
基于Transformer的多轨音乐生成对抗网络
2022-01-05 02:31李小兵
计算机应用 2021年12期
汪 涛,靳 聪,李小兵,帖 云,,齐 林
(1.郑州大学信息工程学院,郑州 450001;2.中国传媒大学信息与通信工程学院,北京 100024;3.中央音乐学院,北京 100031)
(∗通信作者电子邮箱jincong0623@cuc.edu.cn)
0 引言
随着生活水平的提高,人们在音乐方面的需求也逐渐增加,如游戏背景音乐、影视插曲、主题曲等,人类作曲远远满足不了市场的需求,因此人工智能作曲随之出现。一般来说,音乐可以分为单音轨和多音轨两种类型,从音乐生成的方法看,分为符号音乐生成[1-3]和音频音乐生成[4-5]。本文主要对三种音轨的符号音乐生成进行了研究。
针对多音轨音乐生成所提出的音乐模型有分层递归神经网络(Hierarchical Recurrent Neural Network,HRNN)[6]、卷积生成对抗网络MidiNet(Musical instrument digital interface Network)[7]和多音轨序列生成对抗网络(Multi-track Sequential Generative Adversarial Network,MuseGAN)[8]等几种。经大量实验发现,这些模型只允许网络从真实的音乐数据中学习音符特征之间的关系,而没有从整首音乐中学习和声以及作曲家作曲时需要遵循的规则。
为了解决以上问题,本文提出了Transformer-GAN 模型,该模型在Transformer[9]的基础上改进得到能够更好学习不同音轨之间信息的Cross-Track Transformer(CT-Transformer)网络,并与生成对抗网络(Generative Adversarial Network,GAN)结合,以音乐规则为指导生成符合大众音乐素养的多音轨音乐。最后还提出了一套音乐评价指标,经过实验发现,Transformer-GAN 模型比基准和其他多音轨音乐生成模型生成的音乐更接近真实的音乐作品。本文的主要工作包括:
1)基于Transformer 网络,提出了一种以音乐理论知识为规则,引导生成符合人类音乐素养的GAN;
2)针对单音轨序列的内部信息及不同音轨序列间的信息在多音轨音乐生成中的重要程度,对Transformer 进行改进来生成满足单音轨内部信息相关性及多音轨间和谐性的作品;
3)针对音乐理论规则在音乐中的重要性,提出了一种将音乐规则数学模型化,并与GAN相结合的新型判别方法;
4)在基准数据集上进行了充分的实验,并对比了相关的多音轨生成方法,结果验证了本文模型的有效性及优越性。
1 相关工作
在多音轨音乐的生成中,需要考虑两个重要因素:第一是音乐连贯性,即时间结构;第二是不同音轨之间的相互联系,即音轨之间的相互作用。
