
稠油井智能转周分析技术研究及应用
2021-12-14 07:16杨耀忠赵洪涛马承杰张继庆
油气地质与采收率 2021年6期
杨耀忠,赵洪涛,马承杰,岳 龙,赵 峰,张继庆
(1.中国石化胜利油田分公司信息化管理中心,山东东营 257000;2.中国石化胜利油田分公司石油开发中心,山东东营 257000)
稠油油藏约占全世界已发现石油资源的2/3。由于稠油的黏度高、流动性差,造成稠油开采难度大,对开发技术要求高,目前热力开采依然是稠油开发的主要方式[1-4]。胜利油田探明热采稠油储量为6.8×108t,已动用5.5×108t,近年来稠油年产量平均为440×104t,约占油田总产量的1/5,是油田增储上产的主阵地之一。经过多年的开发,胜利油田稠油油藏普遍进入高轮次吞吐阶段,周期产量和油汽比逐轮次下降,开发效果逐渐变差。相比水驱开发,稠油井产能相对较高,但稠油注汽转周的措施费用和运行成本较高。对于注汽转周时机的确定与优化是影响稠油油藏效益开发的关键,主要通过两种方法实现:一种是基于油藏数值模拟方法预测蒸汽吞吐周期产量[5-6],结合动态经济评价,确定最佳稠油注汽转周时机,该方法需要通过CMG 等软件模拟与生产实际联动,技术要求高,难以大规模矿场应用;另一种方法是通过人工经验进行稠油注汽转周周期的确定,依赖于技术人员的水平,大多数稠油井的产量和效益难以达到预期指标。随着大数据和人工智能技术的进步,通过对稠油井智能转周分析技术的研究,探索解决稠油开发生产中的稠油注汽转周措施方案编制周期长、稠油注汽转周时机不准、措施增油效果不佳等问题的方法。以胜利油田胜科采油管理区稠油井为例,建立大数据模型样本库,采用神经网络技术预测稠油井产量和效益,通过分析稠油注汽转周井影响产量和完全成本的因素,预测稠油注汽转周井的产量和效益。经过2021 年近1 a 的应用,共注汽转周165 口井次,比2020 年同期措施有效增油率提升了约17%,提高了稠油注汽转周措施方案的编制效率和开发效益。
1 神经网络算法优选
以神经网络为代表的人工智能算法具有自学习能力、复杂分类功能和联想记忆功能等优点,在油井产量预测中有着广泛的应用[7-10]。通过对稠油注汽转周预测的算法进行研究,结合各种神经网络算法的特点,优选适合稠油注汽转周井预测的神经网络算法。
1.1 梯度提升回归算法
梯度提升回归(GBDT)算法是一种迭代的决策树算法,通过构造特征刻画序列的周期和趋势效应,利用Boosting 方式得到回归结果。研究证明某些情况下其预测效果优于传统时序预测方法,适用于预测小区级别的天粒度、小时粒度的短期流量数据。
