
基于Lucene的专利信息智能检索技术
2022-02-02 10:13潘晓梅王全喜
机械设计与制造工程 2022年12期
杨 芳,张 宁,潘晓梅,王全喜
(1.国家电网有限公司信息通信分公司,北京 100761) (2.保定市大为计算机软件开发有限公司,河北 保定 071000)
目前,各级知识产权局的相关专利信息展示页面以及知网、万方等文献网站,均对专利信息进行了较为全面的公示。十九大以来,我国每年专利受理量均在400万件左右,如何在浩如烟海的专利信息中检索到需要的专利信息,成为当前信息管理学中需要解决的技术问题。黄孝伦等[1]研究了科技查新系统的实现策略,认为Lucene是系统的核心引擎模块;熊安萍等[2]与李致远等[3]分别对Lucene的索引模块进行了系统研究,并提出了优化策略。在全文检索需求下,赵广[4]、张绍琳等[5]、沙阳阳等[6]和张俊飞[7]分别就各自的全文检索个案进行了算法优化研究,并对Lucene在全文检索的效率和适应性、计划性方面进行了个案研究。在具体应用领域,蒋晓玲等[8]进行了Lucene在高校科技文献系统中的应用研究,刘怡[9]进行了Lucene在电子病历系统中的应用研究,潘宁宁[10]进行了Lucene在融媒体多维可视化系统中的应用研究。
然而,单纯使用Lucene的封装功能会造成搜索结果中的语义、语境理解不一致问题。Lucene提供的根据分词词元权重对文档进行排列,难以在搜索结果中得到更丰富的信息,如专利的下载量、相关或相似专利的数量、收录专利信息的网站数量等。因此,在检索前对词元语义进行分析,在检索后对相关信息充分整合,最终提供更符合检索需求的检索结果,成为当前Lucene应用研究的重点。
1 检索工具包Lucene的应用模式
在爬取信息的基础上确定检索关键词,通过Lucene进行检索,同步抓取信息中的专利下载量、相关或相似专利的数量、收录专利信息的网站数量等信息,采用加权因子法对检索结果进行基于Lucene排序的二次排序,最终得到搜索结果。Lucene应用数据流程如图1所示。
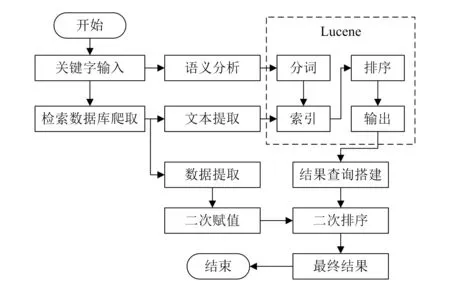
图1 Lucene应用数据流程图
Lucene工具包提供了检索、排序的核心功能,即分词、索引、权重排序、结果输出功能。由于这些功能已经封装在Lucene中,相关的研究多集中在Lucene的索引功能和排序功能算法的优化,导致Lucene相关组件调用的代码过于冗长,在一定程度上增加了系统存在Bug的概率,且给软件的后续升级带来一定压力,因此本文采用基本的格式化Lucene调用代码调用Lucene组件,实现Lucene的基本功能,其调用方法在基本算法分析中不再赘述。通过语义分析和二次赋值两个算法,提高了Lucene的检索效果。
2 基于机器学习的Lucene深度开发
2.1 机器学习模块的输入输出架构
经过爬虫检索的原始结果序列,分两路进入模糊神经网络机器学习模块。一路直接进入,为一个二维序列,二维中一维为指针序列维度,一维为控制字段维度,包括指针序列号(Long格式)、文章标题(String格式)、文章内容快照(String格式);另一路经Lucene进入,经过Lucene的分词、索引、排序、输出后直接输出序列,输出后的结果也是二维序列,且与直接进入的二维序列相同。机器学习模块的输入输出流程如图2所示。

图2 机器学习模块的输入输出流程
以原始结果构建的指针序列为例,将原始序列定义为LOG-A,经过Lucene处理的指针序列定义为LOG-B,经过机器学习最终输出的指针序列定义为LOG-C。虽然上述流程中经历了多步操作,但其指针序列仅经历了2次改变,分别为经过Lucene处理后的一次改变和经过机器学习模块处理后的Lucene序列改变。传统Lucene序列处理后输出的结果为LOG-B驱动下的输出结果,而基于机器学习的Lucene改进算法输出的结果为LOG-C驱动下的输出结果。
2.2 评价标志集生成算法
评价标志集生成算法其目的是检索目标的重排序过程,涉及到的数据量特别是非标准化的文本数据量较大,如果直接输入神经网络中势必增加神经网络的节点量,有较大算力需求,因此有必要采用模糊神经网络算法。将长度未知且同构化难度较大的文本非标准数据生成标志集,使非标数据标准化,如图3所示。
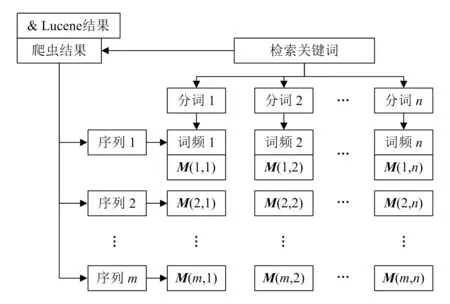
图3 评价标志集生成算法
图3中形成的二维矩阵序列为不同分词条件下的M矩阵,为每一分词在其对应序列下的词频标志矩阵。该矩阵生成模式下,机器学习模块的输入变量集为宽度为n、长度为m的整型变量二维矩阵(Integer格式)。为简化神经网络,设定分词量不多于20个,序列量不多于200个,最终形成n=20、m=200的两个评价标志集输入矩阵M(m,n),可以得到神经网络的2组各4 000个输入变量。
2.3 机器学习模块细节设计
如果单纯使用降维算法将8 000个输入节点变为1个输出节点,则无法实现对实际序列排序结果的输出,因此对于200个序列的重排序结果,必须确保输出节点达到200个。机器学习模块采用多列神经网络实现,每个输出节点的输出值依然为序列指针值,以保证输出结果无需解模糊即可直接获取实际输出情况。多列神经网络结构图如图4所示。