近年来,研究人员们开始将神经网络与变分自编码器(Variational Auto-Encoder,VAE)、GAN 和Transformer 结合用于多音轨音乐的生成任务之中[10-12]。基于循环神经网络(Rerrent Neural Network,RNN)的分层模型HRNN[6]由底层结构生成旋律而高层结构生成和弦和鼓点进行伴奏,在节奏上得到了较大的提升;MidiNet 模型[7]通过遵循和弦序列或通过给定一个小节的旋律进行旋律的续写,进而以生成具有多个MIDI(Musical Instrument Digital Interface)通道(即音轨)的音乐,在和谐度上有较好的表现;MuseGAN[8]将卷积神经网络(Convolutional Neural Network,CNN)和GAN 结合起来生成具有多音轨的MIDI音乐。文献[13]中提出将Transformer的译码结构作为生成器、编码结构作为鉴别器的方法生成多音轨音乐,将MIDI文件中的所有音轨信息统一在一个文本中,包括乐器信息,经过预训练生成器后,通过文本续写的方式进行音乐创作;但该方法生成的音乐中有部分音符的出现不符合音乐规则,且音轨之间的和谐程度较差。为了解决此问题,本文在此模型基础上进行改进,即在生成器中加入多音轨学习模块,并引入音乐规则指导模型的训练,进而生成和谐度高且符合音乐规则的音乐。文献[14]中提出了能够很好地学习不同音轨之间关系的多音轨音乐生成(Multi-Track Music Generation,MTMG)模型。但是,现存的音乐生成模型在旋律、节奏及整体的和谐度及匹配度上均有所欠缺,并且生成的音乐大多不符合基础的乐理知识。
因此,本文在已有成果的基础上,根据人类的音乐创作过程,结合Transformer 模型与GAN,提出了以音乐规则为指导的多音轨音乐生成模型,并通过实验验证了模型的有效性。
2 基于Transformer的对抗生成网络
2.1 数据表示
为了使MIDI 文件适应该模型的生成任务,需要提取MIDI 文件的八种特征,并根据特征编码成事件序列,其中每个事件都表示为一个元组,即Bar、Position、Chord、Tempo Value、Tempo Class、Note On、Note Velocity 及Note Duration。本文实验的MIDI文件按十六分音符划分,按照每个事件类型的开始时间进行排序。Bar 表示第几小节,Position 表示每个事件类型的位置,Chord 表示本文所设定的和弦进行,Tempo Class 表示节奏类型(快、适中、慢),Tempo Value 表示将节奏类型进行量化后的值,Note On 表示音高的起始时间(音高量化范围“0~127”),Note Velocity 表示音符的感知响度(量化范围“0~127”),Note Duration表示每个音符的音长。
2.2 整体架构
如图1 所示,本文所使用的音乐数据均为MIDI 格式,且所有文件只包含钢琴、吉他及贝斯三条音轨。首先,分别将三条音轨编码成时间序列,通过三个生成器(Gp、Gg、Gb)进行单音轨序列的内部信息进行学习并生成下一时刻的状态yt;其次,使用6 个CT-Transformer 模块对音轨序列进行两两学习,并将学习吉他及贝斯两个音轨序列后的钢琴序列进行拼接得到新的钢琴序列,吉他序列及贝斯序列的学习与钢琴序列相同;最后,将真实样本序列与生成样本序列通过鉴别器Dφ进行判别。

