
基于强化学习的无线传能网络节点控制算法
2021-12-14 01:28吴振宇李云雷
计算机应用与软件 2021年12期
吴振宇 吴 凡 李云雷
(大连理工大学创新创业学院 辽宁 大连 116024)
0 引 言
现代社会的发展离不开电能,而无线传能技术因其可以摆脱有线充电的特性受到广泛的关注。无线传能[1-3]可以用于轨道电车的实时供电、无线充电以及医疗器械、特种设备、无线传感网、微波飞机和空间电力输送等方面。
扩大无线传能的供电范围和供电功率一直是业内研究的重点。相比远距离广播式的直接供电,采用多个中继节点进行“多跳传输”更能够有效提高供电范围并保证供电功率。文献[4]根据上述思路提出了一种无线电能传输网络架构(Wireless Power Transfer Grid, WPTG)。WPTG是在空间上任意分布的无线节点通过无线传能这一供电方式形成的虚拟的电能传输网络,可以实时根据环境调整电能传输链路和节点自身功能角色以保证电能供给。网络主要由网络电能来源的电源节点、负责中继传输电能的中继节点以及使用电能的负载节点组成。
文献[6]在WPTG的基础上提出了一种新型的网内无中心、节点平等的无线电能传输网结构。所有节点均具有双向无线电能传输功能,既可接收电能也可以传输电能。文献[7]在上述基础上提出了一种新型自组网方法及系统。上述文献的主要研究对象都是供电链路的动态优化,对单个节点的供电策略并未有较深的研究。
本文针对无线电网各个节点的协同控制问题,设计了一种基于策略梯度的强化学习算法,该方法使用多层神经网络作为控制器,根据每个周期的供电控制状态的反馈设计了一套奖励机制用来评估控制策略的优劣,最后以最大化累计奖励为目标优化网络参数,从而达到一个较优的控制策略。
1 无线传能网络模型构建
1.1 无线传能网络
无线传能网络是基于无线供电方式的网络模型。一般根据其功能划分为电源节点、中继节点、负载节点。
无线传能系统整体采用网状架构[6],供电中心为电源节点,通过一些中间节点将电能输送到负载节点。由于无线传能网络的移动供电机制,供电受距离等因素影响较大。因此,所有节点都自带一个电能储存装置,用于缓解突发的供电不足。
无线传能网路系统算法主要分为两个部分:
(1) 无线传能网络节点之间电能传输链路的动态优化。
(2) 无线传能单个节点的控制算法。
无线传能网络电能传输链路的动态优化一般使用有向图构建网络拓扑结构,通过节点之间的电能传输效率、负荷均衡等指标构建优化节点之间边的目标函数,最后使用最短路径相关算法找到电源节点到所有负载节点的代价最小的最短路径[6-7]。本文使用了一套改进的Dijkstra算法寻找最短路径,由于这不是本文研究的主要目标,所以不做赘述。
无线传能节点的控制算法大多基于供电节点建模,然后使用后端优化算法进行控制求解[8-9],这样能够精准地控制节点达到目标状态。但对控制目标的设置缺乏深层次的思考,也无法针对各种情况进行在线优化。
1.2 单个节点的供电模型
单个无线传能节点组成如图1所示。其中,传感单元包括:传感器和数模转换模块负责收集外部地理位置信息以及自身各项电能指标;无线通信单元负责与其他节点进行通信,交换控制信息与传感器信息;处理单元负责对节点进行合适的供电控制以及存储节点运行时的数据;能量的发射接收由无线电能发射/接收单元完成,其中内置能量储存单元可以存储一定电量,保证外部供电受到限制时也可维持运行。

图1 无线传能节点组成
本文将文献[6]中的3种节点用统一的模型描述电能的流通。如果将供电节点视为高能量输入(来自发电站等设备)的中继节点,则所有类型节点的电能流通都可以使用图2所示节点模型表示。

图2 单节点电能流动示意图
每个节点有唯一的一个功率输入Pin,m个功率输出Pout=Pout,1+Pout,2+…+Pout,m,节点的自身能耗为Ps,自身能源储量E,功率输入与输出存在上限,满足下式的条件:
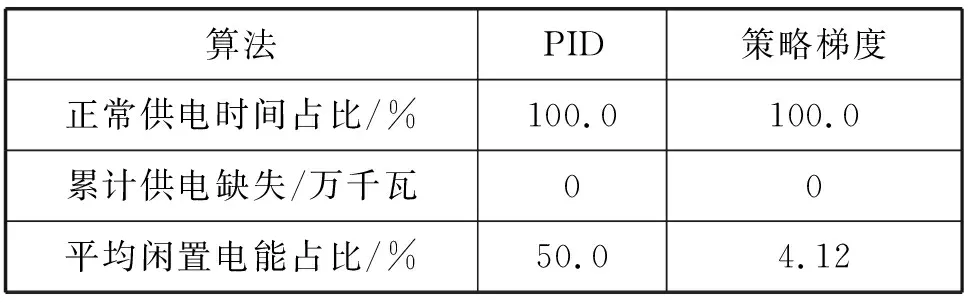
