
基于文本挖掘技术的电子商务网站个性化推荐分析
2021-12-17 09:08张昊
电子制作 2021年22期
张昊
(湖北第二师范学院计算机学院,湖北武汉,430205)
Web文本挖掘主要是为了能够在Web页面内成功提取关键知识信息,个性化推荐就如同“信息找人”这一方式,想要提高个性化推荐的精准率,就要保证信息有效性这一重要基础,所以文本挖掘作为如今个性化推荐中的热门研究话题[1]。Web文本挖掘技术作为多样化的个性化推荐中分支,包括了建立特征表示,提取重要文档,进行聚类分析以及计算相似性。以往利用空间向量模型表示文本,最终的推荐结果准确度不高,并且关键文本的判断推理能力不强,无法有效优化个性化推荐集[2]。不仅如此用户在访问电商网站存在自身兴趣爱好改变的可能性,因此需要一种精准性更高的文本挖掘技术,来对用户的变化及时跟踪且及时响应。本文就此提出基于文本挖掘技术的电子商务网站个性化推荐技术,提高电商网站的推荐精准性。
1 基于Web文本挖掘推荐模型
自信息运动论在学术界提出后,就上升了“信息”概念至“全信息理论”,一定程度上代表获取信息资源,完成开发且加以利用的全过程[3]。在Web访问的过程中也作为产生信息的运动过程,用户在每一次访问过程中都会在Web服务器中留下信息,也就是挖掘对象与传统推荐模型相结合,加入Web文本挖掘、BM25F模型内,在电商网站平台构建个性化推荐模型(见图1)。

图1 基于Web挖掘的个性化推荐模型
根据上文建立此模型分为上、下两部分,上面主要为了对Web服务器数据结构进行分析,完成服务器日志预处理,成功提取事物集并运用模型计算文本表示与权重,通过聚类分析得到Web文本文档集。下面主要经Web数据预处理,对用户会话进行分析,对不同会话内不同Web页面中关键特征词条的权重。之后运用该模型中夹角余弦完成会话和Web文本文档集的相似性结果,计算得出个性化推荐集[4]。
2 文本词条获取
■2.1 挖掘服务器日志
挖掘文本数据作为提取访客的页面访问日志,提取相关页面的核心关键词,用于对用户网页访问行为兴趣的跟踪依据。
首先分析电商网站的页面结构,通常包括了菜单索引、商品详情、导航栏、服务说明等模块,其中关联个性化推荐的功能即商品信息展示[5]。由于如今提取关键词条技术仅仅能够获取文本内容,包括了商品详情,且为了可以更快捷的在平台网站中成功检索此商品,多数内容都要利用爬虫技术优化。
再者提取用户的交易事务,其中包含了过滤数据、识别用户和会话的步骤,数据过滤主要是为了对无关、错误数据进行清洗,通过清洗这些数据有助于减少后续形成个性化推荐的聚类分析负荷。用户识别文本就是利用cookie技术跟踪访客,有着极高的技术可行性,但是不足之处就是存在关闭浏览器cookie的可能性。假若发生此种情况运用SessionID技术,会在访客访问中产生动态化唯一标识,可是无法记录用户的重复性访问行为。会话识别主要用于区分用户的单一访问,用户登录电商网站后会自动获取单一会话,对会话行动进行跟踪假若30分钟以上并无任何活动就会自动断开。