图1 多音轨音乐生成对抗网络框架Fig.1 Framework of multi-track music generative adversarial network
2.3 生成网络
在单音轨部分,使用Transformer 的译码部分作为单轨序列生成网络的组成部分,如图2 所示,输入字符序列是通过嵌入矩阵映射到Embedding 中表示。然后,这个嵌入序列加上位置嵌入,通过Ng(Ng=5)个self-attention 模块,将其中的第k时刻后的信息屏蔽掉,确保字符只能学习第k时刻之前的信息。最后一个self-attention 模块的输出首先映射到词汇空间,然后由softmax 层激活,得到输出字符分布。在预训练阶段,训练单音轨生成器使预测的字符与输入是真实字符之间的交叉熵损失最小化。在生成阶段,生成器以自回归的方式逐个生成字符。生成时可以从头开始或给一个起始序列开始。
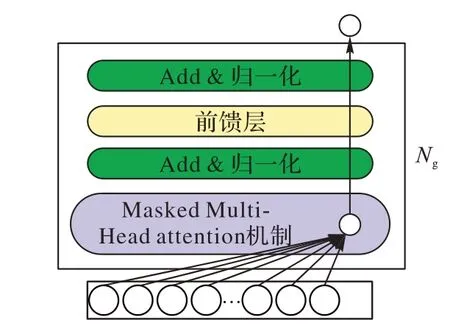
图2 单轨音乐生成结构Fig.2 Single-track music generation structure
在多音轨部分,该模块以Transformer 为基础对selfattention 机制进行改进,即CT-Transformer,其核心部分为Cross-Track attention 机制。将钢琴序列作为学习对象,吉他序列作为被学习对象,分别表示为Xp∈RTp×dp、Xg∈RTg×dg。T(·)和d(·)分别表示序列长度和特征维度。首先定义查询为Qp=XpWQp,键值对分别为Kg=XgWKg和Vg=XgWVg,其 中表示钢琴及吉他所对应的权重。如图3 所示,为在第i时刻得到的状态,i={1,2,3,4,5,6},如式(1)所示。
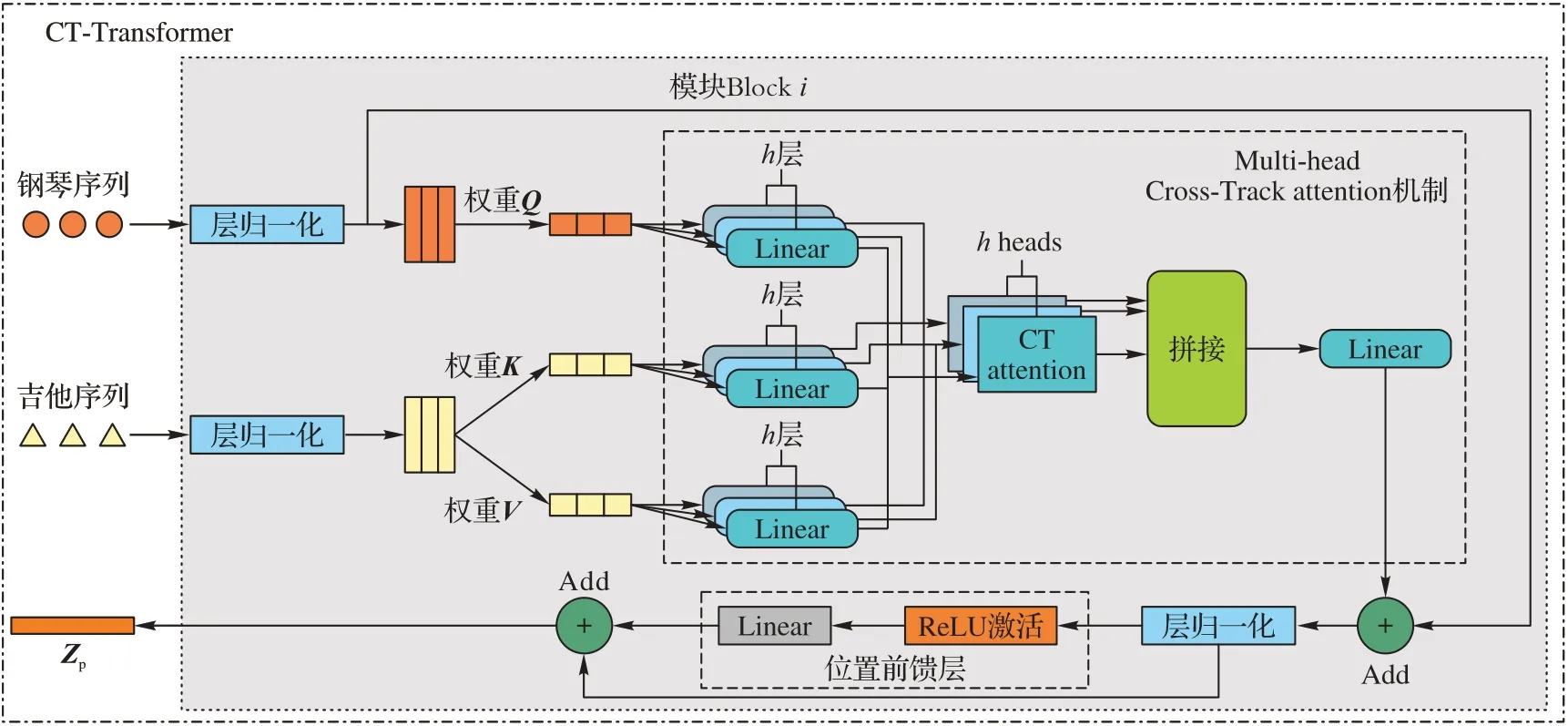
图3 钢琴序列学习吉他序列模块Fig.3 Piano sequence learning guitar sequence module
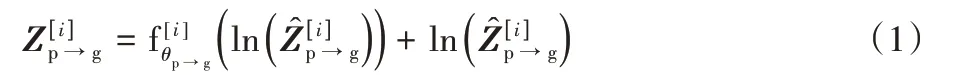

