
基于软件体系结构和广义差分进化的测试资源动态分配算法
2022-01-05 02:32邵志胜张国富苏兆品
计算机应用 2021年12期
邵志胜,张国富,苏兆品,李 磊
(1.合肥工业大学计算机与信息学院,合肥 230601;2.大数据知识工程教育部重点实验室(合肥工业大学),合肥 230601;3.智能互联系统安徽省实验室(合肥工业大学),合肥 230009;4.工业安全与应急技术安徽省重点实验室(合肥工业大学),合肥 230601)
(∗通信作者电子邮箱1402369011@qq.com)
0 引言
软件测试是软件开发中的一个至关重要的环节,主要致力于发现和纠正软件错误,提升软件系统的可靠性。众所周知,软件测试几乎要耗费软件开发资源的一半,因此,如何合理分配测试资源,以耗费尽可能少的测试资源,谋求尽可能高的软件可靠性和尽可能少的测试成本,一直是软件工程领域中的一个热点和难点问题[1]。
传统的方法大都局限于单目标优化,如在有限的测试时间内追求可靠性最大或者测试成本最小,并采用动态规划或者拉格朗日乘子法等确定性方法进行求解[2]。上述工作在面临复杂软件开发、软件规模较大时往往很难在可接受的时间内给出有效的解,因此,进化计算技术被引入到软件工程中,以期提升复杂软件工程问题的求解效率[3]。
近年来,随着基于搜索的软件工程[4]的快速发展,多目标测试资源分配(Multi-Objective Testing Resource Allocation,MOTRA)[5]受到越来越多的关注,一些多目标进化算法(Multi-Objective Evolutionary Algorithm,MOEA)[6]被用来求解MOTRA 问题,试图在测试时间消耗、软件可靠性和测试成本之间寻求一个合理的平衡。与传统的动态规划、拉格朗日乘子法等确定性方法相比,MOEA 对Pareto 前沿的形状或连续性不太敏感,可以在一次运行中输出一组解并最终生成Pareto 最优解集[6]。因此,MOEA 作为MOTRA 问题的多目标优化器已经变得越来越流行[7-14]。这些MOEA 可以为软件项目经理提供许多额外的选择,这些选择显示了软件可靠性、测试成本和消耗的测试时间之间的不同权衡,因此可以促进对软件测试环节进行更加合理的规划。
需要指出的是,在现代软件工程中,软件系统通常是通过选择合适的、现成可重用的构件,然后用明晰的软件体系结构组装这些构件来进行开发。这项技术由于能够显著降低软件的开发成本和时间,已在实际的软件行业得到了广泛的应用。然而,已有研究大都针对传统的并串联模块软件模型[5],鲜有涉及体系结构软件模型[15-16]的MOTRA 问题。如Wang 等[7]、Zhang 等[10]、Su 等[11]和Pietrantuono 等[12]利用第二代非支配遗传算法(NSGA-Ⅱ)[17],陆阳等[9]引入非支配排序差分进化算法,牛福强等[13]和占德志等[14]采用第三代广义差分进化算法(Generalized Differential Evolution 3,GDE3)[18]来求解并串联模块软件模型的MOTRA。在并串联模块软件模型中,通常采用可靠性框图(一个系统由多个串行子系统组成,每个子系统中至少有一个并行模块)来直观地描述系统各构件的可靠性连接方式。虽然这种传统的模型非常简单直接,并且在实际的软件系统中也得到了广泛的应用,但是它并没有充分考虑系统的体系结构(依赖于实际应用中的运行剖面)这一重要的系统特性[8]。
相反,基于体系结构的软件模型能够通过定量地识别软件体系结构中最关键的构件来评估面向对象和基于构件的软件系统的可靠性,近年来越来越受到欢迎[15-16]。因此,研究体系结构软件模型的MOTRA 问题具有重要的现实意义。然而,时至今日仅有Yang 等[8]提出了一种归一化加权求和多目标差分进化(Multi-Objective Differential Evolution based on Weighted Normalized Sum,WNS-MODE)算法。此外,上述工作简单的假设软件测试是一个静态的过程。在实际的软件测试中,软件项目经理通常会根据用户需求和软件测试结果动态调整测试流程,即整个软件测试环节往往被划分成若干个测试阶段[12-13]。在每个测试阶段,软件的可靠性以及发现的软件错误数可能因用户需求或软件测试结果而发生动态变化,这时就需要根据变化后的测试环境动态调整测试时间的分配,而上述静态测试资源分配方法显然难以适应上述测试环境的动态变化。
基于上述背景,本文面向体系结构软件模型,针对可靠性和发现的错误数在不同测试阶段动态变化的测试环境,首先构造了一种基于体系结构的多阶段多目标测试资源分配模型,然后基于参数重估计、种群重新初始化、GDE3和归一化加权求和设计了一种面向动态可靠性和错误数的多阶段多目标测试资源分配算法,最后通过仿真实验验证了所提方法的有效性。
1 问题描述
本节从文献[8,15]中回顾体系结构软件模型的测试资源分配,并将其扩展到本文的动态测试问题。
首先,基于体系结构的软件模型如图1 所示,整个软件系统由n个构件组成,构件i和构件j之间可能存在着一步转移概率pij∈[0,1],i,j∈{1,2,…,n},表示构件i运行完后有pij的概率过渡到构件j。对于每个构件i,满足,即从构件i出去的所有一步转移概率之和为1。
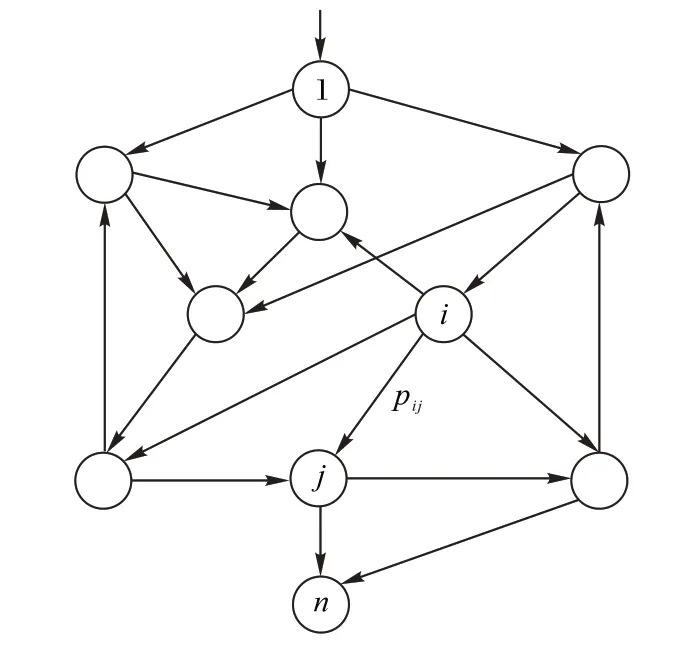
图1 基于体系结构的软件模型Fig.1 Architecture-based software model
其次,体系结构软件模型看成是一个吸收马尔可夫链(其中pij=1 的状态称为吸收状态),其转移矩阵为P=[ ]pijn×n,显然,P中的每一行之和均为1。假设图1 中共有l个吸收状态和n-l个非吸收状态,则可把转移矩阵划分[8,14]为:
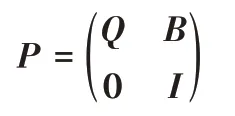
其中:0 是一个l×(n-l)的零矩阵(所有元素均为0);I是一个l×l的单位矩阵(对角线上的元素均为1,其余元素均为0);B是一个(n-l)×l的非零矩阵;Q是一个(n-l)×(n-l)的亚随机矩阵(每一行的元素之和不超过1)。
根据吸收马尔可夫链的性质,矩阵I-Q有可逆矩阵M:
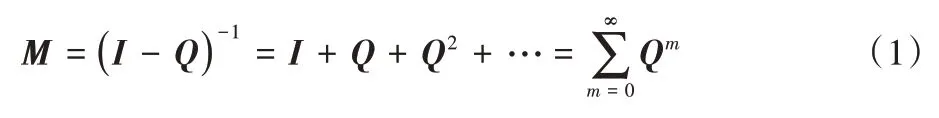
M中的每个元素为从一个非吸收状态到另一非吸收状态的预期访问次数,记

