
优化三元组损失的深度距离度量学习方法
2022-01-05 02:31李子龙王洪栋
计算机应用 2021年12期
李子龙,周 勇,鲍 蓉,王洪栋
(1.徐州工程学院信息工程学院,江苏徐州 221018;2.中国矿业大学计算机科学与技术学院,江苏徐州 221116)
(∗通信作者电子邮箱lzl@xzit.edu.cn)
0 引言
近年来,距离度量学习在图像检索、行人再识别、聚类等方面都有着很好的应用,已经成为计算机视觉领域的研究热点之一。随着深度学习的飞速发展,许多专家提出了深度距离度量的方法[1]。深度距离度量旨在通过深度神经网络学习训练样本到特征的映射。在该映射下,相似样本的距离更为接近,而相异样本的距离则更为远离。
为了学习样本到特征的映射函数,设计合适的距离度量损失函数是提高深度神经网络性能的重要因素。对比损失是深度距离度量学习中经常被使用的一类损失函数[2-4]。通过该损失函数能使正样本对特征向量之间的距离最小化,而使负样本对特征向量之间间隔一定的距离。三元组损失使用正样本对和负样本对组成三元组[3,5],在对比损失的基础上进一步考虑了类内距离和类间距离的相对关系。相比负样本对,这样会使得正样本对在映射后的特征空间里距离更近。由于构造三元组的数量往往巨大,一些学者提出通过减少三元组的数量来降低算法的复杂度[6-7]。文献[8]中提出了一种层次的三元组损失结构,该方法将采样和特征嵌入结合在一起进行学习;文献[9]中提出了一种距离加权采样的方法,它是基于相对距离进行样本选择;文献[3]中提出在训练过程中充分利用小批量数据来构建成对距离矩阵,并使用结构化损失函数来学习特征嵌入;文献[3]中的工作后来在文献[10]中进行了扩展,提出了一种基于结构化预测的距离度量方案,并用其去优化聚类效果;文献[11]中扩展了三元组的思想,允许在多个负样本之间进行联合比较;文献[12]中考虑了角度关系,提出了一种新颖的角度损失函数。
上述方法都是使用单一的距离度量去适应多样化的数据,也就是从整个训练集上学习距离度量,这容易忽略训练样本间的局部差异性,在数据类内变化大、类间模糊的情况下就显得力不从心;而且使用单一、全局的距离度量容易导致过拟合。为此,一些学者尝试对训练样本分组,然后在组内对局部差异性进行距离度量学习,并使用集成技术进一步增强其性能。如文献[13]较早将集成学习的思想引入到度量学习中;文献[14]中使用基于Boosting 的度量学习算法去计算按层次结构组织的人脸数据;文献[15]中提出采用多个基于视觉注意机制的学习者进行集成;文献[16]中建议将训练数据的标签随机分组,并以此来集成多个相关的嵌入模型。
上述这些集成的方法主要关注训练过程的集成,并不是针对距离度量的集成,而且不能同时实现神经网络和弱学习者的端到端训练。本文采用Boosting 算法的思想,构造多个三元组深度相对距离度量的级联模型,每个相对距离对应卷积神经网络(Convolution Neural Network,CNN)全连接层中所划分的单独的一组,每一组对应的全连接层代表一个弱分类器,所有组共享CNN 的底层表示。在Boosting 框架中,不断地更新训练样本的权重,使得后续的相对距离度量更加关注那些难样本上。为了有效评价三元组训练样本的相近程度,本文对经过神经网络映射的三元组训练样本的相对距离进行阈值化处理,并使用线性分段函数作为相对距离的评价函数。该评价函数会作为弱分类器不断加入到Boosting 框架中去,最终生成一个强分类器。为了优化弱分类器和神经网络的参数,本文采用交替优化的方法来获得最优值。相比经典的基于三元组损失的距离度量方法,本文方法在深度神经网络上并没有引入额外的参数,且在学习评价函数参数时所花费的代价也并不太大。
1 基于Boosting的深度距离度量模型
让X=[x1,x2,…,xN]表示N个挑选而成的三元组训练样本。其中,第i个三元组训练样本表示为,它对应一个三元组标签yi∈{-1,+1}。是组成三元组训练样本的三个训练样本,称为锚点样本。如果这三个训练样本的类别一样,都属于正例样本,则yi=+1;如果只有的类别一样,都为正例样本,而为负例样本,则yi=-1。
本文使用多个神经网络,第i个三元组训练样本xi=经过所学习的第m个神经网络映射后的三元组为。根据Boosting 算法的思路,本文使用一组对应多个神经网络的三元组训练样本的相对距离弱分类器去构造一个强分类器,如下式所示:

其中:M是弱分类器的数量,φm是三个训练样本经过第m个神经网络映射的特征值之间两两组合的相对距离评价函数。为了评价三个训练样本映射后的相对距离,使得相同类别的三个训练样本映射后的相对距离更为靠近,而不同类别的三个训练样本映射后的相对距离更为远离,本文使用了一个适应能力更强的相对距离评价函数,其定义如下式所示:
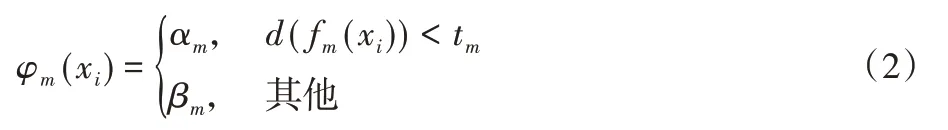
在Boosting 算法中,每一次迭代都会产生一个新的弱分类器并加入到强分类器中。根据文献[17]的介绍,一个弱分类器添加到强分类器的过程可以看作使下面的损失函数最小化的问题:

上式可进一步变为下面的优化问题:

2 优化三元组损失的学习方法
在Boosting 算法中训练多个CNN 的代价太高,为了避免较大的计算开销,将CNN 的全连接层划分为几个不重叠的组,每个组代表一个弱分类器,而所有的弱分类器共享相同的底层表示,也就是将CNN 中连续的卷积层和池化层进行共享。参考文献[3],本文采样小批次数据,通过CNN 前向传播,并在网络的最后一层中组成三元组形式,最后根据损失函数反向传播到网络的全连接层。在本文实验中,参与对比的相关文献也是采用此种方案。为了训练模型中的弱分类器,本文参考文献[18]的思路,采用交替优化方法来学习深度神经网络和距离评价函数的参数。
在第m次迭代,固定第m个深度神经网络全连接层参数的同时来研究式(4)的优化问题。为此,本文先利用三元组训练样本的标签对其进行拆解分析,如下式所示:

对拆解后的公式分别对αm和βm求偏导数并令偏导数为0,则可以得到这两个参数的最优值,如下式所示:

在每次迭代之后,训练样本的权重被更新,如下式所示:

在训练样本的权重被更新后,将所有训练样本的权重进行归一化处理。经过上面的分析,可知影响距离评价函数的参数实际上只与tm有关,其优化值采用穷举法就可以得到。于是,一个最优的弱分类器被找到并可被加入到强分类器中去。而此时,被正确分类的样本会被赋予较低的权重,而被错误分类的样本则被分配较高的权重,这就会使得后面的弱分类器更加关注前面弱分类器不能判别的样本。
接着固定第m个距离评价函数参数αm、βm、tm的值后,再去优化第m个深度神经网络的全连接层参数。本文使用三元组损失函数去训练深度神经网络,训练过程使用常规的反向传播算法。具体来说,在前向传播中,对每个三元组训练样本计算其映射后的两两组合的相对距离。而在反向传播算法中,迭代地反向传播三元组损失函数值去更新深度神经网络的参数。参考文献[5],使用经典的三元组损失函数,这种损失函数会惩罚正三元组训练样本的较大距离和负三元组训练样本的较小距离。使用前面根据学习得到距离度量阈值tm作为三元组相对距离的距离间隔,于是得到下面的三元组损失函数:

3 实验结果及分析
为了验证本文方法的有效性,选取CUB-200-2011、Cars-196 和Standford Online Products(SOP)三个公开可用的数据集进行实验,并与当前流行的深度距离方法(文献[2-3,5,8,11-12,15-16,19-21]中的方法)在检索任务上进行了比较。
数据集CUB-200-2011 由200 种的鸟类图片构成,使用前100 个类别的5 864 幅图像进行训练,而剩余的100 个类别的5 924 幅图像用于测试;Cars-196 数据集包含196 种不同类别的16 185 幅汽车图像,使用前98 种不同类别的8 054 幅图像用于训练,而后98 种不同类别的8 131 幅图像用于测试;数据集SOP 包含大量产品图片,使用11 318 个类别的59 551 幅图像用于训练,而其他11 316个类别的60 502幅图像用于测试。
为了评估本文方法在图像检索方面的性能,使用Recall@K来度量检索效果。这个度量指标是这样计算的:首先,对于测试集中的每幅图像,从剩余的测试集中检索出K幅最相似的图像,这个相似性由本文所提出的三元组距离度量来定义;然后,如果这K幅检索到的图像中有一个与查询图像具有相同的标签,则将召回值增加1;最后,最终的Recall@K值是召回值占所有测试图像的百分比。在数据集CUB-200-2011 和Cars-196 上选择K∈{1,2,4,8,16,32}来计算召回率,在数据集SOP上选择K∈{1,10,100,1 000}来计算召回率。网络结构上主要参考文献[2]中使用GoogLeNet 作为特征提取器,并使用TensorFlow 来实现本文方法。实验中将batch 的大小设置128,所有深度神经网络均使用随机梯度下降算法进行训练。
弱分类器的数量对深度距离度量的效果有影响,为此,在CUB-200-2011、SOP 和Cars-196 这三个数据集上观察弱分类器数量对距离度量的影响,如图1 所示。从图1 可以看出,随着弱分类器数量的增加,Recall@1的值不断增加,而后不断下降。在Cars-196 数据集上,当弱分类的数量为4 时Recall@1的值达到顶峰,在SOP 和CUB-200-2011 这两个数据集上,分别在弱分类的数量为5 和6 时Recall@1 的值达到顶峰,这说明在不同图像数据集上进行图像检索的难易程度是不同的,在后面与不同方法对比实验中也按照此方式设置。

图1 弱分类器数量对图像检索性能的影响Fig.1 Influence of the number of weak classifiers on performance of image retrieval
特征向量的大小也是影响深度距离度量中的一个重要因素,因此,在数据集Cars-196上进行实验以观察不同特征向量的大小对检索精度的影响。文献[19]中的实验针对特征向量大小从64 至1 024 的情况分析了它对检索性能的影响,本文也进行同样的实验,并与文献[19]中的方法进行对比分析,实验结果如图2所示。从图2中可以看出,随着特征向量大小的增加,检索性能逐渐提高。当特征向量的大小为256 时,本文方法的性能逐渐平稳,在后面的实验中将特征向量的大小设置为此值;而且本文方法在不同特征向量大小上的检索性能都要优于文献[19]方法。

图2 不同大小的特征向量的大小对图像检索性能的影响Fig.2 Influence of feature vector size on performance of image retrieval
接下来在数据集Cars-196 上与文献[6]方法比较了训练和测试的检索性能。从图3 中可以看出,在训练集和测试集上,本文方法的Recall@1 值之间的差距比文献[6]方法的要小。这清楚地表明,本文方法并不倾向于导致过拟合。

图3 不同时期数下训练和测试的图像检索性能Fig.3 Image retrieval performance of training and testing in different epochs
本文方法和文献[3,5,11,19]中的方法在数据集Cars-196 上训练时的收敛速度的对比如图4。从图4 中可以看出,在最开始40 个时期内,本文方法的检索性能就达到了最高值,比其他的方法快得多;并且,除了文献[19]方法之外,其他方法都要100个时期以后开始慢慢收敛。

