
基于时空上下文信息增强的目标跟踪算法
2022-01-05 02:31温静,李强
计算机应用 2021年12期
温 静,李 强
(山西大学计算机与信息技术学院,太原 030006)
(∗通信作者电子邮箱wjing@sxu.edu.cn)
0 引言
视觉目标跟踪作为计算机视觉领域的重要课题,主要用于研究视频帧之间对象的时空关联性,在自动驾驶、智能交通监控、人机交互、医学诊断和行为识别等诸多领域有着广泛的应用[1]。依据跟踪目标数目的不同,目标跟踪可分为单目标跟踪和多目标跟踪,本文主要研究单目标跟踪。单目标跟踪旨在给定某视频第一帧中任意目标的位置和大小,在视频的后续帧中预测该目标的位置和大小。
目标跟踪的早期研究主要利用边、角和轮廓等视觉特征进行目标跟踪。视觉跟踪算法的基本框架一般由搜索策略、特征提取和观测模型等模块组成。传统机器学习算法在特征提取阶段主要采取方向梯度直方图[2]、颜色特征提取(Color Names,CN)[3]等方法,这些方法存在特征信息不完整、有噪声等缺点,导致跟踪精度下降。
近几年基于卷积神经网络(Convolutional Neural Network,CNN)的特征提取算法在视觉目标跟踪上得到了广泛的应用。Danelljian 等[4]利用预训练VGG(Visual Geometry Group)网络提取目标的深层特征与浅层特征,并将提取到的特征融入相关滤波器。基于预训练网络的深度特征提取算法增强了特征的外观表征能力,提升了算法精度,但网络参数过多以及目标模型的在线更新导致算法的跟踪速度满足不了实时的要求。
针对基于预训练网络跟踪算法因其网络参数频繁在线更新而导致时间效率较低的问题,Bertinetto 等[5]提出了一种基于全卷积孪生网络(Fully-Convolutional Siamese Network,SiamFC)跟踪算法。该算法通过计算候选区域和目标模型的相似度来预测目标的最终位置。SiamFC 在跟踪过程中不需要在线更新网络参数,显著提升了跟踪算法的时间效率。在SiamFC 算法的基础上,Li 等[6]结合了SiamFC 和Faster R-CNN中的区域生成网络(Region Proposal Network,RPN)模块提出了SiamRPN。当SiamRPN 算法预测到正确的目标时,会预测跟踪目标的长宽比给出更为精确的box 尺度,使得跟踪算法达到了较高的精度。Wang 等[7]发现当物体发生旋转时,简单的box表述会产生极大的损失。Wang等认为通过直接预测物体的mask 可以得到更准确的box。基于此,Wang 等提出了对视觉目标跟踪(Video Object Tracking,VOT)和视频目标分割(Video Object Segmentation,VOS)的统一算法SiamMask。SiamMask 缩小了任意目标跟踪与VOS 之间的差距,在视频跟踪任务上达到了最优性能,并且在视频目标分割上取得了当前最快速度。