Pin (1) Pout 输入功率Pin被分成3个部分:直接送到输出的Ptin、输送到电池的Pein和自身能耗Ps。其计算式表示为: Pin=Ptin+Pein+Ps (2) 输出功率Pout由直接输出的Ptout和电池输出的Peout组成,Ptin=Ptout。对于节点自身的能源储量E,考虑到充电效率ηin与放电效率ηout,E的一阶导数为: (3) 单个节点控制目标就是满足下一级节点的供电需求,即使得实际的功率输出Pout等于下一级节点所需求的Pout need,一般情况下只需令Pout=Pout need即可达到所需目标。但考虑某时局部用电激增或节点距离供电节点较远,上层节点无法提供所需求的Pin,所以需要使用额外的自身能源进行供电。当自身电量E用完的时候,功率输出Pout就无法满足供电需求,造成局部供电不足,所以需要在其他时刻给自身能源充电。 节点自身能源不允许同时充电和放电,当Pein>0时,节点处于充电状态,此时Peout=0,当Peout>0时,该节点处于放电状态,此时Pein。 传统算法如PID在解决单点控制模型中有着非常稳定良好的表现,能够控制单点的电量稳定在目标值附近。但目标值的选取存在一定的问题,目标值选取过大会使得节点一直趋于较大电能的状态,从而造成一定的能源浪费;目标值选取过小则失去了该节点储能功能的意义,应对风险的鲁棒性较差。 在此问题背景下,本文提出了一种算法能够针对不同节点的特性,动态地学习节点的控制参数。强化学习的方法是解决这种问题的一种思路。作为机器学习的一个重要理论分支,强化学习(Reinforcement learning , RL)[8-9]是一种学习不同状态下的最优决策动作技术,以最大化智能体的长期奖励累计值。智能体是自发选择可能产生较大奖励值的动作,而不是被告知采取哪个动作最好,这也是强化学习的自我探索优势。 本文根据上述模型设计了一种基于策略梯度(policy gradient)[10-12]的节点控制算法,该方法用一个值函数表示该策略长期回报的期望,通过求出值函数关于策略参数的梯度,并使得参数沿着梯度上升的方向更新,最大化值函数,从而使得策略回报得到提升。该方法相对其他强化学习算法,具有更好的收敛属性,适用于高维度和连续的状态空间。 强化学习系统基本交互如图3所示。 图3 强化学习的基本交互 (1) 控制器根据策略函数输出动作(供电输入input)到节点设备。 (2) 节点设备按照控制器给定的供电输入与实时的供电输出需求更新自身状态,并给出该状态的奖励。 (3) 策略函数根据上一时刻的奖励提升策略参数。 本文用系统t时刻的自身能源储量Et、自身能耗Ps,t、节点的输出Pout,t和节点当前的输入Pin,t等特征来表示t时刻的系统状态st;为了减少网络波动带来的影响,并且使输出连续,将动作空间ai,t设置为{-1,0,1},分别表示将节点的输入Pin增加一个步长Δh、保持不变、减小一个步长Δh。 st=[Et,Ps,t,Pout,t,Pin,t] (4) ai,t={-1,0,1} (5) 应用强化学习算法的目的就是确定一个在状态st下选择动作ai,t的概率的策略函数πθ(ai,t|st)。 本文使用一个MLP(多层感知器)来拟合策略函数πθ(ai,t|st)。为了加快收敛速度,该多层感知器只使用两层全连接隐藏层。每层16个神经元,激活函数使用ReLU。最后输出到表示3种动作选择概率的三个神经元上。该网络模型如图4所示。 图4 MLP结构 实际运行时,使用网络输出概率最高的动作作为实际输出: at+1=argmaxaπθ(ai,t|st) (6) 环境更新e(st,at)用来计算节点在状态st下选择动作at的下一时刻状态。这个更新计算基于1.2节所述简化后的节点供电模型,表示为: st+1=e(st,at) (7) 奖励(reward)设计是强化学习算法的核心,定义了算法的学习目标。通过设计一个奖励机制r(st,ai,t)来提升策略的表现。r(st,ai,t)表示节点在状态st下选择动作ai,t的单步奖励。 