
基于K-means的改进协同过滤算法
2021-12-22 09:18吴婷婷李孝忠刘徐洲
天津科技大学学报 2021年6期
吴婷婷,李孝忠,刘徐洲
(天津科技大学人工智能学院,天津 300457)
互联网上信息资源的爆炸式增长给用户带来了信息过载问题,不明确的用户需求更是对搜索引擎提出了更大的挑战[1–2].针对这一问题,推荐系统作为一种高效便捷的自动化筛选信息工具受到广泛关 注[3].已有的推荐系统可分为基于内容的推荐、基于关联规则的推荐、协同过滤推荐、混合推荐[4].在目前的推荐系统中,基于协同过滤的推荐算法使用范围最广[5],具有较高的研究和发展价值.常用的协同过滤推荐算法主要有两类[6-7]:(1)基于用户的协同过滤(user-based collaborative filtering,User-based CF)算法,通过用户的历史行为判断用户对项目的喜爱程度,根据不同的用户对同一项目的偏好计算用户之间的关系,并在具有相同偏好的用户之间进行项目的推荐;(2)基于物品的协同过滤(item-based collaborative filtering,Item-based CF)算法,根据计算不同用户对不同项目的喜爱获得项目之间的关系.但是在使用协同过滤推荐算法中存在着数据稀疏、用户相似度不高等问题,导致推荐结果的准确度较低. Kanimozhi[8]通过对商品进行聚类,较大程度上缩小了商品的最近邻居搜索范围,提高了算法的运行效率.但是,该算法并没有利用用户对商品的评级信息,忽视了用户的历史行为记录,从而导致了推荐结果准确性的提高存在一定程度的限制.Tsaic等[9]将协同过滤算法与聚类算法相结合,有效地提高了推荐系统的准确度,但是在计算用户的相似度时仅使用了皮尔森相似度公式,存在着用户相似度可能不高的问题.李顺勇等[10]将K-means聚类算法运用到协同过滤算法中,并利用改进的相似度公式寻找用户的邻居集合,在一定程度上提高了推荐结果的准确性,但是在运用相似度公式时未考虑用户共同评级的影响.岳希等[11]先用基于用户的协同过滤算法对用户未评价的项目进行预测,然后将预测分数对原始用户-项目评分矩阵进行填充,从而缓解了数据的稀疏性.但是第一次运用协同过滤算法时采用皮尔森相似度进行计算,导致预测评分存在一定的偏差,影响原数据的准确性以及后续的推荐结果.Feng等[12]在计算用户相似度时考虑多种因素的影响,提高了用户之间相似度性.但是计算较为复杂,计算量较大,影响算法的整体效率. Koohi等[13]将模糊聚类融合到协同过滤算法中,得到最 佳的推荐结果,但是在数据量较大时,要获得确定 的聚类结论可能有一定的困难,影响用户之间的相 似度.
本文主要针对基于用户的协同过滤算法中的用户相似度计算部分以及K-means聚类算法进行改进.相似度公式主要考虑用户之间共同评分的项目的数量以及不同用户针对同一项目评分标准之间的差异这两个影响因素,进而提高用户之间的相似度;聚类过程中主要在K-means聚类算法的基础上引入了二分K-means聚类算法,从而提高聚类结果以及推荐结果的准确性.
1 基础工作
1.1 基于用户的协同过滤算法
基于用户的协同过滤(User-based CF)算法于1992年提出并在邮件过滤系统中应用成功,1994年被研究机构GroupLens在新闻过滤中成功使用,直到2000年成为了推荐系统领域中应用最广泛的算法之一.该算法收集用户偏好的数据后,使用KNN算法计算用户的最近聚类,从而得出用户的共同偏好,最终根据共同偏好程度向用户推荐共同偏好.
在User-based CF算法中,对目标用户进行推荐需要利用用户-项目评分矩阵搜索与目标用户相似的邻居用户,利用邻居用户产生预测评分.算法主要有3个步骤:相似度计算、邻居用户的选择和评分预 测[14].User-based CF算法的流程图如图1所示.
