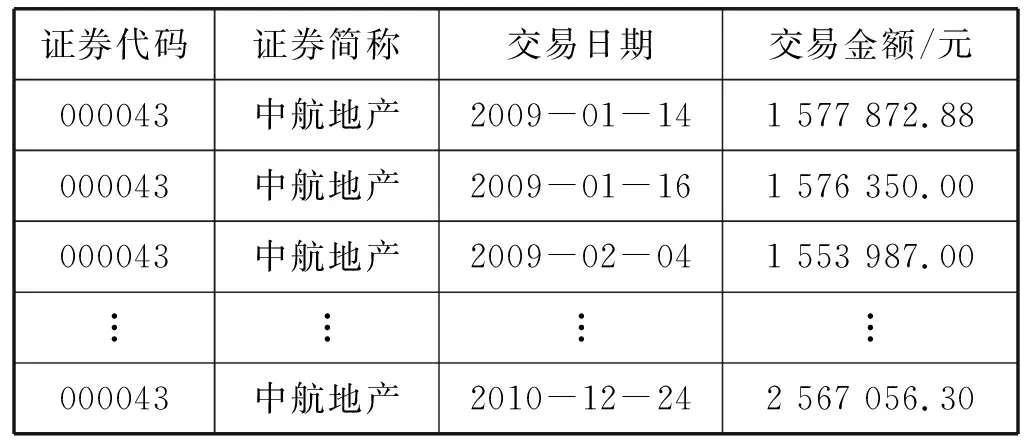
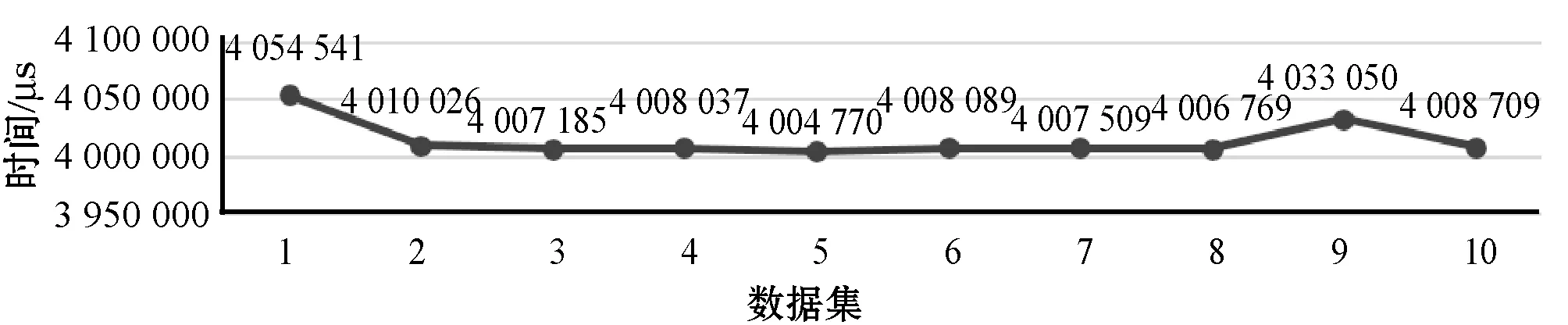
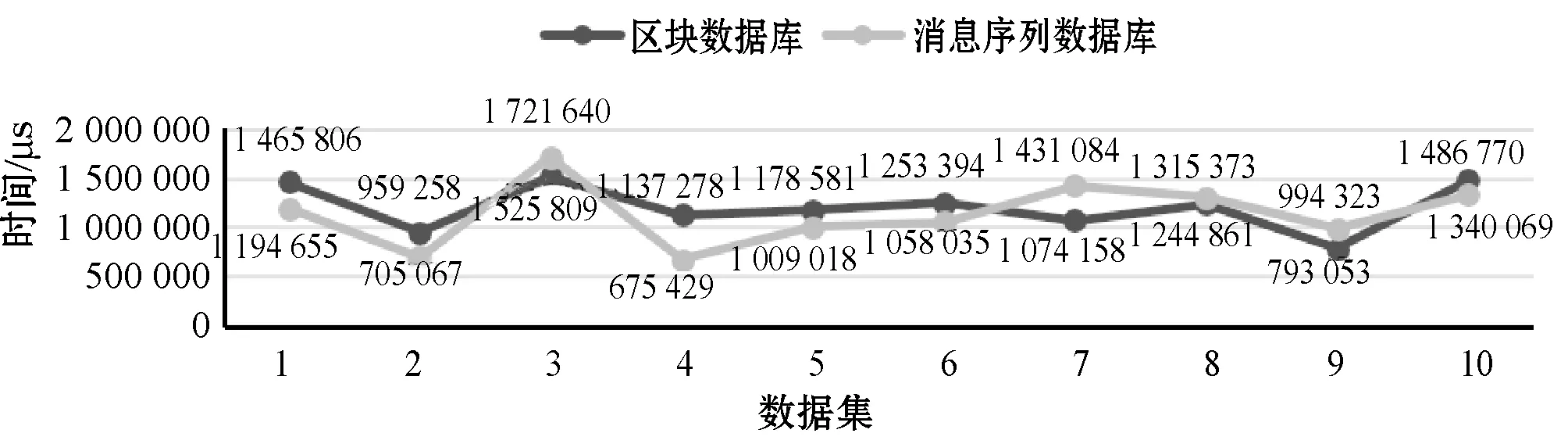
17. IFTimeKey 18.Copy(tmpStruct[i].key,BTree.data[i].key); 19.Copy(tmpStruct[i].value,BTree.data[i].value); 20.i++; 21.BTree=BTree.child[i]; 22. UNTILBTree==null 23. 将tmpStrcut数据发送给peer; 对于服务恢复算法,首先是从两个备份数据库中分别获取数据,由于数据库的主键存储是用时间戳来存储的,所以本文设计从TimeEnd-t1-t2(t1、t2来自算法1)时刻开始获取数据,将数据暂存在结构体数组中。在与peer建立连接之后,对于区块数据便将其直接发送给peer,但是对于消息序列数据需要调用orderer的CreatNextBlock()函数,打包成区块,再发送给peer。所以本文针对时间戳查找做了两种服务恢复算法,一种是数据库遍历查找服务恢复,另一种是为数据库建立B树索引查找服务恢复。 本文实验的硬件环境是一台操作系统为Linux并配置有8 GB内存、3.40 GHz CPU的电脑;软件环境是基于Fabric1.0版本,在官方给出的examples/e2e_cli案例基础之上,进行二次开发,并且e2e_cli使用的共识模式solo,在原先的2个peer组织即4个peer节点,1个orderer组织即1个orderer节点基础之上增加到4个orderer节点以及7个peer节点,指定其中主orderer和备用orderer。 本实验所需要的数据主要是peer之间的交易信息,利用peer之间进行频繁的转账操作,生成交易信息,从而提交到主orderer节点,为备用orderer的备份提供数据。 本文选取的数据集来源于国泰安数据中心[25],数据集如表1所示。 表1 中航地产证券的交易数据(部分) 本文使用的均为证券交易数据,共用了10组数据集,即十家企业证券在2009年至2010年的交易数据,每组数据集的数据量的大小如表2所示。 表2 数据集的数据量大小 首先利用实验数据模拟peer之间的正常转账场景,其中peer1作为购买证券的客户,peer2作为一家证券企业,通过cli工具执行两个peer之间的转账函数。以表1中每一行的交易金额作为每一次执行的转账金额,从而为主orderer产生需要排序、打包的交易数据,同时也会让备用orderer的备份功能运转起来,从而为备用orderer恢复主orderer业务做好铺垫。 