
手写汉字评价方法研究进展
2022-01-25 18:54李成城
计算机工程与应用 2022年2期
肖 雪,李成城
内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
互联网的不断发展、创新以及与教学领域的融合,给教学设备带来许多新的机遇。如今人们已经积累了丰富的计算机辅助教学经验,教学体系也在逐步完善。尽管计算机辅助教学设备发展得非常迅速,但也存在许多问题[1],如计算机辅助手写汉字的书写质量评价软件不充足、资源共享度不高,缺乏书写质量评价的相关研究等。
目前“提笔忘字”的现象普遍存在,这将成为传统文化丢失的先兆。为了提高书写水平,教育部对小学生的书写要求下发相关文件[2],而手写汉字的指导工作主要由教师完成,教师对学生的手写汉字进行评价时会存在以下两方面的缺点[3]:(1)评测专家具有极强的主观性。如教师对相同书写水平的手写汉字打分时,会受到经验、耐心等自身因素影响,导致分值出现不同程度的偏差。(2)教师不能及时对学生的手写汉字作品做出反馈。在实际生活中,受书法课程时间以及教师精力的限制,学生作品无法随时得到评价,容易产生书写错误的累积。而手写汉字书写质量评价的计算机辅助教学设备,可以克服传统手写汉字评价中存在不公正和反馈不及时等问题,提高教学质量。教师可以把更多精力和时间放在教学与辅导阶段,极大提高了工作效率。
在教学领域,一个高效的计算机辅助书写质量评价设备具有以下三种特点:(1)改变传统手写汉字评价方法。(2)改正人工评价时容易出现主观性和精力有限等问题。(3)找出手写汉字中存在的不规范问题,有助于学生书写规范汉字,实现及时评价[3]。此外,手写汉字评价技术在反馈形式与反馈内容方面已成为数据到文本生成、自动问答、字形匹配以及图形辅助等技术发展的支持或潜在支持部分。如手写汉字与模板汉字产生的数据差可实现数据型文本的自动生成;学生对手写汉字的评价提出问题,利用自动问答解决问题;通过手写汉字评价产生的笔画数据,利用字形匹配以及图形辅助等内容,可以使反馈形式更加生动、形象有较好的用户体验,有助于学生充分理解评价含义。由此可见,手写汉字评价具有重要的研究意义与开发价值。
初期手写汉字的特征提取主要在汉字结构方面[4],这类方法只能解决手写汉字的整体规范性问题。为了解决以上问题,研究者开始尝试提取手写汉字的细节特征进行书写质量评价,实验证明此想法在书写质量评价的准确性方面确实有了很大的提升,但手写汉字的特征提取始终依赖专家的先验知识获取,既费时又耗力。随着深度学习的发展,研究者正在试图利用深度学习的方法解决书写质量评价不全面的问题,它不但能够提取一般特征,而且还能获取到一些人工无法获取的隐藏特征,有利于手写汉字的评价。但基于深度学习的手写汉字评价方法目前处于刚刚起步状态,还需要研究者不断深入的钻研。
1 文献统计及相关概念
1.1 文献统计
文中对手写汉字评价的参考文献进行收集整理,以书写评判(handwriting evaluation)、水平评测(level assessment)、书写质量(handwriting quality)、计算机评价(computer evaluation)等作为关键词,输入Google scholar、ACM digital library、IEEE xplore digital library以及Springer link等途径查找,通过阅读文献标题以及摘要等涵盖论文重要信息部分对论文进行筛选,并对收集到53篇手写汉字评价的文献进行统计分析,得到图1的结果。
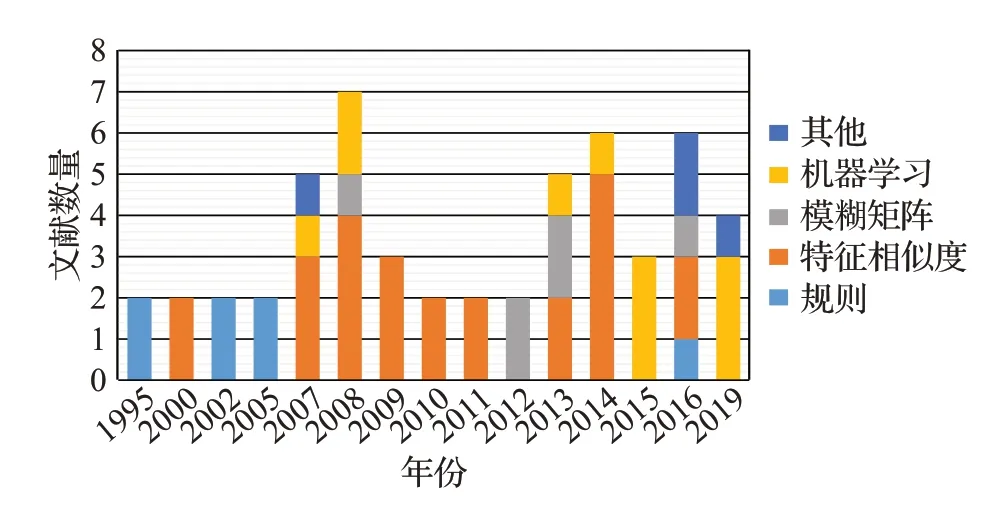
图1 文献分布情况Fig.1 Literature distribution
由图1可知,超过70%的文章发表于2009年之后,从2011年期间起,发表关于手写汉字评价文章的数量正在逐步增加,占总数量50%左右。最初利用基于规则的方法对手写汉字进行评价,随着机器学习技术的不断发展以及手写汉字可提取的特征越多,利用机器学习以及特征相似度的手写汉字评价方法在近几年呈现上升趋势。
根据目前统计的文章,手写汉字评价相关的综述性文章较少。仅有安维华[5]总结了计算机辅助汉字教学的相关研究,其中包括数字化演示、书写规范性评测以及书写水平评测等任务,并且着重介绍书写规范性评测中的即时评价和事后评价,未涉及到评价方法原理的介绍,也未对反馈形式做出具体分析。
1.2 书写质量评价相关概念和一般框架
手写汉字的书写质量评价不仅包括书写规范性评价,还包括书写美观、笔画质量、结构、章法等多方面的评价[3]。传统手写汉字的书写质量评价是指,教师对学生书写作品做出评分并对书写细节提出改正建议,通常评价的准确性容易受教师主观性的影响。计算机辅助手写汉字的书写质量评价是指,利用计算机对各类手写汉字进行评分及评价。相对而言,传统手写汉字评价与计算机辅助的手写汉字评价,二者具有极大的共通性。传统手写汉字评价通过教师的经验以及观察手写汉字整体结构、笔画等细节与模板汉字对应部分进行对比给出评价。计算机辅助手写汉字的书写质量评价,通过计算机提取出手写汉字的特征与模板汉字的特征进行比对,相似度越高则手写汉字的书写质量水平越高。书写质量评价的一般框架如图2所示。
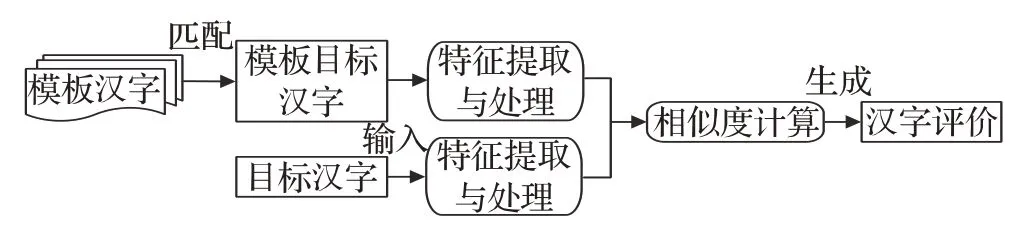
图2 书写质量评价一般框架Fig.2 General framework for handwriting quality
根据计算机评价手写汉字的时间不同,可将手写汉字的书写质量评价分为即时评价和事后评价两种(表1给出了两种评价的对比)。

表1 评价对比Table 1 Evaluation and comparison
1.2.1 即时评价
即时评价是指用户每完成汉字的一个笔画,系统就立即与模板汉字的相应笔画进行相似度计算,评判笔画的正确性(形状正确性与位置正确性),并提出修改意见,为汉字的规范性奠定基础。及时发现手写汉字的错误并且给予反馈是非常重要的。有些教学系统根据即时评价获得手写汉字的笔画、笔序、部件相对位置等基本信息后,用于检测书写错误并评估书写质量[6-7]。也有一些教学系统对手写汉字信息进行归纳,将手写汉字以动画等另一种形式展示指导,加深学生的记忆[8-9]。
在即时评价中信息的双向展示非常重要[10]。学者进行实践练习的同时及时得到反馈,是加深印象的关键。然而,如何全面地发现手写汉字问题,并且突出显著错误的反馈也是研究者致力解决的问题。
