
基于局部敏感布隆过滤器的工业物联网隐性异常检测
2022-01-05 02:32肖如良曾智霞肖晨凯
计算机应用 2021年12期
肖如良,曾智霞,肖晨凯,2,张 仕,2*
(1.福建师范大学计算机与网络空间安全学院,福州 350117;2.数字福建环境监测物联网实验室(福建师范大学),福州 350117;3.福建省网络安全与密码技术重点实验室(福建师范大学),福州 350007)
(∗通信作者电子邮箱shi@fjnu.edu.cn)
0 引言
随着工业4.0 时代[1-2]的到来,工业物联网(Industrial Internet of Things,IIoT)系统目前已经广泛应用于安全监控[3]、智能交通[4]、环境监测[5]等领域。IIoT 系统的传感器节点配备了摄像机、麦克风和其他传感器,能够从物理环境中收集视频、音频、图像等多媒体数据。但是,传感器设备由于持续使用和正常磨损出现损坏,导致收集和记录的IIoT 数据出现异常。由于IIoT数据通常具有高维度、大规模、多类型的特点,大规模高维数据无关特征的存在可能会掩盖异常的存在,隐性异常难以被检测。因此,构建一个良好的异常检测模型对IIoT应用有非常重要的意义。当前已有很多学者开展了相关的异常检测方法研究[6-9],特别是近年来,异常检测算法的研究已成为产业界与学术界共同关注的热点问题。
目前,在异常检测算法研究中具有代表性的有:Deng等[10]提出的一种基于Bloom Filter 的异常流量检测框架。他们主要分析了两种异常流量(端口扫描流量和TCP 泛洪流量)。对于端口的扫描,使用Bloom Filter 结构框架可以检索这个流已经访问的端口:如果在不同的端口上有太多的流量,则可以确定异常;对于TCP 泛洪流量,使用Count Bloom Filter来计算一段时间内每种类型的流中具有相似长度的包的数量,如果检测到相同长度的报文比例较高,则异常发生的概率较大。Lee 等[11]提出了一种新的用于异常事件检测的双向多尺度聚合网络模型。该模型学习正常事件的时空模式,以检测偏离学习的正常模式为异常。该模型主要由帧间预测器和外观-运动关节检测器两部分组成。设计了帧间预测器对正常模式进行编码,利用基于注意力的双向多尺度聚合生成帧间预测器。通过特征聚合,实现了常规模式编码对目标尺度变化和复杂运动的鲁棒性。在编码正常模式的基础上,同时考虑场景的外观特征和运动特征的外观-运动联合检测器检测异常事件。Gibert 等[12]使用计算机视觉和模式识别方法的自动轨道检测最近显示出了提高安全性的潜力,利用深度卷积神经网络允许更频繁的检查,同时减少人为错误。
总的来说,以上这些方法为异常检测拓展了新的思路,但是现有异常检测方法依然存在两个方面的问题:
1)大规模高维特征的存在可能掩盖异常的存在,隐性异常难以被检测系统检测。
2)在耗费大量时间标记好训练数据后,异常检测模型仍需要大量的时间进行训练修正才能够有效地对异常进行检测,并且模型对参数具有较高的敏感性。
针对以上问题,本文提出一种基于局部敏感Bloom Filter(Locality Sensitive Bloom Filter,LSBF)模型的异常检测算法,与现有方法的不同之处如下:
1)提出的基于空间划分的快速Johnson-Lindenstrauss 变换(Spatial Partition based Fast Johnson-Lindenstrauss Transform,SP-FJLT)具有很强的映射保距性,可以准确识别隐性特征,减少数据在哈希投影中的精度损失;
2)提出的基于LSBF 模型的异常检测(LSBF-based Anomaly Detection,LSBFAD)算法能够有效地对高维度、大规模、多类型的IIoT 数据进行异常检测,探测隐性异常,提高检测的准确率;