为从初始状态0到非吸收状态i的预期访问次数[8,14]。
和惯例[8,15]一样,考虑测试时间作为主要的测试资源。系统总的可用测试时间为T∗,可由参与测试的软件工程师人数乘以每个工程师的工作时间而计算得到。假设整个软件测试环节被分成了s个测试阶段,每个测试阶段的预期可用测试时间为,k∈{1,2,…,s},满足

则第k个测试阶段实际可用测试时间为:

根据上述知识,使用经典的可靠性增长模型来评估构件软件系统的可靠性。在可靠性增长模型中,系统的可靠性满足非齐次泊松过程[8]:


其中,τ为软件系统的有效工作时间,通常为给定的常数;μ0,i为构件i的预期访问次数,可由式(1)、(2)得到。此外,λ(⋅)为构件i的错误强度函数,通常由错误均值函数[15]:

求偏导得到,即

软件测试带来的成本非常复杂,包含各种因素,考虑风险成本的系统成本模型[8]为:
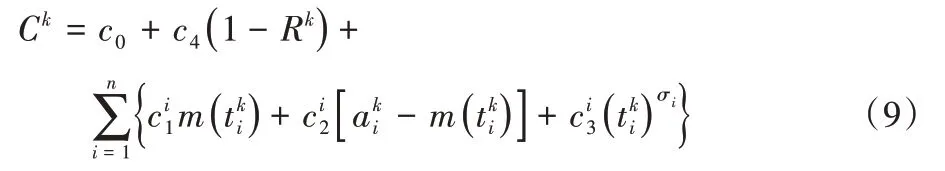
其中:c0为软件测试准备成本;c4为软件失效产生的成本;为构件i的测试阶段纠正软件错误的成本;为构件i运行阶段纠正软件错误的成本;为构件i的一般测试成本(大都指人力成本);0 <σi<1为构件i的一般测试成本折扣率。
综上所述,基于体系结构软件模型的动态测试资源分配问题可描述为如下的一个多阶段三目标优化模型:

满足如下约束:
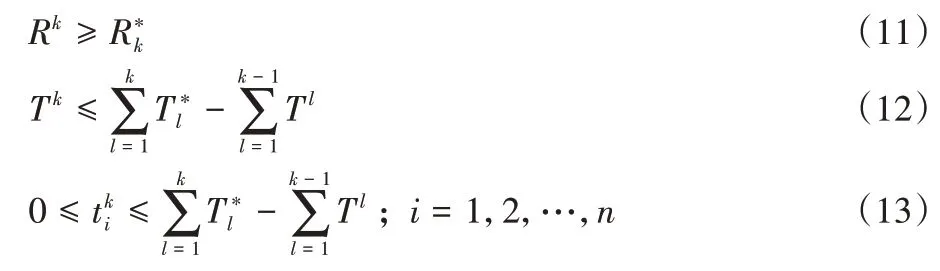
其中:式(10)是为了最大化第k个测试阶段的系统可靠性、最小化系统成本和测试时间消耗;式(11)为每个测试阶段的可靠性下限;式(12)、(13)为每个测试阶段的测试时间上限。
与文献[8,14]不同的是,上述模型考虑了软件的多阶段动态测试,而且还考虑了不同阶段其可靠性约束和可用的测试时间可能会发生变化。
2 测试资源动态分配算法设计
式(10)~(13)是一个典型的动态多约束多目标优化问题,对求解器的性能要求较高。Yang等[8]已经验证在求解构件软件的MOTRA 时,多目标差分进化算法比经典的非支配遗传算法[17]的搜索性能更好,因此,本文引入GDE3[18]来求解构件软件测试资源动态分配问题,称为DTRA-GDE3(Dynamic Testing Resource Allocation based on GDE3)算法。
为了更加清晰地说明本文所提出的DTRA-GDE3,下面将详细介绍DTRA-GDE3 算法中的一些关键细节,并给出算法的整体框架和具体步骤。
2.1 基本GDE3算法
GDE3 算法[18]继承了差分进化算法的全局搜索能力,且引入了非支配遗传算法[17]中的非支配排序、约束违背度和拥挤距离计算等算子,能够更好地保证解的收敛性和多样性。GDE3算法的基本步骤如下:
1)根据约束条件随机生成种群规模为N的初始种群。
2)根据目标函数和约束条件评估种群中每个个体的目标函数值和约束违背程度。
3)对种群中的每个个体p∈{1,2,…,N}执行如下操作:
a)从种群中随机选择三个与p互不相同的其他个体q1,q2,q3。
b)在个体所有的基因位中随机选择一位g∗。
c)生成新个体q:对于个体中的每一个基因位g,在(0,1)之间生成一个随机数r,执行
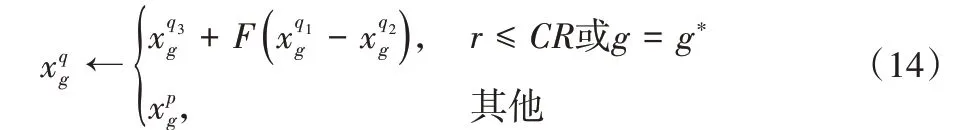
其中:CR∈[0,1]为交叉概率,F∈[0,2]为缩放因子。
d)评估新个体q的目标函数值和约束违背程度。
e)如果新个体q能够支配当前个体p,则将个体q放入新种群中;如果当前个体p能够支配新个体q,则将当前个体p放入新种群中;如果新个体q和当前个体p互不支配,则将这两个个体同时放入新种群中。
4)如果新种群的规模超过了N,计算新种群中每个个体的拥挤距离,并对新种群进行非支配排序,保留N个最好的个体。
5)如果没有达到最大迭代次数Gmax,转步骤3),否则结束算法,输出新种群。
由上述流程可以看出,GDE3算法的时间主要耗费在对新种群的非支配排序,其时间复杂度为O(MNlogN)[17],其中M为优化的目标数,因此,GDE3 算法总的时间复杂度为O(GmaxMNlogN)。
2.2 构件参数重估计
在动态测试资源分配中,前一个阶段k的测试结果显然会影响当前k+1测试阶段的开展。对于构件i,前一个阶段k被纠正的错误多,当前k+1阶段的剩余错误数就会减少。此外,与文献[13-14]不同的是,本文根据实际软件测试环境,还考虑在前一个阶段k可能会发现新的错误(例如纠正软件错误带来的新错误等),这时当前k+1 阶段的剩余错误数可能会增加,相应地,错误检测率也会变化。因此,在优化当前k+1阶段的测试资源分配时,需要利用极大似然估计[13-14]基于前一阶段k在构件i上消耗的测试时间、纠正的错误数和发现的新错误数,对当前k+1阶段构件i的参数重新进行估计:
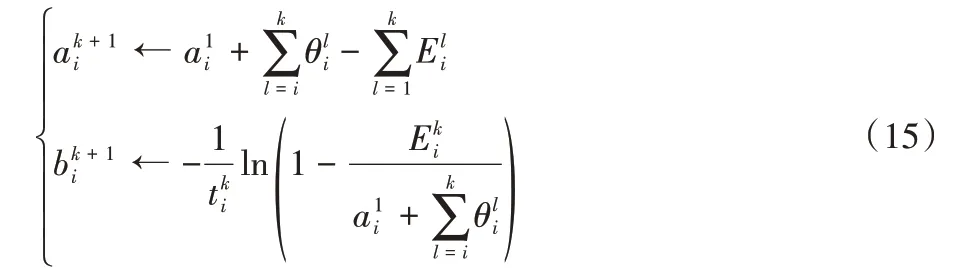
2.3 种群重新初始化
由于在每个测试阶段,可靠性约束(11)、测试时间约束(12)、(13)以及构件参数均是动态变化的,因此,在优化每个测试阶段的测试时间分配时,需要在种群进化前依据新的约束空间对种群重新初始化,以尽可能地让种群靠近当前阶段的可行解区域。此外,可以通过分析模型,把测试时间尽可能地分配给最需要的构件,从而让系统尽可能地满足当前阶段的可靠性约束,驱使种群快速向可行解区域进化,提升算法对动态环境的适应性。
根据可靠性约束(11)可以看到,要想测试时间分配方案满足给定的可靠性下限约束,每个构件i分配到的测试时间至少存在一个下限。同理,根据测试时间上限约束(12),每个构件i分配到的测试时间至少存在一个上限。如果能把区间尽可能地缩小,则可以在种群初始化时,利用这个区间驱使每个个体尽可能地同时满足给定的可靠性下限约束和测试时间上限约束,即尽量让每个个体可行。基于上述考虑,首先,根据式(5)和(8)可以得到:

以式(16)作为等式约束条件,利用经典的拉格朗日乘子法[2]求解最小化总测试时间消耗,即满足时最少需要投入的总测试时间,然后可推导出此时每个构件投入的测试时间为:
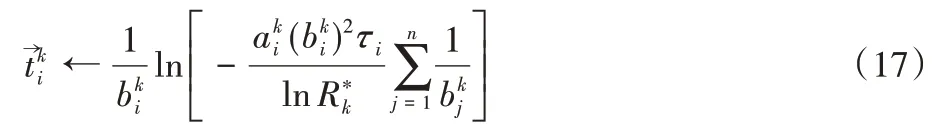

再由式(12),得到
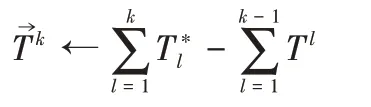
表示第k阶段可用的测试时间总量,则可得出且。这是因为,时可靠性不可能满足超过时则会违背测试时间约束。


通过上述种群重新初始化策略,可以在每一个阶段,迅速让个体逼近同时满足可靠性和测试时间约束的可行解区域,加快种群的进化,提升算法的收敛性能。
2.4 归一化加权求和选取方案
每一个阶段优化完成后,需要从解集中选取一个最佳分配方案来规划当前测试阶段。本文使用流行的归一化加权求和方法[8,14]进行测试时间分配方案的选取:

其中:w1,w2,w3∈[0,1]表示各个目标的重要程度,满足w1+w2+w3=1;为第j个目标的归一化值,如式(22)。

其中:min(fj)和max(fj)分别表示解集中第j个目标上的最小值和最大值。
基于式(21)对解集中所有的解进行归一化加权求和,然后选择值最小的f对应的解作为当前阶段的测试时间分配方案。
此外,在本文中,随着测试阶段数的增加,投入的测试时间总量不断加大,这时可以更加注重可靠性的权重,因为软件测试的最终目标就是为了最大化系统的可靠性[1]。因此,随着阶段数的增加,本文动态增加可靠性目标f1的权重w1。
2.5 DTRA-GDE3算法框架
图2 给出了本文DTRA-GDE3 算法的流程,其基本思想是:在每个测试阶段开始时,首先基于上一阶段的测试结果(纠正的错误数和新发现的错误数),利用极大似然估计对构件的参数进行重新估计,以让构件参数适应测试环境的变化;然后基于更新后的构件参数和模型参数(当前可用的测试时间总量和可靠性约束),利用二分法和拉格朗日乘子法确定每个构件测试时间的上下限,以让决策变量适应测试环境的变化;紧接着,利用GDE3 算法优化当前阶段的MOTRA;最后,利用归一化加权求和选取当前阶段的最佳分配方案规划当前阶段的测试活动。
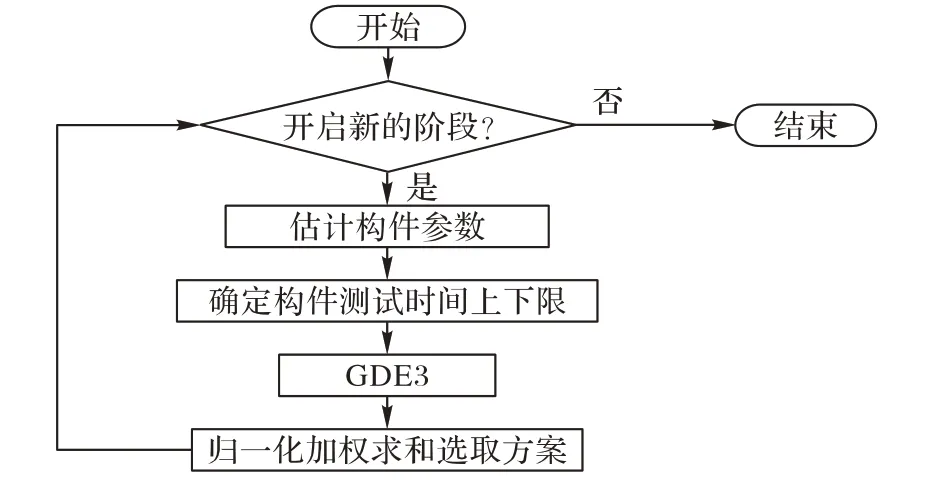
图2 DTRA-GDE3算法的流程Fig.2 Flowchart of DTRA-GDE3 algorithm
二分法和拉格朗日乘子法的时间复杂度为O(n),确定每个构件的测试时间上下限的时间复杂度最多为O(n2),因此在上述流程中,DTRA-GDE3 算法的时间主要耗费在GDE3 中,其时间复杂度为O(GmaxMNlogN)。因此,DTRA-GDE3 算法总的时间复杂度为O(sGmaxMNlogN),其中s为测试阶段数。
3 仿真实验结果与分析
为了验证本文所提算法的有效性,与文献[8]的WNSMODE 算法进行对比分析。WNS-MODE 算法是Yang 等[8]为求解构件软件的MOTRA 而设计的一种高效多目标优化算法。
3.1 实验参数和评价指标
本文考虑两种体系结构软件系统:单输入单输出(Single-Input and Single-Output,SISO)系统和多输入多输出(Multi-Input and Multi-Output,MIMO)系统[8]。此外,如图1 所示,体系结构软件模型的复杂性除了构件数,主要体现在系统中状态转移边的总数。因此,为了更加全面地进行对比分析,在SISO 系统和MIMO 系统上分别采用三种不同的规模:10 个构件、约40 条状态转移边的简单系统;20 个构件、约150 条状态转移边的复杂系统;50个构件、约800条状态转移边的大型系统。模型参数如表1所示,共有3个测试阶段。构件的初始参数范围如表2 所示,这些参数范围均来自文献[8,14]。此外,c0=50,c4=50 000。本文依据上述参数对SISO系统和MIMO系统各随机生成10个不同的实例。