为了解决输入字符与模板字符进行匹配时,因汉字结构复杂和书写风格差异较大等原因导致不能准确找到笔迹错误位置的问题。胡智慧等人[11]设计出一套实时评测与反馈的汉字书写质量系统,该系统通过属性关系图实现即时检测笔画信息,对笔画与笔画之间的关系(相邻、相交、相接)、笔画顺序以及笔画类型(横、竖、撇等)及时作出反馈评价,并利用剪枝策略提高评测速率。但这套系统仅对以笔画为基础的汉字进行匹配评价,忽略了手写汉字结构因素(对称性、匀称性等)的影响。目前存在大量即时评价的书写质量评价系统,它们主要关注笔画和笔顺的特征,忽略了字体结构对书写质量的影响,而笔画、笔顺等特征只能证明此手写汉字是否可识别,手写汉字结构的判断却是书写质量的一种衡量标准(可以评价手写汉字)[12]。庄崇彪等人[13]根据计算机可识别出手写汉字常见的十一种错误,引入单笔画框(局部特征)以及多笔画框(全局特征)的概念,制定出笔画、笔画间特征以及特征分类的规则,该算法可以对笔势、多笔画等特征进行正误和工整评判。但笔画起始点位置工整性的判断,并不能代表笔段是否书写工整。现实生活中,初学者及一些具有独特书写风格的学者并不能按照标准笔段进行书写,所以该算法只能进行初步的工整性评价,并且识别手写汉字错误的数量由制定的规则决定。
即时评价主要关注手写汉字的局部特征,能够及时发现手写汉字的首发错误并作出反馈,训练书写者对汉字笔画等基础结构的掌握。但即时评价会频繁打断书写者的学习过程,与书写者的交互形式不是很友好,影响其对整体汉字的认识。
1.2.2 事后评价
事后评价是指对书写完成的汉字一次性指出书写质量中存在的问题并给出反馈意见。事后评价的主要技术是特征比对[14-15]与反馈指导[16]。特征匹配是指目标图像或特征在数据库中利用相似性搜索匹配结果。反馈指导是指根据匹配结果给出反馈意见(笔画数目是否正确、笔画之间的比例等关系)。事后评价的方法主要关注手写汉字的全局特征,有利于书写者对整体汉字的认识,却存在书写错误积累(初学者常见错误),无法及时提醒书写者首发错误的问题,所以事后评价比较适合有一定基础的书写者。
事后评价的一般步骤为:(1)提取手写汉字的特征,特征包括部件(笔画、关键点等)、整体(骨架、章法布局等);(2)特征匹配;(3)根据匹配相似度结果给出规范性指导。也可将步骤(1)和步骤(2)在图像处理中一起实现。其中闫文耀等人[17]针对现实生活中手写汉字存在连笔、个性化书写风格等问题导致手写汉字分割困难,提出基于图像纹理的书写质量评价方法。该方法通过Gabor对全局特征进行提取,利用支持向量机的统计学习方法对书写质量进行评价。在CHAED数据集下,手写汉字的书写质量评价准确率达到了95%。其优点是放弃了分割的过程,避免由分割失误对评价结果产生误差。但是此评价结果只有优秀和一般两种,不能具体指出手写汉字特征错误位置及原因。
1.3 评价指标
手写汉字的评价指标主要由反馈指导的形式决定。目前关于手写汉字的反馈指导形式主要有:文字评价、评分以及图形辅助三种。在书写质量评价的一般框架下,不同手写汉字评价方法需要依据手写汉字的字体、评价结果以及数据规模大小的不同进行改进,为了验证手写汉字评价效果,可参考以下评价指标。
1.3.1 人工评价
当反馈指导的形式为文字评价时,好的文字评价指标应该满足:(1)准确性。从评价文本的内容来看,评价文本能正确体现手写汉字的缺点以及对缺点的分析。(2)流畅性。由于评价文本是基于自然语言进行描述,因此文本需要语法正确并且流畅,方便书写者阅读理解。(3)相似性。生成的评价文本与参考评价文本之间的相似度越高表明模型的训练效果越好。
人工评价时,将得分项设为1~5(1为最低等级,5为最高等级),研究者会邀请有一定经验的教师阅读评价文本进行打分。不同教师存在个性、认真态度、评价经验等差异性导致评分存在偏差,可通过金字塔方法[18]解决以上问题。虽然人工评价的成本较高,但此评估方法依旧是当前研究工作中重要的一部分。
1.3.2 自动评价
(1)BLEU
BLEU(bilingual evaluation understudy)指标用于比较生成文本与参考文本之间n元词组的重合程度,其中共有四元词组,BLEU-1代表一元词组,以此类推。BLEU指标的取值越高(n元词组重合程度越高),生成文本质量越高,其公式如下:
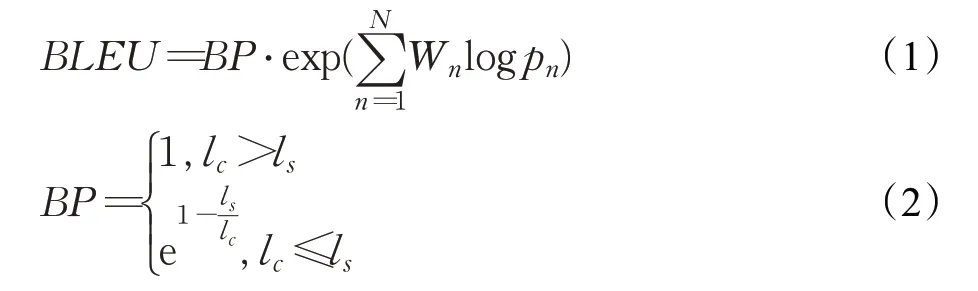
其中,Wn表示权重,pn表示精度,BP是惩罚因子。
(2)METEOR
METEOR(metric for evaluation of translation with explicit ordering)指标在考虑词性的同时还扩充了同义词集。在评价生成文本流畅度时应用了chunk,每个chunk的平均长度越长,生成文本与参考文本的语序越一致。其公式如下:
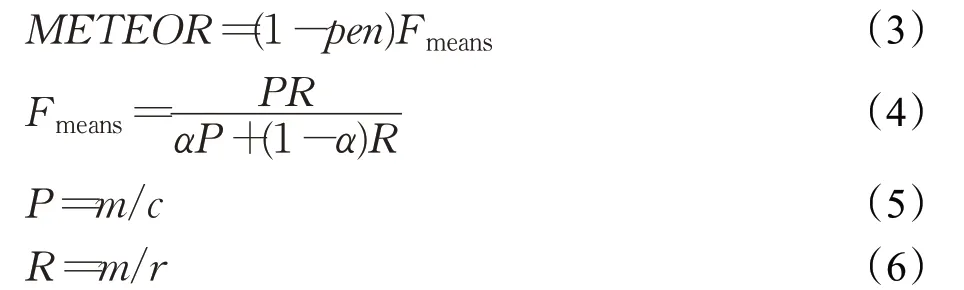
其中,c表示生成文本的长度,r表示参考文本的长度,m为参考文本中能够被匹配的一元组数量,pen为惩罚因子(惩罚生成文本与参考文本词序差距过大),其计算公式为:

其中,#chunk是指chunk的数量,chunk是指既在输出文本中相邻又在真实文本中相邻的一元组聚集而成的单位。
(3)ROUGE
ROUGE(recall-oriented understudy for gisting evaluation)指标可以分为ROUGE-N和ROUGE-L。其中,ROUGE-N主要用于计算两个句子之间n元词组的重合率,ROUGE-L计算最长公共子序列的重合率。其公式为:

其中,Countmatch(gramn)表示生成文本与参考文本中同时出现n-gram的个数,count(x)表示x出现的次数,{RefSummaries}是参考文本。
ROUGE-L的计算公式如下:
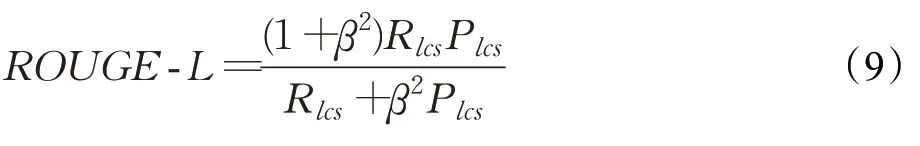

其中,X表示输出文本,Y表示真实文本,m表示生成文本的长度,n表示输出文本的长度。
(4)CIDER
CIDER(consensus-based image description evaluation)指标通过度量生成文本与参考文本之间的相似性来判定质量。利用TF-IDF的余弦夹角对每个参考句子与生成句子之间的相似度进行度量。其公式如下所示:
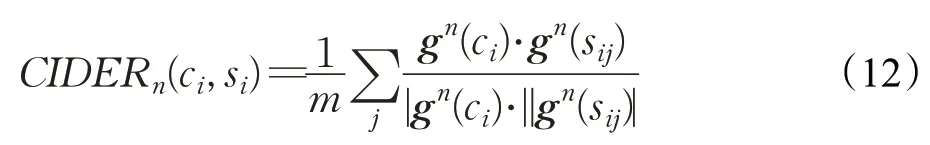
其中,gn(ci)和gn(sij)是TF-IDF向量,ci是生成文本的句子,参考文本句子集合si={si1,si2,…,sim},当使用了长度不同的n元词组时,存在以下公式:

2 手写汉字评价方法