3)LSBFAD 算法是半监督模式,即训练过程中不需要异常类标签的数据。
本文使用3 个仿真数据集进行了充分的实验评估,与多个典型的异常检测算法进行比较。实验结果表明,本文LSBFAD 算法具有更高的检测率(Detection Rate,DR)以及更低的误报率(False Alarm Rate,FAR)。
1 相关工作
目前常规的异常检测算法根据应用技术主要分为三大类:基于分类的异常检测方法[13-15]、基于最近邻的异常检测方法[16-18]和基于统计的异常检测方法[19-21]。三种方法都存在一些优点与不足。基于分类的异常检测算法由于具有先验模型,具有较高的检测效率,在IIoT 系统中得到了更广泛的应用。而基于分类的异常检测算法又分为三大类:基于神经网络、基于支持向量机和基于规则。其中,基于神经网络的异常检测算法的检测精度最高,但通常不能做到及时响应。基于分类的异常检测算法相对成熟,有很多优秀的科研成果。Han 等[13]提出了一种混合异常检测模型,包括针对异常活动的基于原始数据的方法和针对异常状态的基于谱图的方法两种;然后利用卷积神经网络对支持向量机预测的活动进行分类,再利用递归神经网络直接对信号进行预测。Farshchi等[14]分析了一种度量日志上下文异常检测技术在空中交通管制系统中间件中的有效性,研究解决了将此类技术应用到一个新的案例研究中的挑战,该案例具有高密度的测井数据量和更精细的监测采样率。Dasgupta 等[15]提出了果蝇Bloom Filter,发现果蝇的嗅觉回路进化出一种Bloom Filter 的变种,以评估气味的新颖性。与传统的Bloom Filter 相比,这种果蝇根据两个额外的特征调整新颖性反应:一种气味与之前经历过的气味的相似性,以及自上次经历这种气味以来的时间间隔。他们详细阐述并验证了一个框架来预测果蝇对特定气味的新颖性反应,并且将果蝇的见解转化为开发了一种距离和时间敏感的Bloom Filter。
Bloom Filter 模型[22]被提出的最初原因是哈希编码占用了大量的内存空间,为了解决这个问题,Bloom Filter给出了一种新的数据结构,该数据结构通过容许哈希编码中的少许错误减少哈希编码所占用的空间。后来的一些学者也从中得到启发作进一步的改进,并逐渐形成了现在通用的Bloom Filter。如今Bloom Filter 已经成为大规模数据集的常见处理手段。目前,传统的Bloom Filter 的功能主要是快速判断给定的元素v是否在集合S中,它的主要思想是通过一组长度为w、初始值均为0 的二进制编码模型,通过k个哈希函数映射,把集合中的元素一一映射到模型中,每当模型中一个位置被激发,修改该位置的值为1。然后使用同样的哈希函数映射给定的查询点,当模型中查询点所映射的k个位置均显示1 时,说明该查询点存在集合中,即v∈S,输出True;否则,输出结果为False,即该查询点不在集合S中。
2 LSBFAD算法
2.1 LSBFAD算法总体框架
针对IIoT 数据的异常检测,由于异常的IIoT 数据特征不同于正常的IIoT 数据,并且异常的IIoT 数据数量占少数,因此本文的工作建立在样本数据的两个假设基础上,即:1)异常数据具有区别于正常数据的特征;2)异常数据的数量远远小于正常数据的数量。
本文利用LSBF 模型,结合SP-FJLT 矩阵投影和相互竞争(Mutual Competition,MC)策略,提出LSBFAD 算法,算法总体框架如图1所示。

图1 LSBFAD算法总体框架Fig.1 Overall framework of LSBFAD algorithm
