
基于迁移成分分析和支持向量机的肝移植并发症预测方法
2022-01-05 02:32曹鸿亮李繁菀那绪博
计算机应用 2021年12期
曹鸿亮,张 莹*,武 斌,李繁菀,那绪博
(1.华北电力大学控制与计算机工程学院,北京 102206;2.交通数据分析与挖掘北京市重点实验室(北京交通大学),北京 100044)
(∗通信作者电子邮箱dearzppzpp@163.com)
0 引言
原发性肝癌是我国常见的恶性肿瘤之一,发病率和死亡率居我国恶性肿瘤第二位。近十余年来,肝移植在我国得到蓬勃发展,成为治疗肝移植的重要手段之一,肝癌也成为肝移植的主要适应症之一。越来越多的人由于进行了肝移植手术而重获生命,肝移植已逐步成为临床常规手术,在临床诊疗领域具有重要地位。原位肝移植因其移植过程复杂,易产生各种并发症,制约着肝移植手术的成功率[1]。肝移植受者术后并发症一共有六种(包括死亡),本文以下部分简称为术后并发症Ⅰ、术后并发症Ⅱ、术后并发症Ⅲa、术后并发症Ⅲb、术后并发症Ⅳ、Ⅴ级(死亡)[2-3]。目前对肝移植受者术后并发症的检测依然是靠人工排查以及定时复检[4],这主要是由于肝移植的样本数据集很小而特征空间很大,导致现有的机器学习算法很难准确、有效、可靠地预测肝移植术后并发症[5-6]。准确、高效地预测分类肝移植术后受者的并发症对提高肝移植成功率起到重要作用。
传统机器学习预测模型将肝移植并发症的诊断过程看作以肝移植过程的临床表现为特征的统计分类预测问题,根据临床表现建立样本特征空间,将已有的病历样本特征和对应的标记作为训练集合,采用统计分析模型训练分类预测函数,从而可以对新病例进行预测分析[7]。然而由于已有的肝移植术后并发症病例样本数量少,主流的机器学习算法对小样本无法学习到足够的特征,难以训练出高效可靠的并发症预测模型。目前解决小样本模型训练问题的主要方法有迁移学习技术和采样技术[8]。采样技术利用一定的策略在原始样本集上生成样本均衡的训练集,在均衡训练集上训练并发症预测模型,可以提高召回率,但会导致模型的准确率下降,限制了模型的效果。迁移学习是利用已有的知识对不同但相关的领域进行求解的一种机器学习方法。基于特征的迁移学习,关注的是如何将源领域和目标领域的数据映射到新的特征空间,使得在新的特征空间中,源领域数据与目标领域数据分布相同,并且最大限度地保留源领域和目标领域的内部属性[9],从而可以在新的特征空间中利用源领域已有的标记数据进行训练,对目标领域的数据进行分类测试[10]。
本文提出了基于迁移成分分析(Transfer Component Analysis,TCA)的并发症预测方法,首先对混乱的原始数据进行预处理,筛选出有效信息。由于样本量小而特征空间很大,因此在模型训练过程中引入基于特征的迁移学习,对特征空间进行降维,自适应地选取最优特征组合,大幅减少了模型训练的时间,同时通过支持向量机(Support Vector Machine,SVM)在源领域上进行训练,对目标领域的数据进行分类测试。由于肝移植病历数据较少,并且正负样本不均衡,本文综合采用准确率和F1值作为度量标准[11]。实验结果表明,相比传统机器学习模型,本文提出的采用基于TCA 和SVM 相结合的新型肝移植并发症预测方法在预测准确率和F1 值上均有较大提升。