1.2 自回归差分移动平均模型算法
自回归差分移动平均模型(ARIMA)算法是在平稳的时间序列基础上建立起来的,适合预测短周期的流量数据。将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归建立模型。
在建立稠油注汽转周预测模型时,所采用的数据是跨年度、月度和日度的海量数据。如果直接基于GBDT 和ARIMA 算法构建预测模型,则会由于时间粒度周期短和时间周期记忆不稳定等问题,导致稠油井周期数据无法正常学习,难以精准预测稠油井产量和完全成本。
1.3 长短时记忆神经网络
长短时记忆(LSTM)神经网络是一种改进的循环(RNN)神经网络,它能够保存数据样本间的顺序关系,即每一次决策都参考了上一次的状态。通过学习历史数据趋势,预测未来的发展趋势。
LSTM 神经网络既能较好解决RNN 神经网络梯度消失问题,又能提高多元时间序列的建模能力。因此,采用LSTM 神经网络对数据中的特征进行挖掘和学习,能够得到比较理想的稠油注汽转周预测模型。主要步骤包括:①对所选数据集进行相关性分析,并建立数据模型样本库。②通过选取部分稠油井数据作为训练集和验证集来进行交叉验证,并保留一部分测试数据对数据模型进行评价。③在选取多区块稠油井数据进行交叉验证时,出现对于低产量的稠油注汽转周井预测准确率不高的问题,采取对产量和完全成本等异常数据进行筛选和删除的方法,优化生产时间和注汽周期等相关参数,完善稠油注汽转周预测模型。
2 数据处理与稠油注汽转周预测模型构建
提取稠油井各周期的生产参数,对数据进行样本标定,利用大数据技术,建立稠油注汽转周预测模型,该模型包含产量预测和完全成本预测两个功能。根据稠油井的注汽及生产情况,预测未来30 d的生产情况;结合产量和完全成本,筛选出未来30 d从产量和完全成本角度需要稠油注汽转周的井,并按稠油注汽转周时间的紧迫性分级预警。
2.1 数据选取
收集试点区块400余口稠油注汽转周井的生产数据,共计5 300 余轮次,83 万余条结构化数据。原始数据为日度数据的形式,特征个数为70,通过累积产液量、注汽量、生产时间、排量和井口温度等数据项进行较为全面的因素分析。
区别以往只依赖专家经验对获取的特征参数进行分析,利用相关性分析、专家经验和实际预测效果比较相结合,选取适合大数据模型训练的稠油注汽转周井的23万条生产数据作为特征样本数据。
采用Pearson(皮尔逊)相关系数矩阵,排除人为选取参数的干扰,以稠油井静、动态历史参数为基础,通过相关系数量化各参数对注汽周期内产量的影响程度[9],确定新的影响因素,为本区块稠油井的后续稠油注汽转周预测模型的制定提供参考。
