
基于频繁项挖掘的贝叶斯网络结构学习算法BNSL-FIM
2022-01-05 02:31李昡熠
计算机应用 2021年12期
李昡熠,周 鋆*
(1.国防科技大学系统工程学院,长沙 410073;2.国防科技大学信息系统工程重点实验室,长沙 410073)
(∗通信作者电子邮箱zhouyun@nudt.edu.cn)
0 引言
贝叶斯网络是一种通用的概率图模型,它可以表示随机变量之间的相关性,是随机变量联合概率分布的一种图形化表示,具有很强的可解释性,在机器学习领域有着广泛的应用,是领域研究的热点之一。
然而在真实机器学习问题中,由于实际样本数据存在噪声和大小限制以及网络空间搜索的复杂性,学习贝叶斯网络的结构是一个NP 难(Non-deterministic Polynomial hard,NPhard)问题[1]。因此,如何减小贝叶斯网络结构学习的误差成为了贝叶斯网络学习的研究难点之一。近年来,人们发现合理的利用先验知识,可以提高贝叶斯结构学习的准确度[2],成为当前贝叶斯网络研究领域关注的重点。
本文提出一种基于频繁项挖掘及关联规则校正的结构学习算法BNSL-FIM(Bayesian Network Structure Learning based on Frequent Item Mining),通过确定频繁项之间的结构关系,从中提取先验信息,并设计算法辅助提升最终结构学习的准确度。
如图1 所示,本文提出的BNSL-FIM 算法首先对样本数据进行二分类处理以及频繁项挖掘,通过关联规则分析初步提取变量间的因果关系;然后使用PC 算法(PC-Algorithm)[3]对频繁项进行结构学习,并利用关联规则分析结果对频繁项的结构学习进行校正,从而形成最后的先验知识;最后以BDeu(Bayesian Dirichlet equivalent uniform)评分函数为基础提出融合先验知识的评分方法,并使用该评分方法对样本数据进行贝叶斯网络结构学习以得到最终的网络结构。
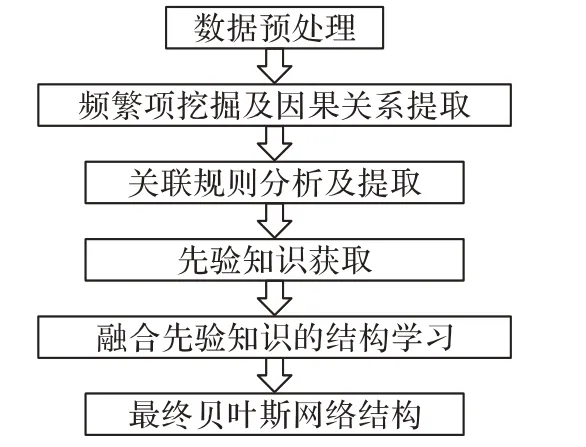
图1 BNSL-FIM算法流程Fig.1 Flowchart of BNSL-FIM
1 相关工作
经典的贝叶斯网络学习研究侧重于评分函数的设计和搜索方法的优化[4],通过对可能的网络结构和节点参数形式进行描述,提高学习算法的智能水平和问题求解能力,在单一的问题领域已经达到了一定的学习极限。这些研究偏重模型对训练数据的可解释性,学习准确度主要由训练数据的质量决定,在数据有限或问题复杂的情况下,往往会出现过拟合的情况[5],难以在实际中应用。
近年来,人们发现结合先验知识可以改进贝叶斯网络学习的准确度,如引入结构先验[6],或引入一定的约束条件[7]等,都可以大大减少结构学习的搜索空间,从而便于算法在有限的时间内找到可行解,因此设计先验知识的引入方法,是改进现有贝叶斯网络结构学习算法的一种思路。
关联分析是数据挖掘中重要的研究内容,其核心思想是通过对数据的共现关系进行计算分析[8],从而发现数据之间隐含的关系与规律。肖海慧等[9]提出了一种融合关联规则与知识的贝叶斯网络结构学习算法;Kharya 等[10]提出通过计算关联规则置信度和提升度并结合贝叶斯网络进行预测的方法。这些方法均尝试通过挖掘节点间的关联规则来提升贝叶斯网络的准确度,但由于关联规则并不显式地表示变量的因果关系,上述方法均没有实现通过挖掘关联规则自动化地进行贝叶斯网络结构学习。为了解决该问题,本文设计了一种新的基于频繁项挖掘的贝叶斯网络结构学习算法。
2 基于频繁项挖掘的先验知识获取方法
本章主要介绍如何基于频繁项挖掘贝叶斯网络结构学习所使用的先验知识,包括:1)基于贝叶斯结构学习样本数据的频繁项集挖掘及其关联规则分析方法;2)基于关联规则的频繁项集贝叶斯网络结构校正。
2.1 频繁项挖掘及其关联规则分析
关联规则分析主要包括两个阶段:第一阶段是从样本数据中找到频繁项集,第二阶段是从这些频繁项集中挖掘出关联规则。本文中的最大频繁项集挖掘和关联规则分析的形式化描述如下:
1)由于关联规则分析要求给定的数据是布尔型变量,故对给定的数据集D={V,Dv}(其中V表示随机变量,Dv表示随机变量V的样本数据)进行二分类,使得分类后数据集可用于频繁项挖掘。
2)使用Apriori算法[4]挖掘支持度Support=P(Vi1∪Vi2∪…∪Vin)≥θ的频繁项Freq_itemi={Vi1,Vi2,…,Vin},其中θ为根据数据集分布规律所定义的最小支持度;并通过频繁项集F=∪Freq_itemi得出最大频繁项集Max_F={item|item∈F∩∀(item∪(Vi∉item)) ∉F}。
3)对频繁项集进行关联规则分析,由于变量的关联规则并不显式地表示变量间的因果关系,故本文中并不使用关联规则分析结果作为贝叶斯网络结构学习的先验知识,而是将关联规则分析作为最大频繁项集结构学习的校正。关联规则分析的具体表示如下:对于任意两个随机变量Vi,Vj∈V,计算其支持度和置信度,公式如下所示:

其中:Sup(Vi→Vj)表示关联规则(Vi→Vj)的支持度,即Vi、Vj同时发生的概率P(Vi∪Vj),用来表示数据集中Vi、Vj同时发生的比例,反映了该关联规则在数据库中的重要性;Con(Vi→Vj)表示关联规则(Vi→Vj)的置信度,即在变量Vi发生的情况下,Vj发生的条件概率,反映了该关联规则的可信程度。本文通过筛选同时满足最小支持度θ和最小置信度c的关联规则{(Vi→Vj)|Sup(Vi→Vj)≥θ∩Con(Vi→Vj)≥c}确定最终的强关联规则集Ass=∪(Vi→Vj)。
2.2 基于最大频繁项集的结构学习与校正
关联规则分析可得出具有强相关性的节点对,因果关系也是一种关联关系,故可用关联规则分析结果Ass对最大频繁项集Max_F的贝叶斯网络结构进行校正,提高最大频繁项集贝叶斯网络结构的准确度,并以此作为总体样本数据贝叶斯网络结构学习的先验知识。
首先描述最大频繁项集Max_F的贝叶斯网络结构学习过程。由于最大频繁项集的节点数通常较少,故使用基于约束的结构学习方法学习最大频繁项集的贝叶斯网络结构,本文使用PC 算法[3]对其进行结构学习。PC 算法通过条件独立性测试来学习数据的依赖结构,尝试通过分析数据中的条件依赖的独立关系给出最好解释的某个网络。具体过程如下:依次提取频繁项Freq_itemi,从给定的样本数据集D={V,Dv}中提取频繁项数据集,对Dfreq_i分别进行贝叶斯网络结构学习得出贝叶斯结构BNfreq_i,最终求得频繁项集的贝叶斯网络结构集BNmax_f=∪BNfreq_i。
但由于PC算法对个体独立性检测的失败比较敏感,某次检测的错误结果将误导整个网络的构建过程,故使用上节中求得的关联规则分析集Ass对频繁项集的贝叶斯网络结构集BNmax_f进行校正,以增加先验知识的鲁棒性。具体过程如下:对于任意节点对(Vi→Vj)∈BNmax_f,若(Vi→Vj)∈Ass,则将该节点对加入先验知识白名单,即