表1 系统模型参数Tab.1 Parameters of system model
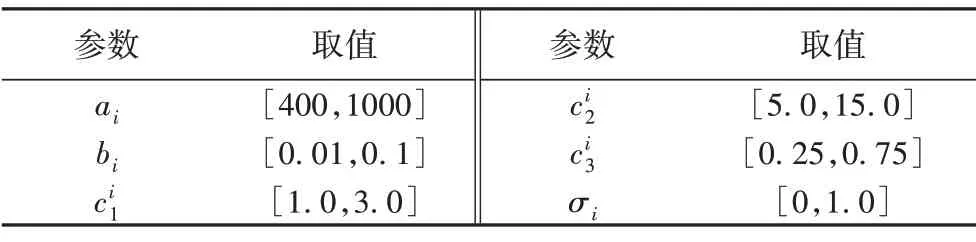
表2 构件参数范围Tab.2 Parameter range of components
DTRA-GDE3 和WNS-MODE 的算法参数设置如下:种群规模为250,每阶段都迭代500 次,CR=0.9,F=0.1。此外,在WNS-MODE 中,归一化加权求和的权重固定为w1=0.1,w2=0.4,w3=0.5。在DTRA-GDE3 中,w1,w2,w3在三个阶段的值分别为{0.1,0.4,0.5}、{0.04,0.35,0.61}和{0.01,0.3,0.69},在第二和第三阶段的值分别在[20,60]和[3,12]中随机生成。
所有对比算法的代码均基于C++编写,为了能够进行统计分析,每个实例均在Intel Core i5 CPU @ 3.2 GHz、8 GB RAM个人计算机上独立运行30次。
为了衡量解集的优劣,使用经典的覆盖值(Coverage value,Cv)[19]指标。Cv 直观地比较了一个算法得到的解有多少被对比算法的解所支配,可作为收敛性指标来比较不同算法的解集的质量。假设A和B分别表示两个不同算法得到的解集,如果A中的一个解在任何目标上都不比B中的另一个解差,则称A中的这个解覆盖了B中的一个解。Cv(A,B)表示A覆盖B的百分比,即B中被A覆盖的解在B中的占比。Cv(A,B) >Cv(B,A)表示A对应的算法要比B对应的算法收敛性更好。为了计算在每个实例上对比算法的覆盖值,对于每个实例,将30 次独立运行得到的解集合并在一起,并去掉重复的解,然后比较合并解集之间的覆盖值[20]。
为了进一步对比算法的整体性能,使用流行的超体积指标[21]。超体积指的是非支配解集与参考点之间的目标空间的体积,可以从整体上衡量整个解集的收敛性和多样性。通常,超体积值越大意味着解集的质量越好。需要注意的是,参考点的选择对于计算超体积至关重要。为了确定合适的参考点,对于每个实例,首先将所有算法的30 次独立运行获得的解合并在一起,然后去掉重复解,再对剩下的解进行非支配排序,去掉所有的支配解,对于余下的非支配解,可将参考点设置为每个目标上最差值的1.1 倍,这种方法已被验证可以在解集的收敛性和多样性之间达到一个良好平衡[20]。
除了一般多目标优化问题的质量指标(如覆盖值和超体积)外,在基于搜索的软件工程中,还强烈建议能够适应用户显式/隐式偏好的问题特定指标来评估解集[22]。在这里,考虑容量值指标[23]。容量值指的是算法最终得到的非支配可行解的个数,即满足所有约束条件的非支配解数目。和上面一样,对于每个实例,将30 次独立运行得到的解集合并在一起,并去掉重复的解。
3.2 容量值结果
为了方便后续描述,将DTRA-GDE3 所获得的解集标记为A,WNS-MODE得到的解集标记为B。
表3~5 分别给出了DTRA-GDE3 和WNS-MODE 算法在简单、复杂和大型SISO 和MIMO 系统上20 个实例的容量值结果,分别用 |A| 与 |B| 表示代表A、B算法获得解集的容量值,即满足条件的解的个数。由表3和表4可以看出,在简单和复杂SISO和MIMO系统上,本文DTRA-GDE3算法在任何一次运行中都能找到很多可行的非支配解,而WNS-MODE 算法在第1阶段就只能找到很少的可行解,在第2 阶段和第3 阶段更少,甚至30 次运行都找不到可行解,如简单SISO 系统的实例1 的第2阶段,简单MIMO 系统的实例3的第2阶段,复杂MIMO 系统的实例4的第2阶段。特别地,在表5中,DTRA-GDE3在10个实例上获得的可行解均接近7 500 个,但WNS-MODE 算法在10个实例上几乎找不到可行解。

