
基于语音识别的智能对话系统的研究与实现
2022-02-09 03:25张浩华李哓慧王爱利刘凡杨程骞阁
沈阳师范大学学报(自然科学版) 2022年5期
张浩华, 李哓慧, 王爱利, 刘凡杨, 柴 欣, 程骞阁
(沈阳师范大学 物理科学与技术学院, 沈阳 110034)
0 引 言
古往今来,人类社会不断变化,科学技术也在不断更新。现代科学技术的发展,推动着人类经济、社会生活等的方方面面。在这种时代背景下,机器人系统应运而生。人们对机器人系统本质的了解逐渐加深,促使它开始不断地渗入到人类的生产生活中去。据此,人们发展创造了各种各样不同形态的智能系统。智能语音系统的出现促进了学生的知识学习。通过语音识别,智能系统会根据关键词回答出正确答案,也可以根据关键词播放对应的文章、歌曲。它可以应用在教育培训机构或者学校的教学上,也可致力于科普知识的宣传。智能机器人系统的应用与研发在近年来形成了非常火爆的趋势,人机交互的真正实现离不开语音识别技术的快速发展[1]。
1 语音识别基本理论
1.1 国内外现状
20世纪50年代,世界各国开始研究简单的英文数字识别内容;70年代,语音识别理论及算法大规模涌现;到80年代,研究者们采用统计分析的方法研究连续语音识别,研究重点转移到了词汇量较大的语音上。在我国,20世纪50年代末有研究者采用电子管电路对英文中的元音字母进行识别。70年代,中国开始进行计算机语音识别的研究。90年代,清华大学和中科院自动化所等单位在汉语听写机原理样机的研究方面取得了重要成果。21世纪,深度学习的出现极大促进了语音识别技术的发展[2]。
1.2 基本原理
语音识别[3],原理是接收语音信号,并将语音信号转化为文字,或者对其进行查询的操作[4]。按照识别对象的不同,它可以分为孤立词、连接词和连续语音识别等;根据针对的发音人,能够划分为特定人语音识别和非特定人语音识别[5]。非特定人语音识别系统更适合生活的实际需求。语音识别包括以下几部分:提取与处理语音特征、对语音进行降噪、建立语言模型、声学模型训练[6]。
1.3 主流算法
在语音识别技术常用的方法中,随机模型法包括几种主流算法,一般主要有动态时间规整方法、矢量量化方法、隐马尔可夫模型方法、人工神经网络[7]方法和支持向量机等语音识别方法[8]。
动态时间规整算法可以比较二者之间相似的范围[9]。此方法计算起来比较复杂,但方法比较简单,识别语音较为准确。它不容易将各种知识应用到算法中去。
矢量量化是对信号进行压缩,所需要训练的数据较少,所用存储空间也较小。它被用在词汇较少的情况中。但是,这种算法在很多性能上都没有优于基于参数模型的隐马尔可夫模型的方法。
隐马尔可夫模型是一种使用概率的统计模型,广泛应用于信号处理、语音识别、行为识别等应用领域。Viterbi算法被用于寻找观测时间序列的隐含状态序列,尤其在隐马尔可夫模型中[10]。此种算法可以被用于词汇量较多的情况和系统中,缺点是需要占用较大存储空间,但识别率却高出许多。
2 语音识别算法
Viterbi算法可以帮助找到问题解决的最优路径,计算量也比同样功能的算法更小。它将全局最优的方法展开到局部最优,很好地解决了全局的问题。它在保证最优解的情况下,序列中的基于非线性的时间对准和针对词语边界的检测问题也得到很好地解决。由此,该算法成为语音识别中常被采用的算法。
输入:模型λ=(A,B,Π)和观测O=(o1,o2,…,oT)
1)初始化
2)递推,对t=2,3,…,T
3)终止
4)最优路径回溯,对t=T-1,T-2,…,1

求得最优路径
3 语音识别算法的实现
3.1 系统总体设计
本系统主要采用micro:bit主控板和IObit 2.0扩展板为主架构,与语音识别模块相连接,采用语音识别芯片LD3320,通过语音识别获取控制指令[11]。同时搭配MP3模块及腔体小喇叭,实现总体搭建,整体系统框图如图1所示。本系统通过添加词组,对用户的言语进行识别并比对,识别完成后,相应地播放对应的音频。本设计有较强的灵活性。

图1 系统框图
3.2 系统硬件设计
3.2.1 micro:bit主板
micro:bit是基于微软公司的开源平台编程经验工具包,是一台微型计算机[12]。开发板集成三合一传感器芯片,同时兼具加速度计、磁力计和陀螺仪的功能,可以与手机APP进行蓝牙通信;它还自带microUSB供电接口,也可外接电池盒供电,实物如图2所示。本系统选取micro:bit主板,控制其他模块的功能,它具有较为全面的功能和易于编程的特点[13]。

