
基于最近邻算法的短语结构语法关系判定方法*
2022-01-15 06:24朱瑞平
计算机与数字工程 2021年12期
杨 泉 朱瑞平
(北京师范大学汉语文化学院 北京 100875)
1 引言
汉语短语层级的相似度计算是自然语言处理中的重要基础性工作,其研究成果在机器翻译[1]、信息检索、情感分析等诸多领域都有实际应用。“N1+N2”结构是典型的汉语短语结构,也是自然语言处理中的高频语言现象,其内部语法关系较为复杂,因此成为计算机自动准确判定的重点和难点问题。本文以此结构为例探讨汉语短语结构的语法关系自动判定方法。
k最近邻(k-nearest neighbor,KNN)算法是机器学习中经典的分类方法之一[2],它具有较高的有效性和数据训练时间复杂度低等特点,已经被成功地应用到很多实际分类问题中,包括与中文文本相关的分类问题[3]。该方法基于由N个已经标注分类样本组成的训练样本集T={xi,i=1,…,N}。针对测试样本xt,通过计算其与样本集中样本间的距离进行分类。因此根据分类问题的属性,提取个体分类特征,依据分类特征建立个体间的距离,并在此基础上建立训练集是KNN分类算法的基本前提。
综上,本文拟在词语相似度计算方法的基础上,从语言学角度研究词义相似度与短语结构语法关系之间的关系,从而建立基于短语结构相似度的短语结构之间的距离关系。为此建立了标注词语语义类别和短语结构语法关系的样本集,最终给出基于k最近邻算法的短语结构判定方法。我们选用基于《同义词词林》的词义相似度计算方法,目的是充分利用《同义词词林》的树状结构,提高计算测试样本与训练样本之间距离的运行效率。
2 基于《同义词词林》的词义相似度的短语结构距离定义
语言学领域的很多专家学者都关注到了N1+N2结构中词语的语法语义关系,如文献[4~5]探讨了N1+N2结构中两个名词的语义类型和语法功能特点。汉语是典型的孤立型语言,不是通过词的形态变化来表达语法作用的。同一个结构实例化为不同的词语时,可能产生不同的语法、语义关系。在N1+N2结构两个词的词性已经确定的情况下,N1和N2各自的语义类别决定了其所构成短语的语法关系,因此两个短语中构成词的语义类别越接近两个短语的语法关系就越相似。这从语言学原理上肯定了使用构成短语的词语间的语义相似度来定义短语结构相似度的合理性。
在自然语言处理领域,词义相似度是对给定的两个词之间语义相似或相关程度的衡量,通常用[0~1]之间的数值来表示。词义相似度的值越大,说明两个词的距离越近,相关性越大,紧密程度也越高。目前汉语中词义相似度计算方法主要分为两大类[6]:基于语料库和基于知识本体的方法。第一类基于语料库的方法能够较为客观地反映真实语言面貌,如文献[7]运用词向量的方法计算词义相似度,但是很多研究结果表明基于语料库的方法对语料的依赖性较大,需要在大规模精确标注语料的基础上进行,然而语料的规模、内容、范围以及标注的标准和规范难以统一,而且可解释性较差[8];第二类基于知识本体的方法在这些方面就显示出了其优越性,越来越多的专家学者都在这方面进行了有效尝试。《同义词词林》是重要的汉语知识本体,它是梅家驹等编撰的可计算用汉语语义词典,后经哈工大研究人员扩展为《哈工大同义词词林扩展版》(下文简称《词林》),目前共收录词语77456条,使用8位编码来表示词语义项,如表1所示。展示了《词林》编码体系。

