
基于异构图注意力网络的微博谣言监测模型
2022-01-05 02:31潘慧瑶隋京言王耀君
计算机应用 2021年12期
毕 蓓,潘慧瑶,陈 峰,隋京言,高 扬,王耀君*
(1.中国农业大学信息与电气工程学院,北京 100083;2.北京理工大学计算机学院,北京 100081;3.北京工业大学经济与管理学院,北京 100124;4.中国科学院计算技术研究所,北京 100190)
(∗通信作者电子邮箱wangyaojun@cau.edu.cn)
0 引言
微博即微型博客,是一种基于用户关系分享、传播以及获取简短实时信息的广播式的社交媒体。最早也是最知名的微博是美国Twitter,新浪微博于2009 年面世,是当前中文社交媒体中活跃用户数最多的微博媒体。本文提及的微博指新浪微博,研究使用的微博谣言数据也是来自新浪微博的官方公开数据。
微博谣言是指通过新浪微博传播的,在传播过程中被证实为谣言的内容。微博谣言的内容涉及社会安全、食品安全、社会热点、明星名人等,具有传播速度快、波及面广、危害大等特性。部分涉及社会热点的谣言具有煽动网民负面情绪及破坏社会稳定、扰乱公共秩序、削弱公权部门权威性等特点,破坏性极大。如果可以根据微博的传播模式,设计算法模型在微博谣言传播的早期自动监测及预警,然后进一步转交于有公信力的部门及时甄别,可以降低谣言的破坏性。
异构图(Heterogeneous Graph)是指一个图模型中可以存在不止一种节点和边的图,且允许不同类型的节点拥有不同维度的特征或属性。异构图神经网络专门用于处理异构图数据,是当前热门的算法,被应用于生物医学[1]、人机交互[2]和网络安全[3]等领域。而引入注意力机制的异构图注意力网络(Heterogeneous graph Attention Network,HAN)在DBLP、IMDB和ACM 等科研平台和机构发布的多行业公开数据集上的实验结果都优于几种常用异构图算法[4]。本文主要探索异构图注意力模型应用于包括社交媒体的信息传播网络分析场景中的效果,基于异构图注意力网络构建谣言监测模型,通过对传播内容及传播网络的分析,实现新浪微博的谣言监测。
1 相关工作
1.1 谣言监测模型
在早期的研究中,网络谣言监测工作主要集中于从文本内容、用户信息和传播结构中手动提取特征,训练传统机器学习分类器实现谣言识别和谣言监测。例如,Castillo 等[5]的决策树、Kwon 等[6]的随机森林和Yang 等[7]的支持向量机(Support Vector Machine,SVM)。Ma 等[8]在训练SVM 分类器时,考虑了谣言的时间特征,利用时间序列建模技术来整合各种谣言信息。此外,Ma 等[9]还提出了传播树核模型,这是一种基于核的方法,通过分析传播树结构之间的相似性来识别谣言。
近年来出现了一些使用深度学习模型来识别社交媒体谣言的方法。首次应用神经网络模型监测谣言的是Ma等[10],他们利用递归神经网络(Recursive Neural Network,RNN)学习网络谣言的文本表示。Chen 等[11]改进了该方法,提出了一种基于RNN 的深度注意力模型,为不同的文本特征分配不同的权重。Yu 等[12]则提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的方法,利用CNN 学习输入序列的关键特征,形成重要特征之间的高层交互。而Liu等[13]的时间序列分类器结合了RNN 和CNN,对用户特征在传播路径上的全局和局部变化分别进行捕获。最近,Ma等[14]还采用了对抗学习方法,利用生成对抗网络(Generative Adversarial Network,GAN)的生成器产生冲突和噪声,迫使鉴别器从增强的、更具挑战性的例子中学习更强的谣言指示性表示。