同时,若频繁项集间的节点不存在关联规则也无法得出贝叶斯网络结构,则认为其是不可能存在的变量依赖关系,并将其加入先验知识黑名单,即

下文中将利用本节求得的Priwhite_list和Priblack_list作为先验知识来进行贝叶斯网络结构学习。
3 融合先验知识的评分方法与结构学习
本文基于BDeu[11]评分函数融合先验知识提出新的评分方法,并使用爬山搜索算法寻找评分最优的贝叶斯网络结构。下面将详细介绍融合先验知识的贝叶斯网络结构学习算法。
3.1 基本定义
基于评分的贝叶斯网络结构学习算法利用评分函数对贝叶斯网络结构的好坏进行评判,并通过搜索算法寻找评分最优的网络结构。因此,该算法主要包括两个方面:评分函数的选取和搜索算法的选取。评分函数包括评价后验概率P(G|D)的评分函数以及同时考虑结构拟合度和复杂度的评分函数。常用的评分函数有经典评分函数BDeu[11]、K2[12]、最短信息准则(Minimum Description Length,MDL)[13]、贝叶斯信息准则(Bayesian Information Criterion,BIC)[14]和近几年新提出的评分函数Min-BDeu&Max-BDeu[15]、NO TEARS[16]等。对于搜索算法,由于网络空间的复杂度随节点数增加呈指数增长,搜索出最优的贝叶斯网络结构是个NP难问题,通常使用近似算法来求取次优网络结构。本节将详细介绍本文中使用的BDeu评分函数和爬山搜索算法。
定义1BDeu评分函数。该评分函数基于贝叶斯定理提出:对于给定的样本数据D和模型结构G,根据贝叶斯公式

将后验概率作为评分。由于P(D)不会影响不同的模型结构G,故评分公式等价为:
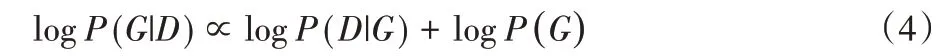
将P(D|G)展开可得:
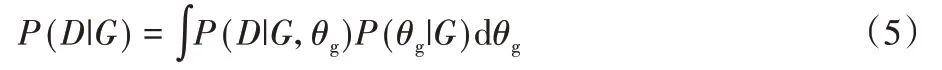
其中:θg表示给定模型结构G时的参数。当参数θg的先验分布满足乘积狄利克雷分布时,可以得到:

其中:Г()表示gamma 函数;n表示随机变量的个数;rПi表示第i个随机变量Xi的父节点集可能的取值数;ri表示随机变量Vi可能的取值数;nijk表示随机变量Vi取k,随机变量Vi的父节点集取j时的样本个数;αijk为狄利克雷参数,当时,该评分函数为BDeu 评分函数,α*为等效样本量(Equivalent Sample Size)。
算法1 爬山搜索算法。该搜索算法是一种局部择优的搜索算法,算法思路是从当前结构的相邻结构里,选取评分最高的结构作为下一个当前结构,重复操作直至所有相邻结构的评分都比当前结构低。
输入 数据集D,评分函数SD(G);
输出 使得分函数SD(G)最大的网络结构Gmax。


3.2 融合先验知识的结构学习
为了融合上文中得出的先验知识Priwhite_list和Priblack_list,本节提出一种新的评分模型,在评分函数中增加罚项:

其中:rw表示满足(Vi→Vj)∈Priwhite_list∩(Vi→Vj)∈G的元素个数,nk表示第k个满足(Vi→Vj)∈Priwhite_list∩(Vi→Vj)∈G的样本个数;rb表示满足(Vi→Vj)∈Priblack_list∩(Vi→Vj)∈G的 元 素 个 数,nt表 示 第t个 满 足(Vi→Vj)∈Priblack_list∩(Vi→Vj)∈G的样本个数。定义本文中融合先验的评分函数如下:

算法2 融合先验知识的结构学习算法。该算法分为评分函数和搜索算法两个阶段,与未融合先验知识的结构学习算法相比,该算法增加了基于频繁项挖掘的先验知识获取过程。具体算法描述如下:首先基于频繁项挖掘获取先验知识;再结合样本数据特点确定评分函数的罚项权重γ的取值,并得出最终的评分函数;最后使用爬山搜索算法寻找最优的贝叶斯网络结构。
输入 数据集D,评分函数SPrior(G),评分函数参数γ;
输出 使得评分函数SPrior(G)最大的网络结构Gmax。