虽然上述跟踪算法实现了较好的跟踪性能,但通过实验发现SiamMask 存在一些问题。图1(a)显示中间人物是待跟踪目标,上方人物是相似的目标。图1(b)是得到的特征置信图,从置信图可以发现相似目标对跟踪目标会产生干扰,进而导致目标框选位置发生偏移,如图1(c)所示。因此,考虑利用视频帧之间时空上的高度关联性来增强跟踪目标的特征显著性,改进后的响应图如1(d)所示,得到了更精确的位置响应。
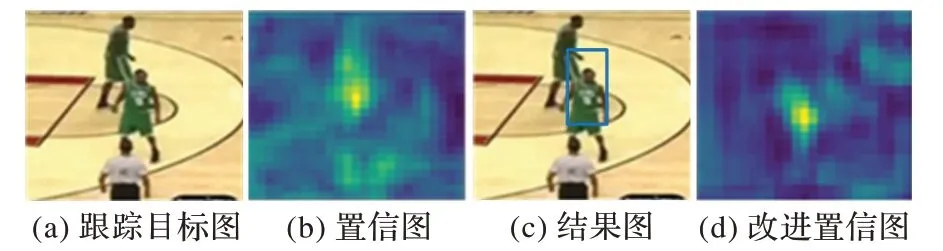
图1 相似干扰目标Fig.1 Similar interference object
为了充分利用时空上下文信息,本文在SiamMask 算法的基础上引入一个短期的记忆存储模块来存储历史帧的外观特征。然后,利用历史帧和当前帧的目标特征具有强相似性,提出了外观显著性增强模块(Appearance Saliency Boosting Module,ASBM)。该模块利用历史帧和当前帧特征相关性,进一步增强当前帧的目标特征,最终提高跟踪的精度。
1 时空上下文信息增强算法
为了任务的多样性和跟踪的实时性,本文采用了基于多任务全卷积的孪生网络框架。
1.1 算法的整体结构
本文主要基于SiamMask 算法[7]来构建网络体系框架。当进行跟踪任务时,网络的上分支主要负责提取视频目标的特征信息,网络的下分支主要负责提取视频当前帧的特征信息;之后将两个特征图做互相关,得到候选区域的响应特征。为了跟踪任务的准确性,本文采用了两种不同生成旋转框的方式:一种是通过RPN 模块生成固定长宽比;另一种是根据分割分支生成旋转框。将响应特征采用第一种生成旋转框策略仅得到跟踪结果,将响应特征采用第二种生成旋转框策略将得到跟踪和分割结果。
为了充分挖掘视频目标跟踪任务中丰富的时空线索,本文对孪生网络的下分支进行了改进,在图2 中展示了训练网络的总体框架。如图2所示,上支以127×127大小的图像作为模板输入,下支以255×255 大小的图像作为输入;经过共享权重的ResNet-50 框架Φ提取图片信息特征,对于网络下支,提出短期记忆存储池保留了视频的历史帧特征信息;其次通过外观显著性增强模块捕获上下文信息,实现当前帧特征的显著性增强,减少环境中相似物体的干扰;再次,对上下支进行特征互相关;最后,通过卷积激活得到目标跟踪和分割结果。
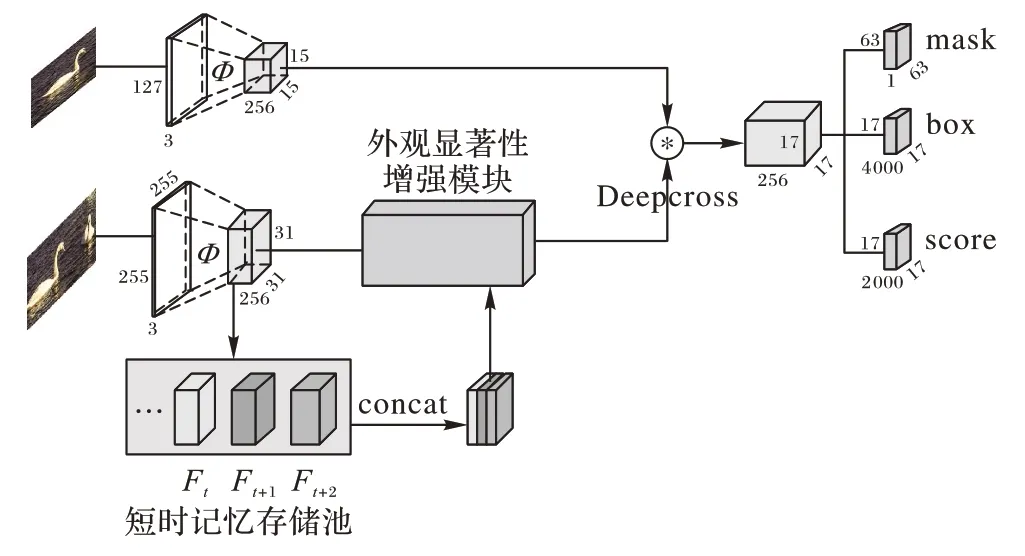
图2 时空上下文信息增强结构Fig.2 Spatio-temporal context information enhancement structure
1.2 短期记忆存储池
视频上下帧之间具有强时空关联性。目前大多数流行的跟踪算法只利用当前帧特征信息进行目标跟踪,当该帧跟踪结束后,将重新初始化下一帧进行跟踪。这些算法缺乏对同一目标在相邻视频帧之间关系的利用。图3为利用CNN提取视频中特征信息的热度图结果。通过实验发现不同帧中提取出来的特征通常关注物体相同的显著部分。为了充分利用历史帧中潜在的显著特征,本文引入短期记忆存储池来保留历史帧特征。具体而言,在记忆存储池中动态地保留了包含当前帧的三帧视频特征(Ft,Ft+1,Ft+2),之后将拼接后的三帧特征送入ASBM。

