
云边协同下基于多智能体强化学习的任务卸载策略
2022-02-17 13:42刘雨晖陈宁江何子琦
广西大学学报(自然科学版) 2022年6期
刘雨晖, 陈宁江,2,3*, 何子琦
(1.广西大学 计算机与电子信息学院, 广西 南宁 530004;2.广西智能数字服务工程技术研究中心, 广西 南宁 530004;3.广西高校并行分布与智能计算重点实验室, 广西 南宁 530004)
0 引言
基于Cybertwin的云边协同网络概念的提出,旨在将物理对象映射到虚拟网络空间进行实时配置从而优化业务流程,为设计支持海量传感器数据采集与处理的万物互联架构以及构建整个物联网信息系统的“数字孪生”提供相应的技术支撑[1]。由于智能移动设备自身算力资源有限,因此需要通过Cybertwin服务代理将复杂终端任务卸载到资源丰富的核心云、边缘云或者空闲设备上执行,在满足用户对网络服务质量(quality of service,QoS)的高要求的同时提高资源利用率。
现有基于近似优化算法的任务卸载方法通常是根据优化问题建立对应的数学规划模型,运用如贪心算法[2]、拉格朗日松弛[3]、李雅普诺夫(Lyapunov)优化[4]和博弈论(game theory)[5]等算法在可接受的时间内求得一个近似最优解,但对于求解动态变化的大规模计算系统问题却难以抉择。由于其解空间的复杂性,因此通常采用单智能体深度强化学习算法求解最佳策略,同时也引出以下问题:第一,单智能体算法解决的是环境中存在单一智能体的情况(或者多个智能体可以转化为一个智能体的决策),缺少考虑多智能体的联合行为对环境稳定性影响而导致效果不佳[6];第二,大规模智能移动设备的接入导致每个智能体的策略随着训练的进行都应发生变化,只考虑单智能体自身状态变化而没有精确完整的环境信息会导致经验重放(experience replay)机制失效[7]。
因此,本文中将针对云边协同环境下资源综合利用困难以及单智能体强化学习算法不能满足大规模终端协作任务卸载等问题,设计基于Cybertwin的云边协同计算系统模型(Cybertwin-based cloud-edge collaborative computing system model,CCECM),并构建基于多智能体双延迟深度确定性策略梯度算法(multi-agent twin delayed deep deterministic policy gradient algorithm,MATD3)的协作任务卸载与资源分配联合优化方法,从而缓解了海量终端协同卸载场景下单智能体强化学习算法效果不佳的问题,进而提高任务处理效率与用户体验质量。