得到输出序列后,为了使输出序列与输入序列维度相同,将输出序列进行层归一化,然后将其输入前馈子层,与归一化后的输出序列进行残差连接,得到第i层模块后的输出序列。同理,钢琴轨学习贝斯轨信息为。

2.4 鉴别网络
损失函数能使深度学习网络有效地学习特征信息之间的联系,让模型网络完成设定的任务,所以,在得到相应的预测值之后,本文将下一时刻输入的音符向量Xt+1当作当前时刻的目标值,即构成一个监督学习环境,根据预测值与原样本更新模型参数。本文将softmax 层作为输出层,即输出为音符的概率分布,因此使用交叉熵构建损失函数[15]。如式(6)所示,在生成多音轨音乐时,通过对模型交叉熵训练,能够极大地优化参数并改善音乐作品的质量。

为了得到符合乐理知识的音乐,本文将乐理规则数学模型化[16],按照乐理知识在音乐中的重要程度反馈给生成网络不同的奖惩值,从而以乐理规则引导音乐生成。在流行音乐的钢琴轨、吉他轨和贝斯轨中,音符需要分别在A2-C5、E-C3及E-1-E1 之中。如式(7)所示,其中:ymin和ymax是根据音乐的调式事先设定好的最低音和最高音;yt为t时刻的音高;Rm1(S1:t,yt)表示在前t时刻中,t时刻状态的奖励值。

在同一时刻钢琴、吉他和贝斯发声的音符数量分别不得超过8、6及1,如式(8),其中:at表示在t时刻的音符个数,n表示音符发声的最大数量,Rm2(at)表示音符个数在要求范围内的奖励值。

在钢琴和吉他的音轨中,每个小节休止符的数量不宜过多,否则会影响整个音轨的辨识度,如式(9),其中:S1:t表示该小节预测序列的音符数,y为休止符的数目,Rm3(y)表示本小节中休止符数目满足条件的奖励值。

本文设定的和弦为三和弦,如F-G-Am-F。对于和弦内音,在强起的音乐中强拍基本均在奇数拍的位置。假如、为t时刻的和弦内音,yt表示生成网络在该时刻所选择的音符,如式(10),其中:RC(S1:t,yt)为该规则所提供的奖励值。
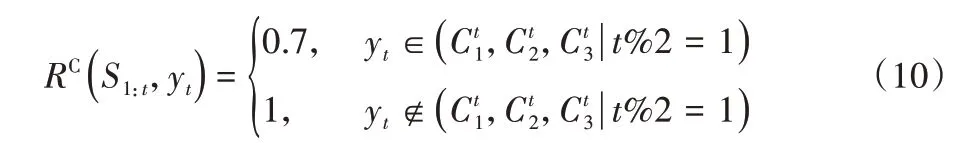
根据不同规则在音乐中的重要程度分配不同的权重比,如式(11)所示,其中:RG(S1:t,yt)表示满足所设定规则的奖励值,αi(i={1,2,3,4})表示第i条规则所占的权重。
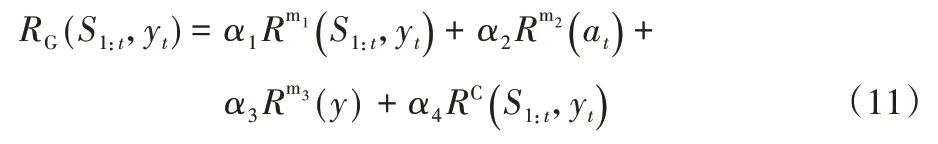
经鉴别网络对奖励函数和交叉熵损失函数分配不同的权重,进而得到模型的目标函数,如式(12)所示,其中:JGθ为奖励值与损失函数值分配权重值β1、β2后的目标函数值。