图3 热度图Fig.3 Heat map
1.3 外观显著性增强模块
本文借鉴图匹配[8]和查询记忆机制[9]的思想提出了一种基于特征对齐的ASBM。
1.3.1 特征对齐
目标特征存在于历史帧中不同的位置,这就导致提取出来的目标显著特征位置不一致,必须以某一帧为基准对其他帧的特征进行调整对齐。因此,本文利用图匹配以当前帧的特征为基准重建历史帧的特征以达到对齐的目的。图匹配通过计算场景图像特征和参考图像特征的余弦相似度来建立场景图像和参考图像特征之间的相关性。在网络中体现为,以当前帧特征为参考信息,将历史帧特征作为场景信息,通过将当前帧特征和近邻帧的特征计算余弦相似性得到相似性度量矩阵,然后将历史帧信息与相似性度量矩阵相乘得到重建后的历史帧信息。
1.3.2 特征增强
在特征对齐基础上的特征增强可以提高目标的显著性,直接对对齐后的特征通道进行简单叠加就可以达到特征增强的目的。这种方法的性能虽然有一定的提升,但是同时也会将历史帧中干扰信息叠加到当前帧中。基于此,本文对上下帧特征的增强方式进行了改进。本文采用一种类似查询记忆(query-memory)机制,通过将当前帧特征与历史帧特征做相似性度量,以此得到当前帧与历史帧中相似目标的相似度,通过相似度可以得到当前帧的显著信息并进行增强。
1.3.3 整体结构
图4 显示了外观显著性增强模块的具体结构,网络上支输入为当前帧的外观特征信息Q∈RH×W×H,下支为历史帧的外观特征信息M∈RS×H×W×D,将上下分支特征经过L2 正则(L2norm)计算,之后将当前帧特征矩阵和近邻帧的特征矩阵进行相乘得到余弦相似度矩阵,将历史帧特征与矩阵相乘得到重建后的历史帧,实现特征对齐。
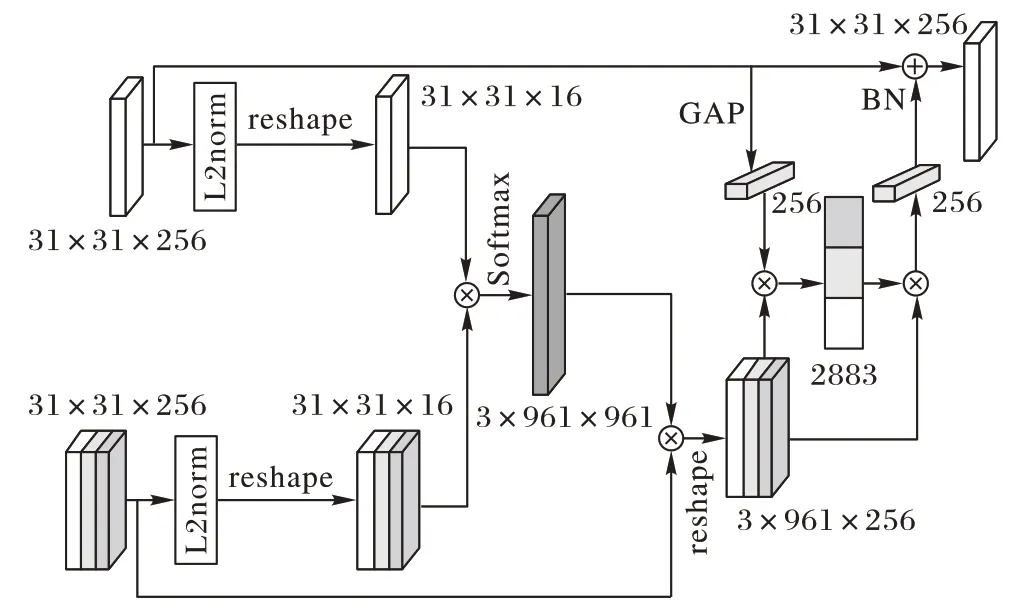
图4 外观显著性增强模块Fig.4 Appearance saliency boosting module
对于特征增强结构,将当前帧的特征映射视为查询帧Q,记忆帧为包含三帧的历史帧特征的集合M,用来增强查询帧Q的表示能力。首先将Q通过全局平均池化操作(Global Average Pooling,GAP)生成信道统计q∈RD,用来作为查询帧的统计描述符;之后将M重构数组维数为M∈R||M×D(M=S×H×W),将M看作一组D维局部描述子,||M为重构完的特征大小,D为重构完特征的维度;接下来,将q和M相乘得到其余弦相似性响应图(式(1)),该余弦相似性就是关于查询向量与存储器中的每个描述符匹配程度的概率图。