表3 简单系统中两种算法的容量值结果Tab.3 Capacity value results of two algorithms in simple system
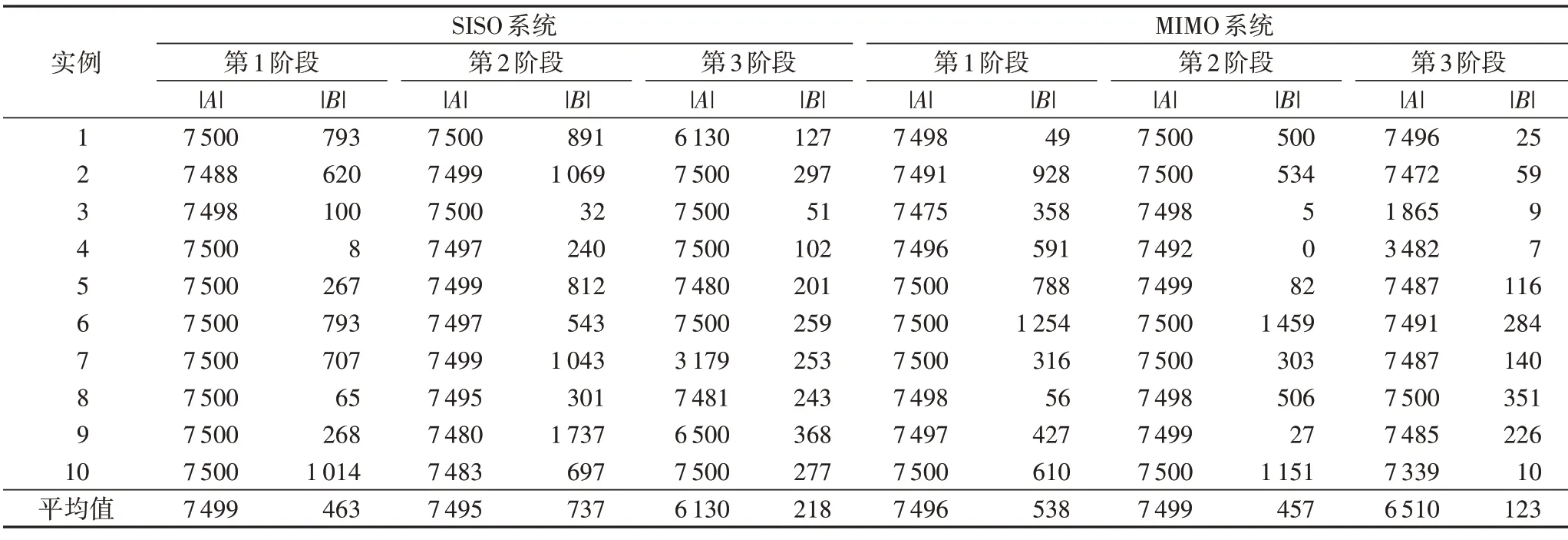
表4 复杂系统中两种算法的容量值结果Tab.4 Capacity value results of two algorithms in complex system
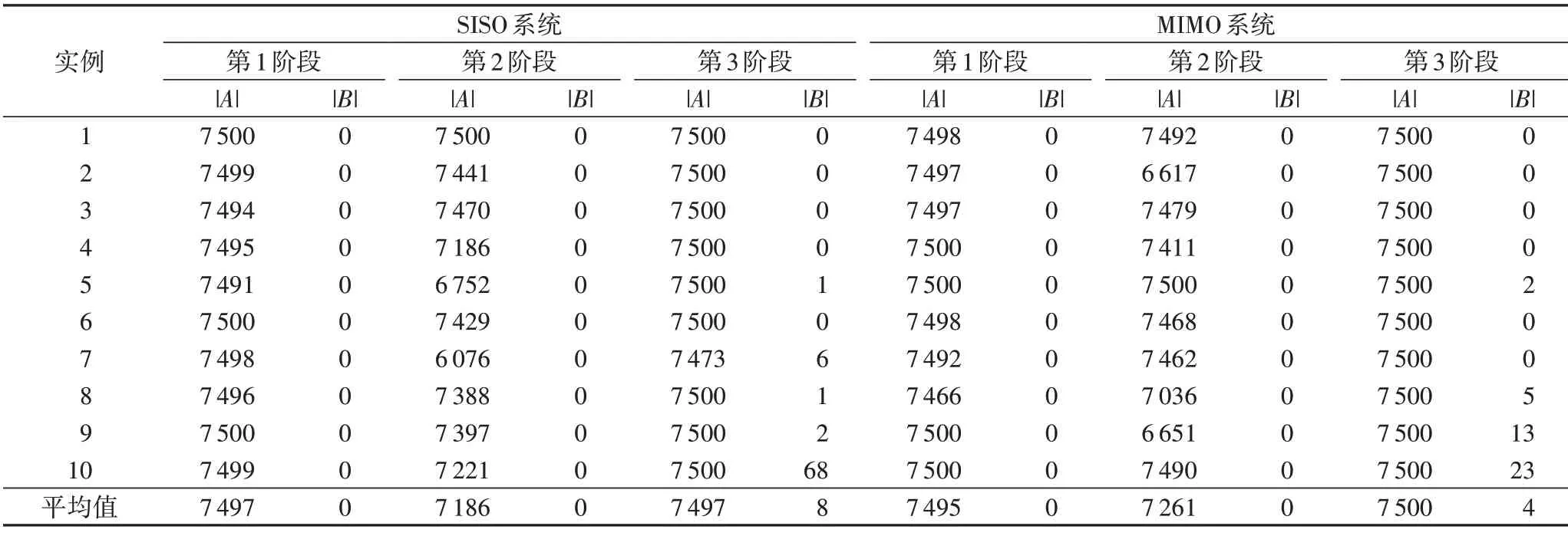
表5 大型系统中两种算法的容量值结果Tab.5 Capacity value results of two algorithms in large system
总的来说,在SISO 系统上,DTRA-GDE3 在简单、复杂和大型三个规模上获得的解集的平均容量值分别为7 499、7 041和7 393,而WNS-MODE 算法在三个不同规模获得的平均容量值却仅有925、473 和3,DTRA-GDE3 在整体上的容量值提升了约15倍。在MIMO系统上,DTRA-GDE3在三个不同规模上获得的解集的平均容量值分别为7 500、7 168、7 419,而WNS-MODE 算法在三个不同规模上获得的平均容量值分别为803、373 和1,DTRA-GDE3 在整体上的容量值提升了约18倍。综合考虑两种系统,DTRA-GDE3 较WNS-MODE 在容量值上提升了约16 倍;而且,规模越大,DTRA-GDE3 算法的优势越明显。上述实验结果表明,本文DTRA-GDE3 算法要比WNS-MODE 算法具有更好的探索能力,可以很好地适应不同的系统规模,挖掘更多的非支配可行解。
3.3 覆盖值结果
由于WNS-MODE 算法在大型规模上几乎找不到可行解,因此,表6 和表7 分别给出了两种算法在简单和复杂SISO 和MIMO 系统上20 个实例的覆盖值结果。可以看出,DTRAGDE3算法的覆盖值除了在简单MIMO 系统实例8的第3阶段略逊于WNS-MODE 外,在其他简单和复杂SISO 和MIMO 系统的所有实例的所有阶段上均显著优于WNS-MODE 算法。在某些实例上,DTRA-GDE3算法的覆盖值达到了100%,即可以完全支配WNS-MODE 算法的解集,如简单SISO 系统的实例1和实例4的第2阶段,简单MIMO 系统的实例1和实例3的第2阶段和第3 阶段,实例2 的第3 阶段,实例10 的第2 阶段。尤其在复杂系统上,DTRA-GDE3 在24 种情形下覆盖值达到100%,而WNS-MODE算法在10种情形下覆盖值为零。

