
基于BP神经网络的Se元素生物有效性预测研究——以黄沙街镇茶叶Se为例
2022-02-03 05:29李聪郭军杨鹏至陈方伟毛雄汤恒佳
四川地质学报 2022年4期
李聪,郭军,杨鹏至,陈方伟,毛雄,汤恒佳
基于BP神经网络的Se元素生物有效性预测研究——以黄沙街镇茶叶Se为例
李聪,郭军,杨鹏至,陈方伟,毛雄,汤恒佳
(中国地质调查局长沙自然资源综合调查中心,长沙 410600)
Se含量是茶叶质量重要指标,为了预测茶叶中的Se含量,本文以岳阳县黄沙街镇茶叶基地的茶叶Se元素为研究对象,基于BP神经网络建立茶叶Se预测模型,在此基础上预测了黄沙街茶厂茶叶Se富集系数。并与实测结果进行对比,其研究结果表明预测结果精度达到84.77%,与实际数据有较好一致性。该建模方法同样可运用于土壤中其他元素的预测研究。
BP神经网络;茶叶Se;生物有效性;模型;黄沙街镇
在以往研究中,对元素生物有效性研究更倾向于建立模型,而模型建立往往选择传统的多元回归方程。在预测原理方面,其回归预测模型需人为选择预测变量间的函数形式,而BP神经网络则不需要人为选择函数形式。可以通过网络的自学习能力,建立预测变量到被预测变量的非线性映射,其在环境评价和预测等方面的具体应用中表现出高于传统方法的精确度(何国民,2019)。因此本文以黄沙街镇茶叶基地所产茶叶中的Se元素为研究对象,根据前人研究及通过对数据进行相关分析挑选了土壤pH、CaO、有机质为变量因素,基于BP神经网络预测了黄沙街镇茶叶Se元素含量。为了更好地安全高效利用土地提供科学依据。
1 材料和方法
茶叶采集均为秋茶,且表1数据取自相同品种黄茶,茶叶类样品采集方法:以0.1hm2~0.2 hm2为采样单元,随机选取15棵~20棵植株,每株采集上、中、下多个部位的叶片混合成1件样品,老叶或新叶混合采样。初步加工:茶叶类样品采用随机取样法缩分,先用清水将样品洗净晾至无水后,将整株植株粗切后混合均匀,随机取所需足量的样品。加工方法:①用不锈钢刀或剪刀将茶叶样品在晾干室内或高出地面1.5m以上架子上摊放于晾样盘中风干,或将切碎样品放在85~90℃烘箱鼓风烘1 h,再在60~70℃下通风干燥24~48 h成风干样品。;②将风干样品置于玛瑙研钵进行研磨,使样品全部通过40目~60目尼龙塑料筛,混合均匀成待测试样。
