
基于稀疏卷积的前景实时双目深度估计算法
2022-01-05 02:32邱哲瀚
计算机应用 2021年12期
邱哲瀚,李 扬
(广东工业大学机电工程学院,广州 510006)
(∗通信作者电子邮箱lyang@gdut.edu.cn)
0 引言
立体匹配作为无人驾驶的核心技术之一,通过不断提升实时性能为自动驾驶提供更稳定的主动安全措施,伴随着深度学习的进步研究而不断发展。立体匹配算法通过匹配双目图像对中的对应像素,计算每对像素的视差值生成视差图。比起传统的立体匹配算法,深度学习视差估计算法可以有效优化图像深度估计中的不适定问题,能够利用先验知识学习估算出遮挡和弱纹理区域的深度信息。基于深度学习的双目立体匹配网络基本构成[1]包括:双目图像对、空间特征提取模块、视差代价聚合卷(cost-volume)和视差回归模块。
2015年,Mayer等[2]首次提出端对端的双目视差估计网络DispNet,通过下采样方式提取空间特征后构建视差代价聚合卷cost-volume,并对cost-volume 进行视差解码,最终回归出稠密的视差估计图。网络DispNet采用端对端的结构,可以直接从双目图像中获取视差估计图,算法的总体性能高。为了进一步提高预测精度,不同于Mayer 等采用二维卷积视差回归模块,Chang 等[3]提出的PSMNet(Pyramid Stereo Matching Network)将下采样的空间特征通过偏移、堆叠形成带有视差通道的4 维cost-volume,并引入三维卷积层[4]进行视差回归,显著提升了视差估计的准确性,但同时也增加了运算资源占用。这是由于卷积层维度从二维到三维的增加,导致了网络参数量大幅增长,算法的实时性能随之也大幅下降。为此,本文方法在构建4 维cost-volume 时,采用稀疏卷积代替稠密卷积,通过只对前景进行特征提取的方式减小输入参数量的初始规模,达到缓解卷积层维度增加带来的参数量增长问题。
针对如何提高算法实时性的问题,Graham[5]提出用稀疏卷积(Sparse Convolution,SC)代替稠密卷积减少运算量。稀疏性允许网络使用运算效率更高的卷积神经网络(Convolutional Neural Network,CNN)架构,且运行更大、稀疏的CNN 可能会提高结果的准确性。具体地,Graham[6]通过在前景区域设置活动站点(active site)稀疏化数据,使得SC 只对稀疏化的数据进行卷积操作,减少了运算量。针对SC会随着卷积层的加深无法保留数据稀疏性的问题,Graham 等[7]提出了子流形稀疏卷积(Submanifold Sparse Convolution,SSC)。SSC 只对输入的活动站点进行卷积操作,且只对具有激活站点的输出赋值,在保持数据原有稀疏性的同时进一步减少了运算量。为了最大限度发挥SC的优势、克服稠密卷积参数量大的缺点,本文方法通过分割算法稀疏化输入数据,并在特征提取主干网络中使用SC 和SSC 完全取代稠密卷积,改善了立体匹配算法的实时性。此外,Uhrig等[8]使用SC在稀疏数据中恢复出稠密视差图,表明SC具有从稀疏数据中提取深度信息的能力。根据该结论,本文方法使用SC 构造视差回归模块,通过解码稀疏视差代价聚合卷中的深度信息,生成能够预测稀疏前景的视差估计图。因此配合分割算法和SC 实现对立体匹配算法的优化,能够有效解决三维卷积解码方式的实时性问题。
视差图中前景的边缘往往会有较大模糊,边缘处视差值误差率大。为了提升立体匹配算法的边缘估计能力,Wang等[9]通过在视差特征中加入语义特征,提升了视差估计的边缘效果;Fu 等[10]提出的注意力模块起到语义上优化边缘细节的效果。可是一般的注意力模块只适用于稠密特征,不能兼容稀疏化特征的提取。本文方法借鉴了注意力机制的构筑方式,构造了适用于稀疏特征的空间注意力机制;同时注意力机制末端采用自适应线性叠加的方法,实现了语义特征和空间特征的叠加,形成能聚合空间、语义特征的语义注意力模块。因此引入语义特征和注意力机制优化立体匹配算法,能够有效地提升网络整体的视差估计精度。
总体上,本文方法利用编码-解码结构的语义分割网络LEDNet[11]作为前景分割模块稀疏化数据,配合一般SC 和SSC逐层提取前景空间特征,大幅减小输入数据的冗余度,提高了立体匹配算法的运算效率。充分利用LEDNet 编码模块的高层语义特征,通过建立语义注意力机制优化稀疏卷积层,可提升视差估计的整体边缘效果。在数据集ApolloScape 的测试中,对比验证了本文方法的实时性和准确性,并通过消融实验证明了本文方法各模块的有效性。
1 模型架构
本文针对场景目标深度估计情景下,基于稠密卷积的双目视差估计算法所采取全局特征无差别提取的学习策略,既耗费额外计算资源,又降低网络提取特征的效率的问题,提出了基于SC 的立体匹配网络(SPSMNet)。模型整体架构如图1所示,本文网络利用编码-解码形式的语义分割模块将图像分割成形状不规则的前景元素和背景元素,把前景元素作为掩膜稀疏化图像并将其输入到空间特征提取模块;利用语义分割编码模块生成空间注意力机制优化空间特征的提取,同时将语义信息嵌入到空间特征中构建视差代价聚合卷;使用带有视差通道的三维稀疏卷积模块解码视差代价聚合卷,最终回归出视差估计图。

