
基于图割精细化和可微分聚类的无监督显著性目标检测
2022-01-05 02:31李小雨房体育夏英杰李金屏
计算机应用 2021年12期
李小雨,房体育,夏英杰,李金屏*
(1.济南大学信息科学与工程学院,济南 250022;2.山东省网络环境智能计算技术重点实验室(济南大学),济南 250022;3.山东省“十三五”高校信息处理与认知计算重点实验室(济南大学),济南 250022)
(∗通信作者电子邮箱ise_lijp@ujn.edu.cn)
0 引言
人类的视觉注意力机制可以很好地从复杂场景中提取感兴趣的区域并提供给大脑进行后续分析,如何使计算机模拟此机制并准确、快速地提取图像关键信息,是图像显著性检测的主要目标。随着显著性检测在目标识别、图像压缩、图像自动裁剪等计算机视觉领域的广泛应用,关注它的学者逐年增多,涌现了大量的显著性检测算法。目前显著性检测算法大致分为传统模型和深度学习模型两类。
基于手工提取特征的传统模型[1-4]通常根据输入图像本身利用主成分分析、频率分析等方法提取线索来突出目标并抑制干扰,可以在很少的时间成本下执行,但是检测精度上普遍不高。例如:Achanta 等[1]利用频域颜色特征和亮度特征来计算显著值;Cheng等[4]将像素的显著值定义为它与图像中所有其他像素的颜色差异的加权和。
深度学习模型[5-10]根据人类注释的显著性masks 是否用于训练,可以分为全监督方法和非全监督方法。在全监督方面,Lee 等[6]将编码的低级距离图和VGG 网络提取的高层特征连接起来,并将它们连接到一个全连接分类器来评估显著性。Hou等[7]提出了一种具有多分支短连接的深度监督框架,它嵌入了高层次和低层次的特征来进行精确的全监督显著性检测。非全监督方法分为弱监督方法和无监督方法,它们大多使用图像级分类标签或使用其他任务生成的伪像素标签来注释显著性。在弱监督方面,Wang 等[8]开发了一种仅使用图像级标记的弱监督显著性检测算法,通过将前景推理网络与全卷积网络联合训练来预测图像级标签。而在无监督方面,Zhang等[9]提出“融合监督”,结合图像内融合流和图像间融合流,从无监督显著性模型的融合过程中生成有用的监督信号以监督深度显著目标检测器的训练。Zhang 等[10]用一个潜在的显著性预测模块和一个显式的噪声建模模型组成一种端到端的深度学习框架。
