
基于一维卷积神经网络的恶意代码家族多分类方法研究
2021-12-14 01:28玄佳兴韩雨桐廖会敏魏博垚
计算机应用与软件 2021年12期
王 栋 杨 珂* 玄佳兴 韩雨桐 廖会敏 魏博垚
1(国网电子商务有限公司(国网雄安金融科技集团有限公司) 北京 100053)2(国家电网有限公司电力金融与电子商务实验室 北京 100053)3(中国科学院信息工程研究所 北京 100093)4(首都师范大学信息工程学院 北京 100048)
0 引 言
恶意代码家族分类研究可理解为不同的恶意代码是否源自同一套恶意代码或是否由同一个作者、团队编写,是否具有内在关联性、相似性。而以深度学习为代表的人工智能技术则被认为能够在恶意代码分析方面发挥重要作用。
Yuan等[1]利用受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)对多层感知机预训练,对安卓恶意软件的检测准确率从79.5%提升至96.5%。李盟等[2]使用n-gram频次信息以及各API间的依赖关系,提出一种提取恶意代码语义动态特征的方法。Jung等[3]结合了多层感知机与循环神经网络(Recurrent Neural Network,RNN)对恶意flash进行检测,以文件头(Headers)、标签(Tags)、指令操作码(Opcodes)、API调用序列为特征,达到98.33%的检测准确率。Pascanu等[4]将系统事件序列视为文本序列,使用循环神经网络和回声网络(Erasmus Student Network,ESN)进行降维,使用最大池化配合逻辑回归分类的方法,检测准确率比3-gram方法更好,提高到98.3%。Saxe等[5]在40万恶意样本数据集上训练一个四层感知机二分类模型,达到95%分类检出率、0.1%误报率。David等[6]以样本沙箱分析报告为特征,分解报告到单词级别后,将20 000维的输入向量降维嵌入至30维,使用k-近邻(k-Nearest Neighbor,kNN)分类,准确率从95.3%提升至98.6%。乔延臣等[7]对恶意样本汇编代码进行文本词向量分析,并将分析特征结果转化为图像送入CNN进行分类,实现了98.56%的分类准确率。Yakura等[8]在卷积神经网络分类恶意样本的基础上引入了注意力机制。
以上工作通过对恶意代码的静态特征进行提取,或者通过沙箱运行进行动态特征提取,建立恶意代码的特征模型,有一定的主观选择性和时间空间开销,相比恶意样本的图像信息获取成本要高,序列信息也会丢失恶意代码本身的某些空间特征。恶意代码图像特征的概念,最早是由Nataraj等[9]于2011年提出的,将恶意代码的二进制文件转换成灰度图像,再结合GIST特征来进行聚类。Cui等[10]基于恶意样本字节码的灰度图像对恶意样本变种进行分类,但准确率不够高。恶意样本图像是一种可以高效处理的恶意样本特征形式,但是既有方法会造成信息丢失;卷积神经网络对图像有良好的分类效果,但恶意样本图像处理不当会引入额外的局部相关性。这两点都会影响恶意代码分类效果。
本文的主要贡献包括以下几个方面:
1) 研究恶意代码图像特征映射和优化,提出改进的恶意样本图像缩放算法(Improved Malaware Image Rescaling,IMIR),实验证明,IMIR会提高恶意代码多分类能力。
2) 基于一维特征图像的卷积神经网络(One-Dimensional Convolutional Neural Network,1D-CNN),构建高效的恶意代码分类模型1D-CNN-IMIR。
3) 通过在公开的恶意代码数据集上进行大量对比实验得出1D-CNN-IMIR准确率达到98%。
1 恶意样本图像特征提取和优化
1.1 恶意样本图像特征提取
恶意样本预处理的方式多种多样,其中恶意样本灰度图像[9]预处理容易、耗时短。如图1所示,在不依赖反汇编的情况下,将恶意样本的8位二进制数据转化为目标图像的一个像素,或者说一个一维灰度图像。