为了实现手写汉字的准确评价,研究人员不断利用各种方法实现手写汉字评价,其正在成为不需要教师参与就可以自动生成评价的可行技术。现有的技术可分为以下几种方法:基于规则、基于特征相似度计算、基于模糊矩阵以及基于机器学习。这些方法存在各自的优缺点,具体情况如表2所示。

表2 手写汉字评价方法Table 2 Classification of handwritten Chinese character evaluation methods
2.1 基于规则的方法
基于规则的方法是根据理论描述成分与成分之间的结构关系和意义关系,并应用其中的关系对事物进行分析。将基于规则的方法与手写汉字结合,领域专家从各自不同的角度出发,制定不同的规则对手写汉字进行评测[19]。此方法遵循以下步骤:首先从手写汉字中找到可以描述手写汉字特征的表示,然后通过决策树等不同的算法对特征表示进行判断,进而得到手写汉字的书写质量评价。这是一种最基础的手写汉字评价方法,而对每种笔画制定规则限制了它在大规模数据下的评价任务。
庄崇彪等人[13]利用单笔画框、多笔画框以及笔段八方向编码对笔画特征以及笔画间特征制定了规范性规则,通过阈值对特征的限制实现等级分类。实验结果表明此方法只对规范的汉字特征提取效果较好,并且书写错误类型判断是否全面由规则决定,这限制了评价的准确性与多样性。
特征描述的贴切程度对书写质量评价的准确性起到决定作用,特征描述越详细评价效果越好。韩睿方等人[20]为了提高识别手写汉字中错误的效率,利用决策树实现手写汉字笔画关键点之间的距离差以及笔段的水平倾角、弯曲程度等细节的不同等级分类。该方法通过收集50个不同学历的人书写的手写汉字笔画,每个笔画采集10~20次,在此数据集上进行测评,结果显示宏观特征的评判效果达到了100%的召回率,微观特征评判效果的准确率与召回率都在80%以上。Tan[21]提出了低整数编码对原始笔画特征和字符特征进行表示,可识别出手写汉字笔画类型、顺序等问题。与韩睿方提出的方法相比,此方法对笔画等特征的评判要求较低,并且缺少汉字结构的评价,更适合初学者练习手写汉字。
这种基于规则的方法是手写汉字评价最初成功的方法,为接下来的研究奠定了坚实的基础。此方法虽然简单但存在局限性:第一,需要对数据库里每一个手写汉字(笔画)制定规则。若出现一个从未出现的汉字(笔画),需要添加新的规则,并且新添加的规则容易与前面制定的规则发生冲突。手写汉字评价广泛地应用于中小学等不同人群,其需要的数据不同,并且不断要求有新字出现,而字库却相对固定,所以基于规则的方法无法满足所有用户的需求。第二,规则的覆盖性较差。有些手写汉字的笔画、结构书写复杂,手写汉字的规则很难总结全面,这也是这类方法进行书写质量评价结果不理想的原因。
2.2 基于特征相似度计算的方法
这类方法主要受到文字识别研究的启发[22]。在评价手写汉字时,手写汉字与模板汉字之间的差异大小,由特征相似度决定。该方法主要执行以下步骤:(1)提取手写汉字的特征。(2)与模板汉字特征进行相似度计算,以相似度高低作为评价书写质量的指标。
汉字大多结构复杂,在一定程度上限制了手写汉字进行相似度计算的速率,在保证特征信息完整的情况下,如何快速地进行相似度计算是提高书写质量评价效率的关键步骤。不同手写汉字特征,相似度计算的速率不同。在书法字检索中[23],利用骨架以及轮廓特征与数据库中的汉字进行特征相似度计算实现检索,骨架特征相比轮廓特征检索的时间减少了70%,提高了检索效率,实现在较大规模的汉字集中能够快速完成特征匹配问题。手写汉字特征包含能够描述手写汉字特性、结构、整体等的特征,进行评价时不仅需要考虑不同特征组合对评价的影响,还应该考虑特征自身特点对评价的影响。邓学雄等人[24]将局部和整体特征一起作为评价手写汉字的粒度,他们认为初学者进行临帖练习效果的好坏由临帖字体与原帖字体之间的相似度决定,并且利用PS工具提取手写汉字的笔画(局部特征),分别利用数学形态细化法以及图像投影的方法提取手写汉字的骨架特征和章法布局(整体特征),对手写汉字的局部特征以及整体特征与模板汉字相应部分进行欧氏距离计算,由相似度决定书写质量。但此方法的缺点是:(1)适用于初学者。毛笔字练习者初期临摹原贴中字的形态、结构等,后期应在初期的基础上不断创新,形成具有风格的字体。而汉字风格特征是一种附着在骨架特征上的轮廓形态特征[25],所以骨架相似度计算并不适合后期的学习。(2)不适用于数据量大的毛笔字临帖评价。此方法中笔画的提取是利用PS工具,对数据量较大的手写汉字进行评价时,提取笔画特征将花费大量时间。其中李牧[26]认为邓学雄的算法没有考虑到笔画简单的叠加进行相似度计算的结果将受到结构信息的影响。为了笔画特征不受旋转、形状区域平移的影响,李牧利用Hu矩进行笔画的相似度计算。而吴楚洲[27]认为李牧在进行骨架相似度计算时,很难取到不同骨架相同的对应点,所以将骨架进行米字格或九宫格的划分,与模板汉字相同区域内的骨架利用Hu矩进行相似度计算。该方法对书写等级较低的用户来说,临摹时容易出现手写汉字笔画与模板汉字对应笔画不在同一区域内的缺点。
在以上实验中模板汉字是事先提供的,不存在检索模板汉字的过程,也不需要考虑识别模板汉字的计算速率。而在现实生活中,进行考试等评估工作时不允许提供模板汉字,而平时的书写练习可以提供模板汉字,所以将书写质量评价系统设置为考试模式和练习模式才具有广泛的适用性。邵荣棠[28]对书法字检索效率低以及如何全面评价手写汉字问题进行解决,设计出练习模式的评价系统。解决方法主要包括四个步骤:首先,提出一种改进的书法字双层检索方法提高手写汉字识别的准确率,从数据库中快速查找出手写汉字的模板汉字。接着,针对检索出的模板汉字提出基于Z-S算法改进的单像素化处理算法,得到手写汉字整体骨架特征并且进行相似度计算。然后,对处理完成的书法字骨架进行九宫格的切分,利用Hu矩对切分出的骨架与模板汉字对应九宫格区域内的骨架进行相似度计算,得到笔段特征相似度值。最后,通过计算手写汉字到边框的距离与手写汉字的整体布局得到布局特征相似度。此方法有效利用手写汉字特征,实现在不影响特征信息的前提下对特征进行处理,加快特征相似度计算的效率,但忽略了笔画的对比信息,对手写汉字的评价信息未能达到具体精细并且其评价指标较少不能得到客观评价。
该方法虽然实现简单却有较多的缺点:(1)手写汉字的特征选择代表了当前手写汉字的特性,如果没有充分考虑手写汉字特征仅将几个特征进行计算,就会造成手写汉字评价不全面。这是此类方法结果不理想不可避免的原因。(2)手写汉字特征提取的效果影响评价结果。如手写汉字骨架提取效果影响全局特征,而骨架提取过程中毛刺的产生是不可避免的,所以将骨架的毛刺去除至光滑或只存在较少的毛刺对手写汉字的评价是至关重要的。
2.3 基于模糊矩阵的方法