3 实验及结果分析
3.1 数据集
本文所有实验均使用Lakh MIDI 数据集[17],该数据集包含176 581 个多轨MIDI 文件。实验前对数据集进行初步过滤,只保留拍号为4/4的歌曲。然后采用Music21包对MIDI文件进行遍历,对乐器编号进行筛选,判断出属于同种乐器演奏的音轨。根据乐器编码筛选出钢琴、吉他和贝斯三种乐器演奏的音轨,最后将这三种乐器进行合并。经一系列的数据处理,得到了34 610 个只包含这三种乐器轨的MIDI 文件,将其中的24 610个MIDI文件作为训练集,10 000个MIDI文件作为测试集。
实验使用Adam 优化器对生成器和鉴别器进行优化,使用奖励网络使模型的输出达到最优状态。设定Adam 优化器的学习率ε为0.000 2;训练所进行的迭代次数为10 000。若训练迭代次数未到10 000,loss收敛,则训练停止;若训练迭代次数到10 000,loss 未收敛,则终止训练。在训练过程中Gθ网络每次获得奖励时,都会更新自身网络参数,更新的目标为最大化长期奖励。本文对目标函数相对于生成器网络的参数θ进行梯度推导,如式(13),并可按式(14)更新网络Gθ的网络参数θ,直至参数达到最优。
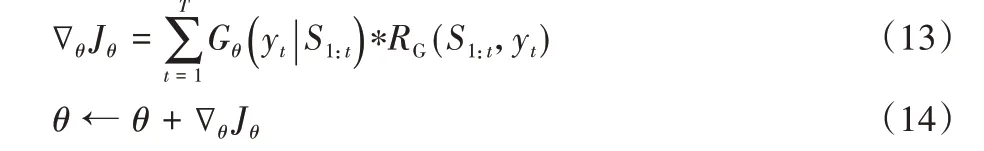
3.2 主观评价
把所有的参与者分成专业作曲家和非作曲家两组。专业群体的参与者是拥有音乐创作或电子音乐创作和制作教育学位的人,包括中央音乐学院、中国传媒大学和郑州大学。
3.2.1 人为作曲&智能作曲
首先,准备一个混合音乐集,里面有5 首由专业人类作曲家创作的音乐作品和5 首由本文模型创作的作品,供人们判断它们是由人类还是由人工智能创作。40 名专业作曲家被要求对他们从音乐创作理论方面听到的每首乐曲进行评分,而60 名非作曲家被要求根据他们的主观感受进行评分。每位听者会对测试样本进行评价和打分(分数范围为1~10),汇总最后的分数[18]。为了避免参与者受到其他方面的影响,如乐器音色,所有测试音乐无论是由人类还是模型创作的,都是从相同乐器中导出的。
由表1 可知,在专业作曲家中,人类音乐作品的平均得分高于人工智能作曲;然而,在所有参与者中,Transformer-GAN模型创作的音乐得分8.11 高于真实人类作品的得分(7.93),这表明Transformer-GAN 模型的人工智能音乐创作质量非常接近人类作曲家的质量。