表6 简单系统中两种算法的覆盖值结果 单位:%Tab.6 Coverage value results of two algorithms in simple system unit:%
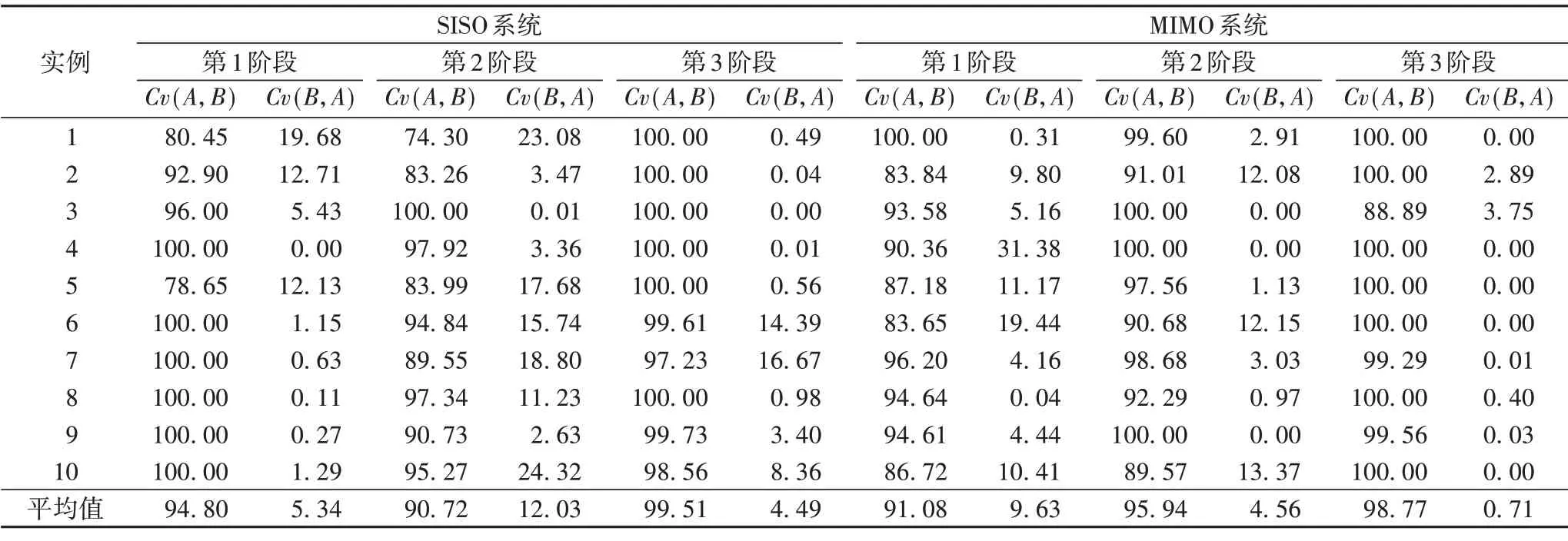
表7 复杂系统中两种算法的覆盖值结果 单位:%Tab.7 Coverage value results of two algorithms in complex system unit:%
从总体上看,在SISO 系统上,DTRA-GDE3 在简单和复杂两种规模上获得的解集的平均覆盖值分别为91.26%和95.01%,而WNS-MODE 算法在这两种规模上获得的平均覆盖值却仅有14.21%和7.29%,DTRA-GDE3 在整体上的覆盖值提升了约83个百分点。在MIMO系统上,DTRA-GDE3在两种规模上获得的解集的平均覆盖值分别为92.18% 和95.26%,而WNS-MODE 算法在两种规模上获得的平均覆盖值分别为12.17%和4.97%,DTRA-GDE3 在整体上的覆盖值提升了约85 个百分点。综合考虑两种系统,DTRA-GDE3 较WNS-MODE 在覆盖值上提升了约84 个百分点。上述实验结果表明,本文DTRA-GDE3 算法要比WNS-MODE 算法具有更好的收敛性,可以找到更好的非支配解。
3.4 超体积结果
表8 和表9 分别给出了两种算法在简单和复杂SISO 和MIMO 系统上20个实例的超体积结果(均值和标准差)。可以看出,除了在简单SISO 系统实例9 第3 阶段上DTRA-GDE3 得到的超体积不大于WNS-MODE 算法外,在其他简单和复杂SISO 和MIMO 系统的任何实例任何阶段上,DTRA-GDE3得到的超体积均要优于WNS-MODE 算法。特别地,在某些实例上WNS-MODE 的超体积为0,说明解集中的解均被参考点支配或者找不到任何可行解,如简单SISO 系统实例1 的第2 阶段,简单MIMO 系统实例3的第2阶段,复杂SISO 系统实例4的第1阶段,复杂MIMO系统实例4的第2阶段。

表8 简单系统中两种算法的超体积(均值和标准差)结果Tab.8 Hypervolume(mean and standard deviation)results of two algorithms in simple system
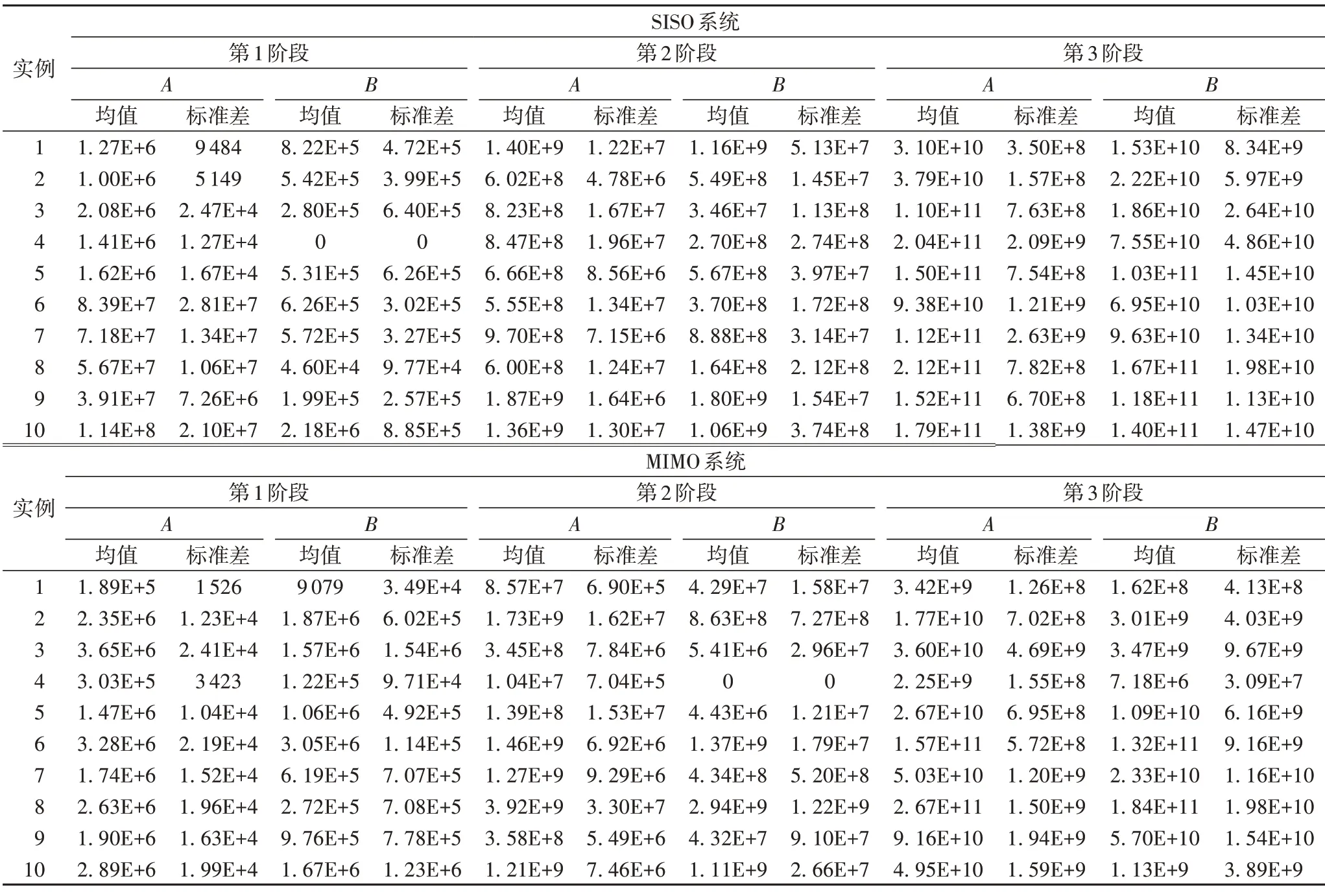
表9 复杂系统中两种算法的超体积(均值和标准差)结果Tab.9 Hypervolume(mean and standard deviation)results of two algorithms in complex system
从整体上来看,在SISO 系统上,DTRA-GDE3 相比WNSMODE的超体积在简单和复杂规模上分别提升了约13%和22倍,在MIMO 系统上,DTRA-GDE3 相比WNS-MODE 的超体积在简单和复杂规模上分别提升了约13%和69%。综合考虑两种系统,DTRA-GDE3 较WNS-MODE 在超体积上提升了约6倍。上述实验结果表明,本文DTRA-GDE3 算法要比WNSMODE算法具有更好的综合性能。
为了直观地理解非支配解的分布以及更高的超体积代表的含义,在图3 中,根据简单MIMO 系统中的实例9 分别在三个阶段选取和超体积均值比较接近的一次运行结果,绘出解集的分布情况。之所以选取这个实例,是因为它的超体积与整体超体积均值更接近。从图3 可以看出,与WNS-MODE 算法相比,DTRA-GDE3 算法得到的解在目标空间中分布更广,提供了更多的多样性。此外,易观察到DTRA-GDE3 算法似乎比WNS-MODE 算法具有更好的收敛性,有相当多的解优于WNS-MODE算法。

