
基于最小生成树改进K-means聚类的网络入侵检测技术
2022-02-04 08:45陈功平
重庆科技学院学报(自然科学版) 2022年6期
王 红 陈功平
(六安职业技术学院, 安徽 六安 237158)
0 前 言
计算机和互联网作为当下信息传递的主要工具,已经被广泛应用于各行各业中。全球范围内的计算机和便携式上网设备都通过互联网进行连接,这给我们带来便捷的同时,也带来了许多安全隐患。网络安全问题已逐渐成为人们重点关注的问题。网络安全具有机密性、完整性等特征,应对网络攻击行为进行识别和检测[1]。网络入侵一般会留下痕迹,但具有一定的隐藏性,需要经过信息处理才能被识别[2]。现有的网络入侵检测技术需要对聚类数目和聚类中心进行人工设定,容易造成误差[3-4]。因此,本次研究利用最小生成树对K-means聚类算法进行改进,设计了一种新型网络入侵检测技术。
1.1 数据预处理
网络入侵数据一般混在正常数据中,若要挖掘出入侵数据,就需要使用聚类算法对数据进行预处理[5-6]。K-means是一种典型的聚类算法,其迭代基础是聚类中心,需要提前确定聚类数量和聚类中心位置,得到的结果往往受人为因素的影响较大,因此本次研究利用最小生成树改进 K-means聚类算法。
K-means聚类算法一般通过评价函数来判断簇之间能否合并或聚类。评价函数如式(1)所示:
(1)
式中:I—— 评价函数;
J—— 聚类解的常用目标函数;
n—— 簇的数量。
基于最小生成树改进的K-means聚类算法中,数据对象的簇数量是提前给定的,利用经典的Prim算法得到一棵最小生成树,将其划分为若干个部分,并把每个部分看成一个簇[7]。因此,根据经验随机给出的簇数量会在很大程度上影响聚类结果。
