
混合式的K-匿名特征选择算法
2022-01-05 02:31杨柳,李云*
计算机应用 2021年12期
杨 柳,李 云*
(1.江苏省大数据安全与智能处理重点实验室(南京邮电大学),南京 210023;2.南京邮电大学计算机学院、软件学院、网络空间安全学院,南京 210023)
(∗通信作者电子邮箱liyun@njupt.edu.cn)
0 引言
大数据时代,随着数据分析技术的发展和各种各样数据挖掘算法的提出,数据的共享和传播更加频繁。越来越多的研究机构和商业公司会在大数据中提取想要的信息并挖掘数据带来的价值,但随着数据的发布,随之而来的就是数据中的用户隐私泄露问题。近年来,不适当的数据共享造成的隐私泄露事件频发,例如Facebook 与数据分析公司Cambridge Analytica 的不当共享造成了8 700 万用户个人信息泄露[1]、NetFlex的推荐比赛中用户观影记录泄露[2]。除了数据共享引起的隐私泄露,还有许多恶意的攻击者会通过不同数据集之间的链接攻击来推断用户的敏感信息[3]。例如数据的发布者一般会删除用户个体的姓名标识符,然而攻击者还是可以通过比较不同数据集的邮编、年龄、籍贯等准标识符信息来获取用户的隐私信息[4],因此关于隐私保护的研究逐渐受到广泛关注,其中数据匿名化方法是隐私保护领域非常流行的一类方法。数据匿名化技术采用不同匿名策略对数据进行压缩或者抽象,并保证隐私不被泄露的同时,又使得数据可用性最大化[5]。
K-匿名技术是最常用的数据匿名化技术之一。1998 年,Samarati等[6]首次提出K-匿名的概念,要求数据中需存在一定数量不可区分的个体,从而使攻击者无法轻易判断具体个体的隐私信息。2002年,Sweeney[7]正式提出了K-匿名隐私保护模型,将发布数据划分成多个等价类且使每个等价类中至少有k个元组在准标识符属性上相同,使攻击者不能判别隐私信息所属的个体。K-匿名模型自提出以来一直受到广泛关注,在隐私保护领域取得了很好的效果,Iyengar[8]基于遗传算法考虑隐私保护与数据信息损失的权衡,解决K-匿名在数据挖掘中的分类问题;Machanavajjhala 等[9]在K-匿名模型基础上提出l-多样性算法,保留数据更多的信息;Xiao等[10]在2006年的SIGMOD 会议上提出的基于人性化匿名的新泛化框架,实现了满足个体需求的最小泛化,从而保留了更多数据信息。
K-匿名模型需要将数据部分属性通过泛化或隐藏等方式匿名化,这样得到的数据虽然满足K匿名隐私保护的条件,但忽视了数据在分类模型上的分类性能。实现K-匿名常用的隐藏特征的操作往往只考虑了操作后数据的隐私性而没有考虑数据在分类任务中的可用性和有效性,而这类操作可以视为一种以保护隐私为目的的特征选择方法[11]。特征选择方法作为机器学习与数据挖掘领域经典的数据预处理方法,可以通过特定的评价标准获得,可有效保证数据分类性能的特征子集从而受到了广泛研究[12]。