图2 实物图
3.2.2 IO bit 2.0扩展板
IO bit是一款支持micro:bit的IO口引出扩展板。它可以引出micro:bit上的所有输入/输出资源,同时自带蜂鸣器开关,通过跳线帽的自由切换,实现对P0引脚的连接与释放。此扩展板既支持3V电压,也支持5 V电压,可连接多种传感器。扩展板增加了较为丰富的传感器功能模块,满足设计的多种需求。
3.2.3 语音识别模块
语音识别模块选取了适合的语音识别算法应用于芯片,它可以通过语音唤醒来制作智能系统的部分。通过两线式串行总线识别语句、获取结果,发送和接收数据,实现人类和机器的交互。当断电时,它可以保存其中的数据,模块可以添加高达50条的识别语句,每条语句的汉字不能超过10个。嵌入LD3320芯片的语音识别模块,可以完成识别语音和声音控制的功能[14]。针对非特定人的语音识别技术ASR[15]是以关键词语列表为基础的一种匹配识别算法。它的本质在于声音特征提取完毕后,寻找匹配度最高的语句。输入到语音芯片的声音要与关键词进行对比逐个打分。同时,它有以下3种识别模式。
循环检测模式:系统会不断检测听到的语音并识别。
口令检测模式:识别到口令时,蜂鸣器响一声,之后开始识别,每唤醒一次识别一次。
按钮检测模式:外界语音传输到系统主控中心,语音识别芯片会开始计时,在固定的时间段内,外界发出对应的词汇语音。计时结束后,需要重新触发按键继续识别[16]。模块原理如图3所示。
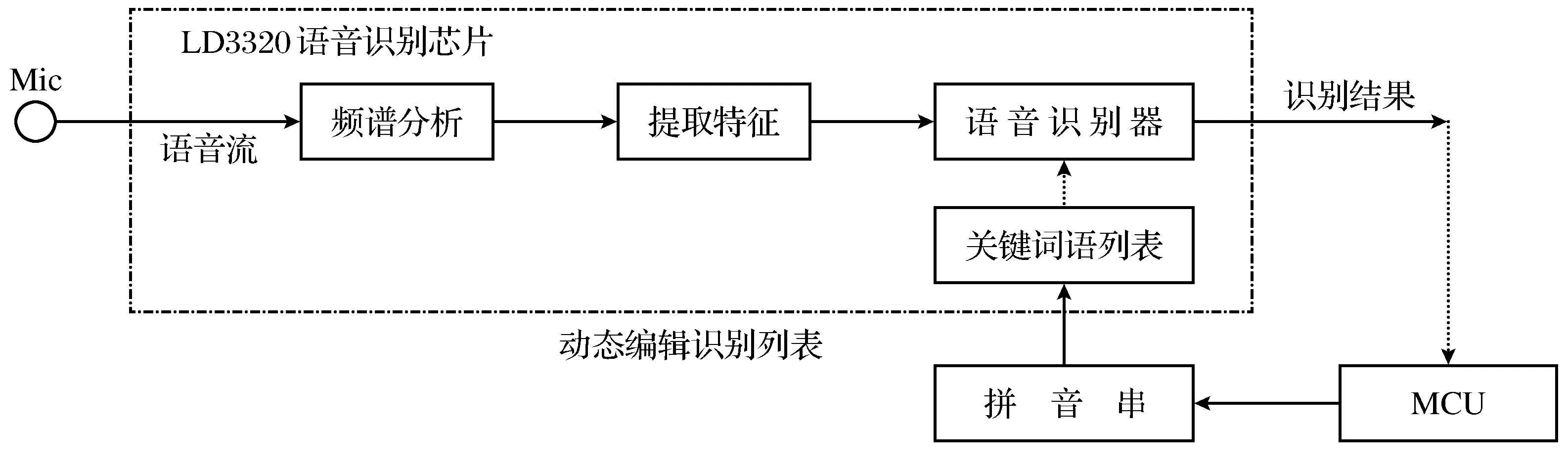
图3 模块原理图
3.2.4 MP3-TF-16P模块
MP3模块提供串口,直接采用微处理器对不同格式的音频解码。根据编码方式及编码过程,会从存储卡中自动寻找到对应格式的音频文件,此时,MP3模块对调出的文件解码,播放对应的语音文件[17]。此模块在上层可以完成音乐播放的指令和音乐播放的形式选择,省去下层烦琐的操作,可靠性得以提升。它支持多种不同的采样率,让音乐选取更加多样。同时,它可以通过不同的方式控制音乐播放,有简单的输入输出、按键开关控制和串口控制模式等。文件系统中最多包含100个文件夹,每个文件夹有255首曲目。片上系统(system on chip, SoC)方案,开发难度和成本较低,因而被选用,方案如图4所示。同时,选用了将内存、USB等接口和驱动电路整合在一起的集成电路MCU,利用aDSP进行解码,硬解码的方式使得整个系统更加稳定可靠。

图4 MP3模块方案图
3.3 系统软件设计
3.3.1 语音识别模块主程序设计
语音模块要进行初始化设置,添加词语列表,同时设置变量作为识别结果。接通电源时,微控制器向语音识别芯片写入系列词语,然后控制芯片循环识别听到的声音信号[18]。本系统通过检测人们发出的声音,判断识别词语是否匹配,并播放对应文件夹的音频。语音识别流程如图5所示。

图5 语音识别流程图
3.3.2 MP3-TF-16P模块主程序设计
MP3-TF-16P模块与语音识别模块配合使用,实现问答功能。MP3-TF-16P模块的部分代码如下:
basic.forever(function(){
value=Asr.Asr_Result()
serial.writeNumber(value)
if(value==1){
dfplayer.setTracking(1, dfplayer.yesOrNot.type1)
}
basic.pause(2000)
})
3.4 系统性能测试
语音识别算法有很多种,本文将算法传输到芯片实现语音识别获得了较大的完成度。本系统应用语音识别算法,结合micro:bit主板、扩展板,通过对语音识别模块和MP3-TF-16P模块进行设计编码,很好地实现了离线语音识别的功能。
4 结 语
本文分别从语音识别理论的简要概述、语音识别算法的对比以及其在硬件系统上的实现几个方面介绍了基于语音识别的智能对话系统,通过语音识别算法嵌入芯片,结合使用语音识别模块和MP3-TF-16P模块,实现了问答功能和人机交互,为算法在硬件的实现提供了一定参考。语音识别算法在智能音箱、智能家居等人工智能领域被广泛应用,对于不同的智能系统都有很好的借鉴作用。本次设计的智能对话系统,具有较强的实用性和推广性,可以在此基础上继续改进。