当该节点自身能源储量为零,并且输入功率Pin因为受限无法满足输出功率的需求时,就会产生电能的亏空Pt;当该节点能源储量为满,并且输入功率Pin满足输出功率的需求还有额外剩余时,就会产生电能的饱和Pm。本文算法希望尽量减少电能亏空和电能饱和的出现,所以将它们设置为负的奖励。常规情况下,本算法希望尽量减少自身能源的储量,将闲置电能用在其他该用的地方,所以使用递减的log函数去拟合。其计算式表示为: (8) 式中:κ、λ、μ为可调系数,并且1<λ<κ,0<μ<1。 策略提升的目的是为了最大化累计奖励J(θ),将J(θ)作为目标函数,如下式所示: (9) 将目标函数J(θ)使用蒙特卡洛近似的方法进行替换,再对MLP的各层参数求梯度,可得: (10) 式中:τ为可能存在的策略函数与环境的交互轨迹;θ为MLP神经元之间的参数;N为动作空间的维度;T为使用策略与环境进行交互的轨迹长度。 然后使用上述梯度更新网络参数θ,使策略得到提升,其更新计算式为: θ=θ+▽θJ(θ) (11) 该算法中,控制器不断地与环境(节点)交互,根据交互结果的奖励更新神经网络(MLP)的参数,MLP又作为控制器输出控制结果。最终通过不断学习,从而最大化交互奖励,找到较优的控制策略。该算法流程如算法1所示。 算法1策略梯度节点控制算法 初始化所有模块 随机初始化神经网络参数θ 更新各节点状态s while True: #程序运行主循环 #定期更新网络参数 for step in range(period) 策略函数πθ根据当前状态s输出动作a 节点执行动作a更新自身状态s 奖励机制根据更新后状态s计算奖励r 存储执行的中间结果s、a、r到S、A、R end 根据S、A、R计算策略提升的梯度▽θJ 更新神经网络参数θ end 本实验的所有程序都是在Python3.6上运行,算法的运行环境为Intel(R) Core(TM) i5-6500, CPU@3.2 GHz,16 GB内存,Microsoft Windows 10操作系统。 本文用电数据使用2010年南京市居民夏季用电负荷作为单个节点的输出需求(output_need)。该数据可以按天近似视为周期性变化,在每天的12时至20时出现用电高峰,峰值为0.4万千瓦。仿真实验将绘制各指标的变化曲线,并统计50个周期的相关数据进行对照。实验将本文算法与一般PID算法效果做对比。PID算法计算方式如下: (12) err(k)=E(k)-α (13) Pin=u(k)+Pout (14) 式中:err为控制误差;E(k)为当前能源储量百分比;α为目标能源储量百分比,设置为50%;u(k)为控制量,计算节点输入Pin时需要加上节点输出Pout;Kp与Ki、Kd为可调系数,分别为10.0、3.0、0.01。 (1) 正常运行状态对比测试。为了测试该算法在一般情况下的表现,本文设置参数如下:节点最大能源储量为5万千瓦时,最大输出1万千瓦,初始能源储量为65%,初始输入输出均为0.2万千瓦。将节点最大输入功率设置在0.5万千瓦,大于节点的功率输出需求(output_need)峰值0.4万千瓦,节点在任何时候都能够得到充足供电。测试结果如图5、图6和表1所示。 图5 策略梯度算法测试(max input=0.5万千瓦) 图6 PID算法测试(max input=0.5万千瓦) 表1 正常运行状态结果统计表 如图5所示,节点实际供电输出(output)与节点输出需求(output_need)一直处于重合状态,说明节点一直可以满足下一级的用电需求,正常运行。如表1所示,上述正常供电时间占比为100%,没有产生供电缺失。闲置电能占比指的是储存在节点自身,没有参与电能流通的电能占节点总能源储量的百分比。本文算法经过学习后得到的策略迅速降低节点的能源储量(energy)到一个较低的百分比(4%),符合本文奖励机制中的第三种情况:正常运行时,降低闲置的电能,使整体能源分布更为合理。 