1 系统模型
本节将进一步从协同卸载模式、业务传输模型和综合时延与能耗的卸载成本模型等角度构建基于Cybertwin的云边协同计算系统模型(CCECM),从云边端多角度刻画任务卸载模型,更准确地表征任务卸载所需总成本。基于Cybertwin的云边协同计算系统架构如图1所示,分成以下3层:由工业物联网制造设备、无人机和自动驾驶运输车等智能设备接入的智能移动设备层(smart mobile device, SMD),配置Cybertwin服务代理的边缘云层(edge cloud, EC)以及具有高性能数据中心的核心云层(core cloud,CC)。
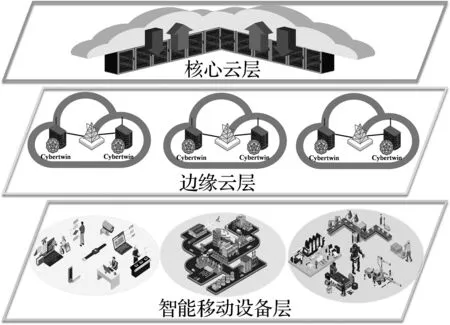
图1 基于Cybertwin的云边协同计算系统架构Fig.1 Cybertwin-based cloud-edge collaborative computing system architecture
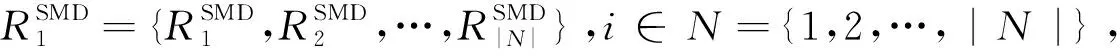
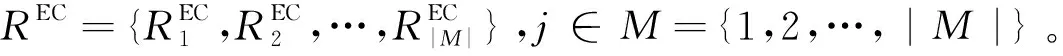
核心云层由多个大型云数据中心组成,依托大容量、高速、低时延的专用数据传输网络为任务执行提供充足的算力资源,因此,一般认为核心云的服务能力能够满足所有用户设备的服务需求,可以将部分任务卸载到核心云的数据中心上,以缓解边缘云的流量压力。
1.1 协同卸载模式

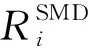
(1)
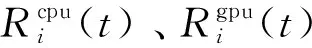
(2)
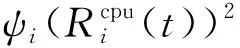
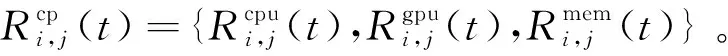
(3)
(4)
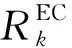
(5)
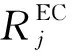
(6)
(7)
④ 智能移动设备卸载任务到核心云的云数据中心:由于核心云的云数据中心拥有海量算力与存储资源,因此当设备卸载任务到核心云时通常忽略在核心云上的执行时间和计算能耗[12],总时延可以表示为
(8)
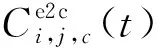
(9)
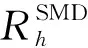
(10)
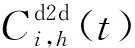