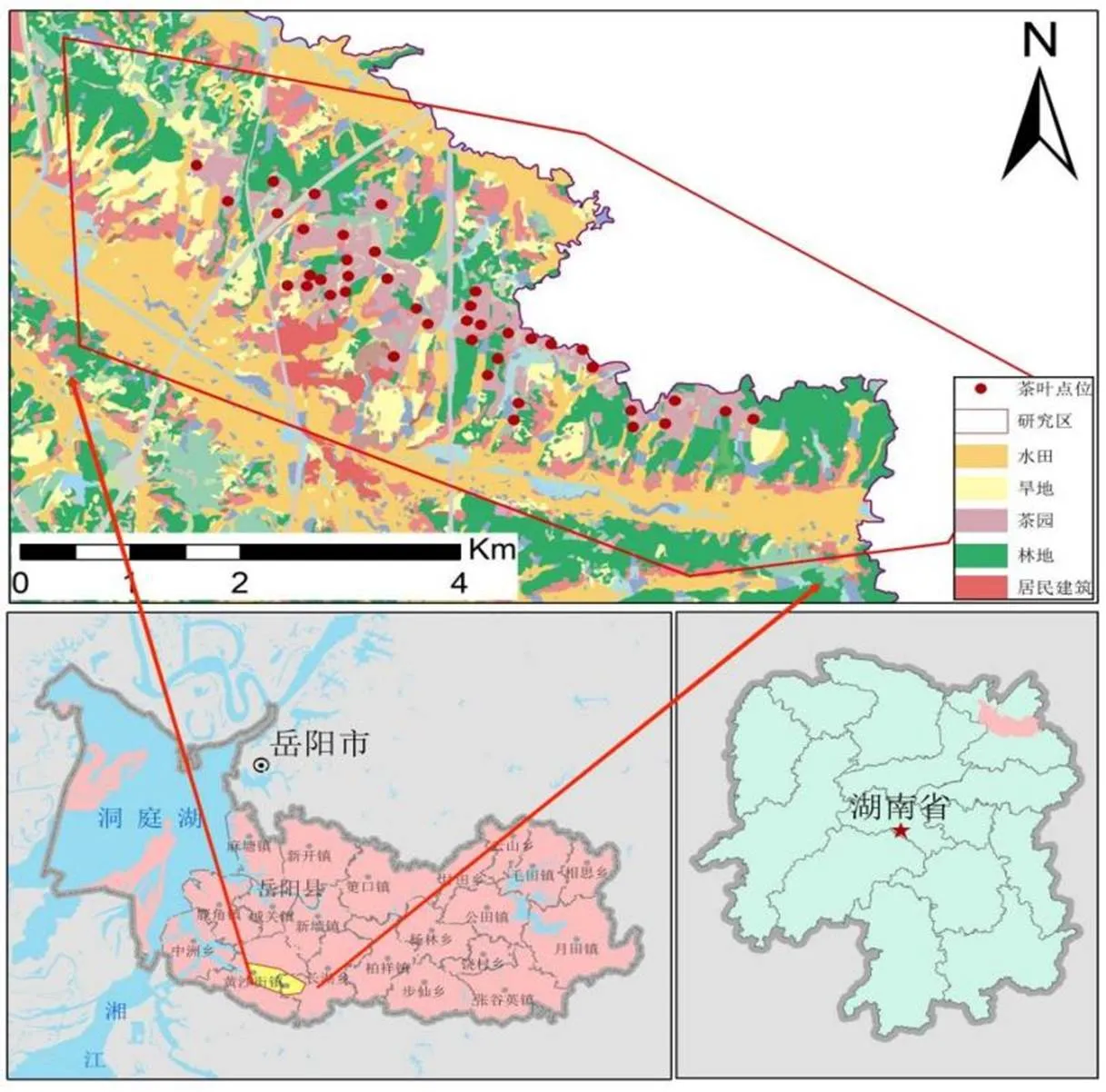
图1 研究区位置图及采样点位图
数据处理方法:数据整理利用Excel、Origin完成,图件绘制利用SPSS、ArcGis完成。
1.1 Se生物有效性
茶叶中Se含量富集系数(K)通过如下公式计算:
K=Cplant/Csoil
其中,K表示元素的富集系数,Cplant为重金属元素在作物中的含量,单位为mg/kg,Csoil为重金属元素在根系土中的含量,单位为mg/kg(王锐等,2020)。
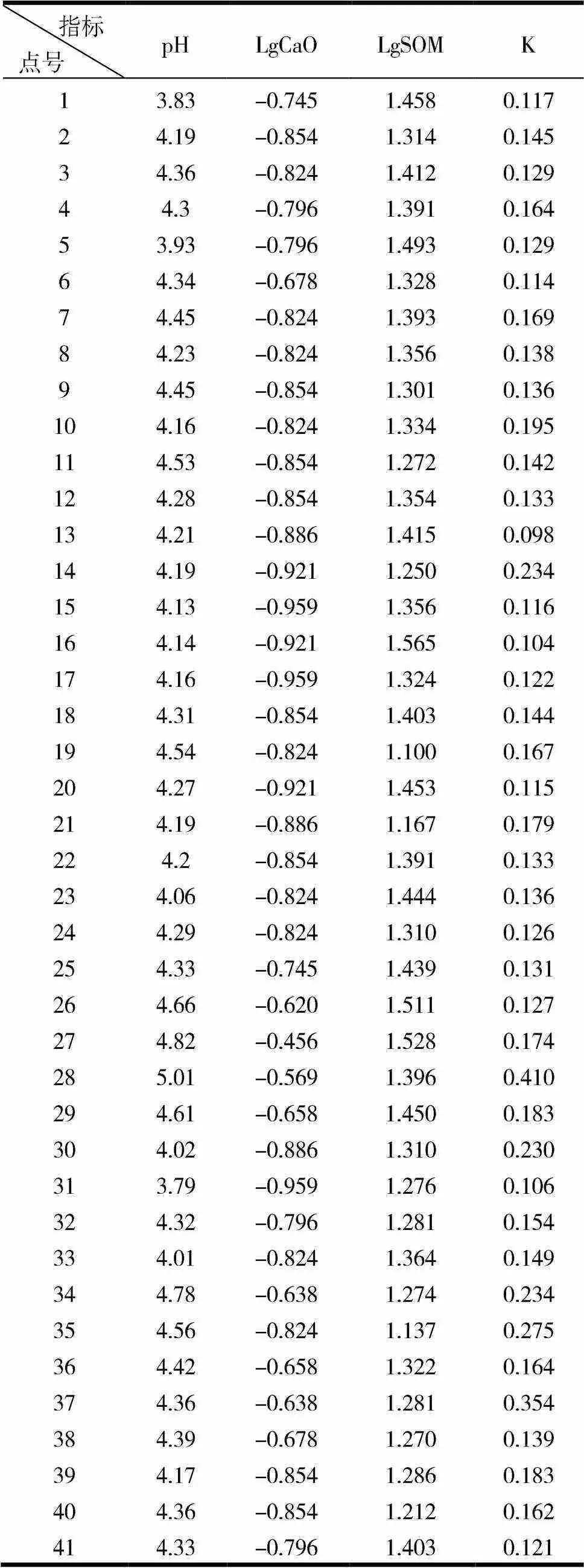
表1 元素指标数据
2 研究区概况
黄沙街茶厂建于1965年,位于湖南省东北部岳阳县洞庭湖畔,东接107国道,茶厂占地面积3.2万亩,是湘北地区建场时间最长、连片种植规模最大、年茶叶产量最大的茶叶生产基地。湖南省九大茶叶示范厂之一,年产干茶5000余担。茶厂地处长江中游中低纬度区,属亚热带大陆季风湿润气候,受季风的影响较大,年平均气温17℃,年平均降雨量在1500mm以上。茶厂主要出露地层为第四系洞庭湖组和汨罗组,厂区的地形主要以岗地为主,土壤类型主要有红壤、水稻土。
3 模型的建立
3.1 建模原则
在拟合模型建立过程中,必须满足数学模型建立的三个基本原则:简化原则、可推导原则和反映性原则。在模型建立过程中,需秉持“简明实用”的原则,防止出现“过度拟合”的错误 。其次,建立的模型要在数学基础上能完成推导,可进行一定程度的推广。最后数学模型的主要目的是为了解决实际问题,因此建立的模型必须具有地质意义,要将地质问题和传统数学联系起来,反映客观事实(杨忠芳等,2020,王锐等,2020)。
3.2 指标样本选取
本文通过主成分分析法确定影响茶叶Se吸收的主因子中,挑选权重较大、相关性较强及与Se密切相关的影响因素用于网络训练及建立多元非线性回归模型方程:土壤CaO、土壤有机质、pH。其变量数据均进行对数化处理(pH除外),茶叶Se含量用富集系数K表示,各指标数据见表1。
3.3 构建模型