如果使用特征选择剔除特征、挑选特征的方式来实现数据的K-匿名,从而既保证数据的隐私性又保证数据的分类性能,这类特征选择方法可以统称为K-匿名特征选择方法。然而国内外对K-匿名特征选择的研究相对较少。一些研究者结合特征选择的思想,采用“多维抑制”的方式在隐私保护数据挖掘任务中实现了K-匿名模型[13-14];Zhang等[15]将K-匿名隐私保护作为特征选择的约束条件,提出了一种用于隐私保护的特征选择方法,使特征选择后的数据满足K-匿名条件;王旭等[16]使用XGBoost(Extreme Gradient Boosting)对特征进行重要性排序,按照特征重要程度的顺序逐个判断K-匿名条件,选出满足K-匿名的特征子集。可见K-匿名特征选择从实现K-匿名的一种技巧已经演变为一类隐私保护特征选择方法。
已知的K-匿名特征选择方法大多是过滤式方法,在特征选择领域,过滤式方法以便捷、高效、不依赖于特定分类器、可解释性好等优点得到广泛研究,文献[15]与文献[16]提出的算法对单个特征按照特征重要性进行排序,从特征排序中选取当前最重要的特征开始搜索K-匿名特征子集。因为每个特征并不是独立地对分类器输出结果产生作用[17],这种搜索策略没办法保证最终选择的特征子集在分类性能和隐私保护之间达到很好的平衡。过滤式方法独立于分类算法,对分类器的分类性能影响有限,而另外一种特征选择形式是封装式特征选择方法,根据后续模型的性能来评价特征子集的优劣,时间成本较大。
针对过滤式方法独立于分类器的限制与封装式搜索成本高等问题,本文结合过滤式与封装式的特点,设计了一种混合式K-匿名特征选择算法HKFS,基于前向搜索策略和K-匿名条件产生更多的K-匿名特征候选子集,再根据分类器分类性能选出最优子集。
1 背景知识
1.1 基本定义
二维表是发布信息的主要形式,为了方便讨论,本文主要研究这类表格数据。假设T={t1,t2,…,tn}是一个待发布的数据表,数据的行项包含n个元组,也叫记录,列项称为属性。
定义1属性。属性是表格数据的列项,根据属性的特性,所有属性可以分为四类:
1)显标识符ID(IDentifier):显标识符能标识个体的身份,唯一确定一条元组(即用户记录),为保护用户隐私显标识符一般都需要删除,例如用户的姓名。
2)准标识符QI(Quasi-Identifier):准标识符属性联合起来可以以较大概率确定一条元组,一般需要做匿名化处理,例如用户的年龄、性别。
3)敏感属性SA(Sensitive Attribute):敏感属性是需要保护的属性,包含个体的隐私信息,没有关联到个体时不会泄露隐私,例如患病情况、收入,不同个体对隐私定义不同,敏感属性的选择也可能不同。
4)其他属性:不属于上面三类,不需要做特殊处理。
对于表格T={t1,t2,…,tn},用d来表示准标识符的数量,n表示用户记录的数量,Ai表示第i个准标识符属性,As表示敏感属性,tj表示表中第j条记录。
