
基于L-Metric重叠子图发现的B细胞表位预测模型
2022-01-05 02:32高闯,唐冕,赵亮,2*
计算机应用 2021年12期
高 闯,唐 冕,赵 亮,2*
(1.广西大学计算机与电子信息学院,南宁 530004;2.湖北医药学院太和医院,湖北十堰 442000)
(∗通信作者电子邮箱S080011@e.ntu.edu.sg)
0 引言
B 细胞表位是抗原表面上可以被抗体的免疫反应识别的特定区域[1]。识别抗原与抗体相结合的表位对现代药物和疫苗的开发起到至关重要的作用[2-3]。通过实验方法(如X 射线晶体学[4])检测表位虽然准确,但需要消耗大量的时间和资源,因此,探索有效并且可靠的计算方法进行抗原上的B细胞表位识别,具有重要的现实意义;同时,蛋白质数据库(Protein Data Bank,PDB)[5]中提供的抗原-抗体结构数据也为预测算法的研究提供了帮助。
目前,已经开发出许多可用于预测表位的计算方法。Kringelum 等[6]提出的方法使用了来自376 种抗原-抗体复合物的107 个抗原数据的结构和几何特征;Sun 等[7]通过分析161 种免疫球蛋白复合物的理化性质和结构特征,识别表位和非表位之间的差异。随着机器学习算法的发展,这些技术也被用于设计表位预测算法。例如,Zhang等[8]结合常规特征和从3D 结构中提取的特殊特征,将随机森林算法用作分类器,设计B 细胞构象表位的预测模型。此外基于图的方法也被应用于表位预测,如CEP(Conformational Epitope Prediction server)[9]。但是,这些方法大部分只关注单个或多个分离的表位,对抗原中存在的重叠表位的预测效果不理想。与免疫反应相关的蛋白质不止存在单个或多个分离的结合位点情况,还存在多个重叠的结合位点的情况[10]。Zhao 等[11]提出的模型已经证明重叠的子图挖掘方法可以提高对抗原表位的识别能力,特别是对于多个重叠表位;但是,该模型在子图扩展阶段需要设置阈值,这会降低模型的泛化能力。
针对现有表位预测方法对重叠表位预测能力不佳的问题,本文提出了一种基于局部度量(Local Metric,L-Metric)[12]的重叠子图发现算法用于表位预测的模型SGLMEP(overlapping SubGraph mining based on L-Metric for Epitope Prediction)。该模型分为三个主要步骤:1)利用抗原-抗体复合物中的表面原子构建氨基酸残基图;2)利用马尔可夫聚类算法(Markov CLustering algorithm,MCL)[13]将氨基酸残基图划分为互不重叠的种子子图,并利用重叠子图发现算法对种子子图扩展以得到重叠子图;3)利用图卷积神经网络(Graph Convolutional neural Network,GCN)[14]和全连接网络(Fully Connected Network,FCN)[15]构建的分类器对子图进行分类。
1 氨基酸残基图的构建
本文采用两个步骤构建氨基酸残基图:第一,利用抗原链中氨基酸残基的表面原子构建原子图;第二,将表面原子图升级为氨基酸残基图。表面原子的定义是指可及表面积(Accessible Surface Area,ASA)不小于10 Å2的原子[16]。为了得到抗原主链和侧链上的表面原子,本文使用工具NACCESS(Non-commercial atomic solvent ACCESSible area calculation)[17]计算每个原子的ASA,探针大小采用默认设置。根据表面原子的坐标构建KD(K-Dimensional)树[18](利用空间划分在k维空间中存储点的一种数据结构),计算由表面原子构成的不大于阈值(设置为8 Å)的边。通过此步骤可以得到抗原的原子图表示。若两个氨基酸残基中的原子至少有一组边,则定义两个残基存在边。按照此规则,将原子图表示升级为氨基酸残基图。当两个氨基酸残基的侧链最外层原子之间存在边时,则两个残基也一定存在边,因此,为了减少计算量,在构建原子图表示时仅利用主链的表面原子与侧链的最外层原子。
2 基于L-Metric的重叠子图发现算法
对重叠社区的检测已被广泛用于发现社交网络中的社区挖掘[19-20]。本文基于子图划分和社区挖掘思想提出了基于L-Metric的重叠子图发现算法,包括子图发现和子图扩展两个阶段。
2.1 子图发现
MCL 是一种子图划分的算法,它基于消息流传递发现图中成员的不重叠分组[13],因此,首先使用该算法将氨基酸残基图划分为互不重叠的种子子图。MCL的机制是模拟带权重的无向图中的消息流传递过程,需要输入由边权重组成的转移矩阵。本文基于Zhao 等[16]提出的边界边思想,设计边权重的计算公式。
本文计算氨基酸残基(组成生命体中蛋白质的20 种氨基酸)r1和r2构成的边的权重W(r1,r2),由两部分组成,即由r1和r2构成的边在表位和非表位中的频率的χ2检验和对数函数生成,具体计算式为:
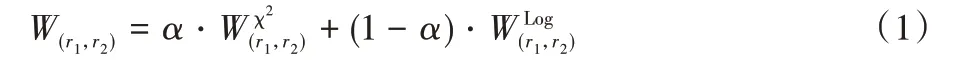
其中:α为超参数,通过网格搜索法优化后为0.4;Wχ2(r1,r2)和的计算式如式(2)、(3)。