本文的主要工作如下:
1)提出了一种基于TCA 和SVM 的肝移植并发症预测方法,解决了传统机器学习应用在小样本、大特征空间的肝移植医疗数据集预测上的不足,能提升并发症分类预测的准确率和F1值。
2)在划分源领域和目标领域的问题上,根据术前、术中、术后的不同时间节点采样医疗数据构成源领域和目标领域,提供了一种划分源领域和目标领域的思路。
3)自适应地实现最优特征的选取,能有效提高模型训练的速度和效率。
1 基于TCA的预测方法
本文提出了基于TCA 和SVM 的肝移植并发症分类预测方法,对患者的临床数据进行分时采样构成源领域和目标领域,利用TCA 将源领域和目标领域映射到再生核希尔伯特空间同时进行降维[12],提取有效临床数据。源领域是指已经进行标记的一批数据,和目标任务要预测的问题在一些知识层面上有着相关性;目标领域是指没有标记的一批数据,需要通过寻找与源领域的可迁移成分来获得标签。利用SVM 在源领域上进行训练,在目标领域上进行预测分类,解决了样本小、特征空间大的肝移植数据集给并发症预测模型的训练和预测性能带来的影响,提高了并发症预测模型的预测性能。
1.1 迁移学习
1.1.1 TCA
同构迁移学习应用于源领域和目标领域特征空间相似的场景。通过将源领域和目标领域的数据特征变换到统一的再生核希尔伯特空间来减小源领域和目标领域之间的差距,然后再利用传统的机器学习方法进行分类预测[13]。按照不同的时间节点对肝移植患者的临床数据进行采样,分成源领域和目标领域,这样划分使得源领域和目标领域间有一些交叉的特征,特征空间相似的同时,也有一些不同。通过迁移学习提取出共同特征实现降维。本文所采用的方法是TCA,以最大均值差异(Maximize Mean Discrepancy,MMD)作为度量准则[14],将源领域和目标领域映射到同一再生核希尔伯特空间,在该空间上实现边缘分布自适应,根据TCA 的假设,当实现边缘分布自适应时,源领域和目标领域同时满足条件分布自适应[15]。式(1)给出了最大均值差异的数学表达式:
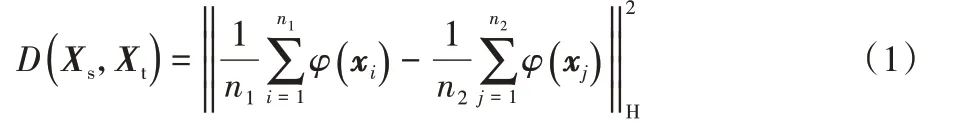
其中:Xs、Xt分别表示源领域和目标领域,n1、n2分别表示源领域和目标领域的样本个数。式(1)给出了映射后的源领域和目标领域的均值之差,衡量了源领域和目标领域的分布差异,MMD 的值越小,源领域和目标领域的分布差异越小。目标是求出映射函数φ使源领域和目标领域映射后的数据分布尽可能相似。
映射函数φ是高度非线性的,直接对MMD 进行优化往往会陷入比较差的局部最小值,因此引入TCA的思想将MMD距离平方展开产生二次项乘积的部分,引入核函数将最大均值差异变换为下面的形式:

其中K为引入的核矩阵:

Ks,s、Ks,t、Kt,t分别表示在映射后的空间上的源领域、跨领域、目标领域数据的核函数。
L为引入的一个分段函数,其中Xs表示源领域,Xt表示目标领域:
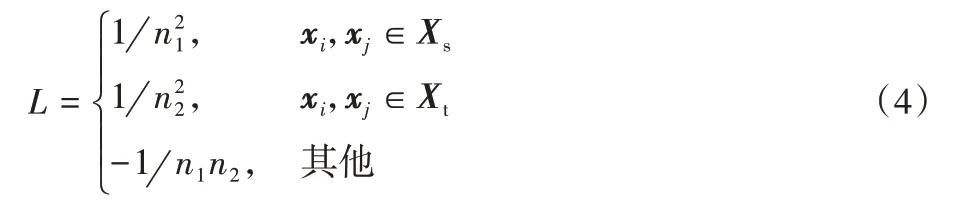
目标函数的第一项最小化两个分布之间的距离,第二项最大化特征空间的方差,其中λ≥0是一个权衡参数。
为了优化求解这个问题,引入降维的思想直接构造结果,用一个比K维度更低的矩阵W构造结果[12]如下,其中为临时变量:
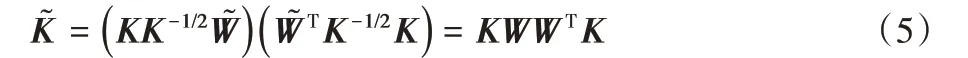
代入到目标函数中整理得到最终TCA的优化目标为:
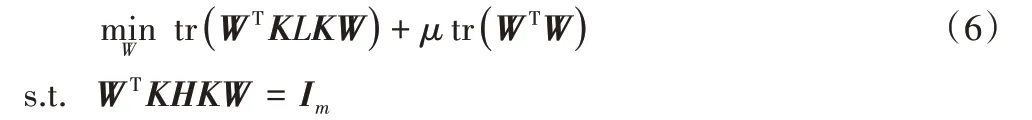
这里的H是一个中心矩阵:

其中:I∈R(n1+n2)×(n1+n2);W即为最终要求的矩阵结果,优化的目标是最小化源领域和目标领域的距离,约束则要求维持各自的数据特征,即维持数据的散度。
算法的流程如下:
算法1 TCA。
输入 源领域数据Xs,目标领域数据Xt;
输出 源领域经过TCA 降维后的结果Ts,目标领域经过TCA降维后的结果Tt。
1)计算L和H矩阵;
2)选择核函数计算K;
3)求解(KLK+μI)-1KHK的前m个特征值。
1.1.2 异构域适应
异构迁移学习应用于源领域和目标领域特征空间不同的场景。Li等[16]提出了一种渐进式对齐的方式来改善源领域和目标领域的特征差异和分布发散问题。通过引入共享字典的思想,在源领域和目标领域上学习一个新的可迁移的特征空间,然后在新空间上对齐分布差异[16]。此外,利用局部一致性,通过保持来自同一样本的距离更近达到保留内部属性的目的。
以下公式所用符号的含义如表1所示。
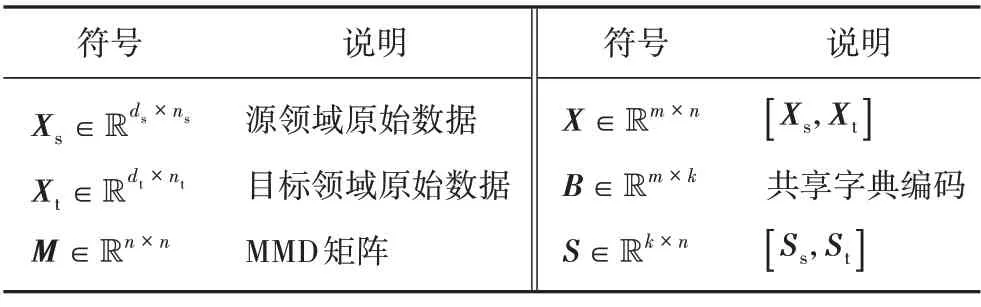
表1 公式符号说明Tab.1 Formula symbol description
1)共享字典编码。
由于源领域和目标领域应用的任务场景有相似之处,因此在源领域和目标领域之间共享一个字典是可行的。通过共享字典编码,源领域和目标领域可以学习到新的可迁移的特征空间,如式(8)所示:
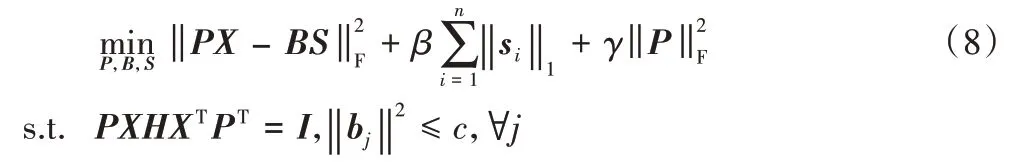
2)渐进式对齐。
通过共享字典编码学习到新的特征空间,然后在新的空间上对齐分布差异,利用最大均值差异作为衡量标准:
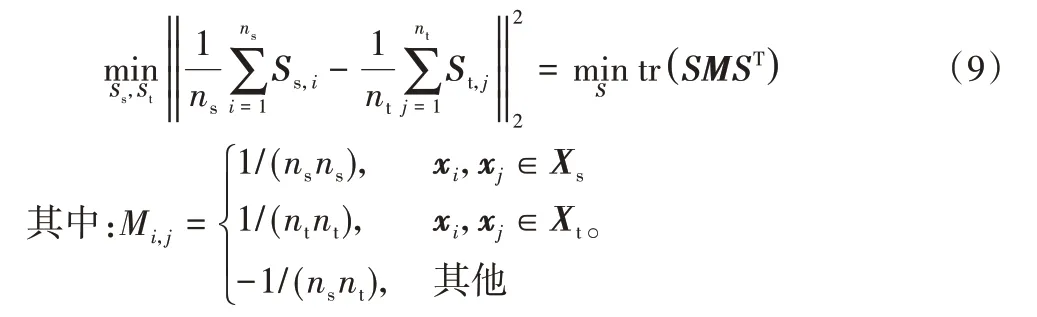
3)局部一致性。
利用局部一致性原理,保持来自同一类的样本距离较近,最小化如下目标:

最小化式(10)可以在新特征空间上保持样本的近邻关系,缓解负迁移。式(10)可以进一步改写为:
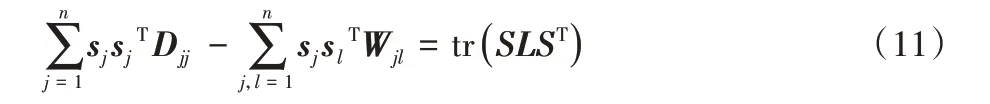
其中:L=D-W为拉普拉斯矩阵,是一个对角矩阵。
结合式(8)、(9)、(11),最终的目标函数如下:
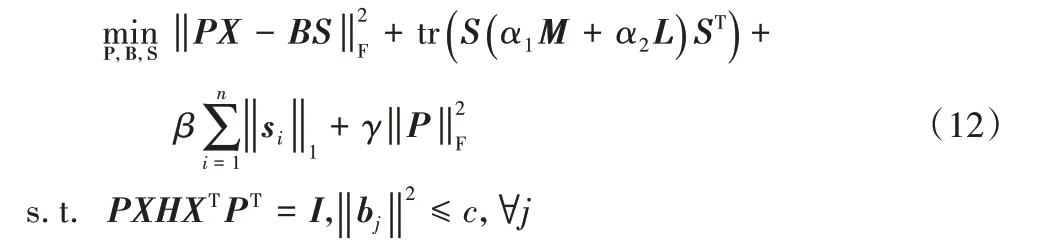