图3 两种算法在简单MIMO系统实例9上获得的非支配解Fig.3 Non-dominated solutions obtained by two algorithms on Instance 9 of simple MIMO system
3.5 运行时间结果
图4 给出了两种算法在MIMO 系统上不同规模的10 个实例上的运行时间结果(均值和标准误差)。从图4 可以看出,DTRA-GDE3在简单系统、复杂系统和大型系统上的平均运行时间分别约为16.9 s、75.8 s 和37.6 s,而WNS-MODE 运行时间分别约为2.2 s、14 s 和9 s。DTRA-GDE3 要比WNS-MODE稍微耗时一点。这是因为,在求解本文的构件软件测试资源动态分配问题上,DTRA-GDE3 的时间复杂度为O(sGmaxMNlogN),而WNS-MODE的时间复杂度为O(sGmaxMN),而且,DTRA-GDE3 还需要多次调用拉格朗日乘子法来估计构件的测试时间上下限,而且调用的次数也与解空间大小有关,具有一定的随机性。需要强调的是,虽然DTRA-GDE3 相比WNS-MODE 平均慢了30 多秒,但是相比在容量值、覆盖值和超体积三个指标上的显著提升,这点耗时是可以忽略不计的。

图4 两种算法在MIMO系统上的运行时间(均值和标准误差)Fig.4 Running times(means and standard errors)of two algorithms on MIMO systems
3.6 讨论
从上面的容量值、覆盖值和超体积的实验结果可以看出,与WNS-MODE 算法相比,本文的DTRA-GDE3 算法可以很好地满足体系结构软件模型的动态测试需求,能够为每个测试阶段提供更多、更好的测试时间分配方案。这是因为,在DTRA-GDE3 算法中,根据参数重估计,可以很好地适应纠正和发现的错误数的变化;其次,根据种群重新初始化,可以让个体尽可能地满足测试时间和可靠性约束,从而接近可行解区域,促使DTRA-GDE3 算法高效地适应环境的变化。而WNS-MODE 算法虽然也对测试时间的变化采取了相应的约束处理技术,但是其首先满足的是测试时间约束,而没有考虑可靠性约束,因此其探索可行解的能力非常有限。
本文从SISO 和MIMO 两种系统的简单、复杂和大型三种规模进行了对比分析。实验结果表明,对于一些复杂难解的多目标优化问题,完全可以根据问题本身来挖掘有用的信息,利用问题本身的知识来缩小MOEA 种群的探索范围,避免无效的重复搜索,从而提升MOEA 解决复杂动态多约束优化问题的能力。
4 结语
测试资源分配是基于搜索的软件工程中的一个热点问题,主要研究如何规划软件工程师的测试时间,从而尽可能地缩短测试周期,降低测试成本,提高软件系统的可靠性。本文针对体系结构软件模型的动态测试问题,首先构建了一种基于体系结构和可靠性、错误数动态变化的多阶段多目标测试资源分配模型,然后基于参数重估计、种群重新初始化、广义差分进化和归一化加权求和设计了一种面向动态可靠性和错误数的多阶段多目标测试资源分配算法。与已有工作相比,本文所提算法在容量值、覆盖值和超体积三个主流性能指标上获得了更优的结果。在今后的工作中,将考虑成本的约束,以及构件的动态增加等问题。
猜你喜欢
今日农业(2022年15期)2022-09-20
科学与财富(2019年17期)2019-04-17
中学生物学(2018年8期)2018-03-01
计算机教育(2017年5期)2017-05-31
考试周刊(2015年62期)2015-09-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中学生物学(2008年6期)2008-08-29
中学生物学(2008年2期)2008-07-07