在最小生成树的改进机理下,对操作数据组成的集合进行处理,集合数量为m-1。通过距离计算,把树分裂成m棵子树,并将其看作独立的簇,选择包含较多元素的簇作为开始节点[8-9]。本次研究基于密度进行聚类划分,不同密度的聚类筛选过程如图1所示。
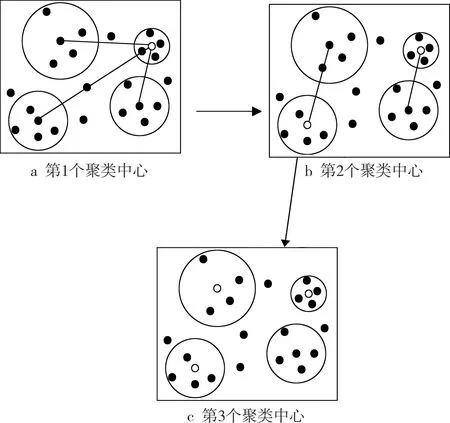
图1 不同密度的聚类筛选过程
图1a中的圆形中心点表示4个高密度点的分布情况,其中空心点表示密度最小,可以将其作为第1个聚类中心;在筛选过程中,将距离中心点最远的高密度点作为第2个聚类中心,即图1b中增加的空心点;根据不同的筛选规则,得到第3个聚类中心,即图1c中增加的空心点[10-12]。基于最小生成树改进的K-means聚类算法中,不同高密度点之间的距离应尽可能远。通过预处理得到的有效聚类数据集对入侵结果的影响很大,若要保证入侵检测结果的准确性,就要消除数据冗余。
1.2 入侵检测模型设计
通过上述聚类分析法划分网络行为数据,并进行数据挖掘,以实现网络入侵检测[13]。网络入侵检测模型示意图如图2所示。
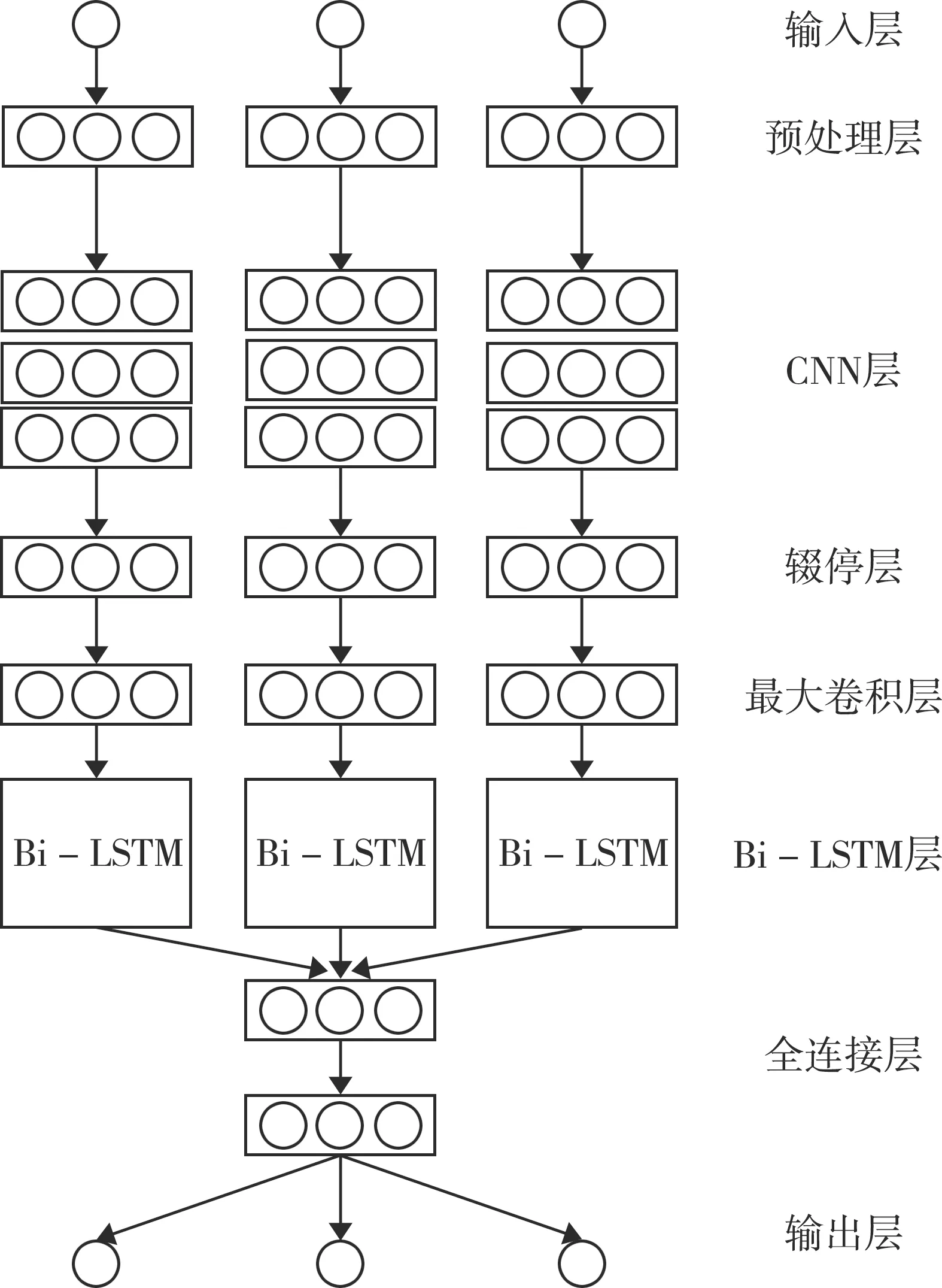
图2 网络入侵检测模型示意图
在网络入侵检测模型中,对字符型特征数据进行编码,将其转化为数值型数据,以消除字符之间的差异性,如表1所示。
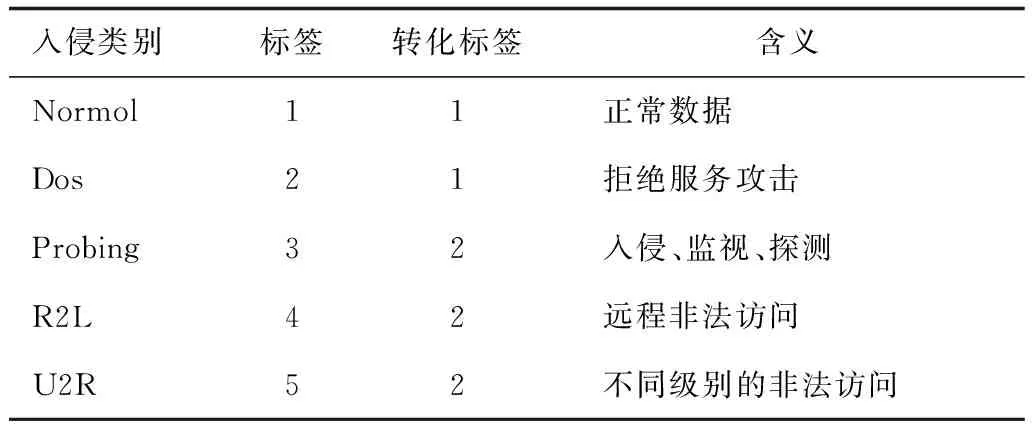
表1 字符型特征数值的转换
为了保证网络入侵检测模型的稳定性和可靠性,应提升模型泛化能力,以抑制过度拟合现象,网络入侵检测流程如图3所示。

图3 网络入侵检测流程
2 实验结果分析
2.1 实验准备