人工神经网络无需事先确定输入输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。作为一种智能信息处理系统,人工神经网络实现其功能的核心是算法。同现行的计算机不同,是一种非线性的处理单元。只有当神经元对所有的输入信号的综合处理结果超过某一阈值后才输出一个信号。因此神经网络是一种具有高度非线性的超大规模连续时间动力学系统(闫以聪等,2007)。我们只需将经过对数化处理后的变量因素导入神经网络中,而后设置代码,经过一系列运算便可得出其结果。
3.3.1 设置代码
getwd( ) #查询工作目录
setwd("F:/data") #设置工作目录
tea <- read.csv("tea.csv") #读入茶叶根系土数据
str(tea) #查看数据结构
plot(tea$K)
hist(tea$K)
tea$Cdr <- log(tea$K)
hist(tea$Cdr)
tea$Cds <- log(tea$Cds) #使数据均衡分布
normalize <- function(x) { return((x - min(x)) / (max(x) - min(x))) }#构造归一化函数
tea.norm <- as.data.frame(lapply(tea[,5:12], normalize))
summary(tea.norm$Cdr) #确认归一化结果
summary(tea.norm$Cds) #确认归一化结果
ind <- sample(2, nrow(tea), replace = TRUE, prob = c(0.8, 0.2)); #随机八二抽样;
tea.train <- tea[ind == 1,] #设置训练数据
tea.test <- tea[ind == 2, ] #设置检验数据
library(neuralnet) #加载神经网络包neuralnetset.seed(12345);
model1<-neuralnet(formula=K~CaO+pH+有机质,data=tea.train) #构造和训练了神经网络plot(model1) #绘图