表1 人工作曲与人工智能作曲评价结果Tab.1 Composition evaluation results of human and artificial intelligence
3.2.2 对比实验
该实验将生成的样本与MTMG、MuseGAN 和HRNN 比较。参与者(15 名作曲家和30 名非作曲家)收到了20 个音乐片段,它们来自四种不同的模型,这些模型都经过相同的训练集训练后被给予了相同的启动音符与乐器音色,每个模型生成5 个音乐片段;然后参与者被要求在旋律、和声、节奏和情感四个方面对音乐进行评价和打分,汇总分数之后,求其平均值并得到标准差。
由表2 可知,相对于MuseGAN、MTMG、HRNN 三种生成模型,Transformer-GAN 的整体质量得到了显著提升,除了情感,其他指标得分明显高于其他三种模型,表明Transformer-GAN 模型生成的音乐更加符合作曲的要求和规则,并在未来工作中需要在情感这一方面加强研究。
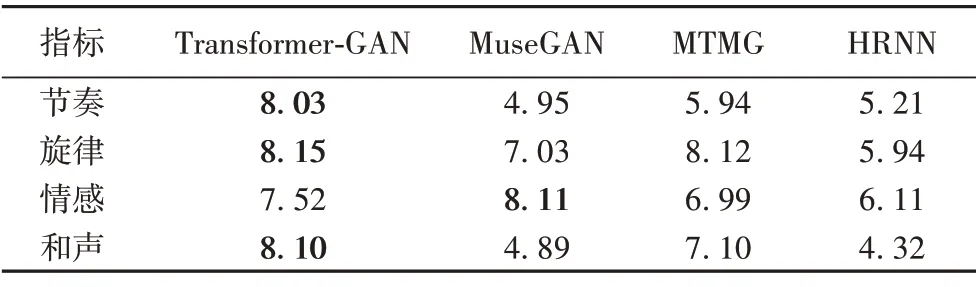
表2 四种模型得分结果Tab.2 Scoring results of four models
3.3 客观评价
此次评价中选用相同的训练集对MuseGAN、MTMG 及HRNN进行训练,与Transformer-GAN模型结果进行比较。
预测精确度(Prediction Accuracy,PA):PA 定义为预测生成的音符与输入音符的相同程度,PA 值越大,模型学习及预测能力越好。定义如式(15),其中:yi表示第i个真实音符,表示第i个预测生成的音符,M表示小节中音符的数量,表示与yi之间的误差值。

序列相似度(Sequence Similarity,SS):序列距离(Sequence Distance,SD)是指将输入序列转换为预测序列所要插入、删除或替换单字符的最小值,可以用来评估两个序列的相似度。相似度越高说明模型生成的音乐更加真实,定义如式(16),其中:M为输入音符长度,为生成的音符长度。

休止符:由于预测结果会有一定的不稳定性,生成结果若出现了休止符而实际结果不是休止符,则预测效果不好,分数越低表示性能越好。
由图4 可知,Transformer-GAN 模型生成的每条音轨相对于其他三种模型在以上三种指标中都达到了最好的效果。从图4 中可知钢琴序列相比其他两种乐器序列更容易学习音符信息,在与真实序列相似度上,Transformer-GAN 模型比MuseGAN 模型提高了3%,说明Transformer-GAN 模型在风格控制及音乐模仿生成的效果上具有一定的优势;Transformer-GAN 模型在休止符指标上相对其他三种模型的得分较低,说明Transformer-GAN 模型具有较好的生成效果,且生成结果比 较符合音乐理论知识。

图4 三种指标结果分布图Fig.4 Distribution diagram of results of three indicators
4 结语
本文提出了一个新的多音轨音乐生成模型Transformer-GAN。在该模型中,我们通过数据预处理输入转换后的文本序列,并采用交叉熵损失与音乐规则相结合的方法对模型进行训练;然后经生成网络学习单音轨内部及不同音轨之间的信息后,预测生成三个单音轨音乐;最后通过多声道融合生成含有三种乐器的音乐作品。实验结果表明,该模型在节奏性、可听性、流畅度及符合音乐规则等方面与现有的一些技术相比具有显著优势。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
阅读(低年级)(2020年10期)2020-01-07
作文大王·低年级(2019年5期)2019-06-13
海峡姐妹(2018年9期)2018-10-17
电影(2018年9期)2018-10-10
Coco薇(2017年11期)2018-01-03
小天使·二年级语数英综合(2017年6期)2017-06-06
世界汽车(2016年7期)2016-07-19
阅读与作文(小学高年级版)(2016年1期)2016-03-04
爆笑show(2015年1期)2015-03-26