定义2等价类(Equivalence class)。在准标识符属性A1,A2,…,Ad上,具有完全相同取值的若干条记录组成一个等价类。
定义3K-匿名(K-anonymity)。如果数据表T中的任意记录t,都能找到至少k-1 条记录与t在准标识符上无法区分,则称该数据表T满足K-匿名。
K-匿名模型常用于抵御链接攻击,要求对匿名处理后的数据表中的每条记录,都应至少有k-1条记录在准标识符上的取值相同,使得观察者无法以高于1/k的置信度通过准标识符来识别用户。k值的大小决定了隐私保护的程度,k越大等价类中记录数目越多,越不易确定用户,隐私泄露的风险越低。
定义4泛化与隐藏(Generalization and Suppression)。泛化与隐藏是K-匿名模型处理数据的两种主要手段。泛化是把数据泛化到一个更大的区间,比如年龄18 可以泛化到(15,20],这样年龄分别为18 和20 的两个用户在年龄这一属性下的取值就是相同的;隐藏,也叫隐匿、抑制,可以针对一些难以泛化或者不能公开的属性进行隐匿或删除操作,例如个体的姓名。
1.2 K-匿名特征选择
一般情况下,数据中的等价类大部分都不满足K-匿名。为了达到数据匿名化的目的,需要通过泛化与隐藏等手段对原始数据进行转化,以达到数据K-匿名模型保护隐私的要求。如表1 所示,表格数据清楚表达了用户的各项信息,其中病人的病情就是敏感属性。在没有数据匿名化的情况下,只需要一点信息就可以准确定位到某个用户并了解他/她的隐私信息,例如知道这个表格中某病人是27 岁就能知道该病人患的是癌症。
通过简单的匿名化泛化手段,表1 变成表2 的形式,表2中所有用户分为了3 个等价类,最小的等价类数目为2,所以这是一个2-匿名表格。
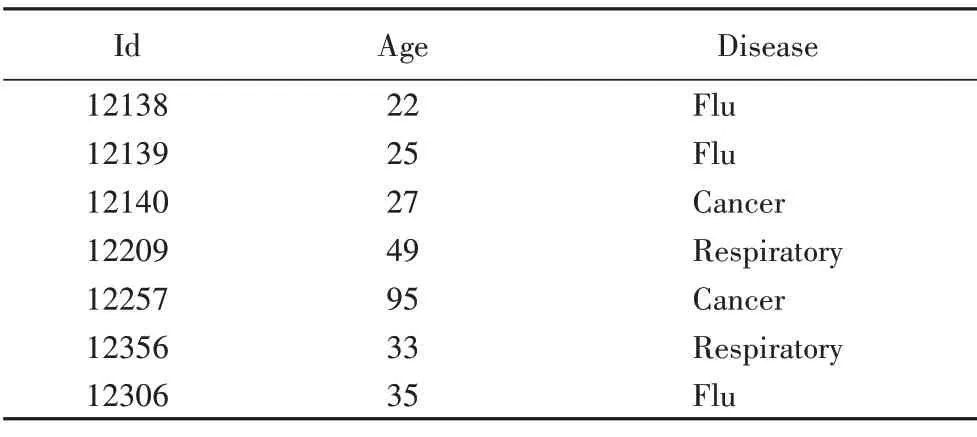
表1 病人数据Tab.1 Data of patients
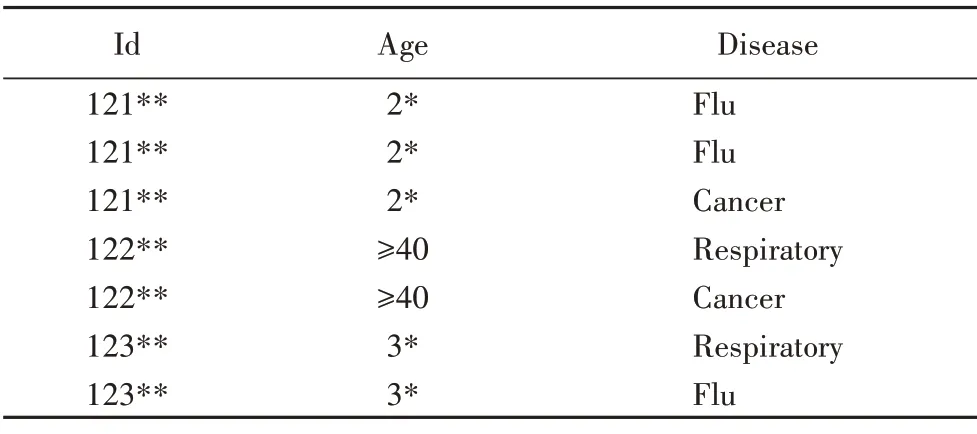
表2 病人数据匿名化Tab.2 Anonymization of patient data
如表3 是一个只包含0 或1 的二值化数据表格,{X1,X2,X3,X4,X5}是准标识属性,Y是敏感属性,不满足K-匿名条件,如果隐藏属性{X4,X5},保留{X1,X2,X3},即可使得数据达成2-匿名,这一操作相当于对数据进行特征选择,把使得数据达成K-匿名条件的一系列特征选择方法统称为K-匿名特征选择方法,所以K-匿名特征选择可以归类为K-匿名模型两大主要手段之一的隐藏操作。
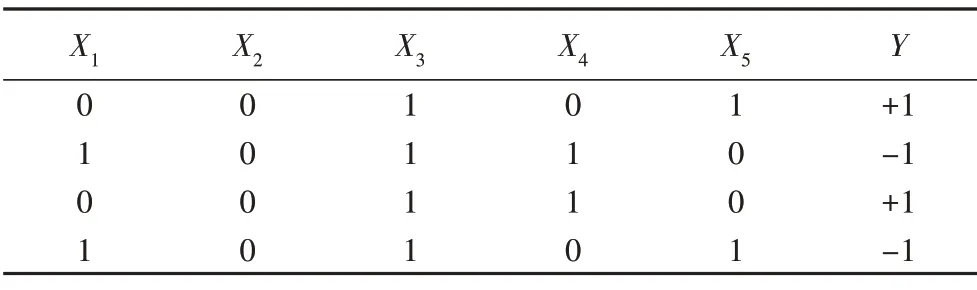
表3 2-匿名特征选择Tab.3 Two-anonymous feature selection