其中:Mi∈RD描述了第i个局部描述符,q和M通过二范数正则化后相乘得到P,t是超参数。然后通过算式O=MTP计算存储器中所有描述符值的和。通过这种方式,M描述符中与Q中相似的特征将呈现更高的权重,同时可以避免低质量帧中信息被破坏。
最后,通过式(2),将O以一种残差的方式传递到Q中。其中,BN是一个批规范化操作,用来提高网络的泛化能力。

1.4 损失函数
损失L3B由mask 分支、score 分支和box 分支三部分组成。对于score 分支采用二分类交叉熵损失函数,将anchor 分为正样本和负样本;box 分支主要采用文献SiamRPN 中的smooth_L1损失,首先利用式(3)将anchor的坐标标准化。

其中:x、y、w、h代表矩阵中心的坐标以及矩阵的宽和高;T和A分别代表groundtruth boxes 和anchor boxes。然后通过式(4)计算smooth_L1损失,得到box分支的损失。
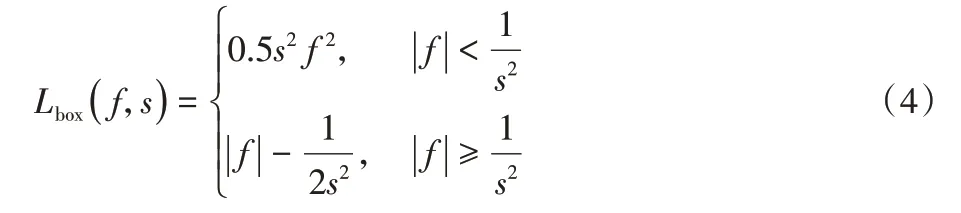
其中:f为anchor 的坐标经过式(3)标准化后的特征图。但对于mask 分支,其损失函数为式(5),其中yn是ground truth 标签,分为1和-1,w、h为mask矩阵的维度。


2 实验结果与分析
将本文算法与SiamMask[7]、SiamRPN[6]、DaSiamRPN[10]、SiamRPN++[11]和 ATOM(Accurate Tracking by Overlap Maximization)[12]进行了对比分析。其中,SiamMask 在多任务框架下完成了跟踪和分割的工作,因此,将本文提出的算法在单任务、带有分割的多任务下与SiamMask算法进行对比。
2.1 实验环境和训练设计
本文算法基于PyTorch框架实现,算法的主干网络采用在ImageNet-1k 分类任务上训练ResNet-50[13]作为预训练网络。训练过程中使用随机梯度下降(Stochastic Gradient Descent,SGD)优化器,前5 个epoch 学习率从10-3到5× 10-4,在15 个epoch内逐渐降到5× 10-4。本文使用COCO[14]、ImageNet-VID[15]和YouTube-VOS[16]数据集训练网络。本文实验在两块NVIDIA 1080Ti GPU,64 GB 物理内存和i7-8700K CPU 上进行跟踪算法训练,在一块NVIDIA 1080Ti 和i7-8700K CPU 上进行跟踪算法的测试,编程语言为Python。
2.2 目标跟踪的评估
为了验证本文算法的有效性,采用了两个广泛使用的数据集进行算法测试:VOT2016[17]和VOT2018[18]。VOT2016 和VOT2018均包含60段视频,60段视频中包含单目标跟踪领域中的难点问题,如相机变化、尺度变化、光照变化和遮挡。VOT2018 将VOT2016 中的一些跟踪准确的序列进行替换,并对于序列的真值进行了重新标定,给出了更为准确的标注信息。根据VOT 的评估协议,本文采用了预期平均重叠率(Expected Average Overlap rate,EAO)、准确率(Accuracy,A)和稳健性(Robustness,R)指标来表示跟踪性能。其中,EAO是一种综合考虑跟踪算法准确性和稳健性的度量指标,该指标越大越好;准确性(A)用来评价跟踪算法跟踪目标的准确度,其值越大表示准确率高;R 表示跟踪算法的稳定性,值越小表示跟踪性能越稳定。
对比实验分为两部分:充分考虑到生成旋转框的策略,在VOT2016 上分别采取box 策略(传统的固定或可变纵横比的轴对齐边界框,即不加目标分割任务mask 分支)和最小外包矩形(Minimum Bounding Rectangle,MBR)策略(通过mask 分支得到分割结果,并根据分割结果得出最小的旋转边框),将其应用于SiamMask 算法和本文提出的SiamAsbm 算法。最终实验结果如表1 所示,本文算法SiamAsbm-box(无分割任务优化旋转框)在准确率和平均重叠率上明显优于基准算法,而在SiamAsbm-MBR 下能获得更优的性能(如表1 中最后一行所示)。MBR 策略生成旋转框的方式相比较传统生成旋转框的策略有着整体的性能提升。