采用传统机器学习方法进行谣言监测,不仅费时费力,而且这些手动提取的特征往往缺乏从谣言传播网络中提取的高层表示。深度学习方法能自动学习谣言的高级特征,但这些方法不能处理图或树的全局关系,并没有充分利用微博的传播信息。
1.2 图神经网络
传统的深度学习方法被应用在提取欧氏空间数据的特征方面取得了巨大的成功,但处理非欧氏空间数据的表现却仍难以使人满意。为了分析复杂的图数据,Gori 等[15]提出了图神经网络(Graph Neural Network,GNN)模型。Kipf 等[16]将深度学习中常用于图像的CNN 推广到图数据上,创建了图卷积网络(Graph Convolutional Network,GCN),在此基础上Pei等[17]设计了图卷积深度神经网络模型Geom-GCN 来更好地捕获结构信息和长距离依赖。受到注意力机制的启发,Veličković 等[18]设计了图注意力网络(Graph Attention neTwork,GAT)。该模型根据相邻节点的表示来计算每个节点的中间表示,而不需要进行代价高昂的矩阵运算,但模型只适用于同构图。在探索注意力机制应用于异构图的效果方面,Wang等[4]提出了异构图注意力网络(HAN)。
2 本文方法及建模
微博是一个广播式的社交平台,用户通过关注机制分享、传播以及获取简短的实时信息,这种信息传播网络可以建模为一张异构图[19]。本研究提出了一种基于异构图注意力网络的模型MicroBlog-HAN 用于谣言微博的识别,为了描述简便,简称为MHAN模型。
每一条微博的异构图网络包含至少两个节点,即微博主贴内容及主贴的用户名;如果有转发和评论,每一次转发及评论都分别可构建为异构图中的一个节点。节点之间用三种边连接:用户-微博、用户-评论/转发、微博-评论/转发,如图1所示。
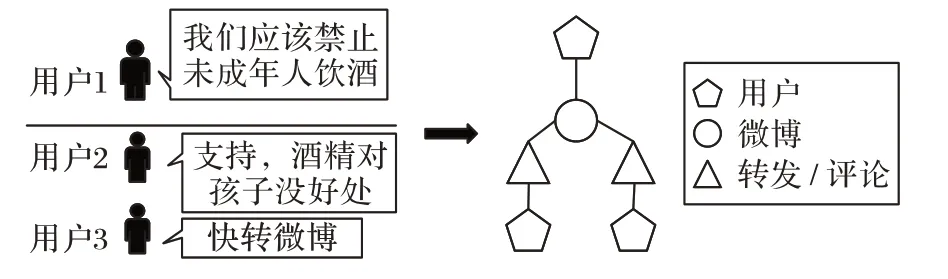
图1 微博的信息传播网络异构图示例Fig.1 Example of heterogeneous graph of microblog information dissemination network
2.1 异构图元路径
元路径是微博异构图的重要组成。异构图的一条元路径Φ[20]可以定义为:
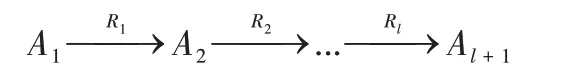
可简略表示为A1A2…Al+1。该元路径描述了节点A1到Al+1的一个复合关系R=R1∘R2∘...∘Rl,∘代表关系的复合操作。在微博数据构成的异构图中,微博之间有可能形成多种元路径连接,不同的元路径包含不同的语义信息。例如“W1-U1-W2”和“W1-P1-U1-P2-W2”为微博异构图中的两条元路径,前者代表两条微博W1和W2是由同一用户U1发布的,后者代表两条微博W1和W2被用户U1转发或评论。
2.2 基于元路径的邻居
给定元路径Φ,节点i基于元路径Φ的邻居被定义为通过元路径Φ与节点i连接的节点集。需要特别说明的是,节点的邻居包括自身。同样以微博异构图为例,假设微博Wi由用户Uj发布,给定元路径模式“W1-U1-W2”,微博Wi基于该元路径模式的邻居是用户Uj发布的所有微博的集合,包括Wi本身。
2.3 异构图注意力网络模型构建
通过2.1 节和2.2 节定义了异构图元路径和基于元路径的邻居后,可进一步定义异构图注意力网络。HAN 模型采用分层的注意力结构:第一层是节点级注意力,目的是学习每一个节点基于元路径的邻居的权重,并对其进行聚合,得到特定语义的嵌入;第二层是语义级注意力,目的是学习元路径之间的差异,得到特定语义的节点嵌入的最优加权组合[4]。图2描述了这两个层级的注意力聚合过程。下面分别对两个层级的构建原理和构建过程进行详细描述。