Pearson 相关系数用来衡量两个数据集合是否在一条直线上,从而判断定距变量间的线性关系。相关系数的绝对值越大,相关性越强。相关性强度判断标准为:[0,0.2]为极弱相关或无相关,(0.2,0.4]为弱相关,(0.4,0.6]为中等程度相关,(0.6,0.8]为强相关,(0.8,1]为极强相关。据此计算各参数与产量和完全成本的相关系数,确定相关性。
2.2 产量和完全成本相关性分析
将稠油井产量和完全成本业务字段作为主要目标值,将累积产液量、注汽量、生产时间、排量和井口温度等作为产量的相关业务字段,将生产时间、泵深、冲次、冲程、日产液量、日产油量和井口温度等作为完全成本的相关业务字段,分别计算Pear⁃son 和Spearman 相关系数。对稠油井动、静态数据表的业务字段进行筛选,计算它们与产量和完全成本的业务相关性。
2.2.1 产量相关性分析
首先,通过Pearson 相关系数矩阵分析,识别影响参数,再与专家经验和实际预测效果相对比,选取适合大数据模型训练的特征参数。分析45 个参数的相关系数计算结果,从中选取相关系数绝对值大于等于0.016 的参数作为产量的训练输入特征,即累积产液量、注汽量、井口温度、注汽干度、焖井时间、生产时间、排量和回压等13个参数(图1)。

图1 产量主要影响参数相关性计算结果Fig.1 Correlation calculation results of main influencing factors of production
2.2.2 完全成本相关性分析
在产量数据分析的基础上,选择5 口井对其进行完全成本相关性分析。通过将业务相关数据代入到Pearson 和Spearman 相关系数计算模型中进行相关性分析,分析相关系数计算结果,选取相关系数为0.07~0.43 的作为完全成本的训练输入特征,相关性参数包括:生产时间、泵深、冲程、冲次、回压、含水率、上行电流、下行电流、耗电量、井口温度、日产液量和日产油量共12个参数(图2)。

图2 完全成本主要影响参数相关性计算结果Fig.2 Correlation calculation results of main influencing factors of full cost
2.3 样本及数据质量分析
2.3.1 样本质量分析
