
基于核典型相关分析的多视图谱聚类算法
2022-01-11 05:11王春杰石延新何进荣王文发
延安大学学报(自然科学版) 2021年4期
王春杰,石延新,何进荣,王文发
(延安大学 数学与计算机科学学院,陕西 延安 716000)
随着信息量的不断增加,数据结构的越来越复杂。随着数据采集技术的发展,大量的数据以各种形式呈现,形成了多视图数据[1-2],例如,一个物体可以用各种形式来描述,它的形状、颜色或纹理。多视图数据比单视图数据具有更多的特征信息,每个视图中的特征信息趋于互补[3],这使得多视图数据的研究比单视图数据更有意义[4]。直接学习多视图数据不仅浪费大量的时间和成本,而且会导致维灾难,因此多视图数据学习面临着更严峻的挑战[5]。
典型相关分析[6](Canonical Correlations Analysis,CCA)是一种将两个多维变量之间的线性关系关联起来的方法,可以看作是寻找两组变量的基向量的问题,使得变量在这些基向量上的投影之间的相关性相互最大化。在很多问题里,两个变量之间的关系是不能简单用线性相关来表示的。为了提高特征选择的灵活性,核方法利用把低维数据映射到高维特征空间能很好的处理了一些非线性数据,成为了一种很好替代方法。近年来,核方法在处理数据方面取得了很大的进展。越来越多的学者对基于核的方法感兴趣,潘荣华等[7]从模型识别的角度提出了基于核的局部保持CCA的算法。Lai等[8]提出了针对于人工神经网络有关核的几个非线性典型相关的扩展,文献[9-10]也相继提出了有关核CCA的方法。Fyfe等[11]推导出一种基于内核CCA新方法,同时还利用非线性核的低阶典型相关性,揭示了时变混合矩阵的性质。Bach等[12]随后在再生核Hilbert空间中,不仅证明了其对比函数与互信息有关,还基于核方法的最新发展证明了这些准则及其导数可以有效地计算。Hofmann等[13]通过数据域定义的函数再生核希尔伯特空间中描述学习和估计问题,论述了使用正定核函数的机器学习方法。Nielsen[14]简要介绍了基于多集CCA的方法,并将这个方法作为经验正交函数技术的多元扩展。此外,Chen等[15]针对大多数工业过程是非线性的采用了核典型相关分析(KCCA),获得了更精确的状态监测效果。最近,Mitsuhiro等[16]则提出了一种将KCCA的扩展与统计匹配相结合的数据组合方法。可以估计公共低维空间的正则变量,保持协变量和结果变量之间的关系。Hui等[17]提出了一种基于特征分解的鲁棒方法,用于多视图图像分类。他们引入特征因式分解矩阵来度量维数中各特征向量与投影向量之间的近似值,由于图像从多个视图获取的,还提出了一种基于多投影向量的多因子分解矩阵的方法,权衡了投影中每个特征的重要程度,得到了更好的多视图图像的特征表示。