(11)
(12)
1.2 业务传输模型
(13)
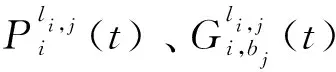
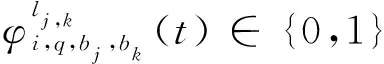
(14)
(15)
(16)
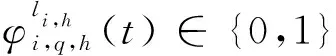
(17)
1.3 综合时延与能耗的卸载成本模型
① 任务卸载的总时延取决于任务Γi(t)完成所选择的协同卸载模式所需要的时间,表示为
(18)
② 任务卸载的总能耗定义为任务Γi(t)完成所选择的协同卸载模式而产生的能量消耗,表示为
(19)
Fi(t)=αiTi(t)+βiEi(t),
(20)
式中αi、βi分别为任务卸载总时延和总能耗的权重系数,通过求解上述权重系数来满足延迟敏感型和延迟容忍型任务的服务质量要求,其满足的约束条件如下:
αi+βi=1, 0≤αi≤1,0≤βi≤1。
(21)
2 基于多智能体强化学习的任务卸载与资源分配联合优化方法
本节首先综合多维资源约束条件制定任务卸载与资源分配的联合优化问题,然后将该问题转化为成多智能体合作的马尔可夫博弈过程(Markov game process,MGP),最后提出基于多智能体双延迟深度确定性策略梯度(MATD3)的深度强化学习算法求解。
2.1 优化问题描述
(22)
通过联合优化智能设备协同任务卸载模式X(t)、频谱资源φl(t)与算力资源Rcp(t)等异构资源分配,实现最小化系统总成本,并尽量提高任务执行的完成率,则该组合优化问题的形式化定义如下:
(23)
C1表示在时隙t可供智能移动设备选择的协同卸载模式决策变量;C2描述了云边协同网络中切片频谱资源分配的指示变量;C3指出智能移动设备只能选择一种卸载方式来完成计算任务;C4、C5表示边缘云上频谱资源与异构算力资源的分配不能超过其资源总量;C6描述了终端设备分配自身算力资源的限制;C7表示计算任务执行完成总时间必须满足其对时延的最低QoS需求,确保不超过最大容忍时延;C8规定在终端设备本地执行任务产生的总能耗不能超过该设备的可用剩余电量,为任务顺利执行提供保证。
2.2 算法描述及其实现
鉴于任务卸载与资源分配联合优化问题P1是复杂而连续的动作空间问题,本文设计了一个基于多智能体双延迟深度确定性策略梯度算法来求解该问题。
2.2.1 多智能体合作的马尔可夫博弈过程