表1 在VOT2016数据集上的实验结果Tab.1 Experimental results on VOT2016 dataset
表2 显示了本文算法与5 种主流的目标跟踪算法在VOT2018 上的实验对比,同样对比了SiamMask 在加入box 和MBR,以及本文算法SiamAsbm 在分别加入box 和MBR 的性能。本文算法SiamAsbm-MBR 在稳健性上相比SiamMask-MBR 降低了2.8 个百分点,在平均重叠率和准确率上提高了1.1 个百分点和3.7 个百分点。本文提出的模块可以得到准确的旋转框使得算法在准确率上优于其他算法,但跟踪任务存在大尺度变化和遮挡问题,因而得不到准确分割结果,导致鲁棒性和平均重叠率提高不明显。
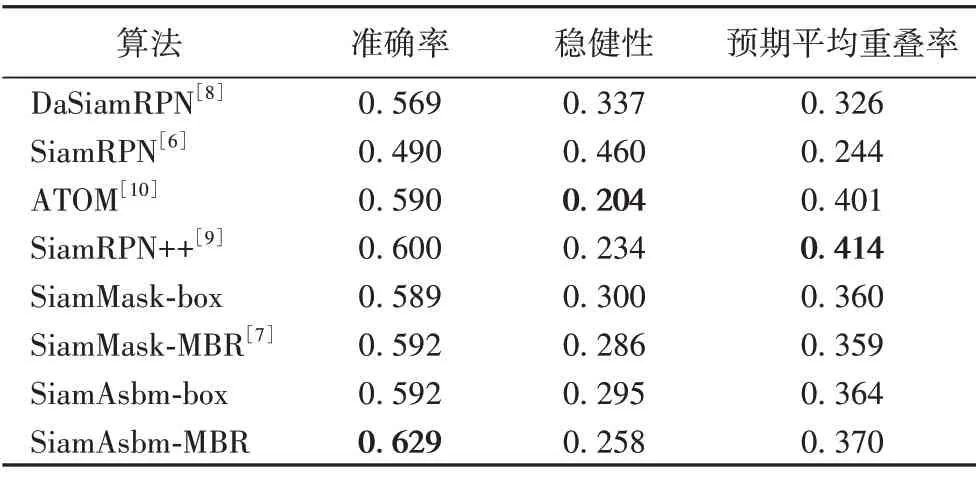
表2 在VOT2018数据集上的实验结果Tab.2 Experimental results on VOT2018 dataset
2.3 消融实验
算法分为基于存储池模块和ASBM 模块,其中,存储池模块可以进行特征叠加操作;ASBM 模块包含两个操作,一个是特征对齐,另一个是对于当前帧的特征信息增强。为了验证本文算法的有效性,采用如下方式进行消融分析。
1)采用文献SiamMask 中的基础网络作为基准网络(Baseline)。
2)在Baseline 中通过短期记忆存储池存储历史帧特征,并进行特征叠加。
3)在Baseline 中保持历史信息,加入特征对齐模块(Appearance Align),进行特征叠加。
4)在Baseline 中保持历史信息,加入外观显著性增强模块ASBM,对当前帧进行特征增强。
从表3 的实验结果可以看出,特征对齐模块相对于跟踪的鲁棒性有明显的增强,特征增强模块对于跟踪的准确率有明显提高。

表3 消融实验Tab.3 Ablation experiment
图5 为跟踪蚂蚁图片,原图中存在较为相似的三只蚂蚁,通过将历史帧特征叠加到当前帧中可以得到图5(b),通过置信图可以看出目标轮廓模糊。之后经过特征叠加到当前帧可以得到图5(c),可以发现目标蚂蚁在置信图中获得了清晰的轮廓,但同时图中还存在一定的干扰物体。当经过特征增强模块之后得到图5(d),可以发现当前跟踪目标的轮廓得到了进一步增强,并且干扰物的信息得到了明显抑制。