基于以上研究的启发,本文提出了一种基于核典型相关分析的多视图谱聚类(Multi-view Spectral Clustering algorithm based on Kernel Canonical Correlation Analysis,以下简称KCCAMvSC)算法模型。首先简要介绍了两个相关的经典算法思想;然后对KCCAMvSC算法模型进行了详细的介绍,并介绍了实验的设计方案以及对实验结果进行验证和分析;最后对本文进行了总结和展望。
1 相关工作
主要介绍2个经典的多视图聚类算法,即多视图K-Means和多视图谱聚类。
1.1 多视图K-Means(MK)
K-Means的核心思想:根据样本集之间的距离大小将样本集分为K个簇,现假设把数据集里的簇分为(C1,C2,…Ck),则目标函数为
(1)
E是平方误差,μi是簇Ci的均值向量。通过矩阵G∈Rd×n来替换,其目标函数为
(2)
G是聚类指导矩阵,F是中心矩阵。通过(2)式将K-Means扩展应用到多视图数据集中,则多视图K-Means的目标函数如(3)式所示
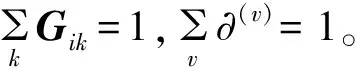
(3)
1.2 多视图谱聚类(MSC)
令{x1(v),x2(v),…,xn(v)}表示视图v,视图v的相似度矩阵和度矩阵分别用K(v)和D(v)表示,则视图v的拉普拉斯矩阵L(v)为
L(v)=D(v)-1/2K(v)D(v)-1/2。
(4)
用SVD来优化(4)式得到(5)式

U(v)TU(v)=I,
(5)
tr是矩阵的迹。文献[18]给出(6)式作为双视图聚类结果是否一致的度量,
D(U(v),U(w))=
(6)
U(v)的相似矩阵用KU(v)表示,先对(6)式进行归一化,选择线性核作为相似性的度量,则
KU(v)=U(v)×U(v)T。
(7)
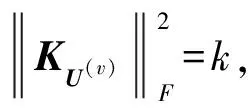
λtr(U(v)U(v)TU(w)U(w)T,
使得U(v)TU(v)=I,U(w)TU(w)=I。
(8)
迭代最大化(8)式,当给定U(w)时,则(8)式可以转化成(9)式
使得L(v)+λU(w)U(w)T。
(9)
(9)式是自适应的,结合拉普拉斯算子与内核函数得到最大值。选用适当的初始化λ和n保证算法收敛,随选取最具有信息性的视图,从该视图开始进行迭代,通过计算迭代之间的目标差值来判断算法是否收敛,当低于某一个设定好的阈值时停止迭代。将两个视图扩展到m个视图时目标函数为