本文将式(23)中表述的NP难问题建模为多智能体场景[14]中的马尔可夫博弈过程,形式化描述为Ω={N,S,A,P,R,η}。N={1,2,…,|N|}表示智能移动设备集合,代表设备的Cybertwin是作为训练学习的智能体;状态空间是全部Cybertwin智能体联合环境的状态集S={s1,s2,…,sK};动作空间A=A1×A2×…×AN为多智能体联合动作集合;状态转移概率函数P(s(t+1)|s(t),a1(t),a2(t),…,aN(t))→[0,1],∀s(t)∈S,ai(t)∈Ai,i∈N;联合奖励函数值集合R={R1,R2,…,RN}反馈了任务卸载与资源分配联合优化决策的合理性与有效性,其中单个智能体的奖励函数表示为ri=Ai×S→R;η是关于时间的折扣因子。
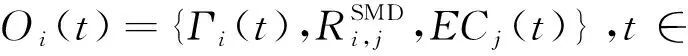
(24)
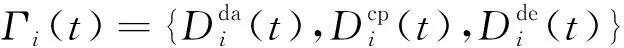
s(t)={O1(t),O2(t),…,ON(t)},∀s(t)∈S,t∈[0,+∞)。
(25)
② 动作空间:在时隙t观察当前环境状态s(t)∈S后,Cybertwin智能体i根据已有策略为当前任务选择一个合适的行为动作,完成协同卸载模式,则每个Cybertwin智能体i的独立动作空间为
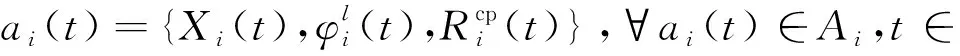
(26)
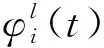
③ 奖励函数:在多智能体合作与竞争环境中,每个Agent可以通过分布式执行的方式做出相应决策,以最大化联合环境中的奖励回报,设计准确有效的奖励函数有利于多智能体快速学习最优策略[15]。根据时隙t观察到环境状态来为计算任务选择卸载动作,则单个Cybertwin智能体i的奖励函数定义为
ri(t)=-(αiTi(t)+βiEi(t))+ε(t),∀ri(t)∈Ri,t∈[0,+∞),
(27)
式中:ri(t)表示在智能体i在时隙t执行卸载动作后立即获得的奖励;ε(t)表示时隙t边缘云中每个Cybertwin智能体的任务执行失效惩罚。系统奖励是由所有智能体收到的奖励总和,表述如下:
(28)
2.2.2 基于MATD3的深度强化学习算法的实现
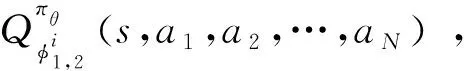
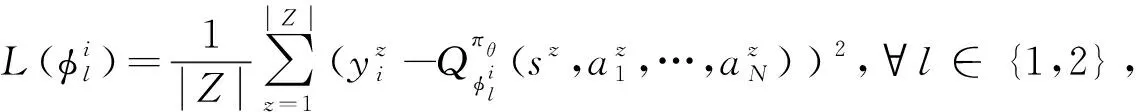
(29)
式中:Z表示从经验重放缓冲区D中取出的样本数据集合;|Z|是样本数量;z是样本数据的索引;yi是目标函数值;λ为折扣因子;μ是添加的动作噪声。Cybertwin智能体i的确定性策略πθi梯度的更新过程表示为
(30)
本文提出的MATD3算法主要分成2个重要步骤:收集环境状态数据和目标策略网络训练,详细的算法步骤如下:
Step1:初始化每个Cybertwin智能体中Actor网络的策略参数θ、Critic网络的评价参数φ1,φ2以及清空经验重放缓冲区D,定义最大训练回合数Kmax和每个训练回合内的最大时间步长Tmax;
Step2:初始化剪切后的高斯噪声μ用于随机动作策略探索a(t)=πθ(O(t))+μ,系统内全部Cybertwin智能体将自身的部分观测值共同组合成云边端协同环境的初始状态s0;
Step3:每个Cybertwin智能体根据时隙t的确定性策略π选择1.1节中的任务协同卸载模式并获得相应回报,并把当前系统状态转移信息元组(s,a1,a2,…,aN,r1,r2,…,rN,s′)作为下一轮训练样本数据存储到经验重放缓冲区D中,此后系统环境转移到新状态s′;
Step4:接着每个Cybertwin智能体单独对经验重放缓冲区D的数据进行批量采样,在样本数据上利用损失函数(29)更新Critic网络的参数φ1,φ2并延迟d个时间步后采用梯度下降法求解,即采用式(30)更新Actor网络的策略参数θ,最后再对目标网络的相应参数进行软更新;
Step5:判断此时算法是否已经达到当前训练回合内的最大时间步长Tmax,若已经达到则跳转到Step 6执行,否则重新返回Step 3执行;
Step6:判断此时算法是否已经达到最大训练回合数Kmax,若是则结束算法并输出最优卸载策略,否则重新返回Step 2继续执行。
算法中Actor和Critic网络分别设计成拥有2层和3层隐藏层的全连接神经网络。根据文献[16]可知,对于隐藏层是由固定数目神经元构成的全连接网络,其反向传播算法的计算复杂度与输入维度和输出维度的乘积成正比。假设本文设计的场景下边缘云数量为M,每个边缘云服务范围内智能移动设备总数为Nm。Cybertwin智能体的Critic网络集中化训练的复杂度为O[M(Nm+M+Nm)]。而对于Actor网络,其分散式执行过程的计算复杂度为O[Nm(M+Nm)]。因此,本文所提出的MATD3算法的复杂度为O[Nm(M+Nm)]。
2.3 实验性能评估
实验的硬件环境:CPU为Intel Core i7-10700 KF、8核心、主频为3.8 GHz,内存为64 GB,显卡为RTX2070。操作系统为Windows 11,运行环境为Python 3.9与Pytorch 1.10。模拟云边协同系统环境所使用的主要参数见表1。
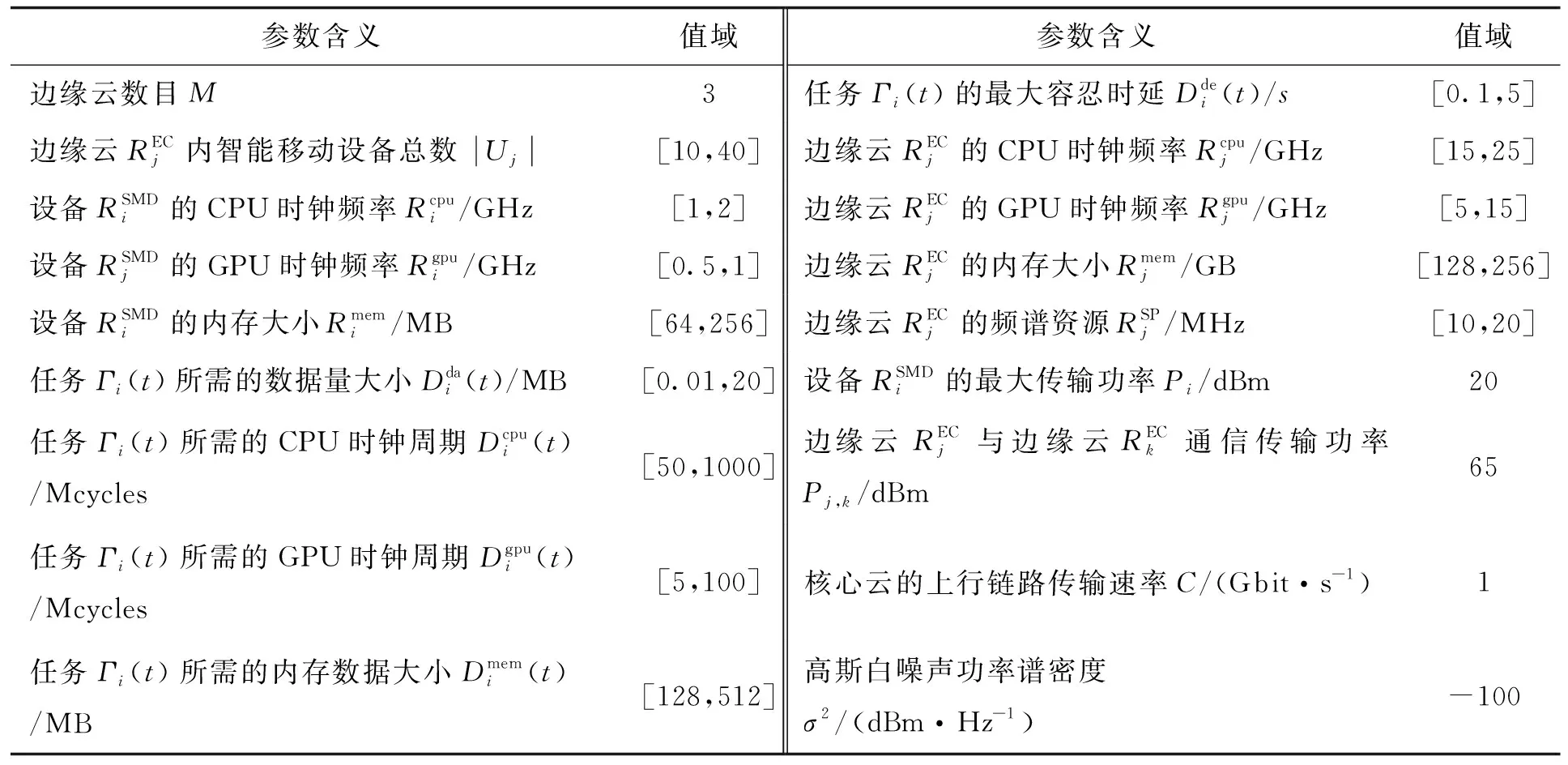
表1 系统仿真参数设置Tab 1 System simulation parameter setting