表1 《词林》语义编码表
前7位编码可以唯一代表一个原子词群,第8位编码表示原子词群中词语间的关系,“=、#、@”分别表示“同义、相关、唯一”三种关系。
近年来基于《词林》的词义相似度算法层出不穷,比如文献[9]、[10]、[11]、[12]、[13]分别提出了基于《词林》结点路径、深度或分支结点数的词义相似度计算方法。文献[13]中计算词语相似度的具体公式如下:
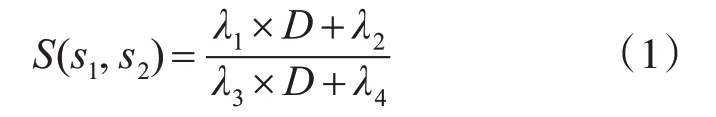
上式(1)中,S(s1,s2)代表两个词的语义s1和s2的相似度,D为最近父结点深度,系数为λ1=0.9811,λ2=0.4977,λ3=0.1244,λ4=4.4612。
在计算语言学领域中,很多研究在分析语法语义关系的基础上,提出了识别N1与N2结构的规则[14~16]。以此从实证研究的角度证明了语法关系相同的结构其语义类别也往往具有较高的相似性。
人工智能领域有许多处理语言学问题的成功方法,本文研究的短语结构判定问题属于人工智能领域中的分类问题。在标准训练集的基础上可以使用k最近邻分类算法进行计算。即计算N1+N2测试集中的语料与训练集中全部语料之间的距离,然后判定该短语结构关系属于哪一类语法关系。
为了使用k最近邻算法判定“N1+N2”的语法关系,我们首先需要定义两个短语结构之间的距离。根据上文的分析,设有两个待比较的“N1+N2”短语结构,分别表示为“N1c+N2c”和“N1x+N2x”,设词语N1c和N1x之间的语义相似度为S1,N2c和N2x之间的语义相似度为S2,则定义这两个结构之间的相似度为

其中0≤μ1≤1,0≤μ2≤1,且μ1+μ2=1。
因此可以定义短语结构间的距离为

根据该定义,当S1和S2均取最大值1时,S取最大值1,此时其距离取最小值0。当S1和S2均取最小值0时,短语结构中的词在语义上无相关性,此时结构间的距离定为无穷大。
计算两个名词间的语义相似度,经过多方比较,本文采用式(1)的语义相似度的计算方法。该方法简洁易用,效果也较为理想,此外,采用基于《词林》的语义相似度计算方法,可以根据《词林》编码已有的树形结构,设计计算测试集短语与训练集短语距离的快速搜索算法。
3 基于语料库的N1+N2结构标准样本集
3.1 收集整理语料
首先在北京语言大学BCC语料库中提取出N1+N2结构语料共17108条,这些语料来自“人民日报、人民日报、文学、科技文献”四个子语料库,去掉各类不合格语料,剩下合格语料共10398条。
3.2 分析标注语料
N1+N2结构实例化后实际存在四种语法关系:“定中、并列、复指、主谓”关系(下文用“dzp、blp、fzp、zwp”表示),据此又建成四种语法关系子库。合格语料中还存在大量重复语料,因此又对语料进行了去重处理,剩下不重复合格语料共5098条,详见表2。

表2 N1+N2结构去重后各关系数量及占比
下面为N1和N2标注语义信息,选择《词林》语义编码体系作为语义标注体系,先用计算机自动标注,再进行人工校对。
3.3 构建训练集与测试集
本文着重研究语义类别与语法关系之间的规律,因此在四种语法关系子库的基础上对训练集与测试集按8∶2的比例进行分配,具体数量及占比见表3。
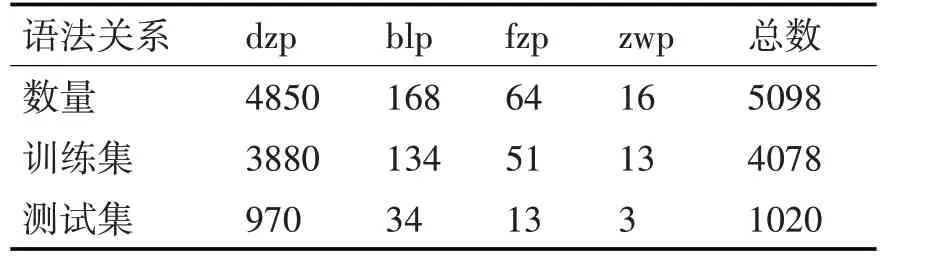