文献[15]中将K-匿名条件作为特征选择的约束条件,平衡数据的分类性能与隐私保护能力。如表3 所示,除了特征子集{X1,X2,X3},特征子集{X3,X4,X5}也可以使表3数据达成2-匿名,然而使用不同的特征子集,降维后的数据在模型中的分类表现也不同,选择既具有隐私保护能力又能保证数据分类性能的K-匿名特征子集是K-匿名特征选择问题的关键任务。借鉴文献[15]中的概念将本文的K-匿名特征选择问题形式化描述为:

其中:DS表示数据D在特征子集S上映射的数据;f是衡量特征子集分类性能的函数;EC()表示数据中等价类包含的记录数目;k是K-匿名模型的k值。
2 混合式K-匿名特征选择算法
本章主要介绍本文提出的混合式K-匿名特征选择算法HKFS。
2.1 过滤式评价准则
1)特征重要性排序:为了保证候选子集具有一定的分类性能并减少最优特征子集的搜索空间,本文对预处理后的数据使用XGBoost 计算每个特征的重要性程度,并按照重要性从大到小的顺序对所有特征进行排序[18]。
2)K-匿名条件:本文将K-匿名条件作为特征选择的一种评价准则。假设数据T是d维数据,特征子集s(||s≤d),数据T按照特征子集s进行特征选择,保留s中的特征,删除其他特征,如果特征选择之后的数据T含有q个不同的等价类,且每个等价类包含的样本数量都不小于给定的阈值k,则这个特征子集满足K-匿名条件。因为独立于分类器,只考虑数据内部关系,所以K-匿名条件是一种典型的过滤式特征评价准则。
2.2 生成候选子集
如算法1(过滤式模块)所示,它的输入数据D只含有准标识符属性,不包含敏感属性,原始数据D在数据预处理阶段进行泛化操作,将数据二值化,在经过特征排序后,再将预处理过的数据送入K-匿名判别模块。
算法2 是K-匿名判别模块K-test,第2)~9)行找出所有等价类,并记录它们的长度,存入字典record;第10)~14)行判断每个等价类的长度,即字典record 存入的每个值大小,只要有一个值小于k,就表明这个数据D′不满足K-匿名。在判别K匿名条件时,第一轮从当前最重要特征开始搜索到最后一个特征,第二轮从次重要特征开始搜索到最后一个特征……以此类推。每轮初始化一个空特征子集,依次把每轮搜索到的每个特征放入候选子集,在K-匿名判别模块里判断此时数据是否符合K-匿名条件。如果加入该特征使得数据具有K-匿名性,则将该特征留在候选子集中,否则剔除出候选子集,这种方法可以保证最终输出所有候选子集都是满足K-匿名隐私保护条件的K-匿名特征子集。
算法1 过滤式模块。

算法2 K-test。


2.3 获取最优子集
在2.2 节中得到了若干个K-匿名特征候选子集,这些候选子集映射数据即匿名化后的数据都满足K-匿名条件,具有隐私保护能力。需要在所有K-匿名候选子集中选择一个最优子集,本文将每个候选子集映射数据按照3∶7 的比例分为测试集与训练集,在每个训练集上都训练一个分类器,最后把分类准确率最高的特征子集作为特征选择结果。本文在这一环节设计了一个封装式模块来选择最优子集,具体伪代码如算法3 所示,其中评价函数J就是封装在算法内部的分类器,用于评价特征子集的分类准确率。