使得U(v)TU(v)=I,∀1≤v≤V。
(10)
选择相同的λ对全部需要共则化的进行平衡。当给定多视图U(v)时,目标函数如下所示
使得L(w)+λU(v)U(v)T。
(11)
2 基于核典型相关分析的多视图谱聚类算法(KCCAMvSC)
2.1 基本思想
本文提出的KCCAMvSC,即将数据通过引用核经过一个变换把最初的样本投影到一个高维的特征空间里面,接着在这个特征空间中可实现不同视图间一致性信息的有效提取,然后在此特征空间中最小化不同视图之间蕴含信息的一致性,应用协同训练的思想对每个视图上进行谱聚类,最终得到所有视图上的结果趋于一致。KCCAMvSC示意图如图1所示。

图1 KCCAMvSC示意图
2.2 数学原理
2.2.1 核典型相关分析
KCCA就是依靠核的理论,经过一个变换把最初的样本投影到一个高维的特征空间,随即在这个特征空间里面在继续进行CCA,通过这样一种方法,间接的完成了最开始空间的非CCA。但是和其他核的方法不相同的地方是:KCCA存在两个变换,这两个变换各自分别作用在两组变量上。KCCA的推导简要的描述如下:
L(wX,wY,λX,λY)=E[(u-E(u))(v-E(v))]-

2.2.2 算法描述
KCCAMvSC算法
输入:多视图数据集。
输出:分配给k个集群。
① 数据应用核典型相关分析初始化;
② 在核典型相关空间上应用协同训练;
③ 初始化:L(v);

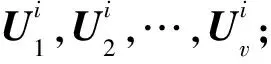
⑦ 构成矩阵V;
⑧ 如果V的第j行通过k均值算法可以分配给簇c,就将j分配给簇c;
⑨ 结束。
3 实验步骤与结果分析
3.1 核函数
3.1.1 核函数定义
核函数定义:如果函数f(x)可以看作是个无穷向量,那么对于具有两个自变量的函数K(x,y),就可以把它看作一个无限矩阵。如果对任意的函数
f都满足K(x,y)=K(y,x)且
ʃʃf(x)K(x,y)f(y)dxdy≥0,
那么K(x,y)是正定的对称矩阵,这时的K(x,y)就是一个核函数。与特征向量和矩阵特征值类似,这时存在一个特征值λ和特征函数Ψ(x),使得ʃK(x,y)Ψ(x)dx=λΨ(y)。对于两个不同特征值λ1,λ2对应的特征函数Ψ1(x),Ψ2(x),证明如下
ʃλ1(x,y)Ψ1(x)Ψ2(x)dx=
ʃʃK(y,x)Ψ1(y)dyΨ2(x)dx=
ʃʃK(x,y)Ψ2(x)dxΨ1(y)dy=
ʃλ2Ψ2(y)Ψ1(y)dy=
ʃλ2Ψ2(x)Ψ1(x)dx,
<Ψ1,Ψ2>=ʃΨ1(x)Ψ2(x)dx=0,又因为特征函数是正交的,所以Ψ表示函数本身。
