
基于XGBoost算法和LightGBM 算法的贷款违约预测模型研究
2022-01-11 09:42唐一峰
现代计算机 2021年32期
唐一峰
(广西师范大学数学与统计学院,桂林 541006)
0 引言
近年来,随着社会生活水平的提高,人们的消费需求、消费能力日益增长,但是绝大多数的年轻人并没有一定的经济储蓄,这就意味着大多数人的消费都离不开贷款的支持,例如:房贷、车贷以及各种分期消费贷款等等。随着互联网企业的兴起,贷款不再是银行独有的业务,支付宝的“借呗”“花呗”,微信的“微粒贷”,京东的“白条”等等,还有各种互联网P2P平台都能提供一定额度的贷款,贷款与人们的生活日益紧密。根据中国人民银行最新公布的金融机构人民币信贷收支数据显示,2021 年1 月各项存款为2161418.83 亿元,贷款总额为1763234.93 亿元,其中住户贷款为644532.95亿元;2021年2月各项存款为2172935.17 亿元,贷款总额为1776828.68亿元,其中住户贷款为645994.37 亿元;2021 年3月各项存款为2209233.14 亿元,贷款总额为1804131.37 亿元,其中住户贷款为657466.81 亿元。各项数据均显示贷款是我国的社会经济发展的重要一环,因此各金融机构要严格控制贷款发放,针对用户的贷款违约风险预测就显得尤为重要。
针对贷款违约风险预测,由于机器学习、神经网络等数据挖掘技术逐渐兴起,越来越多的学者将这些技术应用到了贷款违约风险预测。赵晓翠(2006)[1]针对商业银行信贷风险评估应用主成分分析和支持向量机的方法,首先利用主成分分析提取关键特征,降低维数,然后利用支持向量机的方法构造广义最优超平面,结果表明这一方法有很好的分类正确率;张晟(2020)[2]针对互联网P2P 借贷平台的数据应用XGBoost 算法、随机森林算法、投票分类算法对违规用户进行画像分析,根据评价指标AUC 值,得分最高的是随机森林算法,第二是XGBoost 算法,第三是投票分类算法,但是在数据样本较大的情况下集成学习整体运算时间较长,调参也有一定难度,容易出现过拟合现象;宋点白(2019)[3]针对消费为主的个人短期贷款利用Logistic 和RUSBoost 随机森林模型对违约风险因素进行分析,得出商业银行可根据掌握的人口特征和贷款特征判断个人短期贷款违约风险,并提前进行风险应对。
基于其他学者的研究,发现LightGBM 算法应用的较少,本文选择XGBoost 算法和LightGBM 算法建立模型,利用大数据挖掘技术,对贷款违约因素进行分析,并选择合适的评价指标对两个模型进行比较,最后给出本文的结论和建议。
1 算法理论简介
1.1 XGBoost算法简介

利用泰勒二阶展开式得到损失函数的极小值,然后,采用精确或近似方法贪心搜索出得分最高的切分点,进行下一步切分并扩展叶节点[5]。
1.2 LightGBM算法简介
LightGBM 是微软亚洲院提出的一种基于梯度提升决策树的算法,对标XGBoost,它最大的特点就是运算速度快、效率高。LightGBM 在寻找损失函数的最优分割点时基于梯度的单边采样,对于样本xi,其梯度gi越小说明yi与yi已经非常接近了,在寻找分割点时可以把它的权重放低一点。另外在特征方面LightGBM 运用互斥特征捆绑,试图把尽可能多互斥的特征捆绑在一起,降低数据维度的同时,最大程度的保留数据的信息,加快了运算速度。在树的节点生长方面,LightGBM 按Leaf-Wise 策略生长,选择能够使损失函数减少的最多的节点分裂,可以通过设置max_leaf 参数让树停止生长。最后,在树模型中,位置越靠前的分类器在模型中重要程度越高,而位置越靠后的模型,则对整体的影响很小。Light-GBM 使用DART技术使得后面的分类器也发挥较大的作用[5]。
1.3 评价指标AUC值简介
本文引入混淆矩阵的概念,如表1所示。

表1 混淆矩阵
在逻辑回归里面,对于正负例的界定,通常会设一个阈值,大于阈值的为正例,小于阈值为反例。如果我们减小这个阀值,更多的样本会被识别为正例,提高正类的识别率,但同时也会使得更多的反例被错误识别为正例。为了直观表示这一现象,引入ROC。
根据分类结果计算得到ROC 空间中相应的点,连接这些点就形成ROC curve,横坐标为False Positive Rate(FPR:假正率),纵坐标为True Positive Rate(TPR:真正率)。ROC 曲线与x轴所围成的面积就是AUC(area under ROC curve)值。一般情况下,这个曲线都应该处于(0,0)和(1,1)连线的上方,也就是AUC值大于0.5。
2 实证分析
2.1 数据分析及预处理
数据来源于天池平台上金融风控比赛的数据集,数据集有15 万条,数据集数据包含47 列变量信息,其中idDefault是是否违约,是目标变量,另外有15 列为匿名变量,并且对employment-Title、purpose、postCode 和title 等变量信息已经脱敏过了。大致可以把变量分为四类:贷款信息、借款人信息、借款人信用信息以及n系列匿名变量,部分变量介绍如表2所示。