图1 SPSMNet模型架构Fig.1 SPSMNet model architecture
1.1 语义分割模块
在立体匹配网络SPSMNet 中,语义分割模块需要为网络提供前景分割功能和提取语义信息,以供后续空间特征提取模块和语义注意力模块的使用,符合条件的语义分割模块的结构将会是编码-解码形式;同时,语义分割模块作为前置模块,必须兼有精度高和处理快的特点。LEDNet作为轻量级语义分割网络且具备编码-解码形式的结构,在数据集ApolloScape 的平均精确度(Average Precision,AP)达到0.91,因此很适合作为语义分割模块。
前景分割功能是稀疏化输入的双目图像的过程。利用网络LEDNet语义分割出的前景掩膜,可以获得输入图像的前景区域。对输入图像的前景区域设置活动站点标识,使得后续的空间特征提取模块能够识别需要处理的区域,从而只对输入图像的前景部分进行卷积操作,实现了输入图像稀疏化的功能。语义信息的获取得益于LEDNet 的构成形式。LEDNet采用多次下采样构造语义编码模块,使得丰富的语义信息紧凑地汇集在编码模块的最后一层特征图。由此,后续的语义注意力模块能够简单方便地获取和使用语义信息。
1.2 空间特征提取模块
基于稠密卷积的立体匹配算法,需要通过学习全局特征以区别多种类多目标边界处的边缘细节、估算各物体内部视差。不同于一般的稠密卷积,SC 可以有选择性地学习前景空间特征,网络的计算资源被更多地分配在优化目标视差的任务上,这使得采用稀疏卷积CNN 架构的立体匹配算法具有良好的准确性和实时性。利用稀疏卷积能够高效提取稀疏特征的特点,使用SC和SSC构建4层下采样的空间特征提取模块,模块架构如图2所示。
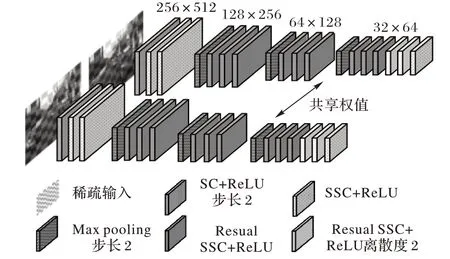
图2 空间特征提取模块Fig.2 Spatial feature extraction module
采用步长为2 的SC 和最大池化函数实现逐层下采样,以保留显著的空间特征、降低特征维度和增大卷积核的感受野;直连或残差连接的SSC 保证了前景特征的稀疏性,同时加强了网络训练的鲁棒性;模块尾端采用离散度为2 的SSC 拓宽卷积核的感受野。卷积层的输入均采用批归一化处理,并使用ReLU 非线性函数激活网络节点,左右图像特征提取的卷积层共享权重。
1.3 语义注意力模块
SC 能够很好地通过稀疏前景估算出前景内部视差,但由于稀疏化的数据损失部分边缘信息,生成的前景视差图边缘不清晰。为了补偿丢失的边缘信息,利用LEDNet解码模块最后一层的特征图构建语义注意力模块,模块架构如图3所示。
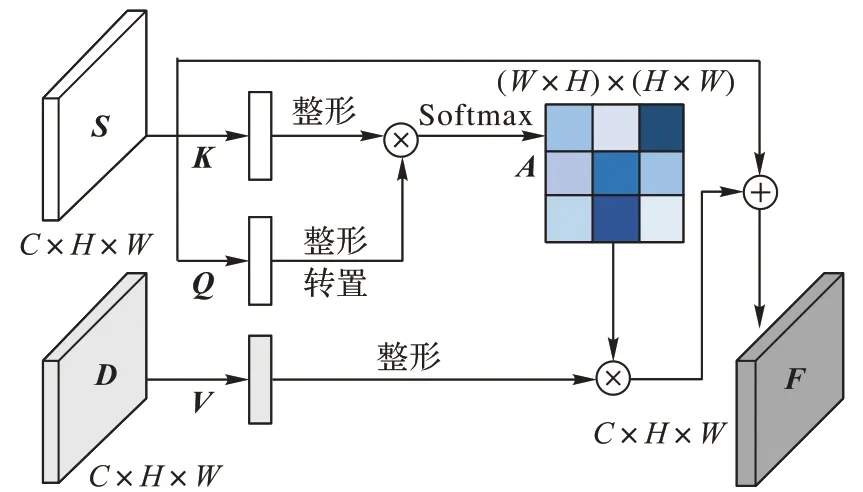
图3 语义注意力模块Fig.3 Semantic attention module
取LEDNet 编码模块的最后一层特征图(segment feature map)记为S∈RC×H×W,特征图S经过核心数为1 的稠密卷积后生成{Q,K}∈R1×H×W。把{Q,K}统一整形成R1×N的结构(其中N=H×W),将矩阵Q转置后与K做矩阵乘积,并应用softmax 函数生成注意力图A∈RN×N。其中aij是注意力图A的元素,i,j为元素坐标,则由{Q,K}生成注意力图A的计算方法如下所示:

取空间特征提取模块的最后一层特征图(disparity feature map)记为D∈RC×H×W,特征图D经过卷积核1× 1 的卷积后整形成RC×N结构(其中N=H×W)。将经过卷积并整形后的特征图D与注意力图A做矩阵乘积,结果加上语义特征图S,之后整形生成聚合特征F∈RC×H×W。其中:fijk是聚合特征F的元素,i、j、k为元素坐标,a、d、s分别是注意力图A、经过1× 1 卷积的空间特征图D、语义特征图S的元素,β为自适应参数。则聚合特征F的计算方法如下所示:

1.4 稀疏视差代价聚合卷
对于一组双目图像输入,在经过语义注意力模块之后,将会得到同时聚合了空间特征和语义特征的左、右两个位置的聚合特征。为了维持特征的稀疏性,由语义注意力模块得到的聚合特征是稀疏的;聚合特征所具有的活动站点标识,其标识的状态与空间特征提取模块最后一层的特征图相一致。视差代价聚合卷是对左、右聚合特征的结合构造,其组织也应该是稀疏的。稀疏视差代价聚合卷的构造方式与PSMNet[3]类似,都是结合左右图中每个视差值对应的特征图,但只对具有活动站点标识的特征做出响应,并输出维持着原有稀疏性的4维代价聚合卷(特征×视差×高×宽)。
在最大可预测视差值设定为D的情况下,由于聚合特征的宽高尺寸是目标视差图的1/8,前景视差估计将会产生D/8个视差值选项,即4维代价聚合卷的视差通道数目。4维代价聚合卷的第d个视差通道即视差值为d时,左、右聚合特征的结合方式为:左聚合特征保持不变,右聚合特征在宽通道上整体右移d个单位,之后在特征通道上对左右特征进行拼接形成视差特征,最后将视差特征在宽通道上由于右移产生的无效左区间的数值置0;同时,移位操作会同步移动活动站点,置0 操作会取消活动站点,拼接操作也会拼接活动站点,这使得稀疏特征能够被正确表示。最后将D/8 个视差特征在视差通道上进行堆叠,形成带有视差通道的稀疏4维代价聚合卷。
聚合卷内不同视差通道的左、右聚合特征,在拼接成视差特征之前,其活动站点需要进行平移和移除操作。根据双目图像左右位置的不同,从属于代价聚合卷内不同视差通道的活动站点a'left,a'right的激活情况如下所示,其中c、h、w是不同视差通道特征图的特征、高、宽通道,d为通道视差值,ε为单位阶跃函数,a是视差聚合前活动站点的激活情况:

在稀疏代价聚合卷的视差通道内,经过平移置零操作后的左、右聚合特征拼接成视差特征的活动站点激活方式如图4 所示,对于视差通道的视差特征,图(a)左聚合特征和图(b)右聚合特征的活动站点标识fleft、fright会合并到图(c)代价聚合层的视差特征中,从而保持了原有特征的稀疏性。
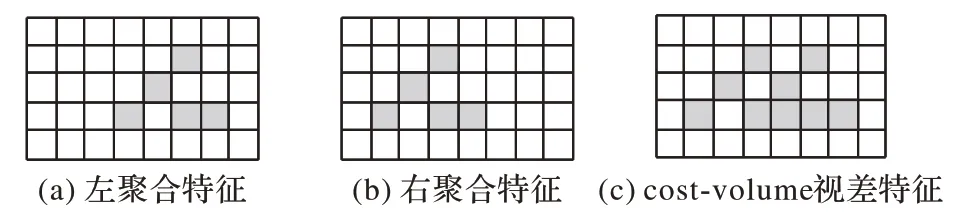
图4 视差通道激活方式Fig.4 Disparity channel activation mode
1.5 视差回归模块
为了适配稀疏的视差代价聚合卷,利用SC 和SSC 构建三维卷积模块对稀疏特征代价卷进行解码。模块架构如图5 所示,模块采用残差连接的方式,SC 与SSC 交替联结。卷积层的输入均采用批归一化处理,每个卷积层后面使用ReLU 非线性函数激活网络节点。
在模块末端的稀疏卷积层,通过连接SC+dense 层将稀疏的解码图转化为稠密的解码图C∈RD×32×64,使用双线性插值对解码图进行8 倍上采样得到C'∈RD×256×512,最后利用以下计算方法回归出最终的视差估计图,其中d为视差值:

1.6 损失函数
实现前景视差估计任务的监督学习,具体做法是通过分割算法有选择性地选取视差真值图的前景区域,只对视差估计图的前景区域使用平滑L1[12]损失作为网络的损失函数。对于视差估计图与视差真值图D,图上对应的每个视差值与di,其整体损失函数可以表示为:

2 实验与结果
2.1 实验数据集
ApolloScape[13]数据集采集自真实路况场景,其中包括适用于不同训练任务的多个子数据集,以满足自动驾驶多种应用需求。立体匹配数据集Stereo 同时包含视差真值图,前景标签图和双目图像对的训练样本共有4 158 个,以6∶2∶1 的比率将样本划分出训练集、验证集以及测试集,并对样本进行清洗和预处理,操作过程遵循以下规则:
1)去除错误标注;
2)对于视差真值图,车体小范围遮挡区域利用邻近的视差值替代,连续遮挡超过1/3车体的区域则直接删除;
3)前景标签图对应视差真值图的删除区域也一并删除。
为了适应网络输出尺寸,采用双线性插值的方法缩放视差真值图,并按照相同比例对视差值进行放缩,利用随机裁剪的方式获取作为训练标签的视差真值图。
2.2 实验设置
2.2.1 训练设置
基于PyTorch[14]深度学习框架,网络的搭载训练和测试过程都在NVIDIA RTX2080 GPU 上运行(可以进行3 个批处理的训练)。首先按照默认参数设置,利用前景标签图监督学习得到训练好的LEDNet,将其嵌入到网络中。将立体匹配的最大视差设置为192,梯度更新采用Adam 优化器(动量参数β1=0.9,β2=0.999),以初始学习率0.001开始训练网络。训练过程每进行50 轮迭代,学习率下调到原来的1/2,直至网络损失稳定在某一数值为止。
2.2.2 测试设置
为了对比本文方法和其他同样在ApolloScape 数据集上进行训练的相关工作,本文采用了常用的衡量指标评估结果。其中表示视差估计图的预测值,di表示视差真值图的实际值,则指标表达式如下所示:
1)平均绝对误差(Mean Absolute Error,MAE):

2)绝对相对误差(Absolute Relative Error,ARE):

3)N点像素误差(NPixel Error,NPE):

2.3 实验结果
从ApolloScape 测试集中选取了5 个图像对,将本文方法与PSMNet[3]和GANet(Guided Aggregation Network)[15]算法进行对比实验,实验结果如图6 和图7 所示,其中前景标签标识着输入图像的前景区域,视差真值的有效范围与前景区域相对应。从图6、7 可以看出,本文方法能够准确预测前景的内部视差和边缘细节,尤其是中远距离物体的视差误差(误差图前景色越暗淡误差越小)明显小于其他两种算法;物体内部视差相对统一,轮廓清晰且过渡稳定,可以较好恢复重合物体的边缘。

图6 ApolloScape测试集的5组样本Fig.6 Five group of samples in ApolloScape dataset

图7 PSMNet、GANet和本文算法对图6的视差估计结果Fig.7 Results of disparity estimation of PSMNet,GANet and proposed algorithms to Fig.6
在视差图生成尺度统一为256×512 的情况下,对测试集的实验结果进行了定量可视化,并把各种方法的误差指标进行了对比,定量结果如表1 所示。表1 中,本文方法的平均绝对误差为1.47 像素,视差误差率在误差大于2、3、5 像素时分别为22.05%、11.16%、3.94%,同时运行帧率为每秒16.53帧,表现效果优于对比的其他算法,具有较高的准确度和实时性。