表3 训练集与测试集各关系统计表
然后将每种语法关系子库的训练集和测试集分别汇总,形成最终不重复合格语料的训练集和测试集,并将训练集语料作为标准样本集。
4 基于词义相似度和最近邻算法的N1+N2结构语法关系判定方法
首先需要作一些形式化处理。
1)将训练集中的语料设为N1x、N2x;将测试集中待测试的语料设为N1c、N2c。
2)四种语法关系中“N1+N2”结构的名词具体表示为并列关系两个名词表示为N1b、N2b;复指关系两个名词表示为N1f、N2f;定中关系两个名词表示为N1d、N2d;主谓关系两个名词表示为N1z、N2z。
K最近邻结构判定算法:
1)输入:测试结构“N1c+N2c”;
2)计算:比较测试结构与训练集中所有结构“N1x+N2x”间k个最近的距离;
3)判定:k个距离最近的结构中,所属类别最多的一类作为测试结构所属的类别。
我们使用kd树算法来提高计算测试实例和训练集中实例距离的计算效率。该方法包括三步:第一步是建树,第二部是搜索最近邻,最后一步是预测。其中需要根据训练集的特点来构造kd树,其它两步都是通用方法。kd树是一种二叉树,用于存储高维空间的实例点,以便对其进行快速检索的树形结构。训练集中的实例都是“N1x+N2x”的短语结构,基于《词林》的相似度计算方法中,N1x和N2x都有唯一的《词林》编码,因此我们可以直接将这两个词的《词林》编码构造为一个新的编码,这就完成了将短语结构到高维空间的映射,从而可以方便进行后续kd树的构成。从语言学上,该分类方法的基本原理如下。
1)N1、N2语义编码都相同
如果我们在测试集中需要测试的语料为N1c+N2c,在训练集中存在N1c和N2c语义编码都相同的短语。只需要根据训练集标注的结果去标注N1c+N2c的语法关系就可以了。因为我们根据语义编码计算相似度,而《词林》体系中存在语义编码相同,词语不同的情况,如当测试语料为“新郎新妇”时,在训练集中存在“新郎新娘”,是并列关系,只需要根据训练集的标注结果判定即可。
2)N1语义编码相同、N2语义编码不同
如果我们在测试集中需要测试的语料为N1c+N2c,在训练集中存在与N1c语义编码相同,N2c语义编码不同的短语。比如当N1实例化为“工资”时,在训练集中有“工资待遇”,是并列关系,记为“N1b+N2b”;还有“工资增幅”,是定中关系,记为“N1d+N2d”,这些短语的N1语义编码都相同。如果需要判定测试集中“工资+N2c”的语法关系,比如“工资基金”,我们就需要计算N2c与N2b的语义相似度以及N2c与N2d的语义相似度,然后比较几个词对相似度的大小,以N2c与N2x最大相似度短语的语法关系作为判定结果。
3)N2语义编码相同、N1语义编码不同
如果我们在测试集中需要测试的语料为N1c+N2c,在训练集中存在与N2c语义编码相同,N1c语义编码不同的短语。如当N2实例化为“护士”时,在训练集中有“大夫护士”,是并列关系,记为“N1b+N2b”;还有“国际护士”,是定中关系,记为“N1d+N2d”,这些短语的N2语义编码都相同。如果需要判定测试集中“N1c+护士”的语法关系,比如“病区护士”,我们就需要计算N1c与N1b的语义相似度以及N1c与N1d的语义相似度,然后比较两个相似度的大小,以最大相似度结果的语法关系作为判定结果。