1)数据预处理。数据预处理阶段在输入IIoT的原始多类型数据后,通过特征化将多媒体数据转换成特征向量;在这个过程中,对文本数据进行特征提取,通常采用词频逆-文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)方法或词频方法,以将文本数据转换为欧氏空间下的特征向量;对图像数据进行特征提取时,通过提取尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征值进行特征化处理。
2)构建SP-FJLT。IIoT数据利用本文提出的SP-FJLT进行哈希投影,首先构建FJLT 投影变换,然后进行空间划分,并采用MC策略进行除噪。
3)构建LSBF。IIoT 数据通过SP-FJLT 投影变换后,通过MC 策略进行除噪,最后映射到Bloom Filter 上,Bloom Filter 被哈希映射的位向量由“0”变为“1”。
2.2 LSBF
2.2.1 降维投影结构
降维是数据分析中常用的方法,它将高维数据投影到低维空间中,同时保留尽可能多的信息。JL(Johnson-Lindenstrauss)定理[23]证明了这一类线性映射的存在性,它提供了任意数量的点从高维欧氏空间到指数低维空间的低失真嵌入。JLT(Johnson-Lindenstrauss Transform)是一个提供了高概率嵌入的随机线性映射,FJLT(Fast JLT)利用快速傅里叶变换(Fast Fourier Transform,FFT)的矩阵向量乘法仅在嵌入维数略有增加的同时减少嵌入的复杂性。利用数据的空间性质,对数据进行空间划分的方式实现降维。这种划分子空间的方法可以很大程度降低数据的失真程度。空间划分是一种重要的数学模型,在信号处理、数据挖掘、模式识别、图论等领域都有重要应用。本文提出的SP-FJLT 映射以傅里叶变换为基础,用JL 定理指导空间划分,克服降维过程中的缺陷,同时利用数据的空间分布性质,增强了映射的保距性能。
先给出FJLT的组成:

φ是一个元素独立分布的k×d矩阵,k=δd,δ是参数,d是数据初始维度。
矩阵P=(Pij)在概率1-q的情况下设置Pij=0,否则(其余概率)从方差为0、期望为q-1的正态分布中提取pij,稀疏常量q表示为:

FN∈Rn×n是一个标准化的Walsh-Hadamard矩阵:

DN∈Rd×d:是一个d×d的对角阵,Dii为1 的概率是1/2,否则Dii为-1。
SP-FJLT 从单位球SD-1中随机均匀地选择一个方向,并使用与该方向正交的超平面利用数据空间分布性质进行划分,组成如下:

使用SP-FJLT 映射来最小化数据的失真,从而保证算法的准确性。与传统的稀疏矩阵投影和FJLT 矩阵相比,SPFJLT 矩阵具有更好的覆盖率,可以更好地利用数据分布的性质来保持数据的准确性,特别是当输入数据是一个稀疏向量(它有许多零元素)时。
2.2.2 MC策略
本文提出的LSBFAD 算法训练Bloom Filter的过程采用半监督模式,只需要正常IIoT 数据进行训练。但是数据收集过程存在误差,不可避免地会把一些异常IIoT 数据标记成正常IIoT 数据。因此当IIoT 数据通过哈希投影后,相似的数据都被映射至同一编码,采用MC 策略对编码进行优化,即根据编码所含的数据比例进行竞争,剔除数据量稀疏的编码,保留数据量在前β的编码。这一操作有利于删除那些标记成正常类的异常数据,能有效降低算法的假阳性。
2.2.3 构建LSBF
正常的IIoT 数据通过SP-FJLT 映射后,在经过MC 策略进行除噪,然后映射到Bloom Filter 上,Bloom Filter 对应的位向量发生改变。即初始的Bloom Filter 位向量全为“0”标记,当对应的位置被SP-FJLT 映射后,“0”转变为“1”,意味着此位向量已被哈希映射,即该位是正常数据映射的位。