其中:c∈{c1,c2},c1为表位残基,c2为非表位残基为在残基图x中标签是c的残基r1和r2构成的边的出现频率;为标签是c的残基r1和r2构成的边出现频率的期望。的计算式为:

其中:P为由氨基酸残基图所组成的数据集;的计算如式(5)。
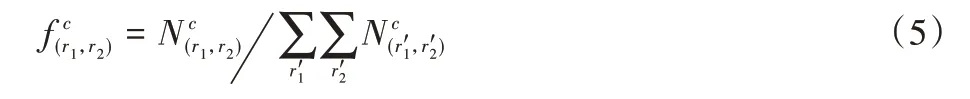
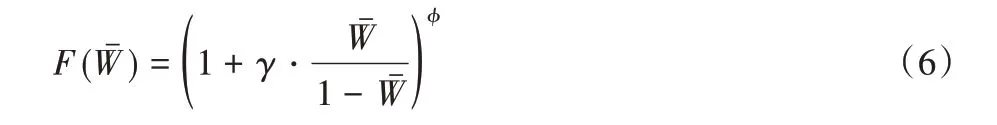
其中:γ和φ为超参数,通过网格搜索法优化后分别为4和1。
在残基图中,边界边(由表位残基和非表位残基构成的边)的存在会影响对表位与非表位残基的鉴别。利用上述公式,计算在c1为边界残基和c2为表位残基、c1为边界残基和c2为非表位残基的两种情况下边的权重,这两个权重中较大的为边的新权重。当权重不小于θ(超参数,通过网格搜索法优化后为0.5)时,则这条边被当作边界边从残基图中删除。
2.2 子图扩展
L-Metric可以度量局部社区网络中的成员关系紧密度,它的优点是不需要全局网络信息,且不需要设置任何参数。本文基于L-Metric对种子子图进行扩展,以检测重叠子图。
图1 描述了在氨基酸残基图G中的一个子图的定义。D是G的一个子图内的点构成的集合,它被分为两部分:边界点集合B(与D外的点存在连接关系的点构成的集合)和核心点集合C(仅与D中的点存在连接关系的点构成的集合)。邻居点集合N是D外与边界点存在连接关系的点构成的集合。

图1 子图描述Fig.1 Description of subgraph
本文中度量L的计算方法为:

式中,Lin和Lex分别为内部和外部的度量,具体计算式为:


式中:Win和Wex为子图内部和外部权重;W(ri,rj)为由式(1)计算得到的边权重。
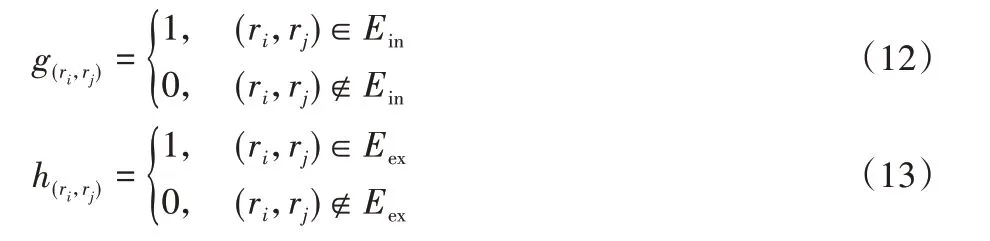
式中:Ein为由D中的点构成的边集;Eex为B中的点与N中的点构成的边集。
因此,当新加入的点满足第1)种和第2)种情况时,该点被加入后形成新的D。当没有其他点被添加进D时,则得到扩展后的重叠子图。扩展后的重叠子图包含表位残基和非表位残基。本文将表位残基数不少于3 个的重叠子图标记为表位子图,其他标记为非表位子图。
3 基于深度学习的子图分类模型
3.1 模型总体架构
抗原表位预测的难点之一是特征选择问题[21]。深度学习是一种无特征学习算法,它能够自动提取特征,降低因专业知识不足而导致忽略某些重要特征的可能性。本文构建了基于深度学习的子图分类模型,总体架构如图2 所示,主要由基于图卷积神经网络(GCN)构建的特征提取器和基于全连接网络(FCN)构建的分类器两部分构成。
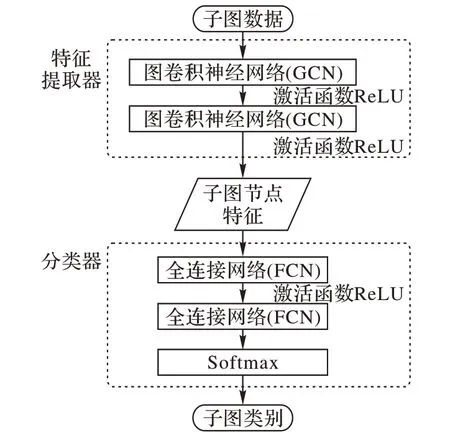
图2 分类模型总体架构Fig.2 Overall architecture of classification model
图卷积神经网络(GCN)是卷积神经网络(Convolutional Neural Network,CNN)在图数据上的扩展,它可以有效地利用图数据的全局信息表示图节点的特征。本文构建的特征提取器包含两层GCN。假设GCN 的输入子图G=(A,Z),A∈Rn×n表示子图带权重的邻接矩阵,Z∈Rn×d表示节点的特征矩阵,其中,n表示图中节点的数量,d表示节点特征向量的维度。第i∈{1,2}层的GCN通过式(13)得到第i层节点特征矩阵:

由两层FCN 构成的分类器,以特征提取器得到的节点特征矩阵为输入。第j∈{1,2}层FCN的映射公式为:

分类器得到子图节点的类别属性(表位残基或者非表位残基),然后利用子图类别定义(子图中含有不少于3 个表位残基的子图为表位子图)对子图进行分类。
3.2 基于代价敏感的损失函数
由于表位与非表位数据的数量极不平衡,表位子图的数量远远少于非表位子图的数量。在本文使用的训练数据中,表位子图的数量与非表位子图的数量之比为1∶6。为了避免与此问题相关的性能损失,本文在训练过程使用焦点损失函数(Focal Loss function,FL)[23]作为网络结构的损失函数,计算式为:

式中,λ为超参数,通过网格搜索优化后为2。pt和αt的计算式如下:
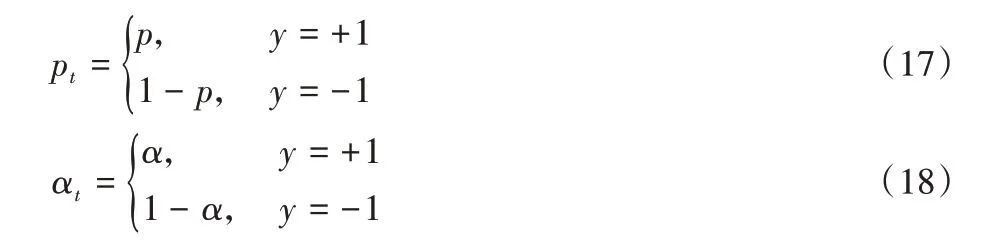
式中:p∈[0,1]为正类的概率;α∈[0,1]为正类在训练样本中所占比例;y∈{-1,+1}为子图标签类型(其中,-1 表示负类即非表位子图,+1表示正类即表位子图)。
4 实验和结果分析
4.1 实验数据
本文从PDB 中检索到808种抗体-抗原复合物,利用通用的数据选择标准[10,16]从其中筛选出397 种复合物。然后,使用 工 具 CD-HIT(Cluster Database at High Identity with Tolerance)[24]去除序列相似性不小于0.9 的冗余数据以降低噪声。最终,获得了由254个复合物组成的实验数据。
4.2 模型评估及分析
由于非表位子图数据的数量远多于表位子图数据,为了实验的准确性,本文采用F1值、召回率Re(Recall)和精确度Pre(Precision)作为模型表位子图分类效果的评估指标,计算式为:

式中:TP(True Positive)表示实际为表位子图被正确预测的数量;FN(False Negative)表示实际为表位子图被错误预测的数量;FP(False Positive)表示实际为非表位子图被错误预测的数量。
选择当前主流的表位预测模型DiscoTope 2(Discontinuous epiTope prediction 2)[25]、ElliPro(Ellipsoid and Protrusion)[26]、EpiPred(Epitope Prediction server)[27]和Glep(overlapping Graph clustering-based B-cell epitope predictor)[10]与本文所提出的模型SGLMEP 进行比较。图3 描述了各个表位预测模型的F1值分布。从图3 中可以看出,SGLMEP 的F1值优于其他模型,且拥有更高的性能下限。
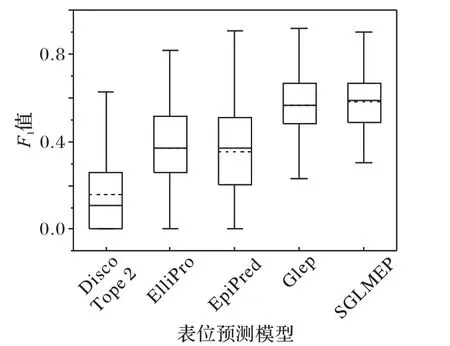
图3 表位预测模型的F1值比较Fig.3 F1-score comparison of epitope prediction models
表1 给出了各表位预测模型的平均F1值、召回率和精确度。与表位预测模型DiscoTope 2、ElliPro、EpiPred 和Glep 相比,本文所提出的模型SGLMEP 将平均F1值分别提高了267.3%、57.0%、65.4% 和3.5%。从表1 可以看出,模型SGLMEP 主要的优势在于拥有更高的召回率,与Glep 相比提高了18.3%。实验结果说明,SGLMEP 能够识别出更多的潜在表位残基,对重叠表位的识别优于Glep。虽然SGLMEP 的精确度不是十分突出,但仍然高于大多数模型。

表1 不同预测模型结果对比Tab.1 Result comparison of different prediction models
4.3 消融实验结果及分析
本文所提出的模型SGLMEP 的核心是基于L-Metric 的重叠子图发现算法。通过在相同实验数据上进行消融实验,验证该算法对表位预测性能的影响。
通过图4可以直观地看出,基于L-Metric的重叠子图发现算法的F1值高于未使用的情况。实验结果表明,该重叠子图发现算法对表位预测性能的提升是有效的。应用该算法的模型的优势主要是提高了召回率,即对未知表位残基的识别能力。
表2 给出了消融实验的详细结果。通过表2 中数据可以看出,应用了基于L-Metric 的重叠子图发现算法的模型相较于未使用子图发现算法时的平均F1值、召回率分别提高了19.2%和38.9%。

表2 消融实验的详细结果Tab.2 Detailed results of ablation experiment
5 结语
为提高重叠表位预测性能,本文提出了基于L-Metric 的重叠子图发现算法,自适应对种子子图进行扩展。同时,利用深度学习算法自学习特征的特点设计分类模型,降低人工设计特征构建分类器的难度。通过实验验证了本文所提出的表位预测模型SGLMEP 对抗原表位具有良好的预测性能。此外,通过消融实验验证了本文所提出的重叠子图算法的有效性。在今后的研究工作中,将对重叠子图发现算法进行优化,旨在发现更多潜在表位的基础上,进一步提高对表位识别的精确程度。
猜你喜欢
保健与生活(2022年12期)2022-06-09
文萃报·周五版(2022年12期)2022-04-02
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
少儿科学周刊·儿童版(2021年22期)2021-12-11
数学大王·趣味逻辑(2021年9期)2021-09-10
孩子·小学版(2020年11期)2020-12-10
家庭用药(2018年12期)2018-02-14
华声(2017年7期)2017-05-18
智慧与创想(2013年5期)2013-06-25