蒸汽吞吐稠油井一个周期内分为排水期、高峰期、稳产期和递减期4 个阶段[11-12]。排水期的产量较低,含水率较高;高峰期,产量较高,达到峰值,含水率迅速下降;稳产期,生产周期较长,产量和含水率基本平稳,该阶段是保证油井整体效益的根本;由于前期消耗导致地层压力亏空,递减期的动液面下降较快,产量降低较快。这4个阶段的产量呈现不同的特征,需要对样本数据进行相应处理。
区别以往人工样本标定,对23万条稠油注汽转周井的生产数据实现样本自动分割和标定,即按时间序列自动识别每口井递减阶段,并提取成样本,每一周期数据为一个样本。因稠油井生产时间长,产量随着注汽转周措施的实施而波动,因此每口稠油井样本不适合直接作为训练样本进行输入,需要将每口井的历史生产数据进行样本标定,将1 口井标定为多个样本,形成最终的训练数据(图3)。

图3 CQC128-P14-0井训练样本集1Fig.3 Training sample set1 of Well CQC128-P14-0
为准确预测日度生产情况,对周期样本进行二次样本标定,即以各个周期为界限,每20 个数据为一个样本,进行迭代样本标定(图4)。
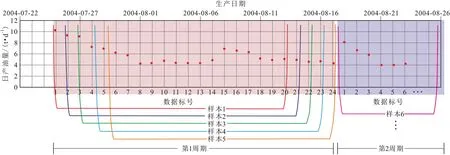
图4 周期样本二次标定Fig.4 Secondary calibration of cycle samples
2.3.2 数据预处理和数据质量分析
数据预处理主要包括:①数据清洗。主要是剔除原始数据集中的重复数据,平滑噪声数据,处理缺失值和异常值等。②数据集成。将多个数据源中的数据结合起来并统一存储。③数据变换。通过平滑聚集、数据概化和规范化等方式,将数据转换成适用于数据挖掘的形式。④数据归约。通过数据集成优化方式,不但能够产生更小但保持原数据完整性的新数据集,而且能够减少无效、错误数据,以及大幅缩减数据挖掘所需的时间、降低储存数据的成本。
数据预处理一方面是要提高稠油注汽转周井产量数据的质量,另一方面是要让数据更好地适应稠油注汽转周预测模型。在稠油注汽转周产量样本数据的处理过程中对试算井数据进行质量分析,对关井期间和排水期或其他原因导致的异常数据进行清理。如C-X425稠油井,通过对该井第1周期数据进行分析,找出生产周期内的返排水期异常数据以及下泵转抽作业关井、停电以及上作业等导致的异常数据(图5),进行数据清理和归约,以确保样本库数据的准确性和可靠性。

图5 C-X425稠油井第1周期数据预处理方法示意Fig.5 Schematic diagram of preprocessing method for firstcycle data of C-X425 heavy oil well
2.4 稠油注汽转周预测模型构建