表2 部分变量介绍
本文先对数据的变量特征进行一个大概的了解,对于日期变量:earliesCreditLine、employmentLength、issueDate,日期变量都需要经过处理才能代入模型.issueDate 的格式是“2014/7/1”这样的,本文将这个变量另外命名为issueDateDT,表示该issueDate 的日期与数据集里最早的日期的间隔天数,操作之后把issueDate 删除;employmentLength 的格式是“<1 year、2 years、8 years、10+years”这样的,操作以后employment-Length 变成范围在0~10 之间的数值变量;earliesCreditLine 的格式是“May-1992、Sep-1994 、Nov-2010”,操作之后只保留后面的年份,也变成了数值变量。
下面本文对数值型变量的值进行分析,发现policyCode 全都是值1,所以把该变量删除;然后来查看变量中的缺失值情况,如图1所示。
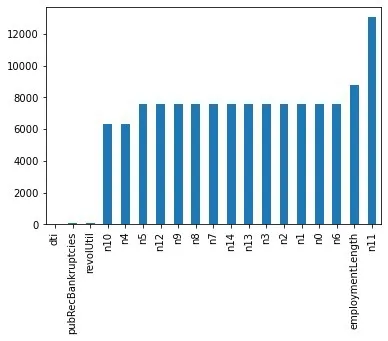
图1 缺失值分布情况
变量中缺失值最多的是n11,有13033条缺失值,n10、n4、n5、n9、n8、n7、n14、n3、n2、n1、n0、n6 以及employmentLength 的缺失值在6000~8000 之间,这里本文选择用平均数对数值型变量进行填补,对类别型变量本文使用众数进行填补。将数值型变量分为离散和连续型两种,观察连续型数值型变量的分布情况,对于分布不符合正态分布进行对数化变换,使得该变量更加接近正态分布,因为一些情况下正态型变量可以让模型更快的收敛,并且贝叶斯算法对数据正态有喜好,部分连续变量分布如图2所示。

图2 部分连续型变量的分布情况
接下来,对于类别变量grade 有“A、B…F、G”七个等级,本文用1~7 的值来对应;对类型数在2 之上,又不是高维稀疏且纯分类的变量homeOwnership、verificationStatus、purpose、region-Code、subGrade,本文使用pandas 的get_deummies函数得到它们的虚拟变量。
2.2 特征工程


图3 剩余变量相关系数
到这里,本文对数据集的特征工程部分就可以结束了,下面开始建立模型。
2.3 建模调参
本文使用的算法是LightGBM 算法和XGBoost算法,调参用的方法是贝叶斯优化方法。贝叶斯优化的原理[4]是:①根据最大化采集函数来选择下一个最有“潜力”的评估点xi。②根据选择的点xi评估目标函数yi=f(xi) +εi。③把新得到的输入观测值对(xi,yi)添加到历史观测集中,并更新概率代理模型,为下一次迭代做准备。本文先分别建立两个模型要估计参数的CV 函数,给出各个参数的估计范围,经过贝叶斯优化之后,得到最优的参数。LightGBM 算法和XGBoost 算法的参数如表3所示。

表3 部分重要参数的值
2.4 模型预测结果
本文利用模型交叉五折验证,LightGBM 模型的最优迭代次数大约是1420次,得到的AUC值为0.7221。XGBboost 模型的最优迭代次数大约是4004 次,得到的AUC 值为0.7285。ROC 曲线如图4所示。

图4 两个模型的ROC曲线对比
3 结语
经过本文对两个模型的特征重要性分析,贷款发放时间、信贷周转余额合计、债务收入比、年收入、分期付款金额、信用等级、贷款金额等变量对模型的贡献度较高。显而易见,贷款发放时间越长违约率越高,信贷周转余额越少违约率越高,债务收入比越高违约率越高,年收入越高违约率越低,分期付款金额越高违约率越高,信用等级越高违约率越高,贷款金额越高违约率越高,进一步说明了本文的两个模型是合理的。
本文的两个模型得到的AUC 值还算理想,也比较接近,说明两个模型都有不错的学习能力和预测能力,但是在实际操作过程中XGBoost 算法的运算速度实在是太慢了,在贝叶斯调参过程和模型训练的过程中都很慢,虽然XGBoost 得到的结果稍微比LightGBM 好一点,但是电脑配置不行的话,本文还是主推LightGBM模型。
建议金融机构在发放贷款的时候,一定要完善贷款人的信息,严格审核贷款人的贷款资格,健全自身的风险评估体系,有科学明确的发展方向。
猜你喜欢
阅读与作文(英语初中版)(2019年8期)2019-08-27
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
数学学习与研究(2017年10期)2017-06-22
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
新高考·高二数学(2014年7期)2014-09-18
福建中学数学(2011年9期)2011-11-03