3.1.2 核函数的种类
核函数的种类很多,在这里只简单的介绍实验中所用到的9种核函数。
1)线性核(Linear Kernel)是最简单的核函数,数学公式:k(x,y)=xty。
2)多项式核(Polynomial Kernel)是一种非标准核函数,数学公式:k(x,y)=(axty+c)d。
3)高斯核(Gaussian Kerne)函数对噪音有着较好的抗干扰能力,数学公式:

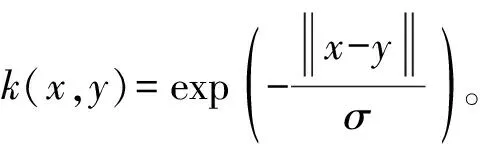

7)多元二次核(Multiquadric Kernel)是非正定核函数,数学公式:k(x,y)=(||x-y||2+c2)0.5。
8)对数核(Log Kernel)一般用在图像分割上,数学公式:k(x,y)=-log(1+||x-y||d)。

3.2 数据集的描述
为了评估KCCAMvSC算法模型,选用不同性质的数据集来分别对模型进行实验和对比分析。这些数据集包括文本数据集和图像数据集,分别是手写体数字(HW)数据集、4所大学的网页(WebKB)数据集、剑桥微软研究院(MSRCV1)数据集、英国广播体育专题(BBCSport)数据集、3个在线新闻文章构成(3-Sources)数据集、人脸数据库(ORL)数据集。如表1所示。
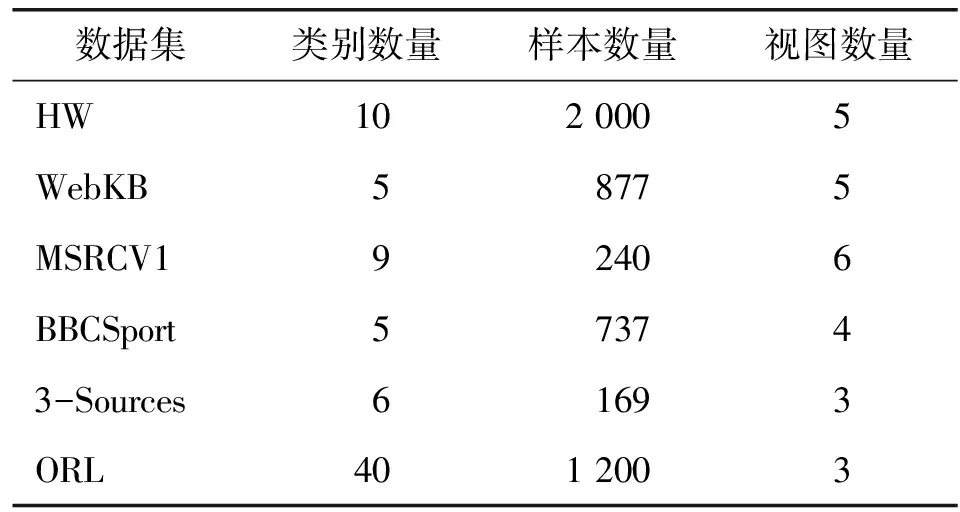
表1 实验数据集的描述
3.3 实验设置
为了验证KCCAMvSC模型的有效性,首先给出不同算法在不同多视图数据集上的聚类评估值,对比研究了多个代表性的经典算法,即:K-Means、K-Means级联(CK)、多视图K-Means(MK)、单视图谱聚类(SC)、SC级联(CSC)、多视图谱聚类(MSC)。定义了10个不同的参数,每个参数运行3次,选择参数最优的20次结果的平均值作为最终值。从3种不同的数据预处理方法对数据进行预处理,采用0~100之间的参数对数据进行降维,接着选取出效果最佳的维数,然后取20次运行结果的平均值作为最终的算法效果评估值,最后和其他算法的最高值做对比。统计了各种算法在6个数据集上的归一化互信息(NMI),NMI给出了所获得的聚类与聚类熵归一化的真实聚类之间的相互信息。NMI范围在0~1之间,如果得到的值越高,就表示与真实聚类更接近。同时还采用了兰德指数(RI)、纯度(P)、精度(ACC)值作为聚类质量评估度量,取值都介于0和1之间,值越高聚类精度越好。聚类评估值对比表2~5分别表示每个聚类算法在6个数据集上的聚类评价指标的值。
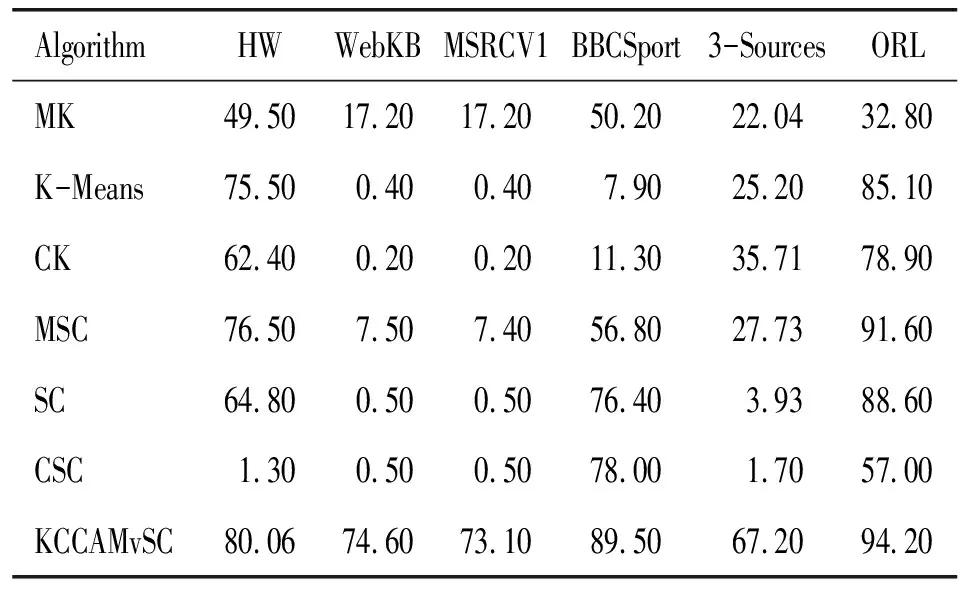