由于最终优化的参数有3 个,可以通过固定其中两个,迭代求解第三个,完整算法流程见算法2。
算法2 渐进式对齐异构域适应(Heterogeneous Domain Adaptation,HDA)。
输入Xs,Xt,参数α1,α2,β,γ,c;
输出Xt的标签。
1)利用PCA初始化P,初始化B,计算MMD矩阵M;
2)迭代求解式(3)~(5)直到收敛或者到达最大迭代次数;
3)固定B、P优化S;
4)固定S、P优化B;
5)固定S、B优化P;
6)通过Ss分类St。
1.2 SVM
SVM 是由Vapnik 提出的基于统计学习理论并采用结构风险最小化原理的一种机器学习方法[17],具有较强的泛化能力,采用数量有限的训练集就可以得到一个针对独立测试集的分类错误率相对较小的分类模型,对于小样本预测分类效果很好[18]。本文在对原始数据集进行TCA 降维后,采用SVM在源领域进行训练,在目标领域上进行预测分类。
对肝移植术前、术中、术后三个阶段的不同时间节点进行采样分成源领域和目标领域,对源领域和目标领域进行TCA,将源领域和目标领域映射到同一特征空间并进行降维,在降维后的源领域训练SVM 模型,训练好的模型在目标领域上进行分类预测,输出结果即为在目标领域上的预测分类值,完整算法见算法3。
算法3 基于TCA和SVM的分类预测方法。
输入Xs,Xt;
输出 在目标领域上的预测分类值Rt。
1)计算L和H矩阵;
2)选择核函数计算K;
3)求解(KLK+μI)-1KHK的前m个特征值;
4)求解经过TCA降维后的源领域和目标领域;
5)采用SVM在源领域上进行训练;
6)训练好的模型在目标领域上进行预测分类。
图1是本文提出的基于TCA和SVM的肝移植术后并发症预测方法的完整流程。输入数据是一批进行过预处理的病历数据,在输入层通过对数据在术前、术中和术后以相同时间间隔不同时间节点进行采样获得源领域和目标领域数据,源领域和目标领域数据进行过TCA 映射到同一再生核希尔伯特空间,通过在迁移后的源领域数据上训练SVM 模型,并在目标领域上进行预测获得目标领域的预测值,为预测的并发症结果。

图1 TCA结合SVM方法流程Fig.1 Flowchart of TCA combined with SVM
图2是异构域适应结合SVM的预测方法示意图,本文在后面实验部分对HDA 结合不同传统机器学习算法进行比较,此处以SVM 为例说明。与算法3的不同之处在于源领域和目标领域的迁移是通过异构域适应实现,算法其余部分没有差别。

图2 HDA结合SVM方法流程Fig.2 Flowchart of HDA combined with SVM
2 实验结果与分析
2.1 实验数据集