图1 恶意代码特征图像映射
恶意样本是一维的,而卷积神经网络解决的问题大多是关于二维图像的,从一维样本转换成二维图像必然会导致关于恶意样本特有的空间局部相关性的错误。如果人为地将其转为宽度为w的二维图像,如图2所示,箭头指向了在两种维度情形下的相同数据,在原图像中距离为w的若干点就会被重排到一列上,距离被拉近,在后续的模型中被识别为局部相关点群,而这些点之间却可能并不存在所期望的空间局部相关性。
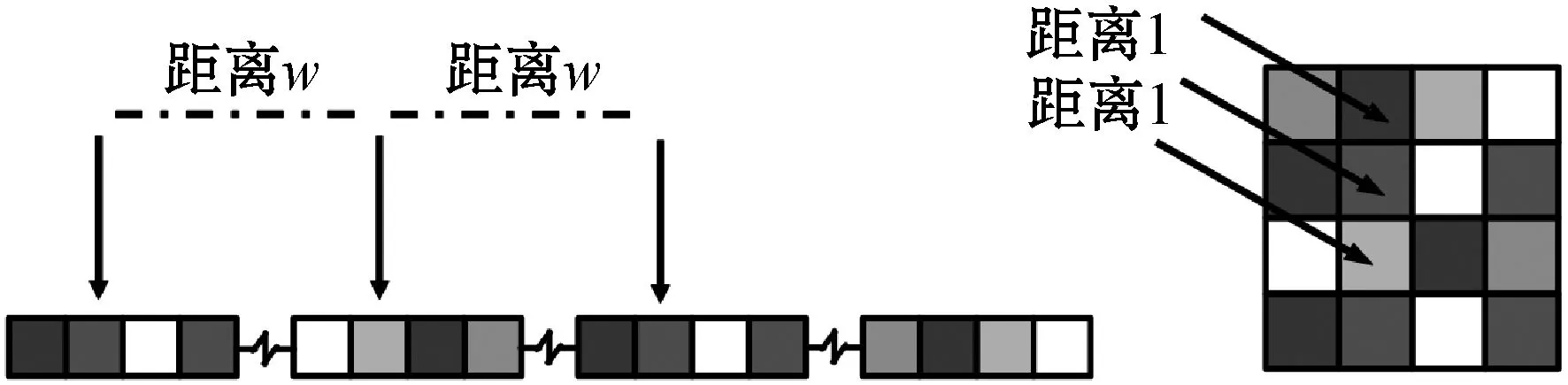
图2 局部相关性变化示意
距离相近的点具有空间局部相关性是卷积神经网络的主要特征之一。距离的定义决定了卷积方式,错误的距离定义将误导分类网络,使其从恶意样本图像上不相关的点中捕获额外的错误空间局部相关性,最后导致过拟合,降低分类性能。为了缓解过拟合,去除了宽度设置,不进行图像维度变换。
1.2 改进的恶意样本图像缩放算法
深度学习模型处理图像信息前需要对多尺度的图像进行规范化。Cui等[10]使用类似双线性插值算法的三线性插值算法。双线性插值算法被广泛用作默认的图像缩放算法。文献[10]也使用双线性插值对恶意样本图像进行了规范化处理。但是双线性插值缩放在规范化图像时有大量的信息损失,会影响后续分类效果。因此,提出改进的恶意样本图像缩放算法(IMIR)。
IMIR算法将采样点的范围从最近的若干个点提升至整个滑动窗口内的点,再调整了滑动方式使其更适合恶意样本图像,且没有增加额外耗时,1万个样本耗时约1 min。在数据集中最小的样本大小是32 KB,恶意图像大小标准取4 096 KB。
IMIR算法基于局部均值算法,不同于真实图像,每一个恶意软件映像的像素同样重要,所以应该尽可能完整地捕获每个字节的信息,避免信息丢失。将范围扩展到采样窗口的边界,调整步幅计算方法和添加填充步骤以适应本地均值恶意软件图片。IMIR算法伪代码如算法1所示。
算法1IMIR算法
输入:任意代码原始图像,目标图像大小targetSize。
输出:具有targetSize大小的恶意代码图像rescaledImg。
sourceSize=size(sample)
stepWidth=(sourceSize-1)/targetSize+1
fullNum=(sourceSize-1)/stepWidth
blankNum=targetSize-1-fullNum
halfLen=(sourceSize-1) modstepWidth+1
fullPart=∅
foreachi∈[0,1,…,fulNum-1]do
fullPart=fullPart+[mean(sample[stepWidth*i,stepWidth*i+1,…,stepWidth*(i+1)-1])]
endfor
halfPart1=sample[stepWidth*fullNum,stepWidth*fullNum+1,…,stepWidth*fullNum+halfLen-1]
halfPart2=repeat(0,stepWidth-halfLen)
halfPart=[mean(halfPart1+halfPart2)]
blankPart=repeat(0,blankNum)
returnfullPart+halfPart+blankPart
//两个数组之间的“+”表示连接符
2 一维卷积神经网络构建
1D-CNN使用VGG模型[11]设计恶意代码分类器。如图3所示,该分类器包含五组伴随最大池化层的卷积层、三个使用dropout的全连接层、一个不使用dropout的全连接层和作为输出的Softmax层。

图3 恶意样本分类1D-CNN结构
使用IMIR算法缩放至4 096像素的恶意样本一维图像作为输入,图3中stride 1使用ReLU函数作为激活函数以缓解梯度消失[12],并提升训练速度。输出9个恶意代码家族标签的概率向量。在此以交叉熵作为损耗函数,如式(1)所示,并使用Adam优化器将其最小化到训练数据上。
L=-Ex,y~datalnP(y|x)
(1)
式中:P(y|x)表示将恶意样本x分类至家族标签y的概率向量。
3 1D-CNN-IMIR模型设计和实验环境配置
模型首先对恶意样本进行图形化处理,利用改进的图像缩放方法进行预处理,然后利用一维卷积神经网络进行识别,输出恶意代码家族分类如图4所示。