test1.results <- compute(model1, tea.test[1:7]) #计算检验数据
predicted1 <- test1.results$net.result #提取验证结果
3.3.2 网络结构(图2、图3)
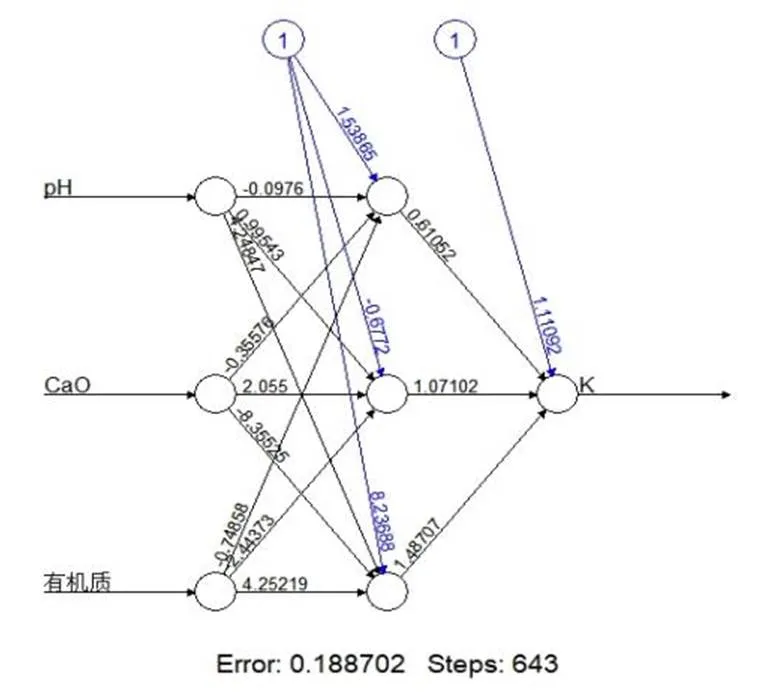
图2 神经网络训练结构
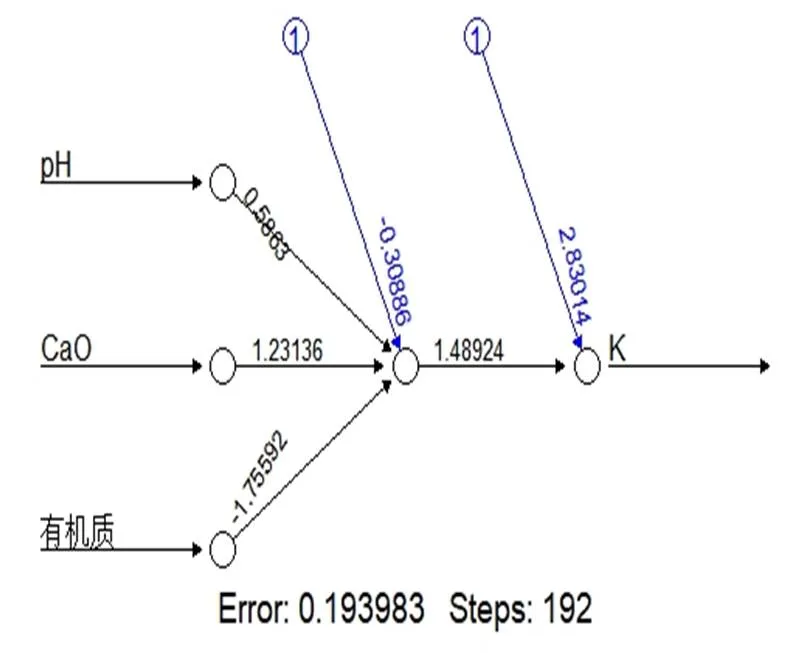
图3 神经网络拓扑结构
3.3.3 训练数据处理
将原始数据经过R语言构造归一化函数,然后将41件茶叶及根系土数据进行八二抽样,以设置训练数据和检验数据,确保后续所生成预测数据与原始数据对比误差小,如模拟精确高、误差小,则证明此网络模型可用于下步预测。
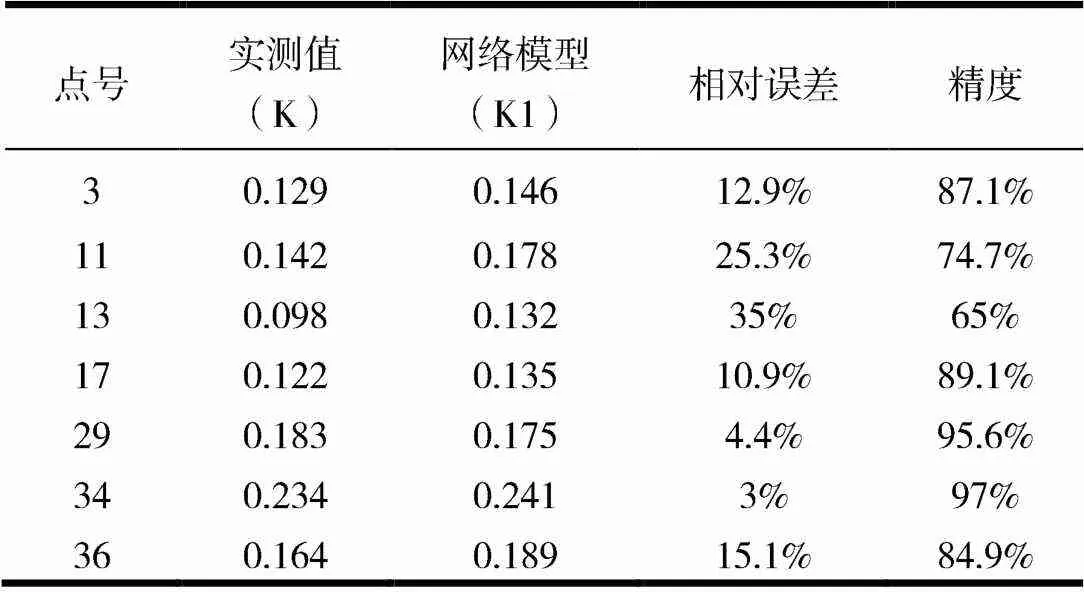
表2 BP网络模型误差表
3.3.4 网络模型的检验与验证
网络训练完后,通过对目标实测值与预测值进行对比参照(表2,图3),下表实测值(K)与网络模型值(K1)均为富集系数,检验网络模型的拟合度及精确度和误差值,在此仅以抽样后检验数据作为对比,其中数值及结果均为经过归一化处理后的还原值。
采用归一化平均误差(NME)和归一化均方根误差(NRMSE)判断模型的准确度与精密度,公式如下:
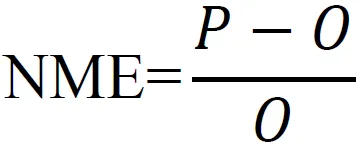
其中:P为预测值的平均值,O为实测值的平均值,Pi表示第i套样品的预测值,Oi表示第i套样品的实测值,N表示样品总数。通过对34组训练数据计算,该方程的NME=-0.024,NRMSE=0.284,其准确度和精确度均较好。
从对Se元素的含量预测中可以看出,BP神经网络预测模型精度达到84.77%,其归一化平均误差(NME)和归一化均方根误差(NRMSE)显示其准确度与精确度均较好,可以体现出网络模型对于这种不直观化的事物中的优越性,明显高于传统多元回归模型。
4 结论
利用BP神经网络的特殊优势及算法,不需要人为选择函数运算形式,可为该地区富Se茶叶选址提供依据,由于神经网络被证明具有非线性函数处理能力,相较于传统回归模型处理线性模型更具优势及根据。