手写汉字评价不能仅局限于与模板汉字对比,其书写风格也应该被接纳。由于每个人的书写习惯以及学习背景不同,所以手写汉字具有其自身的特点。而模糊矩阵恰好可以实现在不忽略每种手写汉字风格的基础上,进行相似度计算。这类方法将需要评判的特征构成模糊子集,选取适合当前特征的隶属度函数进行计算得到隶属度,由当前手写汉字隶属度与模板汉字隶属度之间的相似度决定手写汉字评价。特征的选择对手写汉字是否可以得到全面评价起到关键作用[29]。易于提取的手写汉字大小、重心等全局特征对手写汉字只起到了宏观范围的指导,全局特征与局部特征相结合才会较全面地评价手写汉字。
王耀等人[30]首先对52个大小写英文字母构建模式库,将模板字母的比例质量、位置质量、大小质量以及笔画质量的分析参数进行存储,然后针对不同特征选择不同的函数进行模糊化得到隶属度,最后与模板字母隶属度进行相似度计算,根据阈值的划分得到不同的评价。该方法对250个不同书写形状“A”的书写质量进行评价,实验结果表明其最高有效率达到97.8%。此方法仅适用于构成元素较少的书写体中,而汉字数目众多且结构复杂,对每个汉字建立模式库是不现实的,所以此方法不适用于手写汉字的书写质量评价中。樊亮[31-32]发现学者在触摸屏上进行书写时,因书写能力不同产生笔力均匀、笔力过轻和笔力过重三种现象,并且利用模糊数学实现笔力模糊评价。该方法首先根据书写特点建立8种关键点类型,然后通过高斯函数得到手写汉字每个笔画关键点的隶属度,与模板汉字关键点隶属度进行相似度计算,最后根据隶属度的贴近程度得到手写汉字的等级评价。与王耀提出的方法相比,该方法并没有存储所有模板汉字关键点的分析参数,而是将模板汉字与手写汉字一起利用算法得到隶属度,避免了存储笔画数据带来数据臃肿的缺点,具有更广泛的应用性。但笔力仅是书写质量中的一部分,还需要其他指标(大小、比例、倾斜等)的分析才可以得到较全面的手写汉字评价[33]。
书写质量区间是评价的最重要部分,以上方法都是研究者设置书写质量区间,区间范围的设置难免会存在主观性。而葛佳敏[34]首先利用模糊概率分布可以解决多值分析的问题,得到每个分类值的权重和每个特征的期望值。然后利用模糊综合评价将不同特征期望值在模型中计算,进而得到整个字的期望值。最后将期望值与得到的期望值范围进行比较,得出手写汉字的评价。其中,期望值范围指手写汉字整体期望值在某一值以上时书写质量较为规范。这种方法不再需要人为设置评价标准,也不需要大量的模板汉字作为参照对象,使评价结果具有公正客观性。
对于书写质量区间的设置,王求真等人[35]的算法具有较好的效率。其主要针对评价手写汉字时常见的几种问题:(1)字形结构复杂。(2)不同的书写风格。(3)笔画模糊不规范等等,提出模糊分析方法。该算法的基本思路为:首先根据联机设备获得手写汉字的局部特征(关键点)和全局特征(比例、大小和位置等)的信息,分别利用高斯法和统计实验进行模糊化。
手写汉字的特征向量模糊计算如以下公式所示[24]:
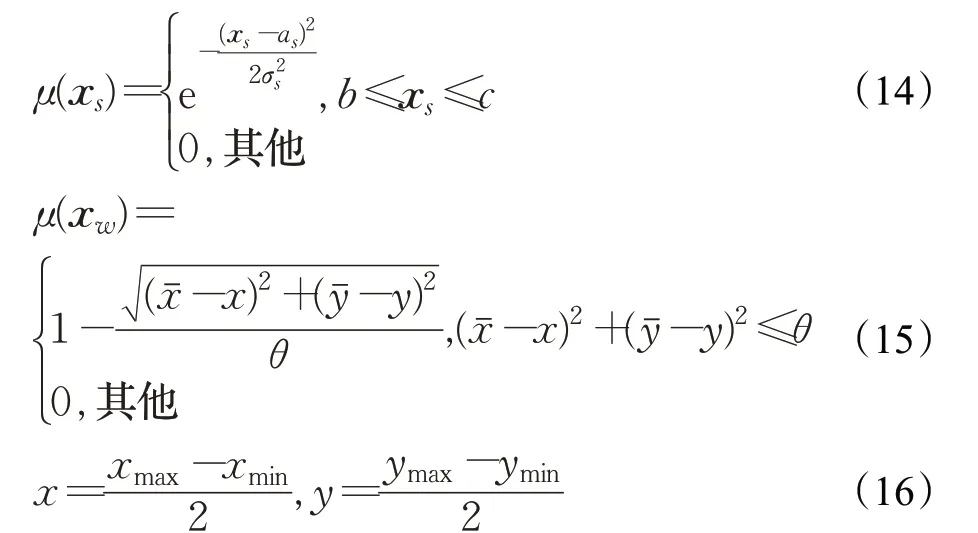
其中,式(14)中xs表示当前手写汉字的特征向量(除重心外),as为特征分布的中心,b和c分别为分布情况图范围的最大值与最小值。式(15)为手写汉字重心的模糊计算,其中xw表示当前手写汉字的重心特征向量,x与y分别为当前手写汉字重心的横坐标与纵坐标,xˉ与yˉ分别为模板汉字重心的横坐标与纵坐标。
最后与模板汉字相应的特征进行相似度计算,其中笔画特征相似度计算的公式为:
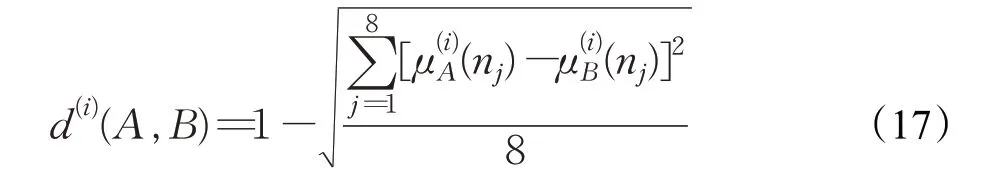
A、B分别代表手写汉字和模板汉字,表示手写汉字A中第i笔画的模糊度。
结构特征值进行相似度计算的公式为:
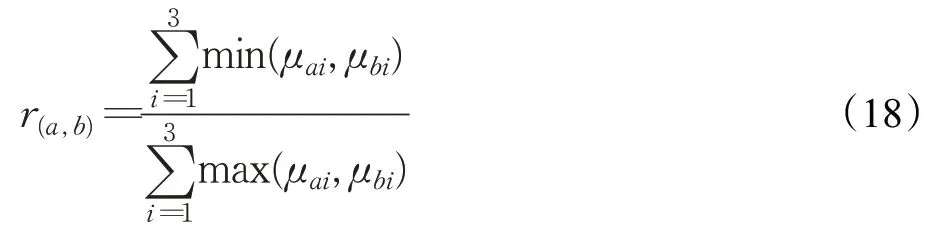
其中,μai表示手写汉字A中结构质量的3个指标(大小、比例、位置)模糊度集合。根据获得的笔画相似度和结构相似度通过权值分配的方法得到手写汉字的评分,若手写汉字的笔画和结构与模板汉字对应部分的相似度任意一项小于0.5,则取其中最小值作为评价分数。
研究者通过收集200个常见汉字进行500次随机书写并进行实验,结果表明其准确率最高可达90.42%。其中书写质量阈值的设置来源于统计模板汉字区间分布,但区间选择只选取统计模板的高频区间,使评价不能达到绝对的公正客观。
这类研究充分利用手写汉字特征,如手写汉字的关键点、重心和笔画等,其评价的效果也随着特征信息的增加而不断变好,但其本质是忽略手写汉字的细节与模板汉字进行相似度计算,虽然解决了手写汉字风格描述困难的问题,但对于一些难以区分的汉字(如“士”“土”,其各自的模糊矩阵非常相似)需要定量分析才可以解决。并且每种特征应该选取合适的隶属函数,若提取出多种不同属性的特征,其隶属函数的选择与构建是一个相当繁琐且耗时的事情,所以隶属函数的泛化是解决此问题的关键。
2.4 基于机器学习的方法
机器学习是研究计算机模拟人类学习的科学,主要学习如何利用有效信息,从数据中获取隐藏的、可理解的知识。在手写汉字评价任务中,利用机器学习从大量数据中学习手写汉字特征与评价之间的关系,避免人工评价效率低、具有主观性等缺点。
2.4.1 基于深度学习的方法
深度学习是一种数据驱动的端到端的方法,其通过学习样本数据内在规律,组合低层特征形成高层特征,用来发现数据的分布式特征表示,更能够刻画数据的内在信息,其在各个领域都有很多成果[36]。在手写汉字评价任务中,运用深度神经网络自动对手写汉字中隐藏的特征进行挖掘,在模板汉字中查找与输入汉字特征最相近的模板汉字,对其进行排序,继而实现手写汉字评价,其一般流程如图3所示。
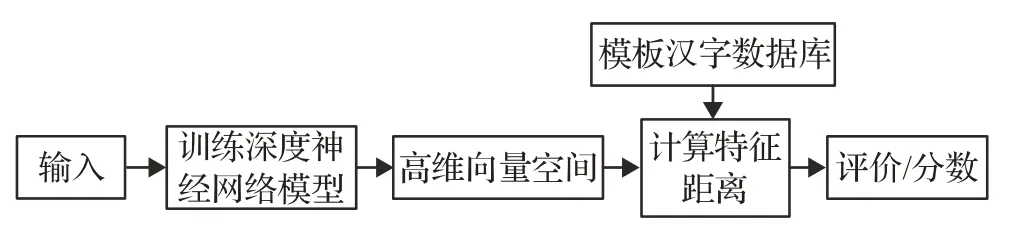
图3 基于深度学习的手写汉字评价方法Fig.3 Handwritten Chinese character evaluation method based on deep learning
这些方法可以高效地代替人工提取特征,尤其在大规模的数据集上改变传统笔画、部件间距等繁杂的特征提取过程,可以更深层次地挖掘手写汉字的特征信息,使手写汉字评价结果的准确率提高。常用的深度学习技术包括卷积神经网络(convolutional neural network,CNN)、BP神经网络(BP neural network,BPNN)等。
(1)基于BP神经网络的方法
以上方法大多利用欧氏距离进行相似度计算,而欧氏距离的计算容易受到特征结构、旋转等因素的影响,并且如何找到不同骨架的对应点也是值得考虑的地方。而人工神经网络可以通过自身的训练学习规则,并不需要事先指定输入与输出之间的关系,就可以得到最接近期望的结果,可避免特征结构、旋转等因素的影响以及找不准对应点带来的误差。