图2 HAN模型的分层注意力结构Fig.2 Hierarchical attention structure of HAN model
2.3.1 节点级注意力
首先通过微博的传播网络构建元路径Φ1(W1-U1-W2)和Φ2(W1-P1-U1-P2-W2);然后利用自注意力机制学习微博节点基于元路径的邻居的重要性。利用word2vec 提取微博i的文本特征作为节点i的初始嵌入hi;接着以初始嵌入为输入,利用节点级注意力深层次神经网络计算元路径权重;最后,对所有通过softmax归一化,得到权重系数。详细计算过程如下:

将邻居节点的特征和相应的权重系数聚合,就可以得到微博异构图节点i基于元路径Φ的嵌入。为了稳定训练过程,模型采用多头注意力机制,重复计算节点级注意力K次并连接计算结果,作为微博i特定语义的嵌入,最终节点i的节点级节点嵌入的计算公式为:

2.3.2 语义级注意力
将所有微博节点的特征输入节点级注意力后,可以得到两组语义特定的节点嵌入,记作。语义特定的节点嵌入只能从一个方面反映节点,只能反映被同一用户发布的语义,只能反映被同一用户转发/评论的语义。为了融合两种语义,学习更全面的节点嵌入,使用语义级注意力学习每个元路径的重要性,softmax 归一化得到每个元路径的权重系数,计算过程如下。

其中:attsem是语义级注意的深层神经网络,模型结构如图3 所示;W为权重矩阵;b为偏置;q为语义级注意力向量;V为微博节点集,||V表示微博节点数目。q与特定语义的节点嵌入的非线性变换做内积,对结果进行平均得到wΦi,wΦi可以用来衡量元路径Φi的重要性。

图3 attsem神经网络结构Fig.3 Structure of attsem neural network

Z为聚合了元路径Φ1和Φ2的语义信息的语义级节点嵌入,包含被同一用户发布、转发和评论的语义信息,是最终的微博节点嵌入,可以输入到多层感知器中执行二分类任务,使用交叉熵作为损失函数。
3 实验数据及结果
3.1 实验数据
模型在两个真实的微博谣言数据集上对模型进行评估,分别是Weibo2016 和Weibo2021。其中:Weibo2016 数据集是由香港浸会大学的Ma 等[10]提供,其谣言微博数据来自2016年之前微博社区管理中心公布的不实微博信息;Weibo2021数据集是通过爬虫从微博社区管理中心的公开数据进行采集获取,采集了2019—2021 年间被官方证实的谣言微博及其评论转发数据。为保证数据样本均衡,同时也采集了同时间段的数量相近的非谣言微博。表1 展示了两个数据集的样本信息。其中,本文研究采集的Weibo2021 数据集已上传到https://github.com/lemon-coder/Weibo2021-dataset。

表1 Weibo2016和Weibo2021数据集的统计信息Tab.1 Statistics of Weibo2016 and Weibo2021 datasets
3.2 实验结果
MHAN 模型使用8 个注意力头,并用随机梯度下降法更新参数,Adam 算法优化模型,学习率为0.005。训练过程在200 个epoch 上迭代。每个微博节点初始的特征向量的维数为6 000,训练集与测试集的比例为6∶4。实验采用了如下4个结果评价指标。
准确率:在谣言及非谣言数据上的识别准确率;
精确率:正确预测为正的占全部预测为正的比例;
召回率:正确预测为正的占全部实际为正的比例;
F1打分:精确率和召回率的调和平均数。
基于Weibo2016 数据集,将MHAN 及MHAN 衍生模型与以下模型比较,实验结果如表2 所示。其中MHAN 及其衍生模型以外模型的实验结果来自Ma等[10]的研究。