2.2.4 LSBFAD算法及复杂度分析
本文提出的LSBFAD 算法(见Algorithm 1)由三个步骤组成:首先利用SP-FJLT 映射算法将数据进行投影,然后采用MC策略进行除噪,最后利用0-1编码构建LSBF。
Algorithm 1:LSBF。
输入 待检测数据Q=(q1,q2,…,qd)∈R1×d;n表示IIOT 数据X的个数;d表示数据初始维度;k表示哈希码的数量;m表示Bloom filter的大小;m'表示位确认向量的大小;β表示编码保留比例;
1)利用IIOT 数据X=(x1,x2,…xd)∈Rn×d构造待检测数据Q的SP-FJLT投影y=SP‑FJLT(Q);
2)利用MC策略保留前β个二进制编码;
3)利用投影数据Y=(y1,y2,…,yk)∈Rn×k构造LSBF
k0...position-1=Bloomfilter(Y)
输出k0...position-1
算法步骤1)构造SP-FJLT 投影的时间复杂度为O((dlb(d)+min{dε-2lb(n),εp-4lbp+1(n)})d3n);步骤2)提取数据的时间复杂度为O(cn);步骤3)构造LSBF 的时间复杂度为O(cmk)。LSBFAD 算法的计算复杂度在第一步构建SPFJLT 投影是最大的,因此整个算法的计算复杂度由第一步,即构建SP-FJLT 投影算法决定的,它的计算复杂度为O((dlb(d)+min{dε-2lb(n),εp-4lbp+1(n)})d3n)。从中可以看出LSBFAD 算法的计算复杂度跟数据数量以及维数呈正相关。
3 理论分析
常规哈希方法在降维过程中不可避免地会损失数据集内部数据对象之间的相似性,本文提出的LSBFAD 算法中,SPFJLT 映射充分利用了数据的空间分布特性对数据进行空间划分,最大限度保留了数据对象的相似性,拥有良好的保距性能。
SP-FJLT 算法中,空间划分主要的难点是球面S与映射μ在内在维度的依赖关系。
定理假设球面S∈RD拥有其特征矩阵前d个特征值。选择一个随机向量U~N(0,(1/D)ID),以任何方式(可能依赖U)将S划分成S1、S2两部分。让p=|S1|/|S|,u1和u2分别代表S1和S2的均值,u'1和u'2分别代表S1∙U和S2∙U的均值。对于任何δ>0,有大于1-δ的概率选择最佳的U,最大限度保留了数据对象的相似性。

证明 在不失一般性的前提下假设S的均值为0。让H是由cov(S)上的d个特征向量组成的子空间,H⊥是它的正交子空间。把任意点x∈RD写成xH+x⊥,其中每一个分量都是RD的一个向量,并且位于各自的子空间。
选取随机向量U,有大于1-δ的概率满足如下两个性质:
性质1:对于任意一个常数c'>0,对于所有x∈RD有:
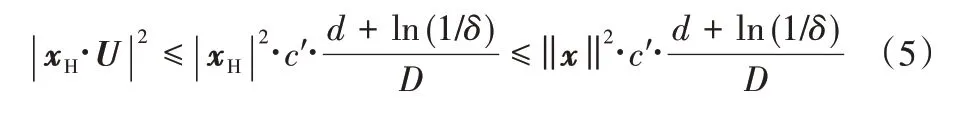
性质2:设X是从S中抽取的均匀随机数

式(4)来自于马尔可夫不等式,式(6)来自于局部协方差条件。
基于以上两个性质,把u2-u1写成(u2H-u1H)+(u2⊥-u1⊥)。

第一项可以由性质1限定:

对于第二项,设EX表示从S中随机均匀选取的期望,有
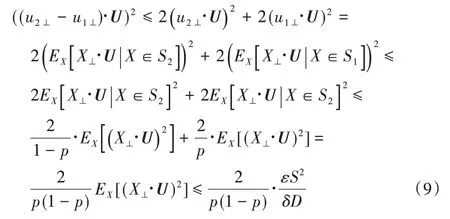
因此本文提出的SP-FJLT 可以选择最佳的U进行划分,最大限度减少了数据间的相似性损失,拥有良好的保距性能。
4 实验与分析
4.1 评价指标