4 实验与结果分析
本章使用经典数据集对BNSL-FIM 算法进行有效性仿真验证,并通过对比融合先验知识所学习的网络结构和未融合先验知识所学习的网络结构与原始结构的汉明距离来评判网络结构的优劣性。
4.1 实验配置
实验基于linux-4.19.128-microsoft-standard 平台,使用python集成环境anaconda3,python版本为3.7.9。实验使用的6 个数据集均来源于公开在线平台Bayesian Network Repository[17],并使用开源python 软件包pyAgrum 对贝叶斯网络进行采样,mlxtend 对采样后数据进行频繁项集挖掘和关联规则分析,pgmpy 对数据进行贝叶斯网络结构学习,最后通过比较学习到的网络结构与原始网络结构的汉明距离来评判该算法的有效性。
4.2 实验过程
为了多维度验证BNSL-FIM 算法的有效性,实验过程中分别使用表1所示的6个标准数据集进行分析,其中包括小型贝叶斯网络Asia、Sachs;中型贝叶斯网络Alarm、Insurance 和大型贝叶斯网络Hailfinder、Hepar2;并且在仿真过程中对不同数据量的样本数据进行了测试,通过验证不同类型的网络结构和不同大小的样本数据更真实地判断本文提出算法的优劣性。
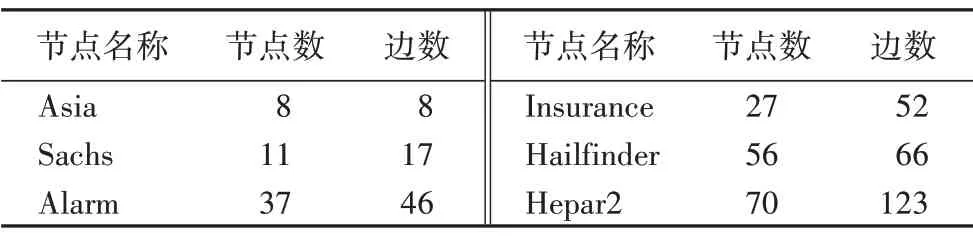
表1 实验使用的6个标准数据集Tab.1 Six standard datasets used in experiments
实验首先通过采样数据集挖掘出频繁项集和关联规则,并确定最终的先验知识;再使用本文中提出的融合先验知识的评分函数对数据集进行贝叶斯网络结构学习;最后计算学习所得网络结构与原始网络结构的汉明距离。所以在实验开始之前要根据样本数据的分布特点对最小支持度θ、最小置信度c以及评分函数的罚项权重γ这些实验参数进行设置。本文中最小支持度与最小置信度的取值是通过分析样本数据特点选取的经验值,具体参数值见本文源代码[18]。下面以采样大小为5 000的Asia网络为例详细阐述实验过程,其原始网络结构如图2所示。
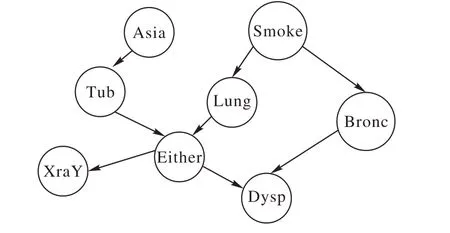
图2 Asia数据集的原始网络结构Fig.2 Original network structure of Asia dataset
实验过程主要分为三个阶段:第一阶段对数据集进行关联规则分析,首先将数据集变量转换为布尔值变量,设置最小支持度θ为0.75,最小置信度c为0.95,对数据集进行频繁项集挖掘和关联规则分析,表2 是一次实验中对Aisa 采样所得数据集进行关联规则分析的数据,挖掘到的最大频繁项集为:{(Either,XraY,Tub,Asia,Lung)};接着对最大频繁项集进行贝叶斯网络结构学习,结合关联规则分析结果确定最终的先验知识。