算法3 封装式模块。

3 实验与结果
通过多项实验来验证本文所提出的混合式K-匿名特征选择算法HKFS的性能。
3.1 数据预处理
本文在UCI 机器学习数据库中选择了6 个真实数据集[19],分别是隐私保护领域常用的成人数据集Adult、垃圾邮件分类数据集Spambase,以及与人类疾病相关的乳腺癌数据集Breast Cancer、心脏病数据集Heart Disease、糖尿病数据集Pima Indians Diabetes 和肝炎病毒数据集HCV,每个数据集的样本数量与特征数见表4。

表4 数据集属性Tab.4 Attributes of datasets
按照K-匿名隐私保护的实现步骤,把K-匿名特征选择也分为泛化和隐藏两个阶段。泛化阶段作为第一个阶段,在数据预处理步骤中完成,将数据泛化到不同区间,以原有特征值不同的区间作为新的特征,新的特征值取0 或1,从而使得数据0-1 二值化,并具有初步的保护数据隐私的效果,也方便接下来的K-匿名特征选择或隐藏操作。以隐私保护领域最常用的成人数据集Adult 为例,将Adult 数据集按照正负类原始比例随机抽5 000 条样本进行实验,正类为年收入大于5 万的用户记录,负类为年收入小于等于5 万的用户记录。原始特征包括6 个连续特征如年龄、教育程度等,以及8 个离散特征如性别、职业、婚姻状况等。将连续特征进行OneHot编码,与离散化特征一起泛化,根据不同泛化范围,将数据进行0-1 二值化,例如年龄值泛化到(0,20]、(20,40]、(40,60]、(60,80]、(80,∞)。
3.2 实验设置
为了验证本文算法HKFS 的有效性,选择了最新的K-匿名特征选择算法XGB-KA[16]作为对比方法,为了清楚表达本文算法的优势,把XGB-KA 作为过滤式对比方法(Filter method),把基于本文算法同样搜索策略但没有进行过滤式特征排序的方法作为封装式对比方法(Wrapper method):
1)Filter method(过滤式K-匿名特征选择算法XGB-KA):计算特征重要性分数并根据特征重要性程度由大到小进行排序,按顺序判断特征子集是否满足K-匿名条件选择K-匿名特征子集。
2)Wrapper method:所有特征不进行过滤式排序,按照自然顺序依次判断K-匿名条件,采用与本文HKFS 算法相同的搜索策略选择多个候选子集,最后从中选择出分类性能最优的特征子集。
首先对数据进行数据预处理,经过3.1 节中数据预处理与泛化操作之后,数据已具有初步的隐私性。然后使用K-匿名特征选择方法对预处理过的数据进行特征选择,即隐藏操作,从而得到K-匿名特征子集与匿名化的数据集,选用线性支持向量机(Support Vector Machine,SVM)作为分类器,采用十折交叉验证(10-fold cross-validation)来测试分类准确率Acc(Accuracy),结果的平均值作为分类器分类性能的估计。准确率的计算公式如下:
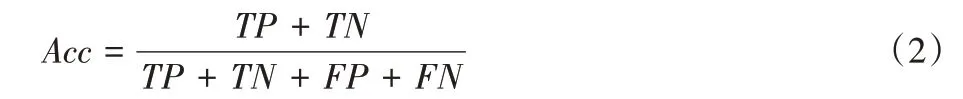
其中:TP是正确分为正类的样本数,TN是正确分为负类的样本数,FP是错误地分为正类的样本数,FN是错误地分为负类的样本数。
由于本文提出的HKFS 算法目的是权衡数据的隐私保护能力与分类性能,K-匿名特征选择算法既可以作为一种数据预处理方法也可以作为一种隐私保护K-匿名化算法,所以选用K-匿名算法经典度量指标[20]——平均等价类大小(CAVG)。CAVG指标基于K-匿名化以后的等价类的大小来衡量数据的匿名化程度,如果所有等价组中平均包含的样本数量越接近k值则表明信息损失度越低,匿名化质量越高。计算公式如下:

其中:Total_records表示整个数据的记录条数(或数据集的样本总数量);Total_equivalence_classes表示匿名化以后等价类的个数。
3.3 实验结果与分析
实验环境:AMD Ryzen5-4600H @3.00 GHz CPU;16 GB内存;Windows 10(64 位)操作系统;实验代码基于Python 3.8实现。对本文的HKFS算法进行了两组实验:1)在6个数据集上比较不同k值情况下各个特征选择算法的分类性能;2)比较不同数据集下,本文算法与其他算法不同k值情况下平均等价类大小度量指标的差异。
3.3.1 不同算法在各数据集下的分类准确率
在K-匿名隐私保护模型中,k值越大表示等价类包含的样本数目越多,也就意味着数据发布时具备的隐私性更高。由图1可以看到,三种特征选择算法的分类性能都会受k值的大小影响,在大多数情况下特征选择分类性能都会随着k值的增大而下降,因为k值增大需要等价类包含的样本数量更多,随着k值的逐渐增大,达到K-匿名的条件也越来越苛刻,三种K-匿名特征选择算法即使都会平衡数据分类性能与隐私保护能力,也无法避免在一些数据集上因为k值增大而引起的分类性能下降。在大多数情况下,如图1(a)、(c)、(d)、(f),只要数据开始匿名化(k>1)分类性能都会下降,而本文的HKFS 算法在多数数据集上都要好于过滤式方法与封装式方法,可以更好地平衡数据隐私保护能力与分类性能。
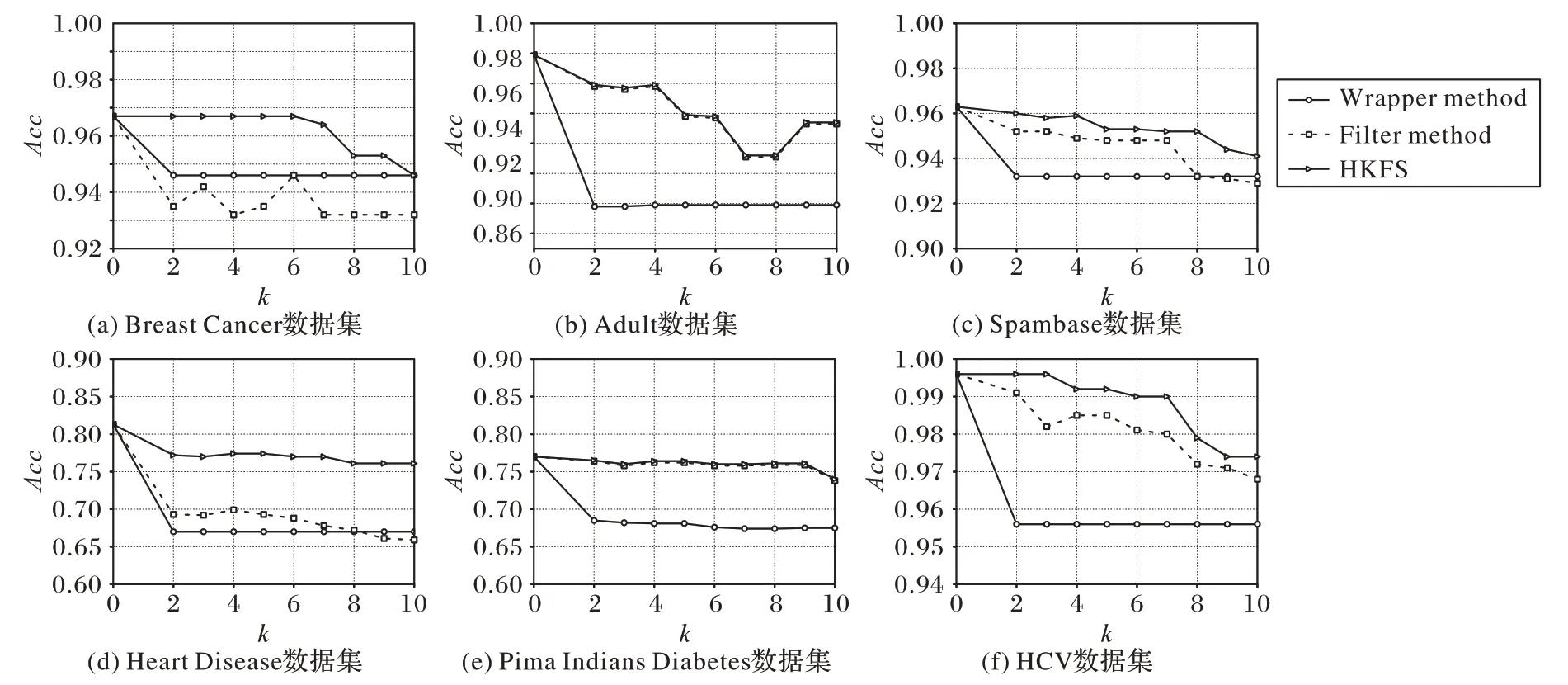
图1 三种特征选择算法分类准确率比较Fig.1 Comparison of classification accuracy of three feature selection algorithms