■2.2 提取特征词条
文本挖掘的首要核心任务即在访问页面中提取文本特征词条,如访客在网站中产生的一系列页面访问A1,A2,A3,...,An,对n个网络页面内获取每页核心词条,能够实时掌握用户的不同行为偏好及具体变化情况。需要运用分词技术来获取特征词条,但是难处就在于最大化消除歧义,在中文语法内断句不同歧义就会有所不同[6]。为了对这一问题妥善解决,如今CRFs算法作为常规中文分词用法,基于条件随机域算法CRF基础上演变形成。此算法居于线性序列,在给定A参数 (λ1,λ2,λ3,...λn)的线性链CRFs对应序列X=x1,...xr中Y=y1,...,yr状态的条件概率公式如下:

公式(1)内XZ作为归一化因子,能够将全部状态序列概率与均作为二值的特征函数,相应的权重为[7]。
此模型算法能够较好的解决如今中文分词内可能遇到的相关问,那么解决此问题也为后续特征词条的提取打下良好基础。因为发生此词条的对应所在位不同,那么重要度也就有较大差别,所以需要对应重要度权重位进行划分。本文划分了网站一个页面包括标题、内容、meta描述标签以上3个域,权重分别对应0.5,0.3,0.2。所获取每个页面内的排名前六词条,用于表示当前页面,词条量过少则代表整体页面,如果过多就必然加大后续的聚类分析负荷。
■2.3 特征词条聚类分析
在提取对应特征词条后,转变完整交易事务为特征层词条为表示的词条组,多个交易事务会形成相关矩阵,对于单一页面特征词用T={t1,t2,t3...tn}表示,完整交易事务用Page={p1,p2,p3,...pm}表示,那么表示单一页面的特征词条权重公式如下[8]:
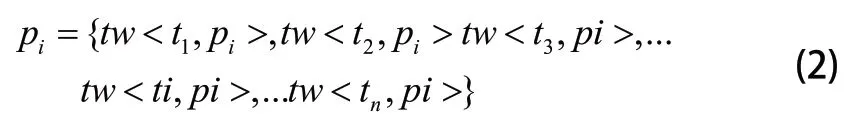
聚类分析算法主要是为了对于特征词条之间相似基础上,完成目标数据分类,最终成功凝聚接近相似数据。本文选用层次聚类分析寻找相似点高的用户群,以聚类分析结果为依据,可以相互推荐相似兴趣点的用户购买行为。对于最后的推荐排序问题,可以对比用户在电商平台的购买结果,以及购物车、收藏夹内的清单情况,假若存在重复可以进行清洗。之后依据用户的相似群内商品相似度作为排序依据,为了确保用户最终满意可以选择推荐数量直至恰当。
■2.4 匹配文档形成个性化推荐
使用Web文本挖掘技术跟踪网站服务器日志,对跟踪结果完成预处理,形成处理后的用户会话U={u1,u2,u3,...um},ui表示类似上节pci,具体的计算公式如下:
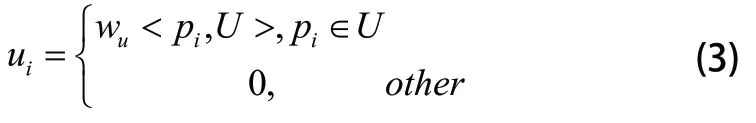