本文采用的数据集是论文合作医院的425 个肝移植患者的术前、术中、术后的诊治记录(脱敏后)。从肝移植患者病历中抽取出重症监护室(Intensive Care Unit,ICU)护理记录数据、病历系统数据以及麻醉单监护系统数据作为样本输入,五种并发症以及是否死亡作为样本标签结果,对每一种并发症建立一个预测二分类数据集,具体信息见表2。数据集中包括425 条病历记录,每条病历记录有456 个临床数据点,由于部分病历记录和部分临床数据点数据缺失,将完整无缺失的临床数据点对应的特征作为样本输入,缺失值对应的特征作为标签建立决策树预测并填补缺失值。对于部分医疗数据进行标准化预处理减少它对其他特征的影响。
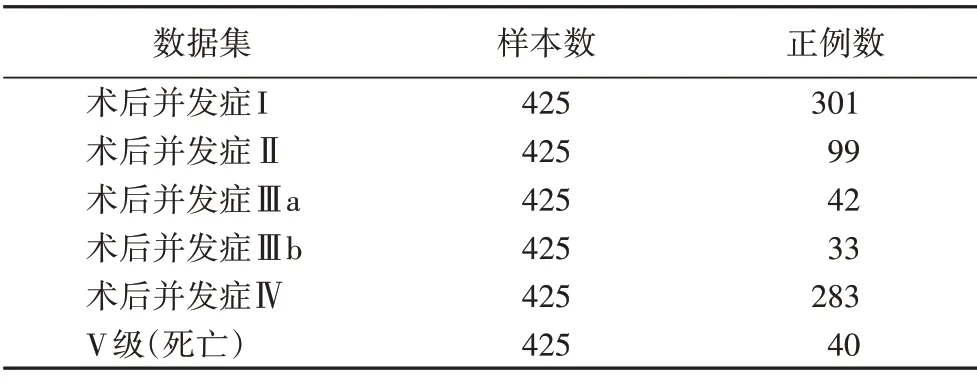
表2 实验数据集基本情况Tab.2 Basic situation of experimental dataset
肝移植数据点具体信息见表3。

表3 实验数据集中的肝移植特征Tab.3 Liver transplantation features in experimental dataset
2.2 实验与结果分析
对于已有的数据集,根据医生专家指导将血常规指标的术前2 d、4 d、6d、14 d、术后2 d、4 d、6d、14 d 的数据划分为源领域,将术前1 d、3 d、5 d、7d、术后1 d、3 d、5 d、7d的数据划分为目标领域;将生化指标术前2 d、4 d、6d、14 d、术后2 d、4 d、6d、14 d 的数据划分为源领域,将术前1 d、3 d、5 d、7d、术后1 d、3 d、5 d、7d 的数据划分为目标领域;将血气指标的术前30 min、门脉开放时、门脉开放后30 min、门脉开放后150 min、进入ICU 时、门脉开放后120 min 的数据划分为源领域,将术前60 min、门脉开放时、门脉开放后60 min、手术结束时、门脉开放后60 min的数据作为目标领域;将凝血指标的术前2 h、4 h、6 h 手术结束后2 h、4 h、6 h、距手术结束2 h、4 h、6 h 的数据划分为源领域,将术前1 h、3 h、5 h、7 h、术后1 h、3 h、5 h、7 h、距手术结束时1 h、3 h、5 h、7 h 的数据划分为目标领域;将术后输血情况的红细胞POD0、红细胞POD2、红细胞POD4、红细胞POD6、红细胞POD8、红细胞POD10、红细胞POD12、红细胞POD14,血浆POD0、血浆POD2、血浆POD4、血浆POD6、血浆POD8、血浆POD10、血浆POD12、血浆POD14、血小板POD0、血小板POD2、血小板POD4、血小板POD6、血小板POD8、血小板POD10、血小板POD12、血小板POD14 划分为源领域,将红细胞POD1、红细胞POD3、红细胞POD5、红细胞POD7、红细胞POD9、红细胞POD11、红细胞POD13、红细胞POD14+、血浆POD1、血浆POD3、血浆POD5、血浆POD7、血浆POD9、血浆POD11、血浆POD13、血浆POD14+、血小板POD1、血小板POD3、血小板POD5、血小板POD7、血小板POD9、血小板POD11、血小板POD13、血小板POD14+划分为目标领域。经过以上处理,将病历数据划分为两个数据集,两个数据集数据数量相同、特征数相同,一个作为源领域数据,另一个作为目标领域数据。鉴于不同时间节点的医疗数据差异性明显,因此这种对于源领域和目标领域的划分具有实际意义。下面对于源领域和目标领域分别进行TCA 降维,特征空间维度从456 维降到30 维,源领域和目标领域的特征空间映射到特征分布一致的再生核希尔伯特空间,可由源领域进行传统机器学习训练预测分类目标领域的标签。