实验环境为Windows 10系统,选择Python语言进行代码编写。网络数据一般为多维度数据,应在优化过程中以距离为基础,使用数值型数据集。采用的数据集包括Iris数据集、Wine数据集和4k2_far数据集,共计612条数据。数据集特征说明如表2所示。

表2 数据集特征说明
将基于最小生成树改进K-means聚类的网络入侵检测技术与基于K-means聚类的网络入侵检测技术进行对比分析。选取聚类纯度作为聚类有效性指标,聚类纯度的计算如式(2)所示:
(2)
式中:Pc—— 聚类纯度;
N—— 数据总量;
K—— 聚类数量;
Ck—— 任意一个聚类中的对象数量。
一般情况下,Pc的取值范围为[0,1],Pc越大,聚类效果越好。实验参数说明如表3所示。

表3 实验参数说明
2.2 聚类结果对比分析
分别使用基于最小生成树改进K-means聚类的网络入侵检测技术和基于K-means聚类的网络入侵检测技术进行对比测试,聚类结果如图4和图5所示。
由图4和图5可知,相较于基于K-means聚类的网络入侵检测技术,基于最小生成树改进K-means聚类的网络入侵检测技术的数据分布更均匀,不同数据库之间的分布差异更明显,与实际情况相符。
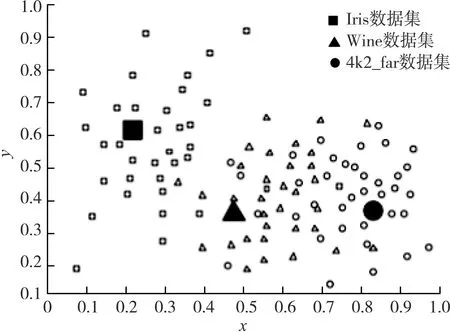
图4 基于最小生成树改进K-means聚类的网络入侵检测技术的聚类结果
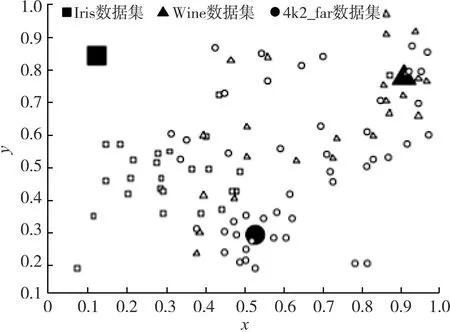
图5 基于K-means聚类的网络入侵检测技术的聚类结果
2.3 性能评估分析
采用检测率和误报率等指标进行性能评估,检测率的计算如式(3)所示:
(3)
式中:DR—— 检测率;
Nad—— 检测到的异常数量;
Nta—— 实际异常数量。
误报率的计算如式(4)所示:
(4)
式中:FR—— 误报率;
NM—— 被误判为异常的数量;