表2 Asia数据集的关联规则分析Tab.2 Association rule analysis of Asia dataset
实验最终得到的先验知识如图3 所示,分析先验知识的准确率可以得出,实验中白名单先验知识的准确率为100%,黑名单先验知识的准确率为85.7%(虚线为错误边)。虽然先验知识的准确率未达到100%,但由于本文中提出的评分函数是基于权重和节点对同时出现的概率来设定惩罚项,故对于先验知识有一定的容错率。
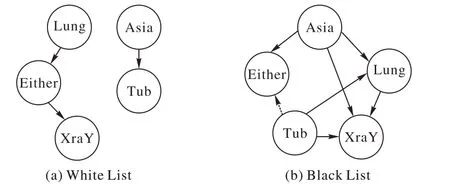
图3 Asia数据集中提取的先验知识Fig.3 Prior knowledge extracted from Asia dataset
第二阶段使用未融合先验知识的算法和融合先验知识的算法分别对Asia 数据集进行贝叶斯网络结构学习,求得贝叶斯网络结构如图4 所示,可以看出,融合先验知识的结构学习结果正确边数(实线所示)多于未融合先验知识的结构学习结果。
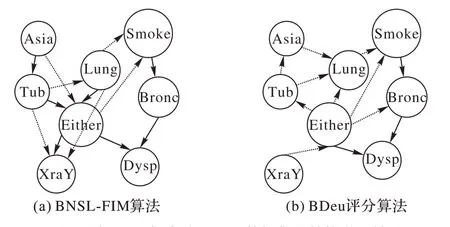
图4 添加/不添加先验下Asia数据集的结构学习结果Fig.4 Structure learning results on Asia dataset with/without prior knowledge
第三阶段计算学习所得的网络结构与原始结构的汉明距离,由于采样数据的不确定性以及搜索过程中起始变量的不确定性,每次结果学习所得到的网络结构存在差异,故为提高实验结果的可靠性,每组数据进行多次采样与结构学习,最后计算所得结构与原始结构汉明距离的平均值,以样本数量为5 000的Asia网络为例,重复10次的实验结果如表3所示。

表3 Asia数据集的结构学习结果(汉明距离)对比Tab.3 Structure learning results(Hamming distance)on Asia dataset
4.3 实验结果与分析
通过4.2 节所述的实验配置和实验方法,分别对不同样本大小的6 个经典网络数据进行实验分析,结果如表4 所示。由表4可以看出,BNSL-FIM算法对Asia和Hailfinder网络有较为显著的提升效果,但对Alarm 和Hepar2 网络的结构学习几乎没有提升效果。一方面,这取决于数据集中的频繁项集的特点,比如频繁项集中能否挖掘出有效的因果关系信息或先验信息是否可靠;另一方面,由于pgmpy软件包提供的爬山搜索算法是基于可分解的评分函数[19]搜索网络,当网络节点较多时,融合先验知识的评分函数的罚项会导致ΔS>epsilon的情况增多,搜索空间成倍增大,影响搜索效率,为平衡搜索时间和内存使用情况,实验中调低了大型网络中先验知识的权重取值,也影响了实验结果;同时,BNSL-FIM 算法在小样本数据下的效果没有大样本数据下效果明显,这是由于小样本数据信息量不足,更难挖掘出正确的关联信息,这导致了小样本情况下所获取的先验知识准确性较低,从而影响实验结果。

表4 两个算法在6个标准数据集上的不同样本大小条件下的结构学习结果(汉明距离)对比Tab.4 Structure learning results(Hamming distance)of two algorithms on 6 standard datasets under different sample sizes
5 结语
本文针对如何提高贝叶斯网络结构学习提出了一种以挖掘频繁项集生成先验知识的贝叶斯网络结构学习算法,实验结果表明该算法对具有某些特点(比如网络节点较少/频繁项集中随机变量存在因果关系)的网络结构学习有较明显的提升效果。但该算法仍然存在一些不足,比如降低了基于可分解评分函数的爬山搜索的算法性能,使得对于大型网络的适应性较差;对于小样本数据和错误先验信息的适应能力仍需要提高。针对如何提升该算法的鲁棒性和搜索算法的性能是下一步需要继续研究的问题。
猜你喜欢
社会科学战线(2022年1期)2022-02-16
客联(2021年9期)2021-11-07
海外文摘·艺术(2020年22期)2020-11-18
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
数学学习与研究(2017年10期)2017-06-22
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
岁月(2016年5期)2016-08-13