通过采用大数据人工智能技术进行多种算法测试,找到适合稠油注汽转周规律的预测算法,再结合稠油注汽转周的历史产量数据和影响相关性的主要特征参数,构建稠油注汽转周预测模型,从而准确预测稠油注汽转周产量。
LSTM 神经网络通过“门”结构实现信息的处理功能,使用sigmoid 函数和按位乘法的操作,经过遗忘门、输入门、记忆门和输出门的逻辑结构处理,对样本库标定数据进行计算,实现预测目标。“门”结构逻辑算法通过以下4步来实现(图6)。

图6 LSTM神经网络的逻辑门结构示意Fig.6 Logic gate structure of LSTM neural network
第1 步,遗忘门。遗忘门的工作就是接受上一个单元模块传过来的输出值,并决定要保留和遗忘哪个部分,在第t时间步记忆单元遗忘层的值ft的计算公式为:
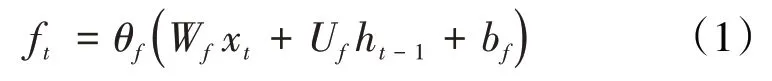
第2 步,输入门。输入门的工作是根据上一次输出和本次输入来计算当前输入的单元状态,当第t时间步输入的信息通过输入门,在第t时间步记忆单元输入层的值ot和隐藏层状态的值ht的计算公式分别为:

第3 步,记忆门。记忆门的工作是用来控制是否将在第t时间步的数据并入单元状态中的控制单位。记忆单元隐藏层状态Ct在第t时间步的计算公式为:
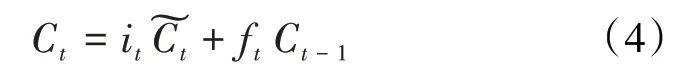
第4 步,输出门。输出门的工作是决定有多少输出信息可以传递到后面的神经网络中。在第t时间步记忆单元输出层的值it和最终记忆单元的输出值的计算公式分别为:
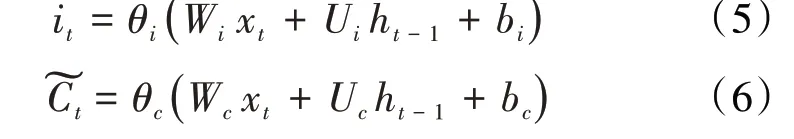
2.5 预测模型应用效果
草4沙四区块位于东营凹陷南斜坡东段乐安油田中区,是胜利油田胜科采油管理区所辖稠油区块中油井数最多、产量最高的单元。探明石油地质储量为670×104t,50 ℃地面脱气原油黏度为1 000~26 000 mPa•s,属于中高孔、中高渗透、具有弱边水的层状构造稠油油藏,开发方式主要为注氮气辅助蒸汽吞吐开发。该单元于2005 年投产,2005 至2009 年为产能建设阶段,累积投产新井80 口,阶段累积产油量为42.2×104t,2009 至2012 年为稳产阶段,阶段累积产油量为75.7×104t,2012 至2019 年为产能逐渐递减阶段,2020 年该单元已有稠油井120口,年产油量为6×104t,占石油开发中心稠油产量的18.1%。目前由于该单元稠油井的平均注汽转周达12轮次,地层压力下降,含水率上升,措施效果逐渐变差,单元产量逐渐下降,开发难度加大。