实验中以异常检测的检测率(Detection Rate,DR)和误报率(False Alarm Rate,FAR)来检验本文LSBFAD 算法的性能。DR 表示检测出的测试数据(TP+TN)占所有测试数据(P+N)的比例,同时反映了正常数据和异常数据分类的正确率;FAR表示误检的测试数据(FP+FN)占所有测试数据(P+N)的比例,其中包括了把正常数据检测成异常情况和把异常数据判定成正常情况。计算公式如下:
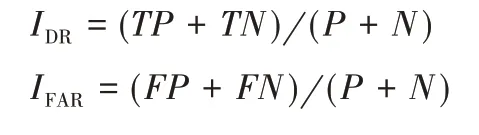
对于每组数据集,选取其中80%的正常数据作为训练集,20%的正常数据以及异常数据作为测试集。每组实验重复20次,通过平均的DR和FAR来衡量结果。
4.2 仿真数据集
为了充分展现算法在不同数据分布下的异常检测性能,挑选了三个不同领域中的大规模高维仿真IIoT数据集进行对比实验,这三个数据集是IIoT领域常用的数据评测数据集。
1)SIFT(https://archive.ics.uci.edu/ml/datasets.php):图像数据集,含15 000条正常数据和500条异常数据。
2)MNIST(https://moa.cms.waikato.ac.nz/datasets/):手写数字识别的数据集,含32 000条正常数据和600条异常数据。
3)FMA(http://mlkd.csd.auth.gr/conceptDrift.html):音频数据集,含25 000条正常数据和1 000条异常数据。
4.3 实验结果及分析
实验1:比较本文提出的SP-FJLT 投影算法与传统的LSH(Locality-Sensitive Hashing)投影[24]算法的保距性能。SP-FJLT和LSH 投影后的数据保留5、10、15、20、25 个哈希位映射到Bloom Filter,通过DR 来比较两种投影算法的保距性能,实验结果如图2 所示。可以看出:在三个不同的IIoT 数据集上,本文提出的SP-FJLT 算法的保距性能明显优于LSH 算法,因此SP-FJLT 算法更适合异常检测模型。SP-FJLT 算法能够尽可能降低数据的失真程度,让数据通过哈希后能够准确地映射到Bloom Filter的向量位中。
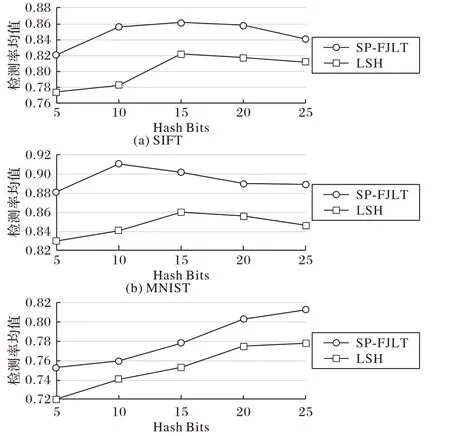
图2 SP-FJLT算法和LSH算法的保距性比较Fig.2 Comparison of SP-FJLT algorithm and LSH algorithm on distance keeping performance
实验2:探究相互竞争的参数β对DR的影响。在实验中,将参数β分别取值为0.7、0.75、0.8、0.85、0.9,并且投影后保留15 个哈希位映射到Bloom Filter 中,比较不同取值β下在SIFT、MNIST 和FMA 数据集的DR,实验结果如表1 所示。可以看出:随着参数β的增大,算法的DR 也随之增高。但是,β的最佳取值范围在0.80~0.85,超过这个取值范围后,算法检测率下降。算法DR 随β增大的原因是假阴性不断下降,但在超过最佳取值范围后,增大参数β的取值会让算法的假阳性增大,因此参数β的最佳取值在0.80~0.85。
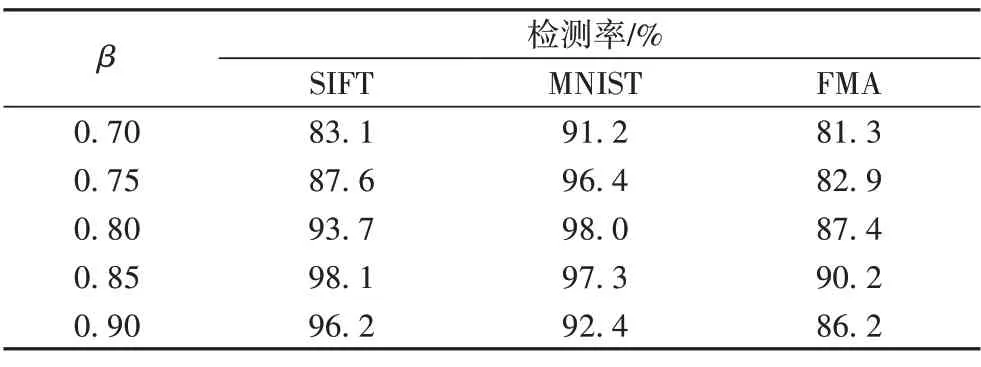
表1 β在SIFT、MNIST和FMA数据集上对检测率的影响Tab.1 Influence of β on detection rate on SIFT,MNIST and FMA datasets
实验3:将本文提出的LSBF 异常检测算法与如下算法在IIoT领域的三个数据集上进行对比,结果如表2所示。
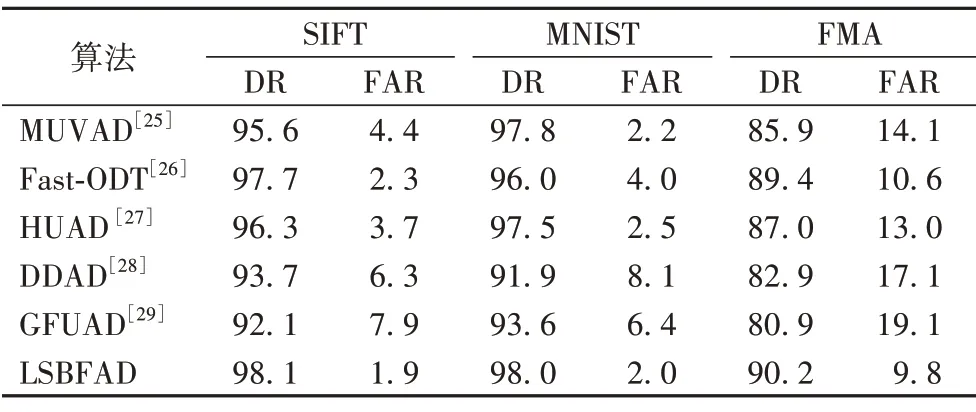
表2 在SIFT、MNIST和FMA数据集上的对比实验结果 单位:%Tab.2 Experimental results of comparison on SIFT,MNIST and FMA datasets unit:%