其中BP神经网络的学习过程由正向传播和反向传播组成,正向传播过程输出的结果与实际期望不相符时,则转入反向传播。反向传播通过误差分摊的思想,使误差沿梯度方向下降。正向传播与反向传播是周而复始地进行的,是权值不断调整以及网络学习训练的过程,直到输出的误差减少到可接受的程度或达到预先设置的学习次数为止,其中BP神经网络模型如图4所示。
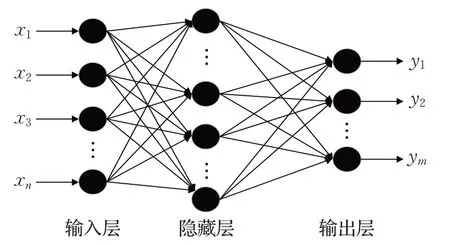
图4 BP神经网络模型图Fig.4 BP neural network model diagram
其中前向传播首先根据属性的个数设置输入层神经单元的个数,除了输入层外其他各层的输入值为上一层输出值与各自权重wij乘积后累加的结果加上偏置θj,每个结点的输出值等于输入值在激活函数f(⋅)的作用下作变换,则前向传播输出层的计算过程如下式所示:

因最初神经网络的权重和偏置都是随机获取,因此需要根据网络的输出层调整网络的权重值和偏置值缩小差异。逆向传播过程如公式(21)所示:
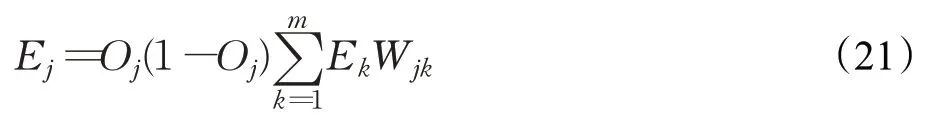
其中,Ej表示第j个结点的误差值,Oj表示第j个结点的输出值,Wjk表示当前层的结点j到下一层结点k的权重值,Ek表示下一层结点k的误差率。
权重值和偏置值调整公式如下所示:

其中,λ∈(0,1),表示学习率。
BP神经网络因其具有较强的自适应性和自学习能力,以及能够以任意精度逼近任何非线性连续函数使其很好地求解内部机制复杂的问题,而被应用于手写汉字评价中,将手写汉字中提取的特征作为BP神经网络输入值,通过学习输入数据的隐藏规则输出手写汉字的评价。
为了手写汉字的书写质量评价效果更优秀,实验采用了神经网络与传统计算方法相结合的方法。手写汉字的特征值越详细,BP神经网络对手写汉字进行评价的效果以及反馈越好。一些研究人员借助联机工具,获取到更多可利用的手写汉字信息[37]。例如,根据笔画的起点和端点、笔势的走向、笔画的像素点集合等,这些信息在图像处理过程中较难获取,并且通常都会对手写汉字评价是否全面起到关键作用。
黄峰[38]利用联机设备获取到每个手写汉字的关键点以及笔画端点坐标等信息,通过外包矩阵以及重心的距离比值等方法得到手写汉字的笔画、部件特征,将其作为BP神经网络的输入进行训练,从而构建了手写汉字评价模型。Sun等人[39]通过3个4层的BP神经网络,分别对全局特征、布局特征以及混合特征进行美感分析,并且使用支持向量机对全局特征进行分类,这种方法更多专注于手写汉字的全局特征,不能满足汉字书写质量评价的细节需求。耿晓艳等人[40]利用三层BP神经网络分别构建了四个评价模型,对9项(复杂度、形态结构特征、黑像素总数等)特征进行不同组合作为输入值,得到11个角度的手写汉字评价,该方法只对标准体的汉字具有较好的评价效果。
以上方法进行手写汉字的书写质量评价时,其准确性与运行速率将受到BP神经网络和手写汉字特征两方面的影响。
BP神经网络方面:(1)因BP神经网络需要解决复杂的非线性化问题,权值是通过局部改善的方法逐渐调整,从而权值容易收敛于局部极小点,使手写汉字评价的训练结果达不到最优效果。(2)BP神经网络对初始权值非常敏感,而随机获取的不同初始化权值极易出现收敛于不同局部极小值的情况,导致每次训练得到不同结果。相同手写汉字在同一评测规则下评分结果应该保持一致,而BP神经网络的运算结果并不满足以上评分条件。(3)BP神经网络算法本质为梯度下降法,调整权值的方向由误差与权值的一阶导数决定,而在BP神经网络的训练过程中,惯性因子是固定的,这导致BP神经网络的收敛速度达不到理想状态,并且为了保证BP神经网络的收敛性,学习率必须小于某一阈值,这同样导致收敛速度不理想,影响手写汉字评价的运行速度。
手写汉字特征方面:目前并没有总结出可以完全描述手写汉字特点的特征值,而是将获得的信息全部进行手写汉字评价,但有些手写汉字特征的信息包含在其他组合手写汉字特征中[41]。例如手写汉字的重心、面积和长宽比数值的组合特征就可得出手写汉字距离各边框的长度,特征提取时就可以忽略被包含的特征,所以分析出一组可得到手写汉字全面评价的特征是非常重要的。该方法为了获得更多有用信息,得到较全面的评价使用了联机设备,而在生活中每个人拥有联机设备是不现实的。为了广泛普及手写汉字评价,如何在不使用联机设备的情况下,高效、准确地提取出手写汉字特征,获得更多有价值信息是值得去研究的。
(2)基于卷积神经网络的方法
卷积神经网络已经在计算机视觉领域取得了巨大的成功,其不仅具有表达效果随着网络层数的增加而增加的优点,而且无需手动选取特征。在手写汉字评价中,之前所有方法都需要人工参与提取特征,算法只是根据特征进行分类或预测,因此人工提取的特征才对书写质量评价的性能起到了关键作用。特征提取不仅需要专业知识而且还花费大量人力。目前,因手写汉字结构复杂,局部特征的提取效果较差并且提取的特征数量有限等问题在一定程度上限制了评价的全面性,而卷积神经网络的出现似乎打破了这种僵局[42]。
典型的卷积神经网络通常包括卷积、池化以及全连接三种基本操作,对图像不断进行卷积和池化运算,在保留图片重要信息的前提下提取图片的抽象特征。卷积神经网络的结构如图5所示。
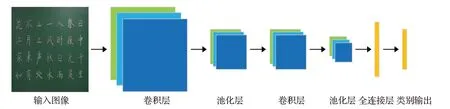
图5 卷积神经网络结构Fig.5 Convolutional neural network structure
卷积层(convolutional layer)是卷积神经网络运算的核心。卷积层利用不同尺度的卷积核对输入数据进行卷积运算,当前层的特征是利用激活函数将输出值进行非线性变换得到,如式(26)所示:
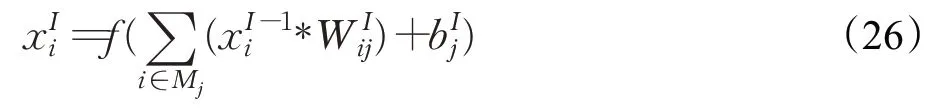
池化层(pooling layer)主要对卷积层的特征进行降维,将像素矩阵大小降为原来尺寸的1/n,可减少计算数量,避免由特征数量过多造成溢出现象,其公式如下所示:
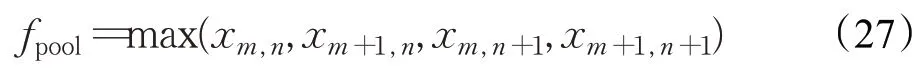
全连接层(full connection layer)实现了特征到类别的转换,用于综合前向提取的特征,可以将卷积层或池化层中具有类别区分性的局部信息进行整合。每个神经元的输出公式如下所示:

其中,wki表示第k层与前i层的连接强度,bk表示偏置,f(⋅)表示激活函数。
Dropout层也是卷积神经网络的常用结构,其通过随机减少单元之间的连接,在整体网络中随机采样一个网络并且更新采样网络的参数,提高网络的泛化能力。