传统的显著性检测模型虽然模型简单并且时间成本低,但分割精度普遍不高,而基于深度学习的模型虽然有较高的精确度,但是训练阶段依赖于大量的手动注释数据或伪像素标签,因此,如何在无人工标记或者少人工标记的情况下对显著性目标进行精确检测是目前该领域面临的一个核心问题。针对该问题,本文提出一种基于图割精细化和可微分聚类的无监督显著性目标检测算法。该算法采用由“粗”到“精”的思想,将显著性目标检测问题分成定位和精细化两个部分进行解决,在无人工标记的情况下仅利用单张图像便可获取精确的目标检测结果。首先,利用Frequency-tuned 算法[1]根据图像自身的颜色和亮度特征进行对比以得到显著粗图;然后根据图像的统计特性进行二值化并结合中心优先假设[11]得到显著目标的候选区域,进而利用GrabCut 算法[12]对单张图像迭代实现能量最小化以实现显著目标的精细化分割;最后,结合具有良好边界分割效果的无监督可微分聚类算法[13]对单张显著图进一步优化,使优化显著图更接近于真值图。
1 算法原理
为了弥补目前显著性检测存在的不足,本文提出一种基于图割精细化和可微分聚类的无监督显著性目标检测算法。该算法整体流程如图1 所示,接下来将以显著性目标粗定位、候选区域的生成、GrabCut 图像精细化分割、可微分聚类优化分割结果四个部分具体介绍本文算法。
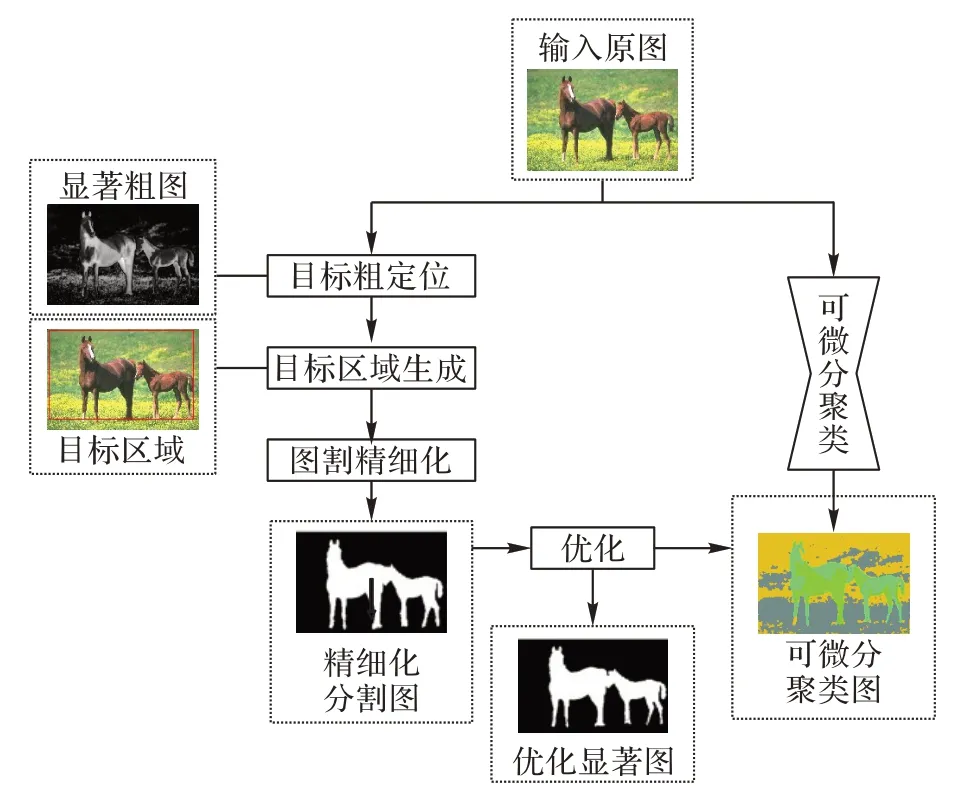
图1 本文算法流程Fig.1 Flowchart of the proposed algorithm
1.1 显著性目标初定位
显著性目标粗定位指的是利用显著性检测算法对图像进行显著性检测,得到一个显著粗图A,用于后续的精细化分割。图像在频率域可以分为低频和高频部分:低频反映图像的整体部分,如基本的组成区域;高频部分反映图像的细节信息,如物体的纹理。显著性目标检测算法更多用到的是低频部分的信息。Frequency-tuned 算法充分考虑这个特点,首先利用高斯滤波排除高频的干扰,再利用颜色和亮度特征来估计中心与周围的对比度以作为显著度,由此得到的显著区域具有明确的边界、完全分辨率和较高的计算效率,生成的显著性映射可以更有效地应用于其他领域。因此,本文采用Frequency-tuned 算法进行初步显著性检测,具有如下的显著性映射定义:

其中:Iμ是图像在LAB 颜色空间的三个通道的算术平均像素值;Iwhc(x,y)是原始图像经过5× 5 高斯模糊后在LAB 颜色空间的像素值;‖ ‖是L2范数。
生成的显著粗图如图2 所示。图2(a)是原图,图2(b)是经过Frequency-tuned 算法得到的显著粗图,可以发现显著粗图中一些背景区域也被突出了。

图2 Frequency-tuned算法显著性检测结果Fig.2 Saliency detection results of Frequency-tuned algorithm
1.2 候选区域生成
由于显著粗图中部分背景区域被突出,自适应二值化得到的候选区域不利于后续的精细化分割。本文则基于图像像素值的统计结果,获取图像像素值的最大值,并设置参数a调节前景和背景的比例,以此获得更加精确的目标二值图B,具体表示如下:

其中,a是0到1的变量。
目标二值图作为下一步分割的先验知识,以指导分割显著目标的准确区域。将二值图中包含所有白像素的相应矩形区域定义为候选区域。部分图像背景与目标的相似程度较高,Frequency-tuned 算法检测出来的显著粗图不够精确,导致目标二值图的白像素覆于整个图像。针对此类情况,本文引入显著性检测的中心优先假设[11]:显著对象更有可能在图像中心附近找到,而边界区域更有可能是背景。充分考虑目标存在于图像边缘时中心优先假设造成的一定程度上的特征丢失,利用参数b调节目标区域的选定。目标区域定义为:

其中:(xmin,ymin)和(xmax,ymax)表示候选区域的矩形对角坐标;表示包含所有白像素的最大矩形区域的对角坐标;b为0到20的变量;W表示图像的宽度,H表示图像的高度。
生成的候选区域如图3 所示。图3 中的第一组图是选取包含所有白像素的最大矩形区域作为候选区域的效果图;第二组图是针对目标二值图的白像素覆于整个图像的情况引入中心优先假设后确定的候选区域效果图。

图3 候选区域选择结果Fig.3 Results of candidate region selection
1.3 GrabCut 图像精细化分割
前文已经对目标进行粗定位并得到一个目标区域,GrabCut 算法通过迭代图形切割优化和边界抠图结合硬分割来处理对象边界上的模糊和混合像素,能够实现很好的分割效果。因此,基于前文所得到的背景区域和可能目标区域,选择GrabCut来实现对显著目标的准确分割。
GrabCut 利用混合高斯模型背景区域和目标区域进行建模,对于每个像素,仅可能来自背景或目标的某个高斯分量。每完成一次分割,便计算一次能量项,即像素n分配目标或背景标签的惩罚与相邻像素n和m之间不连续的惩罚的和,用Gibbs能量项表示:
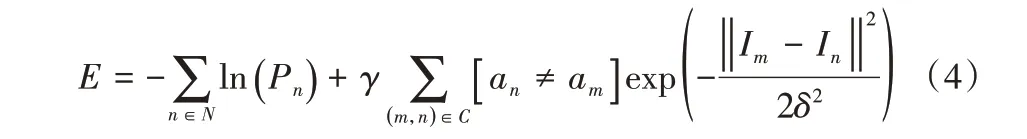
其中:N表示输入图像的像素点集合,C表示相邻像素对的集合;Pn表示像素n属于目标或者背景高斯分量的概率;In和Im分别表示像素n和像素m的RGB(Red-Green-Blue)值;an和am表示像素的类别标签;参数δ指的是高斯模型的方差;γ根据经验取值50。
GrabCut 算法将一次最小割估计算法替换为一个更强大的迭代过程。第一步是对已知背景区域内的每一像素n初始化类别标签an=0;而对已知的可能目标区域内的每个像素n初始化类别标签an=1,再通过k-means 将可能目标像素和背景像素聚类成K类,即高斯混合模型(Gaussian Mixture Model,GMM)模型的K维高斯分量。第二步是根据RGB 值对每个像素分配GMM 的高斯分量并根据给定的图像数据来更新GMM参数。第三步是利用Gibbs 能量项估计最小割。通过第二和第三步交替进行实现最小割估计和参数学习,得到一种使图像Gibbs能量项最小的分割方式。
利用GrabCut 算法对已注释背景区域的图像进行目标精细化分割得到的精细化分割显著图能较好地将显著目标分割并突出,如图4 所示第一组图所示。但当背景和目标相似度高的情况下存在两种问题:一是图割结果中掺杂部分背景,如图4 第二组图;二是图割结果无显著目标或者目标区域极小,如图4第三组图。