表2 不同聚类算法在多视图数据集上的NMI值(Rate/%)

表3 不同聚类算法在多视图数据集上的RI值(Rate/%)
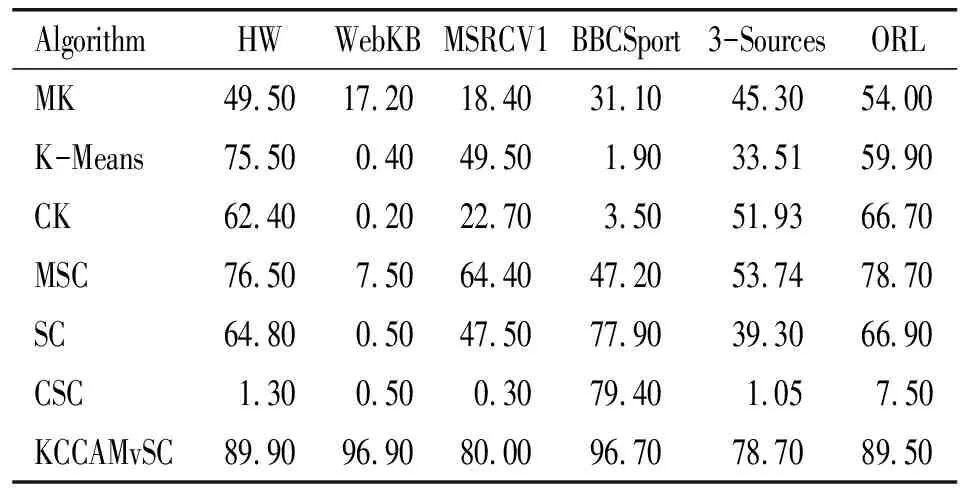
表4 不同聚类算法在多视图数据集上的P值(Rate/%)
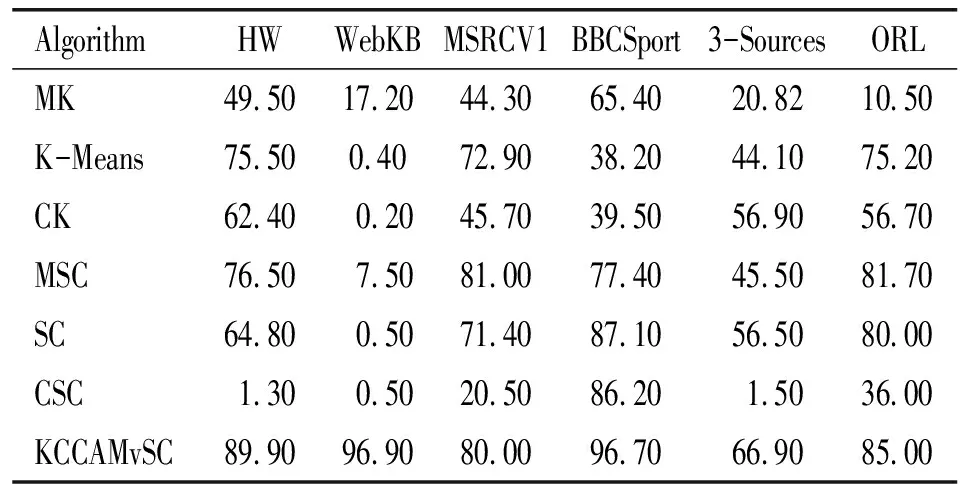
表5 不同聚类算法在多视图数据集上的ACC值(Rate/%)
3.4 实验结果分析
表2~5分别表示了不同算法在不同数据集上的聚类评价指标值,实验选用KCCAMvSC的20次运行结果的平均值作为KCCAMvSC最终的有效评估值,与K-Means、CK、MK、SC、CSC、MSC的20次运行结果的最大值作对比。
由表2~5可以看出:KCCAMvSC相比MK、MSC,在HW数据集、WebKB数据集、MSRCV1数据集、BBCSport数据集、3-Sources数据集、ORL数据集上的性能都有所提高。具体来说,KCCAMvSC的NMI、P指标值在6个多视图数据集上都明显的超过了MK、MSC。RI、ACC指标值除了在MSRCV1数据集表现为次优以外,在其余5个数据集上也取得了最优。对于KCCAMvSC在MSRCV1数据集上表现次优,分析可能存在的原因,虽然已经对MSRCV1数据集的视图从多个方面描述,但是有可能因为视图之间的信息互补性相对较弱、各个视图在局部样本上对簇结构差异性的刻画能力不明显所导致。
4 结论
本文提出并讨论了KCCAMvSC算法模型。目的是寻求从多个表示中找到一致的解决方法,利用每个表示中的信息来提高经典聚类系统的性能。依次介绍了MK、MSC,给出了KCCAMvSC算法模型。实验不仅对比了3个算法在多视图数据集上的聚类效果,同时还对比了K-Means、CK、SC、CSC,实验数据充分证明了KCCAMvSC算法模型的优势。虽然KCCAMvSC算法模型的整体优势很明显,但是在MSRCV1数据集上的优势却很小,其中的缘由需要在以后的工作中更加深入研究和探讨。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
北京航空航天大学学报(2022年8期)2022-08-31
计算机研究与发展(2022年1期)2022-01-19
新城乡(2018年6期)2018-07-09
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
电脑知识与技术(2016年13期)2016-06-29
领导科学论坛(2016年9期)2016-06-05
文苑(2015年9期)2015-09-10