卷积神经网络能够自动从图片中提取特征,通过卷积层自行抽取图像的形状、图形的拓扑结构以及图片内部一些人工无法提取的复杂结构特征,避免了传统算法中特征提取和数据重建过程,所以将其应用在手写汉字评价上可提高特征提取的质量。其中庄子明[43]提出利用卷积神经网络进行手写汉字评价,主要利用以下三部分对手写汉字的美观度进行评价:CNN网络提取手写汉字特征值;CNN网络监督信号;相似度检索以及美感评分。其思路为将手写汉字与具有分数的手写汉字数据库进行相似度检索,根据检索出具有分数的手写汉字确定输入手写汉字的分数,手写汉字相似度检索包括:特征提取和特征的距离计算,其中特征提取的网络图如图6[43]所示。
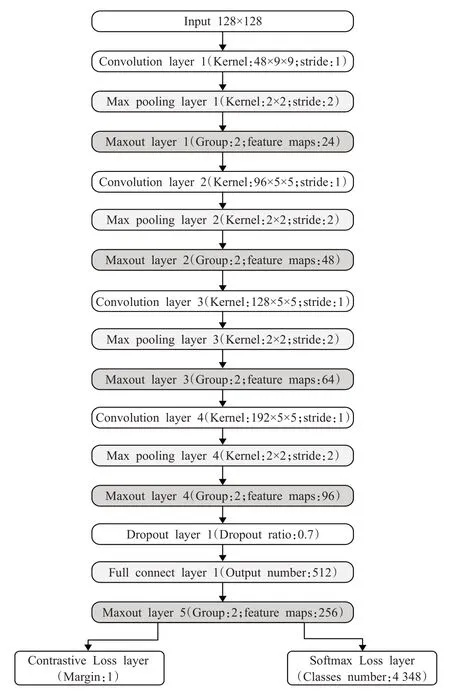
图6 手写汉字特征提取CNN网络Fig.6 Handwritten Chinese character feature extraction CNN network
在手写汉字特征提取CNN网络中,研究者构造了基于maxout结构的特征提取CNN网络,包括4个卷积层、4个池化层、4个maxout层、1个dropout层、1个全连接层以及2个不同的损失层。
卷积层和全连接层使用了ReLU激活函数,其公式如下所示:

在卷积神经网络中,不同激活函数适用的网络类型以及领域不同,而激活函数的选取一般由经验或实验决定,但由于经验可能出现不准确的情况,实验的验证时间较长,所以激活函数的选择成了难点。而两个或两个以上的maxout单元可以很好地逼近任意一个连续函数,使其不仅能在后向传递梯度时避免梯度消失/溢出等问题,还能阻止ReLU函数存在单元失活的问题,并且maxout单元还可以学习隐含单元之间的关系和激活函数,避免非线性激活函数引起的单元非活性化。Maxout的提出解决了激活函数选择困难的问题,但maxout存在激活值不稀疏的缺点,限制了分类精度,而ReLU函数不仅可以增加网络的稀疏性并且可以缓解过拟合问题。
Dropout能够训练共享参数的单元模型,并且均衡这些单元模型,避免在训练过程中出现过拟合现象,提高模型特征学习能力。Dropout在后向传播中更新不同训练子集上的不同模型,而传统模型在激活函数的限制下都是总体训练,不能满足dropout理想的总体分块训练。Maxout利用自身的单元连续线性分段特性和特征子空间池化作用,将dropout根据掩码的不同选择使梯度变化传播到网络的最底层,从而确保模型中每个参数都可进行dropout训练,促进了dropout优化并且提高了dropout快速近似模型平均技术的准确性。所以在图6中maxout、dropout以及ReLU函数结合使用可有效地提高各自性能,在保留图片重要信息的前提下多次卷积和池化运算可以提取图片的抽象特征,用于特征的距离计算。
根据不同汉字书写图像提取的特征值相似度较低这一特征设置了汉字识别监督信号;相同汉字书写图像提取的特征值相似度较高这一特征设置了汉字验证监督信号。汉字识别监督信号和汉字验证监督信号这两方面组成了监督信号。
汉字识别监督信号以及汉字验证监督信号的损失函数如以下公式[43]所示:
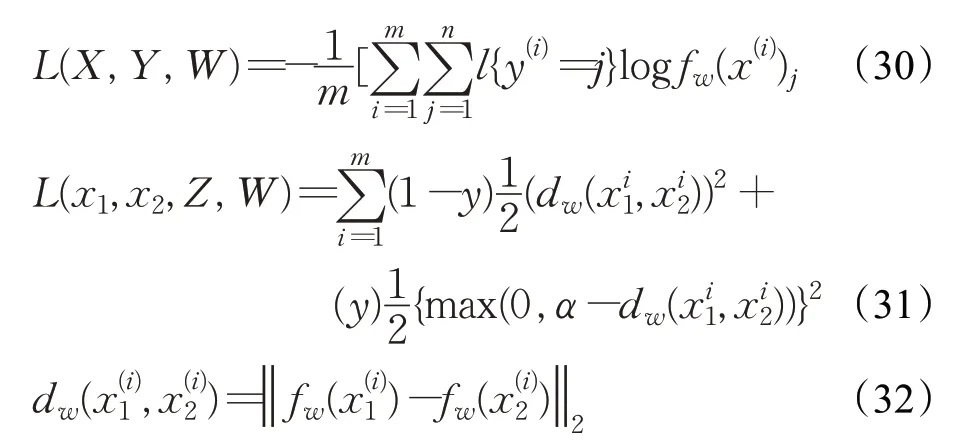
其中,式(30)中X、Y分别表示样本集合以及样本分数类标号,W表示卷积网络的参数。表示为第i个样本前向传递到softmax层第j个单元的概率值,m为批处理参数,l{⋅}为指示性函数。式(31)中x1和x2表示为一个批处理中的所有图像。Z表示这对手写汉字图像是否为同一个字。表示这对手写汉字特征值的距离。
该网络总体损失函数为:
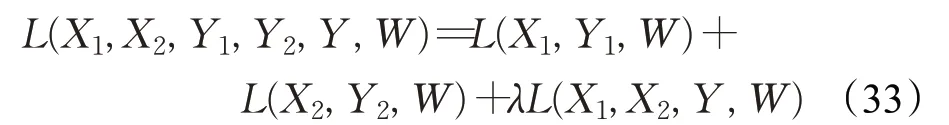
其中,λ表示两个损失函数的平衡系数。
在相似度检索和美感评分部分中,利用余弦距离计算提取出手写汉字的特征值与k类预先训练好的模板汉字特征之间的距离,得到k个概率值,则手写汉字的分数为概率值最大的模板汉字分数。
余弦距离的计算如下所示:
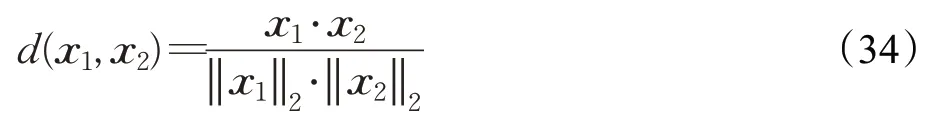
其中,x1和x2分别表示不同手写汉字的特征向量。
实验在收集的109 655张小学生手写汉字上进行测评,结果表明手写汉字的美感评分总体准确率可以达到95.78%。
上述基于神经网络的方法在手写汉字评价任务上取得了较好的效果。运用深度学习的方法自动学习手写汉字中的特征,避免人工提取特征过程中的误判,并且深度学习的分布表示随着数据量的增加而变好。目前需要人工特征提取的方法存在以下两种缺点:(1)在不使用联机设备的情况下,获取到手写汉字的特征仅限于重心、边距和笔画等,对手写汉字进行全面评价任面临一系列困难。(2)手写汉字评价系统最受初学者的欢迎,但初学者在进行汉字书写时,将每一个笔画当做绘画处理并没有体现出汉字的结构化,而手写汉字的结构化也是书写质量的评价标准之一[44]。所以初学者的手写汉字很容易出现笔画与模板汉字笔画差距较大导致笔画匹配问题。笔画匹配主要通过寻找手写汉字相对模板汉字笔画的不同几何变换参数来判断[45],对不规范汉字笔画的匹配存在主观性的阈值限定。因此,利用深度学习进行手写汉字评价可有效解决人工提取特征困难以及笔画匹配等缺点,所以深度学习将推动手写汉字评价发展。
2.4.2 基于机器学习的其他方法
除了以上基于深度学习的方法,手写汉字的书写质量评价还涌现出其他方法。其中祁亨年等人[46]提出利用概率分布计算汉字的对称性、匀称性以及紧凑性,以此作为书写结构的评价指标,利用支持向量机对手写汉字进行三种不同级别的分类。此方法可在宏观上对手写汉字进行评测,较难对手写汉字的笔画、部件等细节形成指导意见,并且用分数的方式对书写质量进行评价,用户无法知道手写汉字的错误位置以及如何改正。温丽敏[47]在书法审美评价中提出将手写汉字的笔段端点、笔段拐点和运笔力度节奏三个特征以及其他信息输入EMD(earth mover’s distance)模型进行相似度的计算,得到手写汉字评价。黄峰[38]利用“质点—弹簧”能量模型(mass spring method,MSM)对手写汉字进行评测,此模型可以容易地识别出手写汉字与模板汉字的变形程度。通过计算手写汉字特征值与模板汉字特征值之间的能量差实现手写汉字的评价。实验结果说明在相同数据集、冗余度为10的情况下,弹性网格评价效果的一致率为92.14%,BP神经网络评价效果的一致率为93.21%。“质点—弹簧”能量模型的评价效果较低的原因是利用手写汉字的特征值比BP神经网络少,仅利用笔画的起点、终点等信息很难判断笔画变形的原因,所以生成指导意见的效果也没有BP神经网络的评价效果好。
