
基于可信列表的改进拜占庭容错算法
2022-02-19 10:24汤红波王领伟
计算机应用与软件 2022年2期
乔 康 汤红波 游 伟 王领伟
(解放军战略支援部队信息工程大学 河南 郑州 450053)
0 引 言
共识算法是区块链的核心技术之一[1],是确保所有节点(包括普通节点和处理交易的节点)彼此同步,并就交易的合法性和区块的上链达成一致的协议。迄今为止,研究者已就区块链的共识算法做了大量研究工作,提出了多种多样的共识算法[2~10],如工作量证明(PoW)[2]、权益证明(PoS)[3]、股份授权证明(DPOS)[4]和实用拜占庭容错(PBFT)[5]等。由于特别适合联盟链的应用场景,PBFT算法及其改进算法是目前最常用的联盟链共识算法[11]。
尽管采用PBFT算法后联盟链的共识效率得到极大提升,但PBFT算法仍然存在通信开销大的问题[12]。随着网络节点数目N的增加,其通信量将呈平方级O(N2)增长,当节点数目超过一定值后,由于网络带宽的限制,将造成通信瓶颈,进而导致PBFT算法性能的显著下降。
因此,为减少通信开销,许多研究在保证安全的前提下,以选举方式挑选少量节点参与共识[13]。Crain等[14]借鉴PoS算法思想对PBFT算法进行改进,提出DBFT算法,根据节点权益值来选举主节点和副本节点;Agarwal等[15]结合PoW算法,提出改进算法Elastico,由普通节点相互竞争当选;Chen等[16]则利用密码抽签协议,提出改进算法AlgoRand,随机选举共识节点; Copeland等[17]结合Raft算法,对PBFT算法进行改进,提出更简洁的Tangaroa算法。