由于并发症样本正负样本数不均衡,准确率无法全面评价实验结果,因此需要考虑更多评价指标。F1 分数同时兼顾了精确率和召回率,可以全面地评价正负样本不均衡数据的预测结果,因此本文综合采用准确率和F1值作为实验结果评判标准。准确率(acc)和F1值(f1)的计算公式如下:
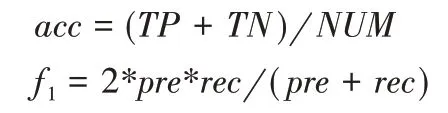
本文同时比较了渐进式对齐异构域适应(HDA)和主成分分析(Principal Components Analysis,PCA)分别结合传统机器学习算法的预测分类结果。纵向比较了PCA、HDA 和TCA 分别结合SVM、K 最邻近(K-NearestNeighbor,KNN)和极致梯度提升(eXtreme Gradient Boosting,XGBoost)的准确率和F1 值,准确率结果见图3,F1 值结果见表4~6;同时还比较了SVM、KNN 和XGBoost 分别结合PCA、HDA 和TCA 的准确率和F1值,准确率结果见图4,F1值结果见表7~9。

表4 SVM在PCA、TCA、HDA上的F1值结果Tab.4 F1 scores of SVM on PCA,TCA,HDA

表5 XGBoost在PCA、TCA、HDA上的F1值Tab.5 F1 scores of XGBoost on PCA,TCA,HDA
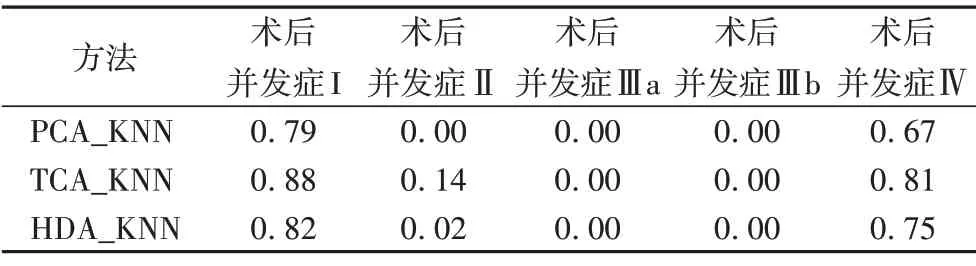
表6 KNN在PCA、TCA、HDA上的F1值Tab.6 F1 scores of KNN on PCA,TCA,HDA

表7 SVM、XGBoost、KNN在PCA上的F1值Tab.7 F1 scores of SVM,XGBoost,KNN on PCA
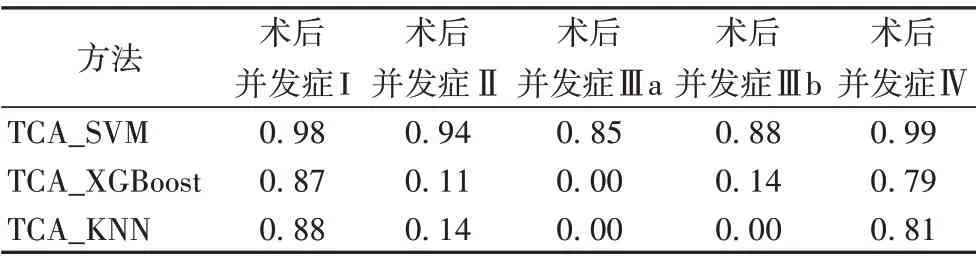
表8 SVM、XGBoost、KNN在TCA上的F1值Tab.8 F1 scores of SVM,XGBoost,KNN on TCA

表9 SVM、XGBoost、KNN在HDA上的F1值Tab.9 F1 scores of SVM,XGBoost,KNN on HDA

图3 传统机器学习在PCA、TCA、HDA上的准确率对比Fig.3 Comparison of accuracy of traditional machine learning on PCA,TCA,HDA
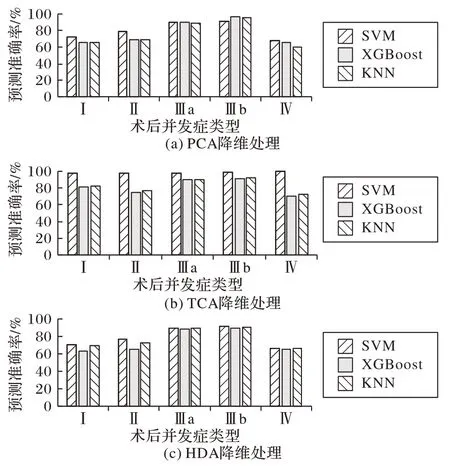