如实验结果图1(b)、(e)所示,在数据集Adult 与Pima Indians Diabetes上,HKFS的分类准确率与Filter method(XGBKA)在分类性能上几乎相同,这是因为:1)XGB-KA 作为过滤式特征选择方法对特征排序后,每次将最重要的特征选入最终的特征子集,在很多数据集(尤其是小样本数据)中对分类结果影响最大的就是特征排序后最重要的第一个特征;2)本文HKFS算法选用与XGB-KA相同的特征重要性计算方法,采用了相同的特征排序,在第一个特征起决定性作用的数据集上,会产生相同或相类似的结果。同样在所有数据集上,封装式方法Wrapper method 表现都较差,并且在实现匿名化以后结果十分稳定,也与特征排序有关,因为Wrapper method 采用自然特征排序,而搜索策略的搜索空间有限,最终得到的特征子集效果会比较差。
3.3.2 数据匿名化质量评价
本文提出的HKFS 算法既可以作为一种特征选择数据降维方法,也可以作为一种K-匿名隐私保护算法模型。K-匿名模型是为了数据匿名化以后每个等价类中包含的记录数目至少为k,而为了数据质量与匿名化数据信息可用性,理想状态下希望每个等价类包含的记录数目都尽可能接近k。所以,CAVG越小越好。在6个UCI数据集上进行实验,将性能较好的过滤式K-匿名特征选择算法XGB-KA 作为Baseline 与本文HKFS算法在CAVG指标上作对比,结果如图2所示。

图2 平均等价类大小对比Fig.2 Average equivalence class size comparison
从图2 可以看出,当k比较小,CAVG值一般会比较大,总体来说CAVG值随着k值增大而呈减小的趋势。如图2(a)、(c)、(d)、(e)、(f)所示,在大多数情况下,HKFS 算法的CAVG值都要小于Baseline,表示HKFS 算法得到的匿名化数据质量相对更高。在图2(b)、(e)上,与3.3.1 节图1 结果类似,HKFS 算法依旧表现与Baseline结果相同。
4 结语
本文提出了一种混合式的K-匿名特征选择算法HKFS,结合过滤式特征选择与封装式特征选择的特点,把K-匿名判断条件作为特征选择的评价标准,将K-匿名特征选择归类为K-匿名隐私保护中的隐藏手段。搜索尽可能多的候选子集,使用封装式分类器评价候选子集分类性能,从而选出高效且具有隐私保护能力的特征子集。本文K-匿名特征选择算法仅考虑了特征子集分类性能与隐私保护能力的平衡性,未来还可以考虑特征子集的其他性能与隐私保护能力的平衡,设计更多样化的隐私保护特征选择方法。
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
中学生数理化·高一版(2022年1期)2022-04-05
中文信息(2017年12期)2018-01-27
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
高中生·天天向上(2015年11期)2015-10-21
数学教学通讯·初中版(2015年5期)2015-06-17
都市丽人(2015年4期)2015-03-20