为了更直观地评估所提出的MATD3优化方案的性能,本文将其与以下5种基准算法进行比较:单智能体双延迟深度确定性策略梯度算法(TD3)[17]、单智能体深度确定性策略梯度算法(DDPG)[18]、贪心算法(Greedy)、随机卸载策略(randomly offloading algorithm,ROA)、本地计算(local processing,LP)。
MATD3、TD3、DDPG强化学习算法的平均奖励曲线如图2所示。从图中可见,这3种算法的平均奖励曲线随着训练回合的增加而逐渐收敛。在0~500个训练回合中,Cybertwin智能体的平均奖励较小并且随着训练回合的递增出现一定幅度的波动。这是因为在训练初期智能体只进行随机动作探索,经验重放缓冲区中样本数据较少,导致刚开始训练好的模型偏向过拟合状态,经过2 000个训练回合充分训练后3种强化学习算法均达到收敛状态。与其他2种单智能体基准算法相比,本文提出的MATD3算法收敛速度最快,经过1 500个训练回合后就已经收敛了,而且奖励波动范围较小,平均奖励值最高。
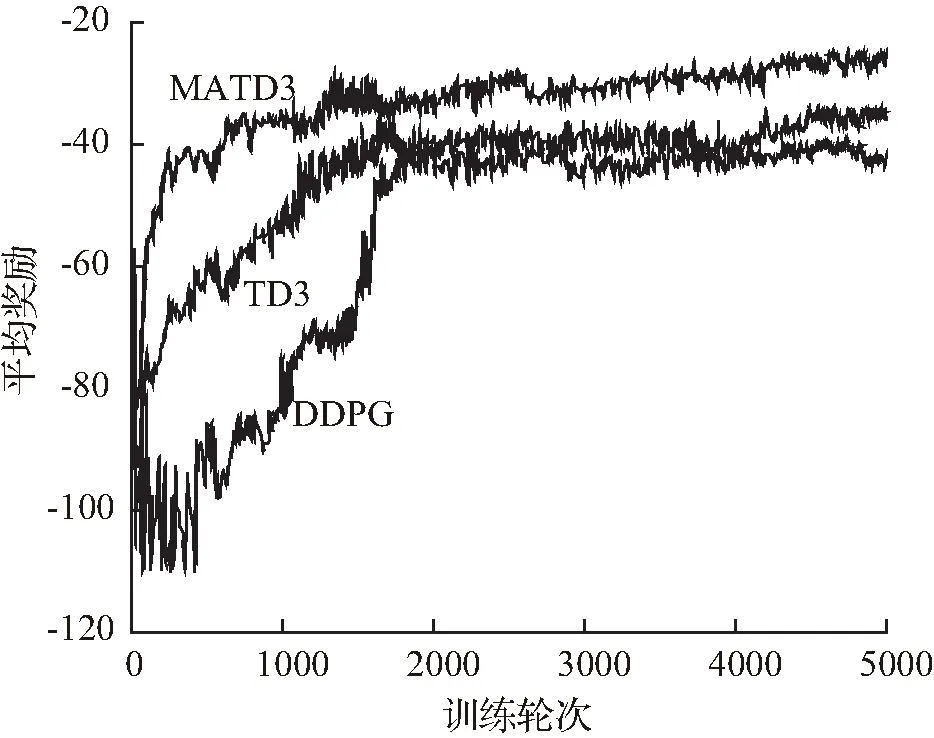
图2 MATD3、TD3、DDPG的平均奖励曲线Fig.2 Average reward curve for MATD3, TD3, and DDPG
图3(a)的结果显示系统平均成本随着智能移动设备数量的增加而逐渐增大的变化趋势,但当设备数越多时增长速度减慢。这是因为接入设备数的增加意味着边缘云内有限多维异构资源不能满足所有用户设备需求,部分设备只能选择在本地执行或者传输到核心云以执行更多的延迟敏感任务导致平均成本的增加,甚至部分任务因算力资源不足在时间到期后被丢弃。从图3(a)可以看出,随着设备数增加,本文提出的MATD3算法在降低平均成本方面优于其他5种算法。当智能移动设备数目为40时,MATD3与TD3、DDPG、Greedy、ROA和LP等算法对比分别降低了24.69%、25.61%、35.79%、43.51%和51.58%的平均成本。
由图3(b)可知随着任务数据大小的增加,平均成本起始增速较快,随后趋于平稳。因为通信传输时延与任务数据大小成正相关关系,任务数据增大代表传输时延成本的增加,进而增加了系统平均成本。当任务数据大小为20 Mbits时,MATD3算法与TD3、DDPG、Greedy、ROA和LP等算法相比分别减少了29.31%、32.78%、43.84%、54.44%和60.34%的平均成本。总的来说,在上述6种算法中,MATD3算法能够综合考虑将任务卸载到不同计算节点上的可行性,对最小化系统总成本和提高QoS实施策略优化,最终得到最低的平均成本。