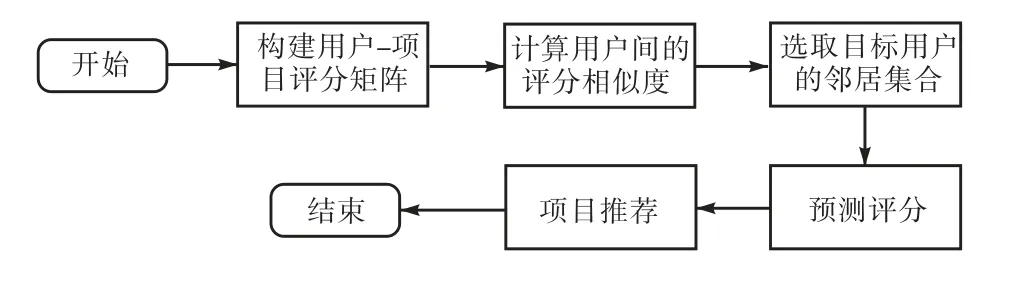
图1 User-based CF算法的流程图 Fig. 1 Flowchart of the User-based CF algorithm
相似度计算过程是算法的核心部分,常见的相似度计算方法公式有皮尔森(Pearson)相似度、杰卡德(Jaccard)相似度等,这些相似度计算方法是将一个用户对所评价项目的分值作为一个向量计算用户之间的相似度.随着数据信息的快速增长,用户和项目数量都在急剧增加,这种情况导致了用户-项目评分矩阵非常稀疏,上述传统相似度计算方法的效果并不理想.因此,近几年来有很多针对相似度计算的研究.
1.2 K-means算法
聚类是以相似性为基础的,也就是将相似的东西划分为一组,在聚类的过程中并不知道某一类是什么,而最终的目标仅仅是把相似的东西聚到一起.聚类一般为数值聚类,对数据提取M种特征并组成一个M维向量,进而得到一个从原始数据到M维向量空间的映射,然后基于某种方法或者规则进行划分,使得同组的数据具有最大的相似性.其中,K-means算法是聚类算法中应用最广泛、最简洁的一种算法.
K-means算法是基于距离的聚类算法中的一 种[15].该算法的目标是根据输入的参数K(聚类目标数),将所有的数据划分为K个类.基本思想是将每个数据点归为距离它最近的聚类中心点所在的簇类.其具体步骤如下:
(1)随机在数据点中选取K个数据点作为初始聚类中心点.
(2)对于每一个数据点,利用欧几里得公式计算该点到每一个聚类中心的距离并将其划分到最近的类.其中,欧几里得公式为
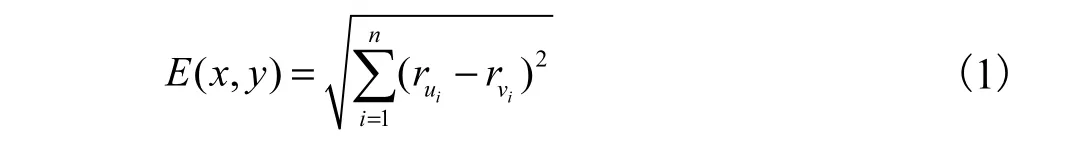
其中:x、y为用户u、v评价项目的分值;iur、ivr表示用户u、v对项目i的评分;n为项目个数.
(3)利用公式(2)重新计算每一个类别中数据点的平均值,并将得到的平均值点作为新的聚类中心点.若没有数据点和平均值点相同,利用公式(1)计算数据点到平均值点的距离,将距离平均值点最近的数据点作为新的聚类中心点.

其中:Ci表示第i个类别,ci代表第i类数据的平均值点,x是第i个类别中的数据点,im为第i个类别中数据点的个数.
(4)如果聚类中心的变化没有超出预设的阈值,则收敛;否则转到步骤(2).
K-means聚类算法简单,计算速度快,同时在处理大量数据时具有相对可伸缩性.