MUVAD(Nearest Neighbor based Multi-View Anomaly Detection)[25]:该算法提出了一个异常度量标准,并利用这个标准来制定MUVAD 的目标,以显式地估计正常实例集,提高异常检测算法的精度。
Fast-ODT(Fast Outlier Detection Tree)[26]:使用离群检测树,构造一个分类树将数据集分类为两个类,然后,使用树中的if-then规则将每个数据点分为离群点和正常点。
HUAD(Hybrid Unsupervised Anomaly Detection)[27]:该模型集成了卷积自编码器和高斯回归来提取特征和去除噪声数据中的异常,并且对数据集异常率的变化具有更强的鲁棒性。
DDAD(Distance-based Distributed Anomaly Detection)[28]:该算法通过低维平面距离观测数据的近似分布来实现异常检测,并且可以有效地扩展到多个维度。这些近似也可以用于其他应用程序,例如范围查询的在线估计。通过估计数据的潜在分布来识别异常,并且以分散的方式处理尽可能多的数据。
GFUAD(Geometric Framework for Unsupervised Anomaly Detection)[29]:该算法提出了一种新的无监督异常检测的几何框架,将数据元素映射到一个特征空间,通过确定哪些点位于特征空间的稀疏区域来检测异常。提出了两个特征映射数据元素到特征空间:第一个映射是一个依赖于数据的规范化特征映射,将其应用于网络连接;第二个特性映射是一个频谱内核,将其应用于系统调用跟踪。
通过实验3发现,本文提出的LSBFAD 算法在三种IIoT数据集上的DR 都要优于对比的异常检测算法,且LSBFAD 算法的FAR 都低于10%,这说明LSBFAD 算法在DR 和FAR 都体现出了更加优秀的性能,能够有效检测出隐性异常;并且LSBFAD 算法训练Bloom Filter 模型的过程中只需要正常数据,不需要异常数据,这也提高了模型的通用性。
5 结语
工业物联网系统已呈现出广阔的应用前景,但是传感器设备由于持续使用和正常磨损出现损坏,导致收集和记录的传感数据出现异常,大规模高维特征的存在可能掩盖异常的存在,隐性异常难以被检测系统检测。因此构建一个性能良好的异常检测算法对IIoT 的实际应用具有非常重要的意义。本文提出了基于局部敏感Bloom Filter 的异常检测算法LSBFAD。该算法利用SP-FJLT 投影算法以及MC 策略将数据映射到Bloom Filter 中。在三个不同领域的IIoT 数据集SIFT、MNIST和FMA上进行实验,结果表明,本文提出的LSBFAD算法与主流的异常检测算法相比检测精度具有明显优势。
在未来研究中,我们将从低失真的投影方法出发,找到更加符合数据投影的哈希方法,以进一步来降低数据的失真程度;此外,对于哈希后的数据对象特征的进一步探测,也是未来研究工作的重点。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年8期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
中国典型病例大全(2022年7期)2022-04-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
学生天地·小学低年级版(2019年5期)2019-06-05
试题与研究·中考数学(2016年4期)2017-03-28
电脑爱好者(2015年13期)2015-09-10