其次是对主orderer的恶意攻击的场景模拟,主要是Linux系统中最常见的两种病毒攻击。 第一种模拟主orderer受到Ramen蠕虫[26]攻击,即让主orderer满足如下要求: (1) 存在/usr/src/.poop目录。 (2) 存在/sbin/asp文件。 (3) 本地端口27374被打开。 第二种模拟主orderer被Rootkit病毒[27]攻击,即让主orderer满足如下要求: (1) 网络占用率达到90%以上。 (2) CPU占用率达到100%。 在这种制造故障的情形下,可以观察备用orderer能否正常运转业务恢复。 在Fabric网络启动成功之后,实验过程分为以下8步。 步骤1查看备用orderer与主orderer的日志来确定它们之间是否建立连接、是否开始检测,对于测试算法中需要的特征测试用例,依据需要针对的恶意攻击特征去生成。本实验模拟的恶意攻击手段是Ramen蠕虫和Rootkit病毒,因此测试用例的生成就要依据实验场景中说明的两种病毒的特征去生成。 步骤2将peer组织中的节点和主orderer以及备用orderer加入同一通道,之后就是进行chaincode安装以及实例化,目的是制定peer之间正常交易的规则,之后就是实现peer之间的转账操作,为主orderer提供交易数据。 步骤3通过查看主orderer的实时日志,可以知道其已经接收到这些交易数据,并且已经通过接收时间的先后生成了消息序列,那么查看备份节点实时日志,是否同步备份好这些消息序列,可以通过打印envelopeDB和blockDB数据库的数据量来确定是否同步备份好主orderer的数据。 步骤4利用3.3节的病毒模拟注入,同时在算法1中t1=3 s之后,备用orderer立刻检测出主orderer受到恶意攻击,并记录TimeEnd。 步骤5备用orderer立刻停止对主orderer的检测,使用外接函数SelectNewOrdererID()获取新主orderer的ID,然后将此ID传入SendTakeOverCmd()函数,使用此函数建立与peer之间的通信,从而替换旧主orderer。 步骤6新主orderer中的服务恢复算法立刻使用TimeEnd-t1的时间作为还原数据的TimeKey,如果是主orderer自主宕机之后,就需要再减去t2。对于两个服务恢复算法,需要比较其恢复时间,因此执行步骤7、步骤8并对比其两种恢复时间。 步骤7在两种没有索引的数据库envelopeDB和blockDB中查找,遇到key值比TimeKey大的数据,就存储起来,并且记录此方法的开始时间和结束时间,计算总的运行时间,最后将需要还原的envelope数据划分为区块之后传递给peer,而需要还原的block则直接发送给peer。 