图4 精细化分割图示Fig.4 Refined segmentation diagram
1.4 可微分聚类优化分割结果
为了弥补GrabCut 图像精细化分割存在的两种不足,需要寻找一种具有良好边界分割效果的算法来进行优化。基于这种需求,本文引入一种可微分聚类算法,该算法在卷积神经网络(Convolutional Neural Network,CNN)中对单张图像进行微分聚类来实现图像分割,分割结果保留了较好的边缘信息,能够有效解决前文算法的不足。
可微分聚类是一种新的基于单图像的端到端网络的无监督图像分割方法,基于这种思想,设计出如图5 所示的结构。首先,使用CNN 进行特征提取获取图像特征{xn},接着利用q维卷积层计算q维特征图{rn},再使用Batch Norm 进行归一化得到归一化特征图。然后,借助argmax 函数获取每个像素对应特征向量中最大值的ID作为像素类别,以此得到最终的聚类标签{cn} 。最后,使用梯度下降的反向传播方法来更新参数,以找到一个使损失函数L最小化的标签分配解决方案。损失函数L表示如下:

图5 可微分聚类算法流程Fig.5 Flowchart of differentiable clustering algorithm

其中:N表示输入图像的像素点集合;表示在映射中的第i个元素的特征值表示在映射中(ξ,η)处的特征值;µ根据经验取值5,表示平衡这两个约束的权重。
可微分聚类结果如图6(d)所示,针对精细化显著图的两种不足,分别采用不同的方法优化。
针对精细化分割图中包含背景的情况,由于精细化显著图中包含的背景是一些杂质,比例较小,将目标中像素占比最小的像素值所对应区域定义为背景得到优化显著图S,映射关系见式(7)。
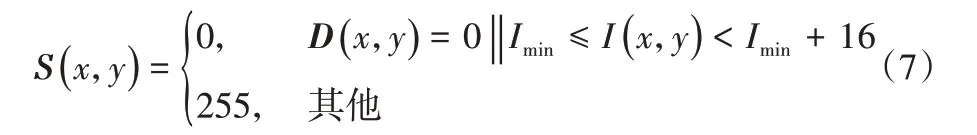
其中:D(x,y)表示精细化分割图中(x,y)处的像素值;Imin表示精细化分割图中目标区域所对应可微分聚类图的区域的统计灰度直方图中占比最少的像素值;I(x,y)表示可微分聚类图中(x,y)处的像素值。
针对精细化分割图无显著目标或者目标区域极小的情况,以目标二值图的最大连通区域为掩膜对可微分聚类图进行感兴趣区域(Region Of Interest,ROI)选择后得到新的目标可能区域,将该区域灰度直方图中除0 像素值以外占比最高的像素值作为种子点Imax来得到优化显著图S,映射关系见式(8)。

利用可微分聚类优化后的结果如图6 所示:从第一组图可以看出,背景噪声被有效抑制;从第二组可以看出,显著目标被准确突出。

图6 可微分聚类优化效果Fig.6 Differentiable clustering optimization effect
2 实验结果与分析
2.1 实验细节
为验证本文提出的基于图割精细化和可微分聚类的无监督显著性目标检测算法的有效性,采用ECSSD[14]和SOD[15]两个国际公开的显著性检测数据集进行实验,其中,ECSSD数据集由1 000 张图像组成,图像结构较为复杂;SOD 数据集是一个更具挑战的数据集,包含300 幅图像,具有多个与背景或与图像边界形成低色彩对比度的显著对象。实验运行环境为Visual Studio 2017 和Pytorch 1.5,硬件平台使用的GPU 为2080Ti,内存为32 GB。
部分参数设置如下:式(2)中的参数a=0.45,式(3)中的参数b=10,GrabCut 的最小割算法迭代次数设置为10,可微分聚类网络的迭代次数设置为100。
2.2 实验评价指标
为了保证对比实验的客观性,采用显著性目标检测普遍使用的平均绝对误差eMAE(Mean Absolute Error,MAE)、准确率P(Precision)、召回率R(Recall)和F‑measure值来进行评价。
MAE表征真值图GT与显著图之间的误差,计算如下:
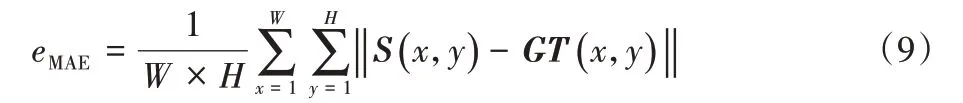
其中:S(x,y)表示优化显著图在(x,y)处的像素值;GT(x,y)表示二值化的ground truth 在(x,y)处的像素真值。eMAE值越低表明真值图与优化显著图之间误差越小,算法越好。
通过将优化显著图S与真实标签进行比较来计算准确率P和召回率R,计算公式如下:

综合考虑P与R,采用P与R的加权调和平均值F-measure来综合评估显著性图片,计算公式为:

其中,为突出准确率的重要性,根据经验值设置β2为0.3。Fmeasure值越大表明显著性目标检测算法的性能越好。
2.3 对比现有算法
为验证本文算法的性能,与以下关注度较高的7 种算法进行实验对比:文献[16]中提出的基于图论的视觉显著性计算方法,检测准确度高,记作GBVS;文献[17]中利用主成分追踪来准确地恢复低秩和稀疏分量的算法,记作RPCA;文献[18]中提出的显著性过滤算法,记作SF;文献[19]中利用自底向上的先验知识来约束图像特征的算法,记作SLR;文献[20]中利用连续性来提高背景先验的鲁棒性,记叙RBD;文献[21]以及文献[22]中的算法通过变形平滑约束的新传播模型来优化背景对比度低的对象区域,分别记作FBS与SC。
表1 列出了8 种算法在F-measure值和eMAE评估指标上的评估结果,加粗数字表示最佳性能,下划线数字表示次优性能。从表1 中可以看出,在ECSSD 和SOD 数据集上本文算法表现优异。
ECSSD数据集包含多个独立或者相邻的显著目标且显著目标大小各异。从表1 可看出,本文算法实现了最低的eMAE值,而且F‑measure值仅仅略低于SC 算法。结果表明,本文算法能够有效地对具有多个显著目标的图像进行检测。

表1 不同显著性检测算法在ECSSD和SOD数据集上的指标得分Tab.1 Index scores of different saliency detection methods on ECSSD and SOD datasets
SOD 数据集图像背景复杂且显著目标大小各异。从表1中可看出,本文算法从eMAE值和F‑measure值综合来看优于除SC 算法以外的算法,本文算法在背景复杂的场景中能够较好地检测显著目标。与SC 算法相比,本文算法具有较低的eMAE值,表明本文算法检测的显著图更接近于真值图。
2.4 优化策略有效性实验比较
为验证本文所用优化策略的有效性,在ECSSD 数据集和SOD 数据集上生成显著粗图、精细化分割图、优化显著图,并计算相应eMAE、P、R和F‑measure值,结果如表2。表2 中“显著粗图”表示Frequency-tuned 算法检测的显著粗图,“精细化分割图”表示经过GrabCut 精细化分割的显著图,“优化显著图”表示在精细化分割图经过可微分聚类优化后的显著图。从表2 可以看出,精细化分割的显著图与显著粗图相比,在4 个指标上均有明显的提升,优化后的显著图与精细化分割图相比,在3个指标上有一定的提升。