通过选举少量共识节点将减少节点间通信次数,从而降低开销和时延。但是,现有算法仍存在以下不足,一是灵活性差,共识节点数目固定,节点身份提前确定,无法动态添加或删除;二是容错率低,系统的故障节点数量不得超过全网节点的1/3,导致容错率相对较低;三是资源耗费高,无法避免故障节点的存在,造成通信资源的浪费和算法耗时的增加。
针对上述不足,本文提出了一种基于可信列表的改进拜占庭容错算法(CPBFT),主要的改进包括:(1) 建立一个信用节点列表。该信用节点列表有两方面作用,一是将共识节点的参与方式由静态改进为动态,节点可动态进入或退出;二是支持通过投票选出信任节点,在投票周期内,网络中的所有参与节点均可进行投票,获得票数最多的前位节点组成一个信任节点列表,该列表将作为共识节点的候选列表。(2) 设计一种信用评价机制。该机制是共识节点选举的依循,包括信用值计算模型和节点选举策略。通过该机制,可从信用节点列表中,选举出可信的共识节点(主节点和副本节点)。可信的共识节点,将提升系统容错率,降低资源开销。(3) 简化算法流程。基于信用评价机制,确保了共识节点的可信度,由此将PBFT算法的三阶段协议简化为二阶段协议,进一步减少通信开销、降低算法时延。
1 实用拜占庭容错(PBFT)算法
为解决存在节点故障情况下的共识达成问题,1982年Lamport等提出了拜占庭容错算法(Byzantine Fault Tolerance,BFT)。但是,长期以来,BFT算法及其改进算法都存在复杂度过高的问题。直到1999年,Castro等[5]提出实用拜占庭容错算法(PBFT),将算法复杂度从指数级降到多项式级,使得拜占庭容错算法在实际应用中变得可行。PBFT算法可以在故障节点不超过节点总数1/3的情况下同时保证共识的安全性和灵活性[18]。PBFT算法的执行流程如图1所示,其包括请求过程、广播过程和响应过程三个过程。