图4 不同方法的收敛速度对比Fig.4 Convergence rate comparison of different methods
最后,将本文与当前流行的一些方法在图像检索任务上进行了比较,结果如表1 所示。从数据集CUB-200-2011 和Cars-196 上的实验结果可以看出,本文方法优于其他的对比方法,包括高阶元组(文献[3,11])、角度损失(文献[12])和集成的方法(文献[15-16]);特别地,本文方法的Recall@1 值在极具挑战性的CUB-200-2011 数据集上也取得了较好成绩。在SOP数据集上,本文方法的表现也很出色。
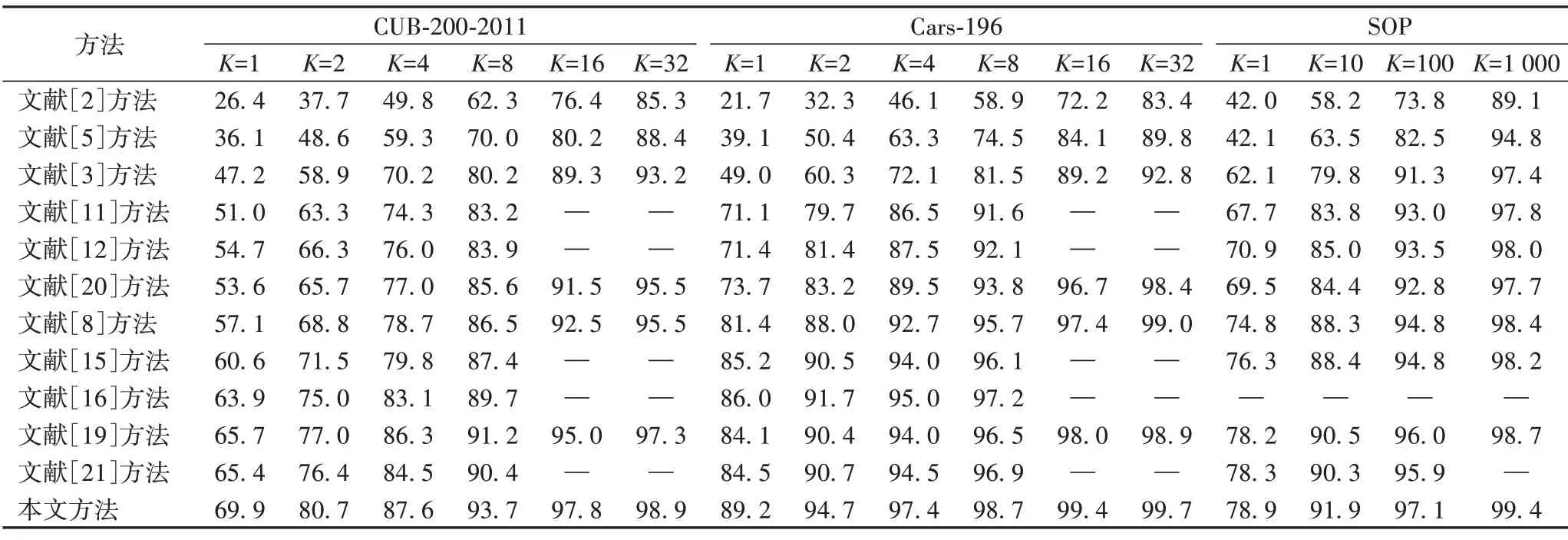
表1 K取不同值时各方法在三个数据集上的Recall@K结果比较 单位:%Tab.1 Comparison of the Recall@K with different methods on three datasets when K takes different values unit:%
4 结语
为了提高深度距离度量的性能,本文提出了一种新的深度距离度量学习方法,该方法将距离度量和神经网络学习融入Boosting 算法中。使用线性分段函数评价通过神经网络映射的三元组训练样本的相对距离,并将该评价函数作为Boosting 算法中的一个弱分类器。通过在数据集Cars-196 上进行训练和测试的结果,表明本文方法具有较好的泛化性能;同时,通过在CUB-200-2011、Cars-196和SOP 数据集上与其他方法进行图像检索任务的比较,结果也表明本文方法的性能优于对比方法。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
上海文化(文化研究)(2022年3期)2022-06-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