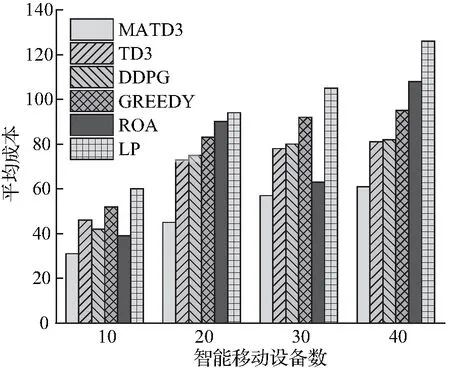
(a) 智能移动设备数对平均成本的影响
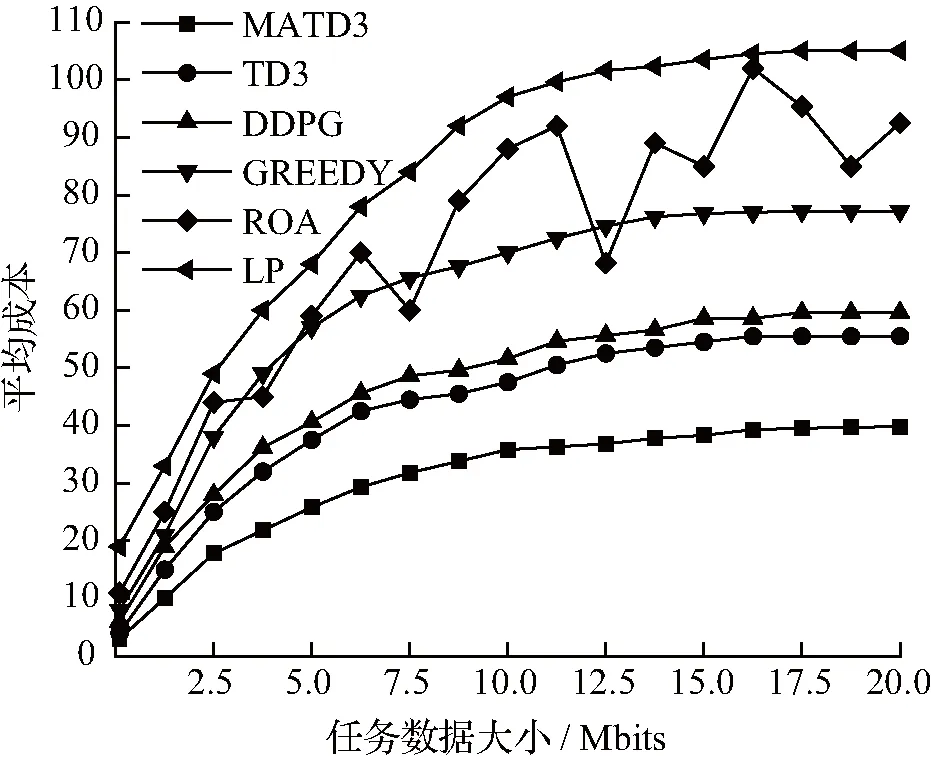
(b) 任务数据大小对平均成本的影响
接着,本文对这几种算法的任务卸载率进行比较,而本地计算(LP)算法只在设备本地执行任务,即该算法的任务卸载率为0,所以不在实验部分进行讨论。在图4(a)中,任务卸载率随着智能移动设备数的增加而降低。这是因为接入设备数的增加将生成更多的异质计算任务,越来越多没有被分配到计算节点执行的任务只能选择在本地完成。当接入设备数为40时,MATD3与TD3、DDPG、Greedy和ROA等算法相比分别提高了34.34%、39.13%、77.76%和95.12%的任务卸载率。
图4(b)对任务丢弃率与任务数据大小的关系进行分析。任务丢弃率反映了智能移动设备与计算节点之间通信服务质量以及算力资源的可用性等问题。由图4(b)可知,任务丢弃率是随着任务数据大小的增加而增加。在对比的6种算法中,MATD3算法的任务丢弃率最低,原因是所提出的MATD3优化方案能够根据任务的服务质量需求有效地综合利用终端设备、边缘云和核心云的空闲资源,从而保证整个网络可以处理尽可能多的业务。
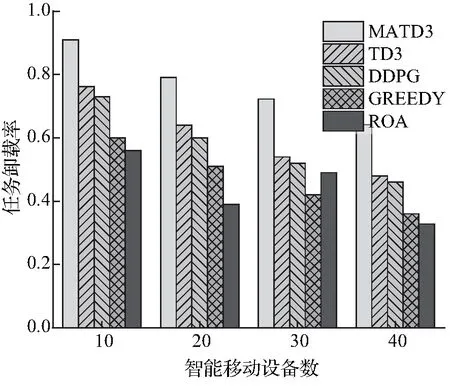
(a) 智能移动设备数对任务卸载率的影响
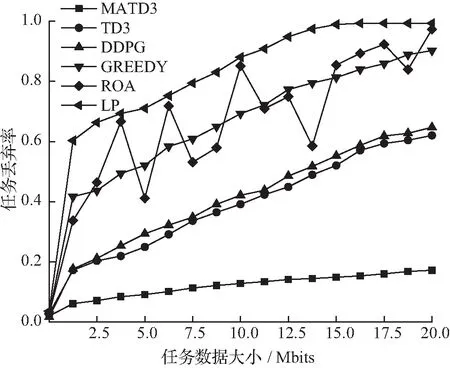
(b) 任务数据大小对任务丢弃率的影响
3 总结与展望
本文中设计了一个基于Cybertwin驱动的云边协同计算框架,能够高效完成任务卸载与多维异构资源联合分配优化配置。通过实验对比分析,在云边协同网络中使用本文提出的MATD3算法,能够最小化任务卸载总成本,提高了任务执行性能并减少任务丢弃率,有效保证了终端设备的用户体验质量。未来,我们将把区块链、联邦计算与Cybertwin智能服务相结合,为分布式跨云环境中的资源管理和用户设备隐私保护提供更加完善的解决方案。
猜你喜欢
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
通信电源技术(2020年8期)2020-07-21
汽车观察(2019年2期)2019-03-15
电子制作(2019年23期)2019-02-23
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
中国卫生(2016年5期)2016-11-12