1.3 二分K-means算法
当质心相对较远时,K-means聚类算法不能很好地在簇与簇之间重新计算分布质点,因而聚类结果不佳[16].为了改善这一问题,采用二分K-means算法,该算法属于分层聚类的一种.通常分层聚类有两种策略:聚合,一种自底向上的办法,将每一个观察者初始化本身为一类,然后进行两两相结合;分裂,一种自顶向下,将所有的观察者都初始化为一类,然后进行递归分裂.
二分K-means算法为了得到K个簇,将所有数据作为一个簇集合并分裂成两个簇,直到划分为K个簇.该算法的具体步骤如下:
(1)将所有数据点当成一个簇.
(2)对每一个簇计算簇内误差平方和(sum of squared error,SSE).SSE表示某一簇内其他数据点到聚类中心的距离总和,该值越小,说明该簇越紧凑,聚类效果最好.在给定的簇上进行K-means聚类(K=2),并计算将该簇分裂后的总SSE.其中,SSE的计算公式为
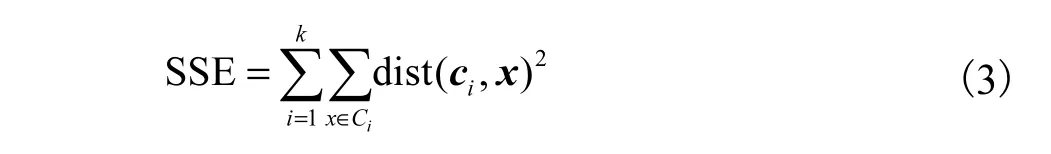
其中:ic表示质心,x表示以ic为质心的簇内的数据,dist表示两个向量的欧几里得距离.
(3)选择可以最大程度降低SSE值的簇进行 划分.
(4)重复步骤(2)和(3),直到达到指定的簇数时停止.
因为二分K-means算法在计算相似度的数量少,所以该算法可以加速K-means算法的执行速 度,同时能够克服K-means算法收敛于局部最小的缺点.
2 本文改进的协同过滤算法
2.1 相似度的改进
传统的相似度计算方法在计算用户之间的相似度时都存在着各自的缺陷.比如,Jaccard相似度在计算时仅考虑了用户之间共同的评分项目的数量,Pearson相似度在计算过程中仅考虑了用户之间不同评分标准的差异性.针对传统的相似度计算方法存在的缺陷进行如下改进:
(1)考虑用户共同评分项目的数量对相似度的影响.在计算相似度过程时,会发现两个用户共同评分项目的数量越多,两者相似度就会越高.
(2)考虑用户评分标准的差异对相似度的影响.用户对同一个项目的评分标准又是不同的.比如,用户1不喜欢项目1,对其评为3分;用户2同样不喜欢项目1,对其评为1分;而用户3喜欢项目1,对其评为3分.
在计算相似度时,将Jaccard相似度和Pearson相似度进行结合,同时考虑了用户共同评分项目的数量和不同用户评分标准的差异性对相似度的影响,最终的相似度公式为

2.2 本文算法
K-means算法与协同过滤算法相组合的算法对传统的协同过滤算法做出了进一步的改进,使得传统推荐算法的准确率有了一定程度的提高.比如,文献[7]将层次聚类算法与协同过滤算法进行融合,减少了用户搜索邻居的范围,提高推荐速度,有效地提高了推荐结果的准确性,但该方法计算的复杂度较高.文献[17]将密度聚类算法与协同过滤算法进行结合,进一步提高推荐结果的准确性,但是该方法对于圈的半径以及阈值这两个参数的设置较为敏感.
考虑上述单一的聚类算法与协同过滤算法进行结合时出现的问题,将K-means算法和二分K-means算法进行结合对协同过滤算法进行改进.首先将数据集转为用户-项目评分矩阵(缺失值用0补充);然后在通过K-means聚类算法进行第一次聚类,根据轮廓系数得到聚类效果最好的K值;接着将K值作为二分K-means聚类算法的输入,再根据二分Kmeans算法进行第二次聚类,得到最终的聚类结果;最后根据目标用户的相似邻居已评分而目标用户未评分的项目进行预测评分.轮廓系数(S(i))、预测评分按照式(5)和式(6)计算.