通过选取2020 年1—10 月胜科采油管理区60口稠油井日度生产数据进行预测分析,识别影响样本库的相关性的主要参数,利用相关性分析、业务经验和实际预测效果比较相结合,选取适合预测模型的生产数据,并在45个日度生产数据和注汽参数中优选出生产时间、泵深、排量、冲程、转速、回压、日产液量、含水率、电流和井口温度等22 个参数作为测试相关性的主要参数。
将测试数据集和其对应的关键参数作为LSTM神经网络的输入样本,并对稠油注汽转周预测模型进行测试,获得稠油井产量预测模型及月度完全成本预测模型,随机抽取样本的80%作为LSTM 神经网络预测样本库模型,从而准确预测周期产量及完全成本。表1为胜科采油管理区稠油注汽转周产量预测样本库,表2 为2021 年某月度胜科采油管理区完全成本预测样本库。
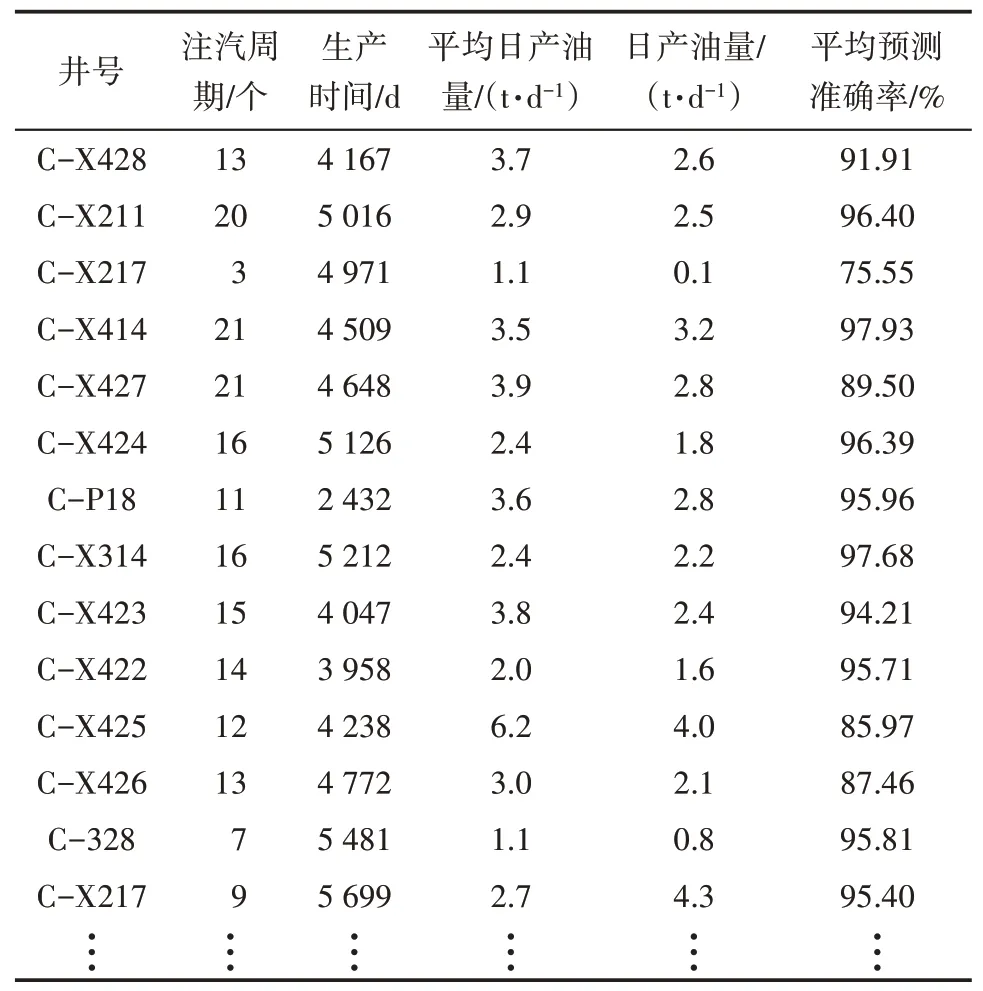
表1 胜科采油管理区稠油注汽转周产量预测样本库Table1 Sample database of production prediction after steam injection cycle of heavy oil in Shengke oil production management area
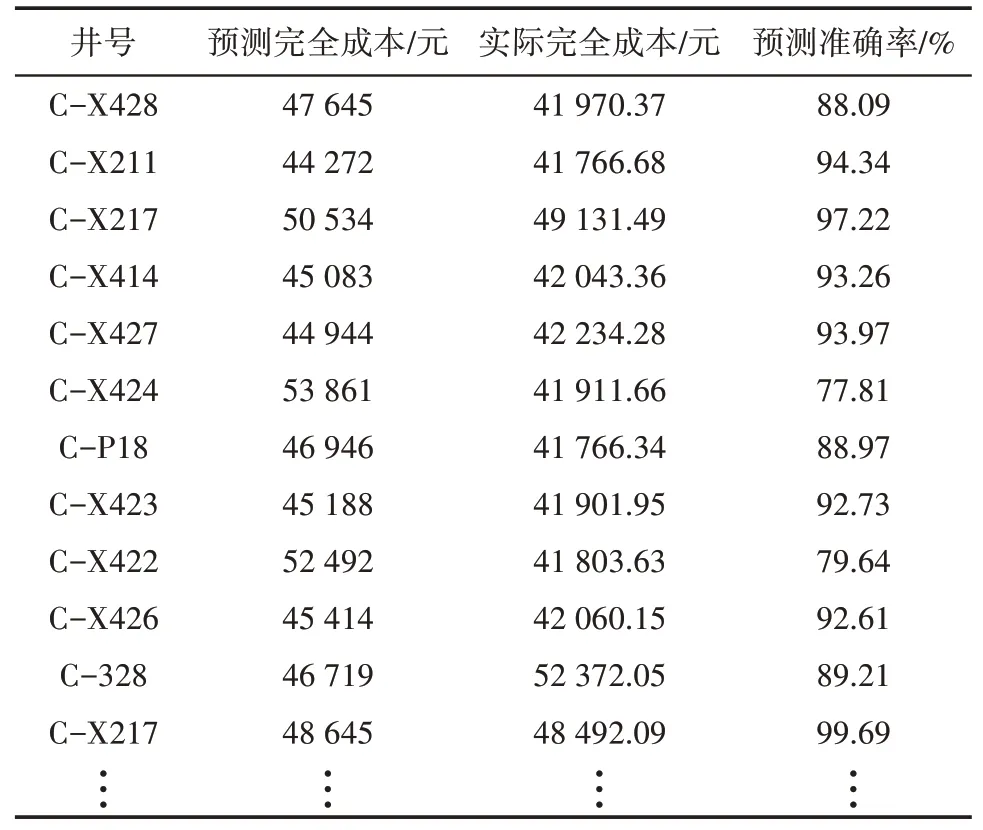
表2 2021年某月度胜科采油管理区完全成本预测样本库Table2 Sample database of full cost prediction in a month of 2021 in Shengke oil production management area
2.6 稠油注汽转周预测模型优化
系统根据源头数据更新频率对稠油井从产量和完全成本两个维度进行稠油注汽转周时机预测,为采油管理区相关技术人[员提供快捷的分析预测服务。采用2020 年1—10 月胜科采油管理区的稠油注汽转周井数据进行预测分析,发现油井产量低于2 t 的预测准确率小于70%。通过对稠油注汽转周预测模型的反复测试,确定影响稠油低产井预测准确率主要包括2 个因素:①异常数据点。②影响油井产量低于2 t的相关性参数。为此,对稠油注汽转周预测模型进行优化,主要优化环节为输入特征的优选和模型参数优选。输入特征的优选主要包括增加或剔除特征值及特征融合,模型参数的优化主要是优化模型迭代次数、学习率及模型结构等。
按照稠油注汽转周预测模型的优化流程(图7),将2021 年1—10 月稠油注汽转周的165 口井的数据通过剔除异常产量数据和优化影响油井产量低于2 t的相关性参数的方式进行进一步预测。