图5 置信图Fig.5 Confidence graph
2.4 对多任务算法性能的提升
在多任务中,本文同时对目标进行分割,而跟踪对分割的性能也有明显的提高,这是因为传统算法是在整幅图片上分割目标,而在多任务中,目标跟踪和特征对齐增强都能缩小分割的范围,提高分割的效率。表4 和表5 是本文算法在DAVIS-2016[19]和DAVIS-2016[20]视频目标分割验证集上的结果。DAVIS-2016 和DAVIS-2016 分别包含20 和30 个验证视频,视频中的每一帧以二进制掩码的方式手工创建分割。度量指标分别是区域相似度J、轮廓精度F和时间稳定性T。对于每次度量C∈{J,F}考虑三个统计平均值(mean)、查全率(recall)和下降率(decay),在表中分别表示为JM、JO、JD、FM、FO、FD、TM。表6 则列出了在NVIDIA 1080Ti GPU 的硬件设备条件下,本文算法与其他分割算法的运行时间对比。

表4 在DAVIS-2016数据集上的实验结果Tab.4 Experimental results on DAVIS-2016 dataset

表5 在DAVIS-2016数据集上的实验结果Tab.5 Experimental results on DAVIS-2016 dataset

表6 速度分析 单位:帧率Tab.6 Speed analysis unit:fps
由表4~6 中的数据可以看出,与传统算法相比,本文算法在区域相似度与轮廓精度上的表现虽然不是最优,但速度提升到了32 fps,能满足实时要求;而与能实时处理的SiamMask算法相比,本文算法在大多指标上能获得更好的表现,因为特征增强模块使得特征目标轮廓更加准确;同时,相较于其他方法,本文方法在decay 实现了更低的衰减,这表明本文方法随着时间的推移是稳健的。
2.5 定性分析
图6 显示了本文算法在VOT 和DAVIS 测试集上的结果,其中Iceskater、girl、crabs 属于VOT 测试集,Bmx-trees 和Dogsjump 属于DAVIS 测试集。在VOT 测试集中展示了分割和跟踪结果,DAVIS 展示了分割结果。从图6 跟踪分割结果可以清晰看出,本文算法不论在复杂场景(crabs),还是简单场景(Dogs-jump)都有很好的分割和目标框的结果。除此之外,因为集成了上下文信息,所以本文算法在面对复杂上下文关系(Iceskater、girl)时,仍然能准确进行目标框的检测而不受上下文信息的干扰。但是对于分割数据集,算法由于没有得到更多的训练,导致分割结果在细节信息的处理上不够完善。

图6 跟踪分割结果Fig.6 Tracking and segmentation results
2.6 失败案例
本文算法也会出现跟踪失败的案例。如图7(a)为要跟踪的目标,图7(b)为当前帧。由图7 可以看出,当跟踪物体运动、尺度和形状变化剧烈时会导致跟踪失败,如图7(b)中箭头所指的目标就会丢失跟踪。这是由于训练数据集缺少具有较大仿射变化的样本,同时训练网络缺乏尺度表达能力造成的。

图7 失败案例Fig.7 Failure case
3 结语
本文提出了一种基于时空上下文信息增强的目标跟踪算法。该算法通过引入短时记忆存储池和提出外观显著性增强模块ASBM,可以获得较为完善、清晰的物体外观,有助于提高跟踪和分割多任务的准确性。通过跟踪邻域的VOT2016和VOT2018 数据集上的实验结果表明,本文算法相较于本文中的其他单视频目标跟踪算法在准确率上有很大的提升;而在目标分割邻域的DAVIS-2016 和DAVIS-2017 数据集上的实验结果表明,本文算法相较于本文中其他单视频目标分割算法在速度上达到了实时性要求,但是其他指标提升不够明显。在DAVIS-2016 和DAVIS-2016 数据集上的实验结果表明,本文算法在性能和速度上均有较好的表现;但算法在面对物体剧烈形变时,仍然会出现跟踪失败的情况,有待进一步研究。下一步的工作将利用数据增强手段,进一步增强数据和网络的表达能力,提高目标跟踪的性能。
猜你喜欢
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
时代英语·高二(2021年4期)2021-07-29
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中国知识产权(2018年12期)2018-12-29
中国知识产权(2017年5期)2017-05-25
中学生数理化·高一版(2016年6期)2016-05-14