图4 多列神经网络结构图
图4中,基于Lucene中200个序列指针集形成200个多列神经网络节点,每个节点的输入来自于其对应的1列Lucene输出数据和基于原始爬虫结果进行降维形成的1列参照数据。
如前文所述,模块的数据输入量为4 000个整型数据(Integer格式),输出为1个双精度浮点型数据(Double格式),其节点按照2/3取整进行降维压缩,即分别为2 666,1 777,1 185,790,527,352,235,157,105,70,47,32,22,15,10,7,3个节点。以上合计8 000个隐藏层节点。由于数据降维过程中会损失大量信息,为确保信息利用率,因此使用待回归系数的多项式节点函数进行节点设计。节点函数为:
(1)
式中:Y为节点输出值;Xi为输入数据列中第i个输入项;Aj为多项式的待回归系数,j为多项式阶数,此处选用6阶多项式进行控制,即有6个多项式待回归系数。
多列模块分别服务于m个输入序列,每个多列模块仅有2个输入节点和1个输出节点,因此其统计学意义并非上述参照模块的数据降维作用,而是分析数据间的逻辑关系。为充分放大数据细节,该多列模块采用数据放大效应最佳的对数函数进行节点设计,将其隐藏层设计为2层,每层3个节点,共6个隐藏层节点。200列多列节点共含有隐藏层节点1 200个。节点函数可写作:
Y=∑(A·lnXi+B)
(2)
式中:A,B为待回归系数。
3 开发效果实测
使用上述基于机器学习Lucene深度模型在LAMP开发平台上进行应用实现,同时在LAMP开发平台上构建纯Lucene查询系统,即未使用上述语义识别和二次赋值数据加权的Lucene查询系统,对同一顺序文件库采用相同数据可视化模式,获得优化后的“复合模型”以及“纯Lucene模型”两组查询结果。
选择100名志愿者,其中50人从事与专利转化相关的工作,50人从事非专利转化工作,男女各50人,年龄在24~50岁,要求其根据查询结果做出主观评价。在特定比较项目中,10分为特别满意,0分为完全不满意。比较两个模型的实际分析效果,结果见表1。

表1 信息查询效果的主观评价结果对比表(Lucene实现模式)
由表1可知,复合模型的主观评价结果显著高于纯Lucene模型,且t<10.000,P<0.01。同时,纯Lucene模型组的数据分散程度显著高于复合模型组,即不同志愿者对纯Lucene模型分析结果的主观评价存在更大分歧,对复合模型分析结果的主观评价相对集中。
将复合模型评价结果与常见的技术文献查询数据库如*乎、*度学术、中国*网、*方数据等的结果进行比较。为避免侵权纠纷,本文将其顺序打乱后分别称为平台A~平台D,比较结果见表2。

表2 信息查询效果的主观评价结果对比表(常用平台)
由表2可知,本文使用的复合模型的评价结果显著高于其他常见平台的评价结果,但该对比结果并不代表其他平台使用的算法效能不及本文复合模型,而是因为信息检索业的盈利模式驱动相关平台需对排序进行其他形式的信息标记加权,导致其无法向用户提供完全符合用户预期的检索结果。加之商业化专利信息展示平台的数据来源具有局限性,导致其数据库并不完善。而本文复合模型因为并不提供商业服务,仅用于相关机构内部进行专利信息检索、比较,所以其检索过程中不受上述制约因素的限制。结合表1与表2数据可以看出,即便不使用前置语义分析和后置信息加权,单纯使用Lucene开发工具包进行开发,其最终的主观评价结果也优于当前的一些商业化专利信息展示网站。
4 结束语
通过使用基于机器学习多列神经网络的语义分析标记模块和后置的权重排序数据加权整合模块,本文提出的Lucene复合检索模型对Lucene检索功能进行了有益扩充,使其检索结果的主观评价结果得到了提升。该模型适用于专利相关企业进行专利开发的查新和专利转化的信息寻访等,如进行商业化应用,专利信息的爬取存在一定法务风险。本文研究的Lucene复合查询模型,在查询效能和查询结果人性化程度方面尚有待提升。
猜你喜欢
水运工程(2022年7期)2022-07-29
电子制作(2019年19期)2019-11-23
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
中国洗涤用品工业(2019年4期)2019-05-11
电子制作(2019年24期)2019-02-23
专利代理(2016年1期)2016-05-17
重型机械(2016年1期)2016-03-01
海军航空大学学报(2015年4期)2015-02-27