表1 ApolloScape测试集上的定量结果Tab.1 Quantitative results on ApolloScape dataset
2.4 消融实验
为了更好地分析各个优化策略的性能,依据采取策略的不同,设置三组模型prototype1、prototype2和prototype3进行消融实验。对比本文模型prototype3,模型prototype1 的CNN 架构为一般的稠密卷积,模型prototype2则是采用稀疏卷积但不使用语义注意力策略。在视差图生成尺度统一为256×512 的情况下,选取了ApolloScape测试集中的2个图像对,各个模型的样本实验结果如图8 和图9 所示。从图8、9 可以看出,采取稀疏卷积策略可以更好地预测中远距离前景的内部视差,语义注意力策略很好地弥补了前者策略在近景视差估计上的不足,边缘细节也更加清晰。这得益于稀疏卷积策略能够高效提取前景特征,同时语义注意力策略可以补充稀疏特征缺乏的高层语义信息,能指导生成更加精准的视差图。

图8 ApolloScape测试集的2组样本Fig.8 Two group of samples of ApolloScape test dataset

图9 三个模型对图8的视差估计结果Fig.9 Results of disparity estimation of three models to Fig.8
从表2 可以更加直观地看出,本文方法prototype3 的视差误差率在误差大于2、3、5 像素时分别为22.05%、11.16%、3.94%,在三组模型中具有最佳性能;只采取稀疏卷积策略的模型prototype2,表现效果优于单独采用一般CNN架构的模型prototype1。
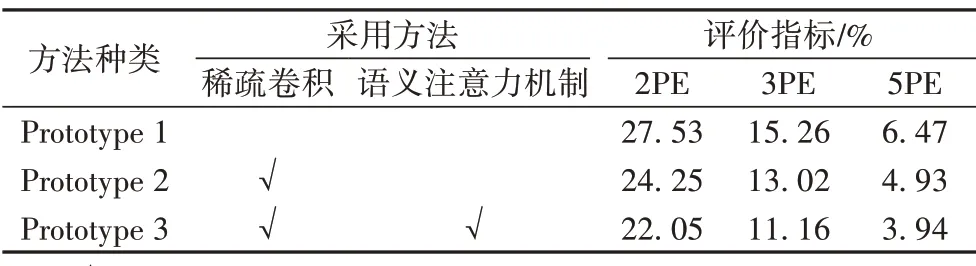
表2 消融实验Tab.2 Ablation experiment
图10展示了200个训练批次下三组模型的验证集损失曲线,从曲线走势可以看出,采取了稀疏卷积策略的网络比模型prototype1 收敛得更快、更平稳;额外采用了语义注意力策略的模型prototype3,其网络收敛速度略快于prototype2。综上所述,本文方法所采用的稀疏卷积策略和语义注意力策略,都对视差估计结果的优化具有一定的有效性。

图10 三组模型的验证集损失曲线Fig.10 Validation dagaset loss curves for three models
3 结语
本文针对前景视差估计的特定任务下,使用稠密卷积架构将造成立体匹配算法资源占用过高、实时性能不足等问题,提出了一种基于稀疏卷积架构的实时立体匹配框架。框架采用了稀疏卷积和语义注意力策略,可以提取丰富的空间、语义联合特征,从而稳定地获得表面平滑,边缘清晰的最终视差图;采用了先提取前景后预测视差的方式,区别于直接获取整个场景的视差图,可以实现对前景区域更快更精准的视差估计。实验结果表明,本文方法具有实时性和准确性的优势,对前景遮挡表现出抗噪性和鲁棒性,视差估计的效果明显优于现有的先进方法。
稀疏卷积架构允许扩大输入图像的尺寸,通过更详细的输入信息获得精度更高的视差图,但是稀疏卷积提取的空间特征缺乏语义信息,这会导致高视差值区域的预测效果不如一般卷积。稀疏卷积架构依赖于分割算法,分割精度会影响到前景空间特征的提取,这意味着网络不是端到端的结构。如何进一步丰富稀疏架构的语义特征,以及实现网络的端到端结构,这些需要在今后的工作中逐步改善和加强。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
计算技术与自动化(2022年1期)2022-04-15
安徽农业科学(2022年6期)2022-04-11
国际太空(2022年1期)2022-03-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
建材发展导向(2021年24期)2021-02-12
海峡姐妹(2019年1期)2019-03-23
长江学术(2015年1期)2015-02-27