4)N1、N2语义编码都不同
如果我们在测试集中需要测试的语料为N1c+N2c,在训练集不存在与N1c、N2c语义编码都相同的短语。比如测试集中有“杨树刺槐”这个短语,其中的两个名词的语义编码在训练集中都没有出现,这时就需要计算“杨树”与训练集中N1列中哪个名词的语义相似度最大,再计算“刺槐”与训练集中N2列中哪个名词的语义相似度最大,然后结合两个相似度计算结构的相似度。再求出结构的距离,作为判定依据。
5 实验结果与分析
按照上述方法,我们对测试集中的语料进行判断。在距离计算中取μ1=μ2=0.5,在k最近邻算法中,经过测试发现取k=1,即能取得较好的结果,因此以下结果中都取k=1,所以实际上用的是最近邻算法。
语料计算结果见表4所示。
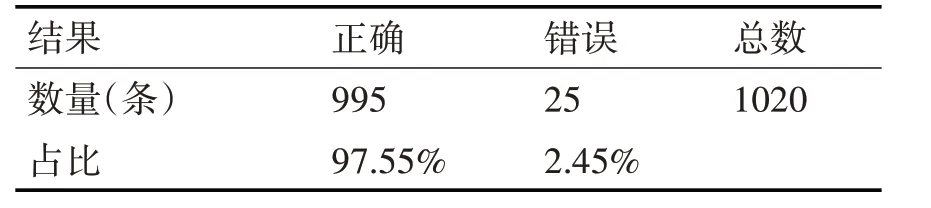
表4 语料测试结果
计算机自动标注的结果与人工结果比较后,四种语法关系计算结果的精确率和召回率见表5所示。

表5 四种语法关系判定结果的精确率和召回率
对本文实验进行分析后,可以得出以下一些结论:
1)本文计算结果证明了本文设计算法的有效性,同时也证明了“N1+N2”结构中词的语义类别对语法关系确实有决定性的作用,因此可以根据“N1+N2”结构中两个名词的语义类别去判定短语的语法关系,这个规律不仅在“N1+N2”结构中存在,在其他类型的汉语短语结构中也同样存在。
2)在本文的计算过程中,我们对不同“N1+N2”结构短语分别计算N1的相似度及N2的相似度,所得结果已经较为理想,但仍有个别例外现象,究其原因主要是因为语料库中四种语法关系的语料不均衡,定中关系语料过多,而其他关系特别是主谓关系语料过少。后面我们可再结合“N1+N2”结构中两个名词的相似度进行计算,并进一步补充完善非定中关系语料,以期得到更为客观、准确的语法关系判定结果。
3)汉语中含有两个词的短语结构我们称为二元短语结构,用最近邻算法在效果和运算量上是最优的;含有三个词的三元短语结构或更多元的短语结构可以考虑采用2、3近邻或更多近邻的算法。近邻算法的思想很适合计算语言学运用语料库处理语言问题,在处理过程中简洁易用,体现了人工智能领域目前“弱标注、小数据、大任务”的发展趋势。
6 结语
综上所述,短语由词构成,又是构成句子的基本单位,是词与句子之间的过渡单位,因此短语的语法关系和语义属性是由其所构成的词决定的;而短语本身的语法关系和语义属性又对其所构成的句子起到了决定性作用。词层级的相似度计算结果是短语层级的基础;而短语层级的相似度计算结果是句子层级的基础,如果将短语的关系进行适当建模,并结合相应的机器学习算法,一定会大大提升利用人工智能方法处理自然语言的效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
厦门大学学报(自然科学版)(2021年4期)2021-06-22
电脑知识与技术(2019年23期)2019-11-03
长江学术(2016年4期)2016-03-11
海峡姐妹(2016年2期)2016-02-27
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
外语教学理论与实践(2014年2期)2014-06-21
教学与管理(理论版)(2009年9期)2009-11-04