表2 各模型在Weibo2016数据集的实验结果Tab.2 Experimental results of different models on Weibo2016 dataset
DTR[21]:基于决策树的模型,通过查询短语检测谣言的排序方法。
DTC[5]:利用谣言特征组合的决策树模型。
RFC[6]:利用谣言特征组合的随机森林模型。
SVM-RBF[7]:结合谣言特征的RBF核支持向量机模型。
SVM-TS[8]:对谣言特征随时间的变化进行建模的支持向量机模型。
GRU[10]:基于RNN,从用户评论中学习时态语言模式的模型。
MHANWUW:只考虑“W1-U1-W2”元路径的MHAN。
MHANWPUPW:只考虑“W1-P1-U1-P2-W2”元路径的MHAN。
此外,使用了近3 年的Weibo2021 数据集对MHAN 进行实验,实验结果如表3所示。

表3 MHAN模型在Weibo2021数据集的实验结果Tab.3 Experimental results of MHAN models on Weibo2021 dataset
3.3 结果分析
如表2 所示,依赖人工提取的机器学习谣言识别模型(DTR、DTC、RFC、SVM-RDF 和SVM-TS)在Weibo2016 数据集上表现普遍较差,测试集准确率都在90%以下。这说明人工提取的文本、用户和传播等特征只能在一定程度上反映谣言特征,缺乏更高层的表示。
GRU 在测试集上的准确率和F1 都高于传统机器学习分类器。这是因为:一方面,作为神经网络模型,GRU 能自动学习深层的潜在特征;另一方面,GRU 能捕捉相关微博的信息随时间的变化。
MHAN 的表现优于其他模型,测试集准确率达到了91.2%,说明模型泛化能力较强。该模型具有良好的可解释性,利用注意力机制分别提取“被同一人发布”和“同一人转发评论”这两种语义信息,最后融合两种语义,充分挖掘了微博异构图基于语义的结构信息。对比MHAN、MHANWUW和MHANWPUPW在测试集上的准确率和F1 都较低,说明在谣言监测任务中,这两个元路径的语义都是有意义的。
表3 的实验结果显示,在Weibo2021 数据集上,MHAN 模型的准确率和F1都在85%以上,而MHANWUW和MHANWPUPW表现较差,进一步验证了MHAN 模型的有效性,且能适用于泛化的数据集。
同时,对实验数据进行分析发现,发布微博谣言的用户往往还具有发布其他不实言论的历史。另外一个有意思的发现是:谣言举报者常常是同一批用户,说明谣言的受众有重叠且有些用户有很强的谣言甄别能力和检举意识。
4 结语
本文将微博数据构建成一张异构图,并利用异构图注意力网络建立微博谣言监测模型。经过在谣言实验数据的验证,结果表明MicroBlog-HAN 模型在谣言分类任务上的表现优于其他模型。
在未来的工作中,将尝试结合图片、视频和用户信息提取微博更全面的特征,在保障召回率的前提下,进一步提高分类的准确率。另外,将探索自动提取元路径的方法,进一步挖掘微博异构图的信息。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
北京航空航天大学学报(2022年8期)2022-08-31
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
环球时报(2022-04-13)2022-04-13
小雪花·小学生快乐作文(2020年4期)2020-10-12
福建基础教育研究(2019年11期)2019-05-28
民生周刊(2017年22期)2017-12-12
新高考·高一数学(2016年10期)2017-07-06
长江学术(2015年1期)2015-02-27