计算ui中,wu
针对聚类分析中所在页面的交易事务权重表示公式如下:

对用户会话U、文本文档pc之间相似性结果进行计算,本文使用夹角余弦公式:
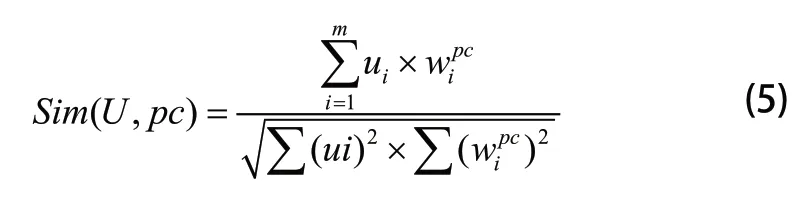
根据以上计算过程可以产生最终的推荐结果,所得每个页面推荐值主要包括两部分,分别是相似值和权重值。
3 实验分析
本文为了对比提出基于web文本挖掘技术的个性化推荐模型应用实效,选用某模型Java变成和Apache Tomcat6.0服务器,以及MySQL数据库,所开发的电商网站为实验平台,建立个性化推荐模型。将本文提出此模型对比传统TF*IDF方法,根据最终的个性化推荐结果精准率、召回率,证实本文提出此个性化推荐模型的应用效果。召回率作为推荐结果内包含相关文档所占整个集合的相关文档比例,精准率作为在个性化推荐结果文档的占比。
运用TF*IDF计算因为Web文本特征为特征词集合,分析特征词个数逐渐增加精准率和召回率比较,实验由3个特征次数逐渐增加18个对比精准率与召回率(见图2、图3)。
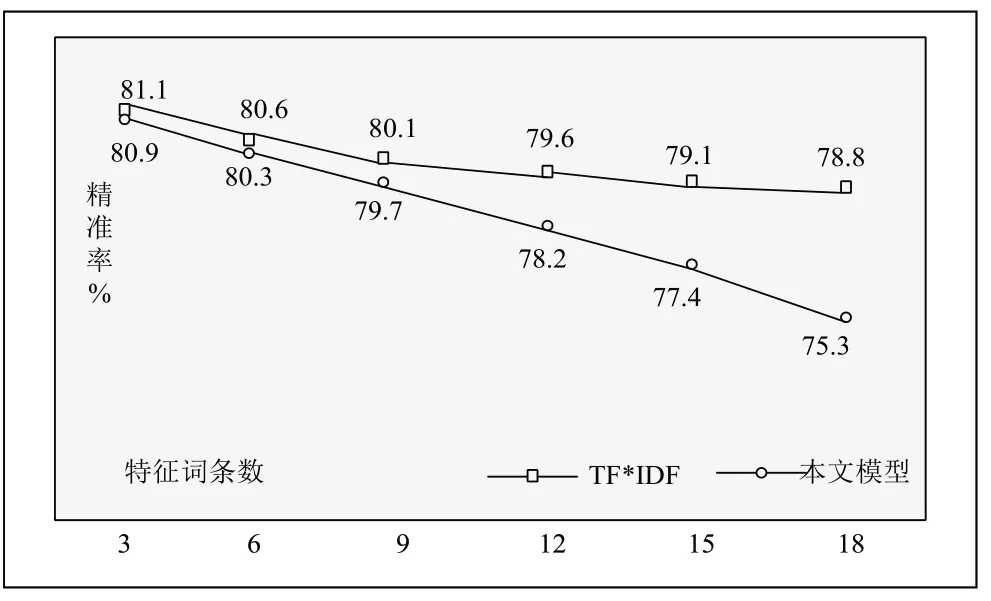
图2 精准率

图3 召回率
经对比分析两种模型精准率、召回率逐渐衰减,根据精准率相较本文建立个性化推荐模型下降率逐渐平缓,最终计算结果发现本文该模型较传统TF*IDF模型的计算结果明显优,精准率呈平缓下降趋势,可以很好的解决传统算法中个性化信息推荐滞后这一问题。在召回率方面随着词条量的逐渐增加,最终计算结果都呈明显下降趋势,但是本文提出该模型的结果始终更高。但是要注意的一点就是需要严格控制特征词条的数量选择,假若词语过多也会一定程度上降低最终结果的有效性。
4 结语
总而言之,本文提出基于Web文本挖掘技术的电商网站个性化推荐模型,在实验中发现通过挖掘服务器日志、提取特征词条,并对特征词条进行聚类分析,最后匹配文档形成个性化推荐结果以上过程。在实验中与TF*IDF相较本文提出的个性化推荐模型,能够有效解决传统算法中个性化信息推荐滞后的问题。但是本模型也存在一定不足之处,由于文中划分电商网页的3个“域”,所以对模型的计算复杂度进一步加剧,也要增强和解决服务器的日志过滤,都作为后续要解决的重要问题。
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
文苑(2020年4期)2020-05-30
电脑知识与技术·经验技巧(2020年3期)2020-05-07
小天使·四年级语数英综合(2015年7期)2015-07-06
网络与信息(2009年9期)2009-10-30
中学生物学(2008年2期)2008-07-07
雕塑(1998年3期)1998-06-28