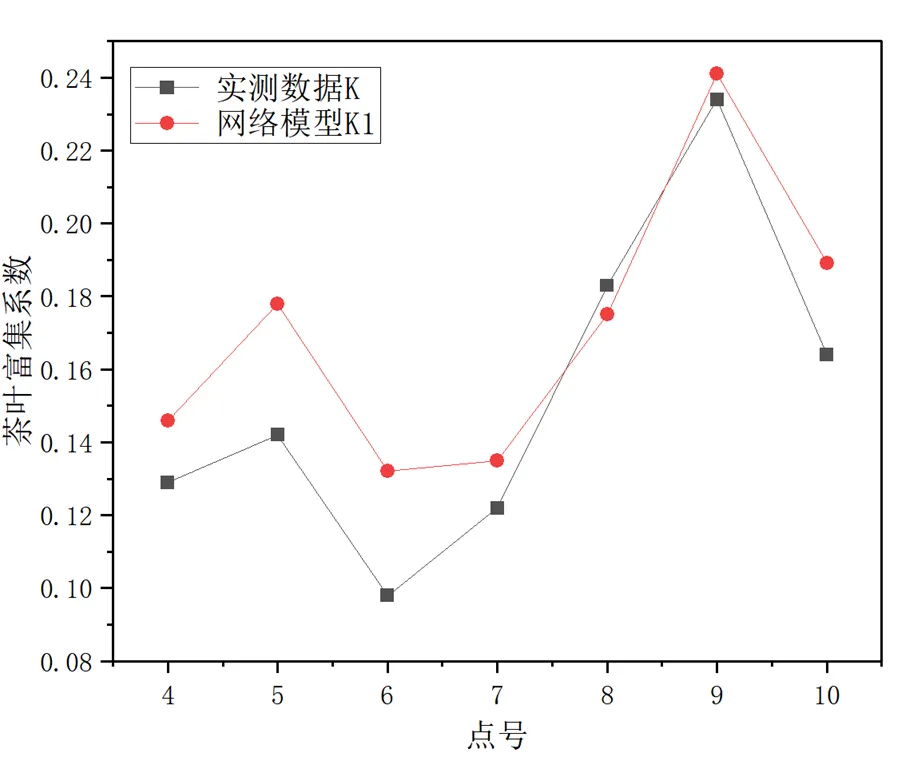
图4 实测数据与网络模型折线对比图
神经网络与传统回归方程在后续研究中可结合运用,由于神经网络在进行计算时,常无法直观明了清楚每个数字运算过程,而是通过特点输入、输出以及特定隐藏层方式构建(周志华等,2004)。
在被证明模型可用后,通过采集少量的茶叶样品及少量的茶叶根系土样品建立模型,在知道该地区农用地土壤元素含量基础上,可将其作为对应茶叶Se元素仿真部分输出值进行计算,即可预测该年份当地农作物Se元素含量。
何国民. 2019. BP神经网络预测模型与回归模型预测效果比较研究[J]. 第十一届全国体育科学大会,
王锐,邓海,贾中民,等.2020.硒在土壤-农作物系统中的分布特征及富硒土壤阈值[J]. 环境科学,12
杨忠芳,汤奇峰,刘久臣.2020.湘鄂重金属高背景区1∶5万土地质量地球化学调查与风险评价报告[R]. 130-131,05
王锐,胡小兰,张永文.2020.重庆市主要农耕区土壤Cd生物有效性及影响因素[J]. 环境科学,04
闫以聪. 2007. 回归方程与神经网络在数值预测方面的对比研究综述[J]. 数理医学杂志,001
周志华. 2004.神经网络及其应用[M].北京: 清华大学出版社.
Bioavailability Prediction of Se Element Based on BP neural——Take Tea Se in Huangshajie Town as an Example
LI Chong GUO Jun YANG Peng-zhi CHEN Fang-wei MAO Xiong TANG Heng-jia
(Changsha Center for Comprehensive Natural Resources Survey, China Geological Survey, Changsha 410600)
Se content is an important index of tea quality. In order to predict Se content in tea, this paper took the Se element of tea in Huangshajie Tea Base of Yueyang County as the research object, established a tea Se prediction model based on BP neural network, and predicted the Se enrichment coefficient of tea in Huangshajie Tea Factory. Compared with the measured results, the research results show that the accuracy of the predicted results reaches 84.77%, which is in good agreement with the actual data. The modeling method can also be applied to the prediction of other elements in soil.
BP neural network; tea Se; bioavailability; model; Huangsha Street Town
X53
A
1006-0995(2022)04-0673-04
10.3969/j.issn.1006-0995.2022.04.025
2022-02-22
李聪(1995— ),男,湖北宜昌人,技术员,研究方向:地球化学土地质量
猜你喜欢
上海工运(2021年6期)2021-08-16
行政事业资产与财务(2020年17期)2020-10-09
绿色中国(2019年14期)2019-11-26
电子制作(2019年19期)2019-11-23
当代陕西(2019年9期)2019-05-20
电子制作(2019年24期)2019-02-23
特别健康(2018年2期)2018-07-14
青年时代(2018年5期)2018-03-31
重型机械(2016年1期)2016-03-01
中国音乐教育(2015年4期)2015-05-20