2.5 小结
以上方法促进了手写汉字评价的发展。这些方法遵循以下步骤:(1)利用不同的方法提取手写汉字特征。(2)特征匹配。(3)特征相似度计算。基于规则的方法依赖专业领域人工制定规则,通过规则匹配识别各种手写汉字特征,此方法虽然在研究者制定的数据集上收获较高的提取效果,但构建这些规则不仅耗时耗力,难以概括所有规则,而且可移植性较差。基于特征相似度的方法对手写汉字的规范性起点要求比较高,其中字体大小对书写质量评分影响较大,而无法体现手写汉字本质的评分。模糊矩阵的方法更适合评价具有独特风格的手写汉字。这两种方法相比规则的方法,在特征提取方面不但可以更简便地提取结构复杂的笔画等特征,并且提取特征的质量有了很大的提升。基于神经网络的方法相比其他方法,具有两大优势:(1)卷积神经网络可以从图片中学习更复杂的特征;(2)可以处理大规模数据。其缺点是在网络训练的过程中,可能会忽视手写汉字中重要的特征,所以重要特征还需要人工提取与卷积神经网络一同进行评价。并且基于深度学习的手写汉字评价需要拥有样本丰富且数据量较大的数据集,而现实中这样的数据集十分稀少,大部分研究者自己构建数据集。这样造成了面对同一任务时因数据集的不同而无法对比各种方法的效果。
3 反馈形式
近年来,大数据和机器学习技术为传统的手写汉字评价方法带来了巨大变革,其可以在花费极少的人力、物力以及财力的基础上,完成手写汉字评价。手写汉字评价的核心问题是通过特征值之间的差距完成评价,因此本质上可以看做手写汉字的特征值差异与评价的映射问题。而如何将手写汉字的评价在内容以及视觉上反馈给用户已经成为数据到文本生成、字形匹配以及图形辅助等技术发展的支持部分[4],其关系如图7所示。
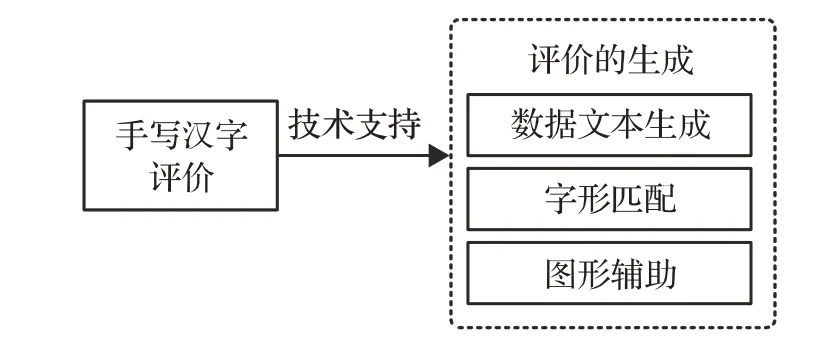
图7 手写汉字评价反馈形式Fig.7 Feedback form of handwritten Chinese character evaluation
3.1 数据到文本生成
数据到文本生成是文本生成任务中重要的一类,主要利用给定的数据库、电子表格以及专家系统知识库等数据,生成贴近事实、描述流畅的相关文本[48]。数据到文本生成可以作为手写汉字评价任务的辅助技术:将手写汉字与模板汉字特征之间的差值作为输入,旨在生成贴近事实的文本描述数据。其目标是实现计算机与人类有效的沟通,加深用户对手写汉字评价的理解,实现评价自动撰写,有效减少教师的工作。
现如今,数据到文本的生成任务主要利用基于规则和模板的方法,因其具有极强的可控性和可解释性,容易确保输出文本的准确性[49]。其中Gkatzia等人[50]针对天气预报的生成,利用不确定信息推荐准则与模拟专家的方式提出了两种基于规则的方法。此方法中模板的抽取离不开人工特征,并且生成内容的多样性与流畅性也存在问题。
基于神经网络模型主要依靠数据驱动,不需要较多的人工干预,也容易产生流畅的文字描述,但无法掌控内容生成,难以确保输出文本同输入数据中的信息吻合[51]。其中文献[52]改变了原有模型中没有明确模拟文本生成顺序的弊端,而将端到端的训练模型分为了内容规划、句子规划以及表面实现三种模块,文本生成效果有了很大的提升,但此方法无法充分利用数据结构的信息,对具体数值推理存在巨大问题。针对以上问题,许晓泓等人[53]对内容规划进行改进,采用基于Transform的内容规划用于上下文数据信息的推理,并且通过生成指引序列控制输出文本的流畅性。实验结果说明,改进的内容规划使性能有了较大的提高。
相比基于规则的数据到文本生成方法,数据驱动的方法不需要专家参与,生成的文本可能与领域无关,但需要大规模的数据集进行训练数据,数据的训练质量影响训练结果。将其应用于手写汉字评价中,存在手写汉字与模板汉字特征之间的差值数据选择由计算机进行挑选,生成的文本不一定满足复杂数据的问题。例如,在一章手写汉字中找到一个整体书写质量最差的汉字,则其笔画或字体大小等某一特征一定存在分数较差的问题,而这并不代表其所有特征在这一章中是最差的。
3.2 字形匹配
字形匹配是指将手写汉字的笔画与模板汉字的笔画进行匹配,找到一个笔画数量最多的匹配集合,集合找到手写汉字笔画集合中的交叉关系与模板汉字笔画集合中的交叉关系是一致的,以上就完成了手写汉字笔画与模板汉字笔画之间的对应关系。将字形匹配与手写汉字评价相结合,字形匹配可以结合图形辅助以图的方式出现,使用户更加了解自己书写汉字的缺点,增强用户体验感。Hu等人[54]利用属性关系图表示汉字,建立汉字笔画之间的空间关系模型,并利用容错图匹配笔画和部件关系的错误。刘颖滨等人[55]提出在三维空间建立高斯混合型模型,利用三维空间可以充分定义字形信息,改善字形匹配的效果。Chen等人[56]根据输入笔画顺序关键信息、笔画之间全局结构关系以及对归类的笔画与模板汉字匹配等问题进行反馈,辅助教师进行手写汉字评价。
该类方法只适用于小范围的数据集,很难接受变形较大的手写汉字。例如,对于手写汉字的初学者,他们对手写汉字的书写仅是模仿,下笔的力度也不能灵活掌握,这会产生想象不到的笔画形变,这时字形匹配的效果也达不到想要的效果,所以字形匹配的方法还需要研究者进一步探索。
3.3 图形辅助
规范且易于理解的反馈形式具有更好的用户体验感。现有的手写汉字评价反馈形式主要有以下几种:评价文本、打分、图形辅助等。评价文本可以直接将手写汉字的缺点以文本的形式展示出来,但表现形式不够直观,不易用户理解,并且对于一部分阅读经验不足的用户来说,并不能全部理解评价文本的内容。评价以打分或等级的形式出现,只是通过这种方法评价用户的手写汉字达到规范的程度,用户无法知道手写汉字的具体错误、如何修改等信息,用户体验较差,如图8(a)所示[56]。图形辅助的手写汉字评价可以利用几何图形在图中标注出手写汉字具体不规范的位置,如图8(b)所示[57],图中将模板汉字与用户书写的汉字叠加展示并且使用动物图片提供更多的视觉反馈,激励用户更好地认识汉字。与文本生成和字形匹配这两种方式相比,图形辅助这种方式更加直观,具有较好的用户体验。

图8 评价的反馈方式Fig.8 Feedback mode of evaluation
以上三种方式都是静态的反馈形式,在规范性指导方面还不够具体。例如无法与用户交流书写错误如何改正,并提供正确的修改事例。所以在图像辅助方面还需要借助各种动画技术以及自动问答技术的支持,对手写汉字的评价进行反馈指导和改进指导,这样才能加强用户体验,充分发挥计算机的辅助作用。
4 问题与挑战
近年来研究者针对手写汉字评价进行了大量研究工作并且获得了不错的研究成果,但仍存在许多要解决的问题,目前关键问题如以下几点:
(1)数据来源匮乏
手写汉字的书写质量评价系统需要一个大规模且样本丰富的数据集。而目前手写汉字的数据集大多关于手写汉字识别,缺少对每个汉字的评价以及分数。也有一部分数据集数据样本数量较少,这给研究带来了一定的困难。例如孙榕鞠等人整理的CHAED字库,它包括30个人书写10种不同字体的100个汉字,由33个专业人士对此数据集进行评分。此数据集中手写汉字种类数量较少,无法全部代表复杂的汉字,并且评价的反馈形式只有评分,这对生成一个完备的评价存在一定困难。
目前研究者的数据集根据反馈形式大多自行采集,收集和整理这些数据需要花费大量的人力、物力以及财力。例如黄峰[38]的数据是通过收集某三年级学生手写汉字集成,每个学生需要书写8遍具有28个汉字的样本,还需要专家在每个实验样本中随机挑选20个汉字进行评分。没有全面且公开的手写汉字评分数据集,很难对不同方法进行效果比较,给手写汉字书写质量评价的研究和发展带来困难。面对数据来源困难可参考自然语言处理或计算机视觉领域的数据扩建方法,利用半监督学习、无监督学习实现数据的自动构建以及迁移学习等方法都可以作为解决该问题的方法。而如何将迁移学习应用在手写汉字评价中,还需要进一步研究。
(2)脱机手写汉字笔序难判断
根据计算机最终得到手写汉字的信息不同,可将其分为联机手写汉字[58]和脱机手写汉字[59]。联机手写汉字是指直接在电子屏等电子仪器上书写,可以实时检测笔画的顺序以及笔画总数等多种信息,较容易提取汉字的多种特征值。脱机手写汉字是指没有电子屏等电子仪器的参与,计算机得到的只有手写汉字图片信息。脱机手写汉字相比联机手写汉字提取的汉字特征值比较少,所以评价的效果不如联机手写汉字的评价好。
规范的汉字书写要求笔序必须书写正确。成授昌[60]提出手写汉字的统一、对称等方面都与笔序相关,正确的书写顺序可以提高手写汉字的书写质量和书写速度,所以笔序对规范的汉字书写是非常重要的。教师在“三笔一画”与小学生的语文考试中,手写汉字的笔序也占一定的分数。联机手写汉字较容易获得笔序等信息,所以评价手写汉字笔序的效果较好[61]。因脱机手写汉字进行手写汉字评价时,得到的只有手写汉字图片,所需要的信息只能利用图片处理等技术得到,笔序等信息无法在图片上体现。为了得到手写汉字笔序相关信息,有研究者利用规则的方法判断手写汉字的正确笔序,却得不到书写者的笔序信息。所以如何评判脱机手写汉字中笔序的正确性,还具有一定的挑战难度。
(3)手写汉字的笔画拆分难
笔画质量是书写质量评价中重要的评估项之一。而手写汉字的笔画拆分过程是一个十分困难的过程。笔画与笔画之间的关系有:相接、相交、相离[18]。笔画相离的手写汉字比较容易进行笔画拆分,但汉字大部分都具有结构复杂、笔画数较多的特点,其中存在大量的相接、相交、相离关系,仅解决相离问题是不能完成笔画的拆分过程。
目前关于脱机手写汉字笔画拆分的解决方法之一[38]是,利用PS工具圈出所要提取的手写汉字笔画。此方法虽然提取的效果较好,但如果评价的书法字数据量大时,则需要花费大量的时间拆分笔画。除此之外,朱欣蔚等人[62]利用PBOD算法找出手写汉字的交叉区域以及端点区域,将手写汉字的端点区域以及交叉区域在无向图中表示出来,利用规则对各区域进行组合实现拆分笔画。但PBOD算法只对规范汉字进行笔画提取的效果较好,却无法较好地分离不规范汉字的笔画。关于联机手写汉字的笔画拆分方法是笔段的拆分与合并[63],该方法需要提前建立大量的工作:建立32种不同笔画的笔画库,对难以区分的笔画通过建立规则以正确区分笔画。该方法利用拐点将笔画分为笔段,对于初学者来说,由于手写汉字中存在变形较大的笔画,对笔画的分段存在划分不准确的情况,致使笔画编码错误,所以该方法对初学者的笔段提取精确率不高。
虽然在光学字符识别(optical character recognition,OCR)领域还有许多关于笔画提取的成果[64](如细化的方法、区域分解法等),但这些方法允许结果有一定的误差,且对每个手写汉字提取笔画计算时间过长[65]。所以如何快速、准确地得到笔画的特征值是一个值得去思考的问题。
(4)手写汉字评价的标准量化困难
评价标准是评价的核心,用来规定当前手写汉字中笔画等特征达到不同范围的对应分值准则。研究者对手写汉字的评价关注点从对称性、匀称性等描述手写汉字全局的特征,逐步转到笔画、部件等描述手写汉字局部的特征,评价手写汉字的书写质量效果在不断地改善,但评价手写汉字的特征越细致,其评价标准范围的选取越严格。
不同研究者对同一等级的手写汉字制定规则时具有主观性,所以会制定出不同的规则[3],不同的规则导致对同一等级的手写汉字评价不同,这在手写汉字的书写质量评价中是不合理的。为了初学者获得自信,有些研究者制定的规则范围较为宽松[66],也有一些研究者针对不同学习背景的人群,分别制定出较难和简单两个等级的评价标准,这种评价标准更适合应用于大众[56]。但因不同研究者对规范的定义不一致,即使不同的系统都选择简单的评价指标,也存在评价分数不同的现象。为了解决以上问题,葛佳敏[34]利用模糊概率分布和模糊综合评价方法结合得到一个期望值范围,解决了传统评价方法简单、具有主观性的单一评价标准的问题。此方法中评价标准制定的数据来源于模板汉字和机器人书写的汉字,由此得到的期望值范围并不适用于所有书写质量评价。所以如何获得一个适合大众、具有专业性的评价标准还是值得去思考的。
5 结束语
目前关于手写汉字书写质量评价方法的研究比较少,处于刚刚起步的状态,还有许多地方需要改进。这项技术的发展必将促进计算机辅助书写教学的进步[5]。文中对近几年的研究做了总结,其中包括手写汉字的相关概念、评价方法、评价难点以及反馈形式等部分。由于传统的手写汉字评价方法需要大量人力资源,研究者逐渐把目光转移到神经网络的评价方法上,神经网络评价方法的出现为手写汉字评价提供了许多新思路,但目前只是处于刚刚起步的状态,由此可以预见,手写汉字的评价方法还有很大的发展空间需要继续去研究。
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
故事作文·低年级(2021年12期)2021-12-21
——识记“己”“已”“巳”
小学生学习指导(低年级)(2020年12期)2021-01-16
考试与评价·高二版(2020年2期)2020-09-10
学生天地(2020年14期)2020-08-25
作文成功之路·小学版(2020年7期)2020-08-24
电子制作(2018年18期)2018-11-14
小天使·二年级语数英综合(2018年10期)2018-10-15