步骤8通过建立B树索引的数据库来还原数据,计算此方法的运行时间。 利用10组数据集进行了10组实验,每一组数据进行一组实验,以下所有数据图中每组的接管反应时间、恢复数据量、数据库查找时间均为此组数据集多次重复实验的均值,模拟了病毒攻击,并统计了备用orderer接管主orderer业务的反应时间,反应时间基本在4 s左右,如图1所示。 图1 备用orderer的接管反应时间 统计了实验中数据恢复的数据量,如图2所示。 图2 恢复的数据量 可以看出,不同的数据集恢复的数据量大小会有所差异,主要是因为数据量的恢复取决于主orderer故障期间接收到的数据量。 统计了区块和消息序列数据库使用遍历查找的服务恢复算法所用的时间,如图3所示。 图3 数据库遍历查找恢复时间 图3刻画了在数据库中遍历查找备份数据所消耗的时间,可以看出数据集2、4、9普遍低一些,这是因为这三个数据集数据量较少导致数据库中备份数据较少。 与图3使用遍历查找算法对应的是使用B树索引查找的服务恢复算法,其恢复过程所用的时间如图4所示。 图4 数据库B树索引查找恢复时间 同样地,图4刻画了在建立B树索引的数据库找备份数据所消耗的时间,并且普遍低于图3的遍历查找时间消耗,这也说明了服务恢复算法中建立B树索引查找还是较优的。 本文为Fabric区块链增加了容错机制,并且在利用心跳机制的诊断方法之上增加了恶意攻击的测试算法,进一步完善了故障诊断技术,更加保障了主orderer的安全可靠性。当主orderer遇到故障之后造成主orderer未及时传输出去的交易数据丢失的问题,以及无法继续负责交易数据的排序及打包成区块的工作,做了相应的备用orderer恢复主orderer的保障机制。通过实验,本文算法的可用性得到了初步的验证。 由于本文提出的容错机制是首次在区块链中尝试,所以仍存在一些技术难题,如:主orderer故障之后peer对于orderer的连接还未及时切换到新主orderer上,仍继续会向旧主orderer发送数据,怎么来保证这一段时间内数据的不丢失将是今后继续研究的方向。3 实 验
3.1 实验环境
3.2 实验数据

3.3 实验场景
3.4 实验过程
3.5 实验结果


4 结 语
猜你喜欢
电脑爱好者(2021年18期)2021-09-23
电脑爱好者(2020年19期)2020-10-20
计算机世界(2020年26期)2020-07-23
红楼梦学刊(2020年3期)2020-02-06
电脑知识与技术·经验技巧(2020年9期)2020-01-16
电脑爱好者(2019年8期)2019-10-30
金桥(2018年7期)2018-09-25
当代贵州(2018年21期)2018-08-29
南都周刊(2018年6期)2018-06-23
软件导刊(2018年3期)2018-03-26