图4 1D-CNN-IMIR模型结构
3.1 实验数据集
实验数据集采用的是微软2015年公开在数据竞赛平台Kaggle上的恶意样本数据集Microsoft Malware Classification Challenge[13],该数据集广泛用于恶意样本研究中,便于同其他研究对比算法效果。数据集共有10 868个样本,分为9个家族,包含了蠕虫、木马、后门程序等多种恶意样本,表1详细展示了各个样本集的数量与种类。其中每个样本提供了两种文件,一种是asm文件,另一种是bytes文件,如图5所示。

表1 Microsoft Malware Classification数据集

图5 数据集中两种文件内容示例
3.2 实验评价指标
实验评价选用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和错误率(Error)这四个指标。具体来说,假设在被检测方法判断为家族a中,实际不属于家族a的数量为FP,实际属于家族a的数量为TP;在被检测方法判断不属于家族a的样本中,实际为不属于家族a的数量为TN,实际为家族a的数量为FN。准确率、精确率、召回率、错误率的定义分别如下:
(2)
(3)
(4)
E=1-A
(5)
此外K折交叉验证(K-Fold Cross-Validation)是能较好地衡量泛化性能效果的一种数据集划分方法,在实验中,统一设置K=5。
4 实 验
使用Adam优化器训练卷积网络,Adam能更快地到达全局近似最优解,节约训练时间,更有利于调整模型参数,具体参数如表2所示。

表2 模型训练参数
4.1 IMIR算法有效性对比实验
使用IMIR算法对恶意样本图像特征进行规范化处理。使用双线性插值做对比实验,选择k近邻算法(k Nearest Neighbor,kNN)、支撑向量机(Support Vector Machine,SVM)、基于二维图像的卷积神经网络(2D-CNN)、1D-CNN-IMIR,对比验证IMIR算法对恶意代码特征处理的有效性和1D-CNN-IMIR分类准确性。
由表3的数据显示,对于kNN分类器,IMIR相对双线性插值极大地降低了分类错误率;对于SVM分类器,IMIR相对双线性插值的错误率提高了1.29百分点,这是因为相比kNN,SVM对特征要求较低一些,因此特征工程算法改进影响会变小;对于两种CNN分类器,因为分类器本身有良好性能,所以错误率都不高,这种情况下进一步降低错误率已经较为困难,然而相比双线性插值算法,不论是使用1D-CNN或2D-CNN,IMIR仍然将错误率降低近三分之一,说明IMIR对CNN分类器有效。

表3 不同分类器(5折交叉验证)错误率(Error)对比(%)
在同时使用IMIR算法情况下,1D-CNN相对2D-CNN的错误率进一步降低一半,说明一维卷积神经网络确实更加适合恶意样本图像特征的分析;而1D-CNN与IMIR的算法组合相对2D-CNN-双线性插值的算法组合错误率降低了62.5%,说明1D-CNN-IMIR算法是有效的。
4.2 1D-CNN-IMIR模型对恶意代码检测实验
统计最优方法组合1D-CNN-IMIR对各个恶意代码家族分类效果如表4所示。平均准确率和召回率分别高达97.50%、98.65%,普遍高于97%,最差也达到了90%,说明了分类模型基本未对某些特定家族偏斜,整体较为有效可靠。

表4 基于1D-CNN-IMIR的图像分类实验(%)

续表4
4.3 1D-CNN-IMIR与其他深度学习算法的对比实验
为了确保结果的客观性,将1D-CNN-IMIR算法与其他深度学习分类算法对比研究,均在相同数据集上使用5折交叉验证。AE-SVM[14]、tDCGAN[15]、Strand[16]是恶意样本字节码或灰度图像特征维度上实验效果最好的方法,而MCSC[17]是基于反汇编的效果最好的研究之一。
从表5可以看出,1D-CNN-IMIR相比其他四个工作,不需要反汇编或沙箱监控过程,但却显著地提高了分类准确率,达到98.94%;即使与需要反汇编的MCSC相比,1D-CNN-IMIR准确率仍然略占优势。这说明了1D-CNN-IMIR对海量恶意样本的快速分类有明显的实际意义。

表5 相关研究准确率对比
5 结 语
本文从样本特征提取、分类网络结构、数据利用三方面对现有基于深度学习的恶意代码分类研究进行了改进,提出了恶意样本专用的图像缩放算法IMIR,设计了基于一维卷积神经网络的恶意样本分类器模型。经过实验验证,三者协同工作,可以减少模型构建与使用的时间代价,提高更新效率,增强时效性。下一步的工作是引入生成对抗网络,实现小样本标签情况下的半监督对抗生成网络,补偿样本标签缺乏导致的分类准确率下降。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
新课程·上旬(2019年1期)2019-03-18
软件导刊(2017年4期)2017-06-20
教师·中(2017年3期)2017-04-20