(1) 请求过程。请求过程包括选主和请求两个步骤,首先通过轮换或者随机算法选择某个节点为主节点,然后由客户端向主节点发送请求消息〈〈REQUEST,operation,timestamp,client〉,σc〉,此后只要主节点不切换,就称为一个视图。
(2) 广播过程。主节点收集请求消息,经检查后向所有其他副本节点广播该请求消息。
(3) 响应过程。所有节点处理完请求后,将处理结果〈REPLY,view,timestamp,client,id_node,response〉返回客户端。客户端统计收到的处理结果,当接收到至少f+1个(f为可容忍的拜占庭节点数目)来自不同节点的相同结果时,该处理结果为最终结果。
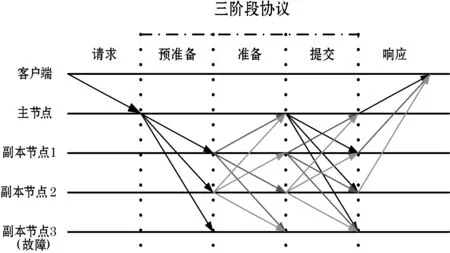
图1 实用拜占庭容错算法的执行流程
其中,主节点广播过程包括三个阶段,分别为预准备阶段、准备阶段和提交阶段。
① 预准备阶段。主节点首先为客户端的请求分配编号,然后向各副本节点发送预准备消息〈〈PRE-PREPARE,view,n,digest〉,σp,message〉,其中view是视图号,n是提案号,message是请求消息,digest是消息的数字摘要。
② 准备阶段。副本节点首先验证预准备消息的合法性,通过验证后向其他节点发送准备消息〈〈PREPARE,view,n,digest,id〉,σi〉,其中id为副本节点的身份证明。副本节点在发送准备消息的同时,也接收其他节点的准备消息。准备消息验证后,则被添加到消息日志中,当接收到至少2f个验证过的准备消息后,节点进入准备阶段。
③ 提交阶段。节点广播确认消息〈〈COMMIT,view,n,digest〉,σi〉,通知其他节点某个提案n在视图view中已处于准备阶段,当接收到至少2f+1个验证过的COMMIT消息后,说明提案通过。