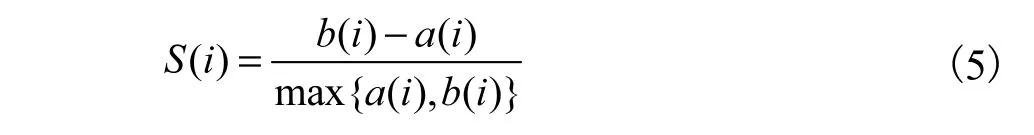
其中:b(i)表示样本点i距离下一个最近簇中所有点的平均距离,a(i)表示样本点i与同一簇内其他点的平均距离.S(i)值越大,聚类效果越好.
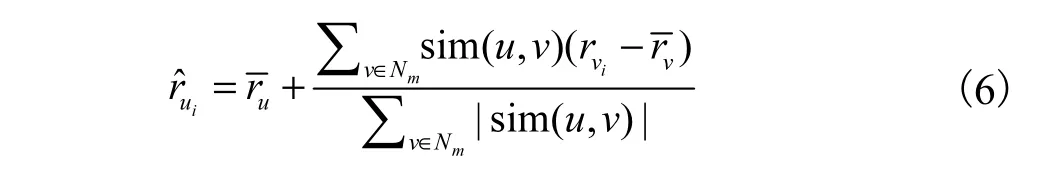
改进之后的算法流程如图2所示,具体步骤 如下:
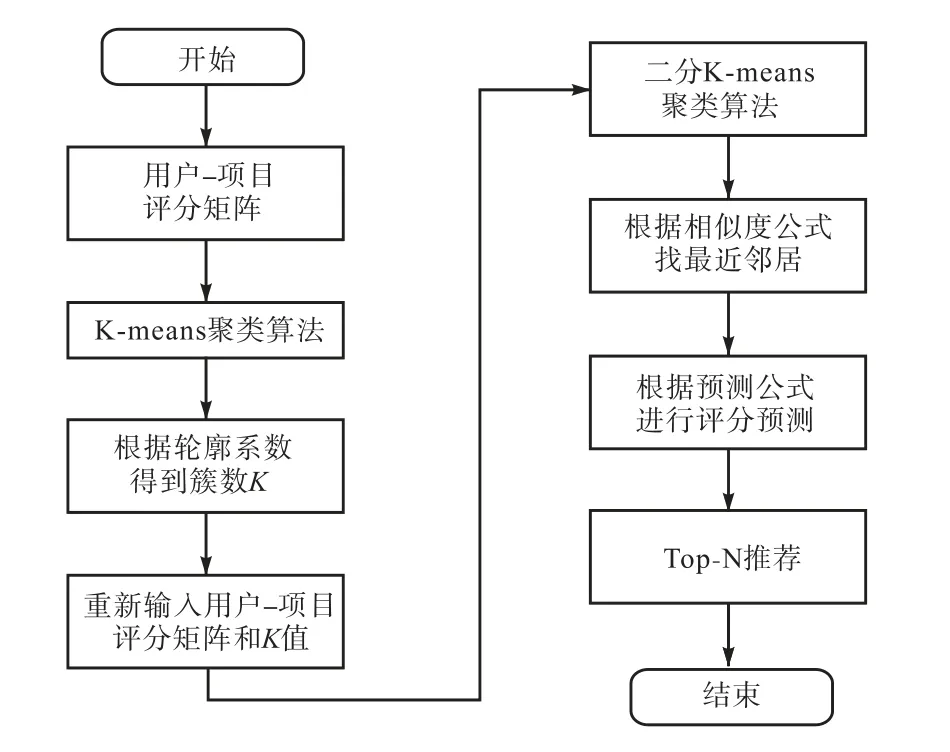
图2 本文算法的流程图 Fig. 2 Flowchart of the algorithm in this article
(1)将数据进行处理并转为用户-项目评分矩阵,缺失值用0填充.