如图6所示,节点实际供电输出(output)与节点输出需求(output_need)也一直处于重合状态,节点正常运行,节点也能够将自身能源储量维持在50%附近。但基于PID的传统算法只是将节点电量维持在目标值附近,传统算法不能够预测该节点的输出需求特征,仍然需要节点保持50%的能源储量才能够正常运行。本文算法在该情形下可以降低91.76%的闲置电能,并能够正常运行。 当然,如果在这个实验中,传统算法PID将自身电量的目标值改为5%,也能够在较小的最大能源储量下正常工作。但传统算法并不能够实时地学习到输出需求(output_need)的特征,从而改变自己的目标值。而这个基于输出需求的目标值,正是本文算法所能够学习到的特征。 (2) 输入功率受限状态对比测试。为了测试该算法在功率受限情况下的表现,将节点最大输入功率设置在0.3万千瓦,小于节点的功率输出需求(output_need)峰值0.4万千瓦。其他参数同上保持不变,测试结果如图7、图8与表2所示。 图7 策略梯度算法测试(max input=0.3万千瓦) 图8 PID算法测试(max input=0.3万千瓦) 表2 功率受限状态结果统计表 如图7所示,策略梯度控制的节点实际供电输出(output)与节点输出需求(output_need)一直处于重合状态,说明节点一直可以满足下一级的用电需求,正常运行。而在每天20时用电高峰来临时,如图8中黑框所示,节点输入功率受限,PID算法控制的节点实际输出(output)小于节点输出需求(output_need) ,产生了供电不足,供电缺失时间占比6.77%,累计供电缺失达25.66万千瓦。如表2所示,本文算法相比PID控制算法减少了99.4%的供电缺失时间以及99.9%的供电缺失量,能够保证节点的正常运行,仅提高了4%的闲置电能。 上述仿真结果综合表明,以PID为代表的传统控制算法,由于缺乏历史数据的积累,无法对节点的输入需求进行预测。只能将节点的输入需求这一不可控因素当成了随机的外部扰动,从而缺乏一些相对应的控制策略,具体控制效果出现了一定的滞后性。其未能预测到20时用电高峰的来临而提高节点供电输入(input),增加自身能源储量。当用电高峰出现时,节点输入功率受限,当前节点的能源储量不足,导致供电不足。 而本文算法能够学习一些不规则的周期性供电需求的特征,能够根据实际情况和控制目标自动寻找到较优的策略。如图7中黑框所示,本文算法预测到用电高峰的来临,提高节点用电输入(input),提前进行蓄电,从而避免了用电高峰的供电缺失,即使一次用电高峰需要用到节点最大能源储量的80%电量,节点依然能够正常运行。 为了解决无线传能网络中的节点控制问题,本文提出了一种基于策略梯度的节点控制算法。该算法主要基于强化学习与数据驱动,与传统算法截然不同。该算法只要设计好节点状态更新的奖励就可以基于交互数据生成合适的控制策略。仿真实验表明,该算法尤其适合周期性变化的供电需求下的节点控制,并且能够针对不同状态,自主学习到较优的控制策略。即使在一些极端情况下,也能有较好的表现。本文最终验证了该算法相对于传统算法的优越性。2 无线网络节点供电控制算法
2.1 策略梯度
2.2 基本交互流程

2.3 状态空间与动作空间
2.4 策略函数

2.5 环境更新
2.6 奖励设置
2.7 策略提升

2.8 算法流程
3 实验与结果分析
3.1 实验环境
3.2 仿真测试





4 结 语
猜你喜欢
建材发展导向(2022年18期)2022-09-22消费电子(2022年6期)2022-08-25新视线·建筑与电力(2021年6期)2021-11-27舰船科学技术(2021年12期)2021-03-29人大建设(2018年2期)2018-04-18科学启蒙(2017年3期)2017-04-10发明与创新·大科技(2016年10期)2016-10-22中学生数理化·中考版(2016年2期)2016-09-10中学生数理化·八年级物理人教版(2016年5期)2016-08-26中学生数理化·八年级物理人教版(2016年5期)2016-08-26