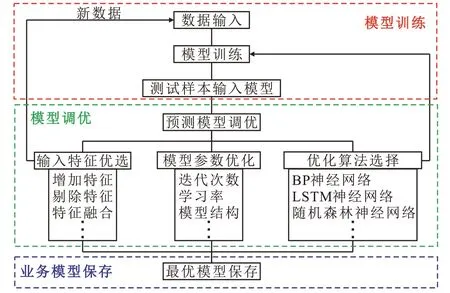
图7 稠油注汽转周预测模型优化流程Fig.7 Optimization process of predictive model for steam injection cycle of heavy oil
稠油注汽转周预测模型经优化后,预测准确率明显提升,例如C-X424 井第7 周期产量预测,模型优化前产量预测准确率仅为74%,对输入特征参数重新进行优选后,准确率提升至96%(图8)。

图8 C-X424井第7周期产量预测结果对比Fig.8 Comparison of predicted seventh-cycle production from Well C-X424
3 应用实例
3.1 稠油井产量预测
用胜科采油管理区165口稠油井进行稠油注汽转周预测模型的验证,其中C-211 和C-X427 等116口稠油井产量预测准确率大于等于90%(图9a,9b),占总井数的70%(图9d);C-X425等140口稠油井产量预测准确率大于等于80%(图9c),占总井数的85%(图9d)。
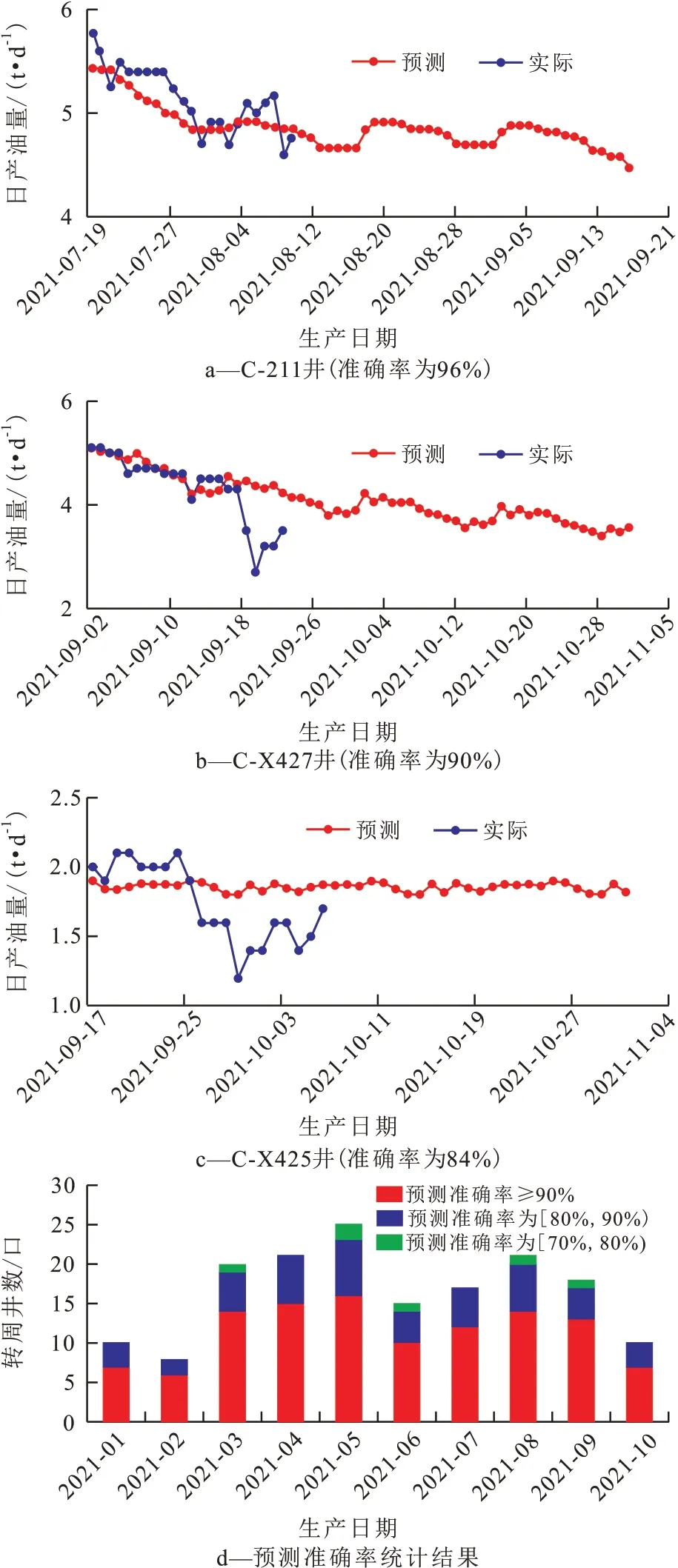
图9 预测产量与实际产量对比Fig.9 Comparison between predicted production and actual production
3.2 稠油井完全成本预测
结合实际业务需求,通过对稠油井完全成本构成进行分析,确定模型构建方法和技术路线,按照稠油注汽转周井的完全成本进行模型构建。
通过科目费用归类及影响参数调整和模型优化,对165口稠油注汽转周井进行完全成本预测,其中C-1 等140 口井的完全成本预测准确率大于80%(图10),占总井数的70%。

图10 C-1井完全成本预测Fig.10 Full cost prediction of Well C-1
3.3 稠油注汽转周预测效果分析
稠油注汽转周的产量和完全成本预测模型的应用效果主要体现在以下三点:①稠油注汽转周措施方案的编制时间由原来3~5 d缩短到1~2 d。②通过对产量和完全成本的预测,可计算出稠油井的效益转周有效期,提高了稠油注汽转周措施有效率。③截至2021 年10 月,稠油注汽转周井措施增油量为7×104t,2020年同期同区块措施增油量为6×104t,措施增油量增加了1×104t,措施有效增油率提升约为17%。实践证实,LSTM 神经网络算法比较适合稠油井生产经营规律的预测分析,稠油注汽转周预测模型可提升油藏经营的效益和效率。