图4 SVM、KNN、XGBoost的准确率对比Fig.4 Comparison of accuracy of SVM,KNN,XGBoost
从图3 中可以看出,对于SVM、KNN 和XGBoost 三个传统机器学习模型,分别结合TCA 在预测准确率上比结合HDA 要略高一些,比PCA 降维要高出7.6%到47.7%;而在F1 值方面,TCA 结合SVM 在五个术后并发症上表现很好,远远高于另外两个方法结合SVM。图3 中HDA 和PCA 降维在术后并发症Ⅱ、术后并发症Ⅲa、术后并发症Ⅲb 上预测的F1 值为0,表示两种方法在测试集上的预测结果都为负,即预测都没有并发症,因此虽然两种方法的准确率比较高但F1 值表现很差,这是由肝移植并发症样本数很少,并且在不同术后并发症上的正负样本不均衡导致的,但是本文提出的基于TCA 和SVM的方法在预测准确率和F1值上表现仍然很好。
从图4 中可以看出,同样使用PCA 降维的情况下,SVM、XGBoost 和KNN 的预测准确率相差不大,XGBoost 的预测F1值在术后并发症Ⅱ、术后并发症Ⅲa、术后并发症Ⅲb上要高于SVM 和KNN。SVM 和KNN 的预测F1 值都为0,表示SVM 和KNN 的预测结果都为负,即预测测试样例都没有并发症。同样使用TCA 的情况下,SVM 的预测准确率比KNN 和XGBoost平均高出7.8%~42.8%,在预测F1 值上要远远高于KNN 和XGBoost,SVM 的 预 测 准 确 率 和F1 值 都 要 优 于KNN 和XGBoost。同样使用HDA 的情况下,SVM、KNN 和XGBoost 的预测准确率相差不大,而预测F1 值三个模型表现都不是很好。
综上可知:本文提出的基于TCA 和SVM 的肝移植术后并发症预测方法在预测准确率和F1值上都取得较好的结果。
3 结语
本文给出了基于TCA 结合SVM 的肝移植并发症预测方法。理论分析和实验检验表明:1)采用基于特征的迁移学习可以有效地对特征空间很大的样本数据进行降维,避免了样本不足情况下无法获取足够信息的缺点,实现边缘分布自适应;2)运用SVM 可以可靠地应对并发症这样的小样本数据集,结合迁移学习能有效提升模型预测的准确率和F1 值;3)对于源领域和目标领域的划分提供了一种思路。此外,从实验结果可以看出,并发症的预测准确率和F1 值很高,但是缺乏一定的可解释性,后续工作也将进一步研究基于专业医学知识的特征自适应选取,以获得具有可解释性的并发症预测模型。
猜你喜欢
传染病信息(2022年3期)2022-07-15
中国典型病例大全(2022年9期)2022-04-19
汽车实用技术(2022年4期)2022-03-07
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
华人时刊(2020年21期)2021-01-14
健康体检与管理(2021年10期)2021-01-03
海峡姐妹(2019年12期)2020-01-14
科技视界(2016年16期)2016-06-29