Nnr—— 实际正常数量。
检测率越大,误报率越小,说明技术性能越好。入侵检测评估指标结果如表4所示。
由表4可知,基于最小生成树改进K-means聚类的网络入侵检测技术的检测率为70%,误报率为0.472%;基于K-means聚类的网络入侵检测技术的检测率为44%,误报率为0.615%。因此,基于最小生成树改进K-means聚类的网络入侵检测技术的性能更优,检测效果更好。
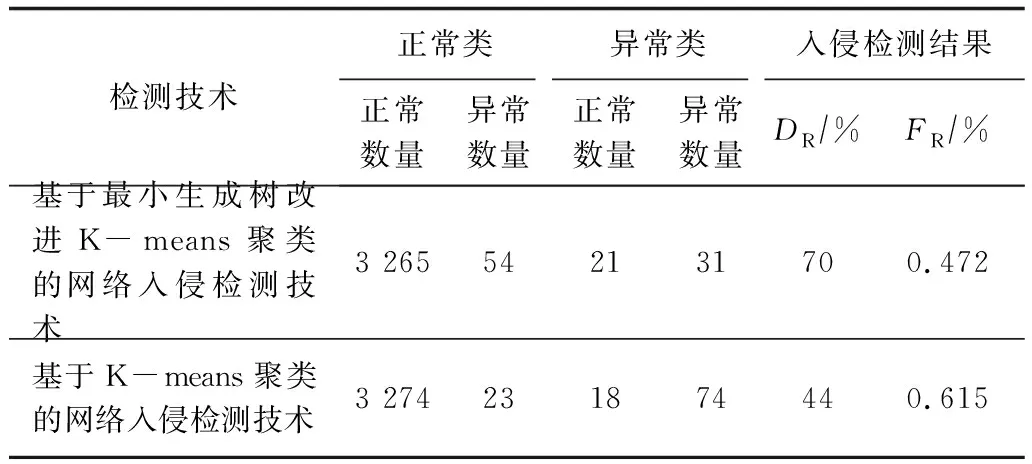
表4 入侵检测评估指标结果
3 结 语
本次研究从网络入侵检测技术存在的问题入手,利用最小生成树改进K-means聚类算法,设计了一种新型网络入侵检测技术。利用最小生成树改进K-means聚类算法,对入侵检测数据进行预处理,设计不同密度的聚类筛选过程,去除冗余数据。构建网络入侵检测模型,将字符型特征转化为数值型数据,优化入侵检测流程,以实现网络入侵检测。实验结果表明,与传统网络入侵检测技术相比,本技术的性能更优,检测效果更好。
猜你喜欢
黑龙江工业学院学报(综合版)(2022年7期)2022-08-29
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
数学小灵通(1-2年级)(2021年10期)2021-11-05
煤气与热力(2021年6期)2021-07-28
铁道通信信号(2019年6期)2019-10-08
小学生学习指导(低年级)(2019年3期)2019-04-22
雷达学报(2017年6期)2017-03-26
小猕猴智力画刊(2016年6期)2016-05-14
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