4 结论
结合稠油注汽井周期性生产的特点,采用LSTM 神经网络对稠油注汽转周井的产量和完全成本进行智能预测,解决了稠油井计划转周顺序和数量,以及注汽转周措施方案的优选等难题。针对稠油注汽转周预测模型构建中参数相关性分析和样本筛选等难点,在相关系数矩阵计算分析中增加了注汽转周相关性参数,更加完整地找出影响稠油井产量和完全成本变化的相关性参数,样本数据筛选采用单周期和多周期样本数据标定,确保了样本数据的准确性。经过反复测试和迭代优化,提高了稠油注汽转周预测模型的精准度和可靠性。首次将完全成本预测经营指标应用在油藏经营分析决策中,提高了采油管理区生产经营决策的科学性。通过2021年在胜科采油管理区应用,措施有效增油率提升约为17%,稠油注汽转周井的措施方案编制效率提升了1倍。
符号解释
bc——隐藏层中的常数;
bf——遗忘层中的常数;
bi——记忆单元中的常数;
b0——输出层中常数;
Ct——记忆单元第t时间步隐藏层状态;
ft——第t时间步记忆单元遗忘层的值;
ht——输入层第t时间步记忆单元隐藏层状态的值;
it——第t时间步记忆单元输入层的值;
ot——第t时间步记忆单元输入层的值;
t——隐藏层记忆单元的时间长度;
Uc——隐藏层中上一时间步输出值对应的权重;
Uf——遗忘层中上一时间步输出值对应的权重;
Ui——记忆单元中上一时间步输出值对应的权重;
U0——输出层中上一时间步输出值对应的权重;
V0——输出层中隐藏层状态对应的权重;
Wc——隐藏层中输入对应的权重;
Wf——遗忘层中输入对应的权重;
Wi——记忆单元中输入对应的权重;
W0——输入层中输入对应的权重;
xt——第t时间步时的输入;
θc——隐藏层激活函数;
θf——遗忘层的激活函数;
θh——对隐藏层状态值的激活函数;
θi——输出层激活函数;
θ0——输入层激活函数。
猜你喜欢
化工管理(2022年14期)2022-12-02
中国石油石化(2021年8期)2021-07-20
电子制作(2019年19期)2019-11-23
钻井液与完井液(2018年5期)2018-02-13
钻井液与完井液(2018年5期)2018-02-13
当代化工研究(2016年6期)2016-03-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
天然气与石油(2015年3期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