(2)将用户-项目评分矩阵作为K-means聚类算法的输入,根据式(5)得到聚类效果最好的分类数目K.其中,利用式(1)计算样本点与中心点的距离.
(3)将用户-项目评分矩阵和聚类数目K输入到二分K-means算法中,得到每位用户所属的簇.
(4)计算目标用户所属的簇以及该簇内最为相似的前m个相似用户,利用式(4)作为相似度计算公式.
(5)根据邻居用户集合,利用式(6)对目标用户未评分的项目进行预测评分.
3 实 验
3.1 数据集
采用豆瓣电影数据集,该数据集包含了947位用户对1494部电影的91319次评分,评分范围为1~5,每一位用户评价至少10部电影.数据集按照70%、30%的比例划分为训练集和测试集.数据集属性包括用户ID、产品ID以及相应的评分.
3.2 评价标准
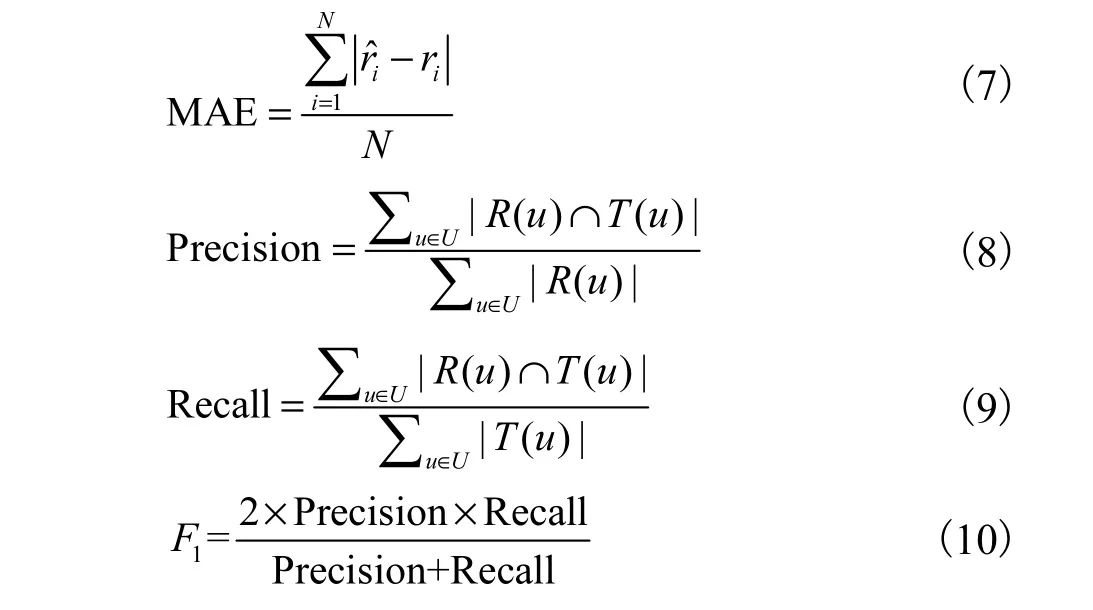
采用平均绝对误差(MAE)、准确率(Precision)、召回率(Recall)以及F1指标检测算法的推荐结果,公式为
3.3 实验结果与分析
为了得到聚类效果最好的簇数,使用轮廓系数作为评价聚类效果的标准.不同聚类数目K下的轮廓系数值见表1.

表1 不同聚类数目下的轮廓系数 Tab. 1 Contour coefficients under different clustering numbers
由表1可知:当聚类数目K为10时,K-means聚类算法的轮廓系数最高,即聚类效果最佳.
为了验证本文所提的算法能够有效地提高推荐结果的准确性,本文选取传统的基于用户的协同过滤算法,仅改进相似度的协同过滤算法,基于K-means的协同过滤算法作为本文的对比算法.对比结果如图3—图6所示.