表2 显著粗图、精细化分割图、优化显著图的比较Tab.2 Comparison of saliency rough map,refined segmentation map and optimized saliency map
2.5 灵敏度分析
对于本文算法所涉及的显著粗图进行二值化时的阈值选择,为了尽可能多地保留图像信息,实验中基于显著图自身的灰度统计特性,选择了多种阈值进行二值化进行对比实验,eMAE值和F‑measure值结果显示见表3。从表3中可以看出,在ECSSD数据集上,当a=0.45时所得优化显著图的eMAE值略差于a=0.4的情况;在SOD 数据集上,当a=0.45时所得显著图的eMAE值和F‑measure值均优于其他取值情况;综合考虑,选择a=0.45。
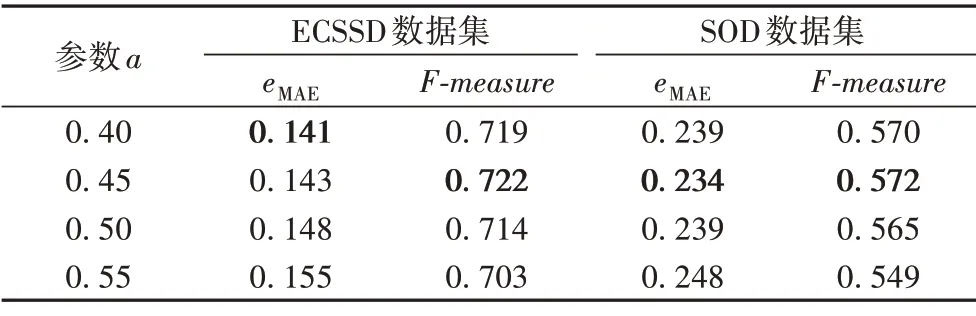
表3 二值化阈值的灵敏度分析(b=10)Tab.3 Sensitivity analysis of binarization threshold(b=10)
对于本文候选区域生成时候选区域选择所涉及的参数b,选择了多种取值进行对比实验,结果见表4。从表4中可以看出,在ECSSD数据集和SOD数据集上,当b=10时所得优化显著图的eMAE值略差于b=15 的情况,但F‑measure值均优于其他取值情况,综合看来,当b=10时实验结果最好。

表4 候选区域选择的灵敏度分析(a=0.45)Tab.4 Sensitivity analysis of candidate area selection(a=0.45)
2.6 可视化实验
从主观视觉上,图7 显示了本文优化过程在ECSSD 数据集和SOD 的数据集上的视觉显著图。从上到下依次是:原始输入图像、人工标注真值图、Frequency-tuned 算法检测的显著粗图、经GrabCut 精细化分割的精细化分割图、经可微分聚类优化精细化分割图后的优化显著图。通过对比可看出,显著粗图能够检测出目标的大致轮廓;经过精细化分割以后,可以将目标从背景中分割出来,但是在精细化分割图中依然存在一部分的背景噪声;可微分聚类可以有效地过滤这些背景噪声,得到一个更接近真值图的优化显著图;针对显著粗图不准确导致精细化分割图不包含任何目标或者仅存在部分小区域的情况,经过优化后显著目标也可以比较准确地检测出来。

图7 本文优化算法在ECSSD、SOD数据集上的视觉显著图对比Fig.7 Comparison of visual saliency maps on ECSSD and SOD datasets
3 结语
近年来,随着深度学习的迅速发展,显著性目标检测算法大部分都是依赖于大量数据或像素级标签的,而本文将图割和可微分聚类引入显著性检测,由“粗”到“精”地优化传统显著性检测算法,仅通过提取单张图像的信息特征便能够在无人工标记的情况下获取精确的显著性目标检测结果。本文提出的算法与7 种现有算法在ECSSD、SOD 数据集上进行对比,本文算法在对背景复杂和多目标的图像进行显著性目标检测时具有一定的优势。在未来的工作中,一方面可以从显著粗图生成方面入手,采用一种更为准确的无监督算法来粗定位目标;另一方面由于本文算法是完全基于图像本身特征进行的无监督的显著性目标检测,后续可以结合有监督的显著性目标检测算法,进一步提高精度。
猜你喜欢
建材发展导向(2022年20期)2022-11-03
北京航空航天大学学报(2022年8期)2022-08-31
建材发展导向(2022年10期)2022-07-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
计算机仿真(2021年7期)2021-11-17
人大建设(2019年4期)2019-11-17
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
中国知识产权(2018年12期)2018-12-29