图3 不同算法的平均绝对误差对比 Fig. 3 MAE comparison of different algorithms
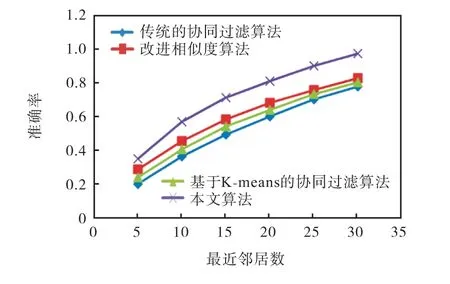
图4 不同算法的准确率对比 Fig. 4 Precision comparison of different algorithms

图5 不同算法的召回率对比 Fig. 5 Recall comparison of different algorithms
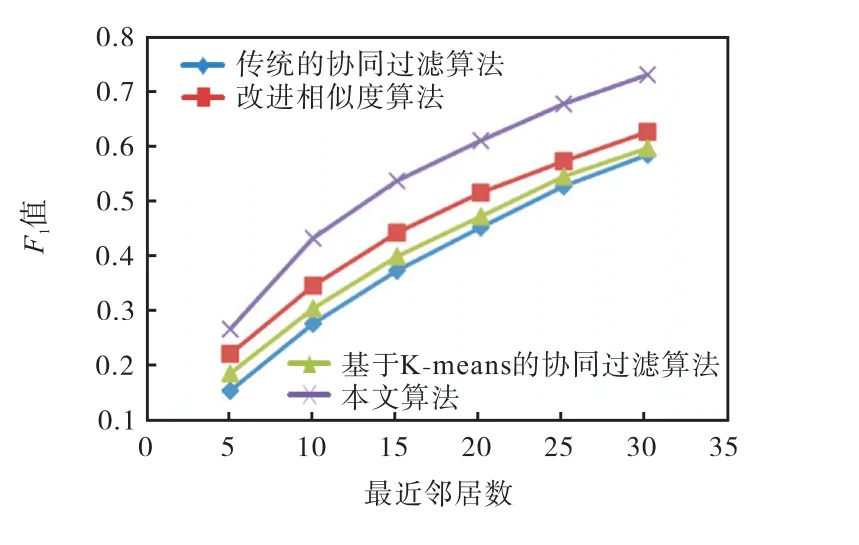
图6 不同算法的F1值对比 Fig. 6 Comparison of F1 values of different algorithms
由图3可以看出,仅改变相似度计算方法或仅基于K-means的协同过滤算法的MAE值均比传统协同过滤算法的MAE值低,但本文算法的MAE值是最低的,这也进一步说明本文算法预测的分值与实际的分值更接近.通过图4—图6可以看出,上述算法的准确率、召回率以及F1值均随着目标用户的最近邻居数的增加而增加.首先,通过观察发现仅改变相似度计算方法或者仅基于K-means的协同过滤算法均能使传统的协同过滤算法的推荐效果提高,但推荐效果都不如本文的算法.其次,通过实验结果发现寻找目标用户的邻居时,仅改变相似度的计算方法和仅基于K-means的协同过滤算法都在一定程度上使得用户间的相似度得到提高,但是本文将两者进行结合使得用户之间的相识度更加准确,进一步验证了相似度的计算是推荐算法的核心部分.
4 结语
本文将聚类算法和协同过滤算法进行结合,并对聚类算法和相似度计算进行相应的改进,提出了基于K-means的改进协同过滤算法.该算法在聚类过程中既考虑了K值选取的影响又考虑了随机质心选取的影响,使得在寻找最近邻居时的相似度更加准确.采用豆瓣电影数据集进行对比实验,实验结果表明本文算法进一步提高了推荐的效果.但是,面对数据集极度稀疏以及用户冷启动的问题还是无法解决,后续工作应该对算法进行相应的改进,以求进一步提高算法的准确度.
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
新班主任(2022年4期)2022-04-27
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
汽车观察(2019年2期)2019-03-15
现代计算机(2018年27期)2018-10-25
中学生数理化·高一版(2018年6期)2018-07-09
民生周刊(2017年19期)2017-10-25
雷达学报(2017年6期)2017-03-26