2 算法设计
2.1 信任节点列表建立
如图2中第一部分所示,在投票周期T内,区块链网络中的所有节点i均可参与投票,通过统计各节点得票数目ni,获得票数最多的前h位节点,排序组成一个列表作为信用节点列表。投票提案vote由系统每隔一段时间发起,首先,投票主节点向普通投票节点广播投票准备消息PREPAREvote;其次,投票节点自由投票并将投票结果RESULTvote回复主节点;最后,由投票主节点统计得票结果并广播给所有节点。信任节点列表的建立主要依赖投票制度,其前提假设为区块链网络中的大部分节点是合法节点。每个节点拥有一次投票机会,可选择自己,也可选择其他节点。信用节点列表将作为候选集,供下一步共识节点选举使用,如图2中第二部分所示。通过建立信用节点列表,将共识节点的参与方式由静态改进为动态,节点可动态进入或退出,提高了节点的灵活性。
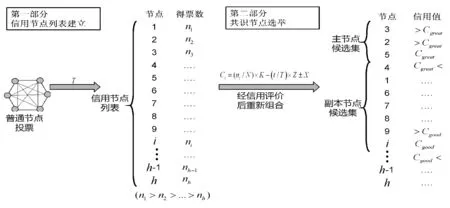
图2 基于信用列表的共识节点选举
2.2 节点信用评价机制
为从信用节点列表中选择出高可信度的共识节点,本文设计了一种节点信用评价机制,该机制包括了信用值计算模型和共识节点选举策略。
2.2.1信用值计算模型
首先,对节点信用值计算进行建模,信用值的计算分为两种情况:一是信用奖励,如式(1)所示;二是信用惩罚,如式(2)所示。
Ci=(ni/N)×K-(t/T)×Z+X
(1)
Ci=(ni/N)×K-(t/T)×Z-X
(2)
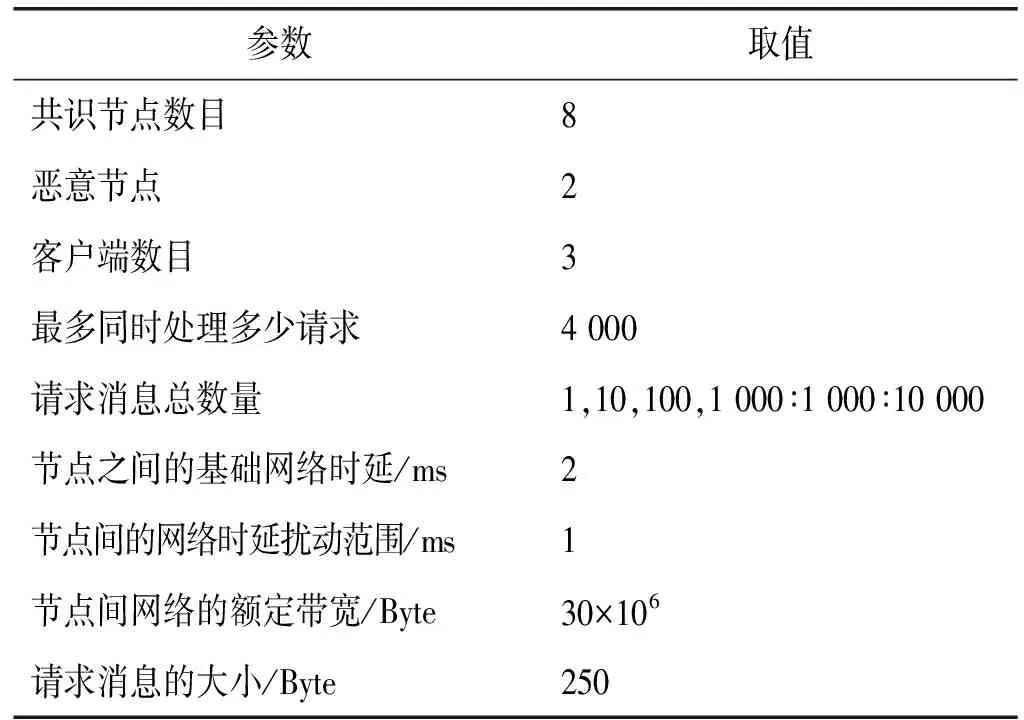
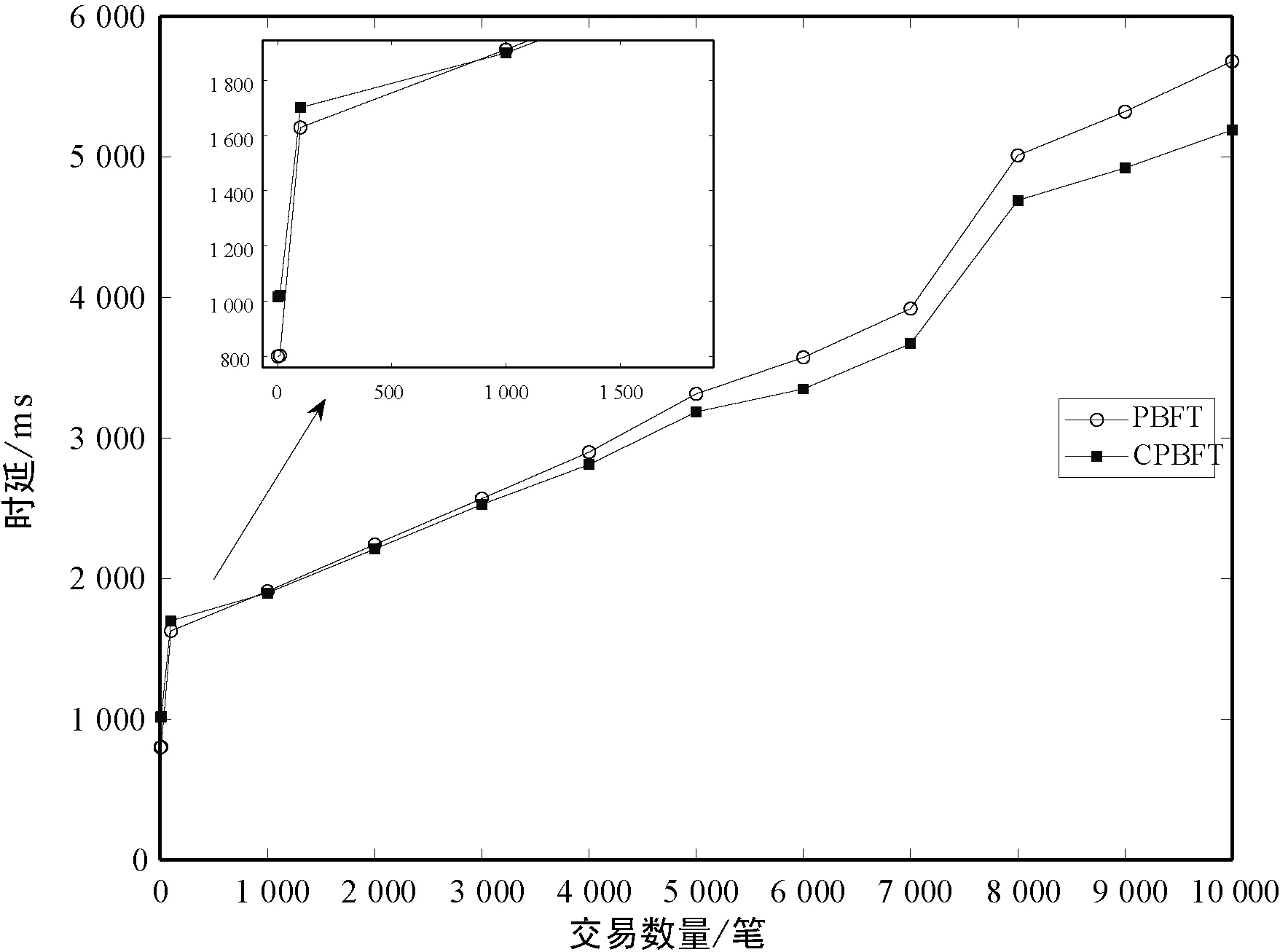
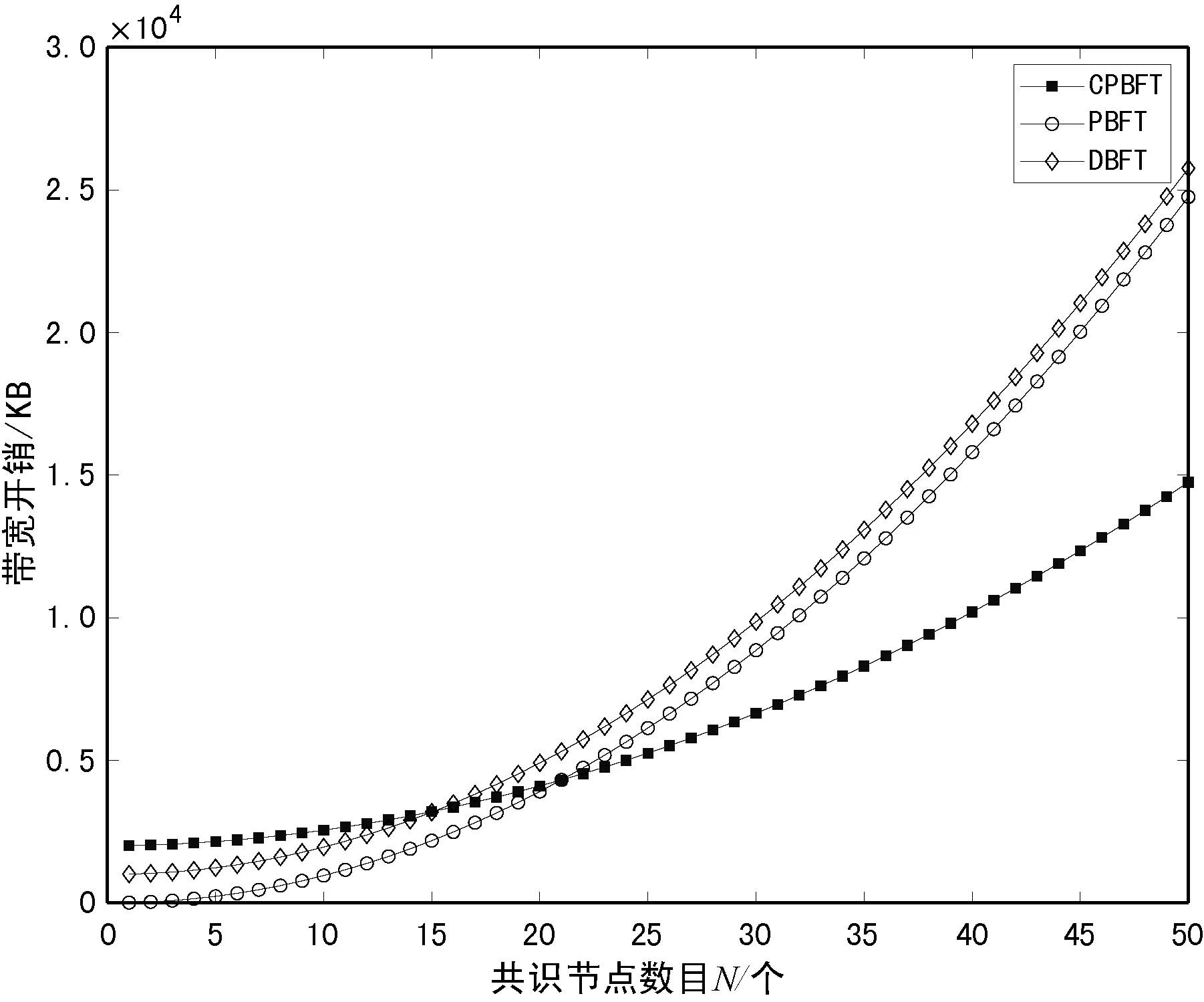
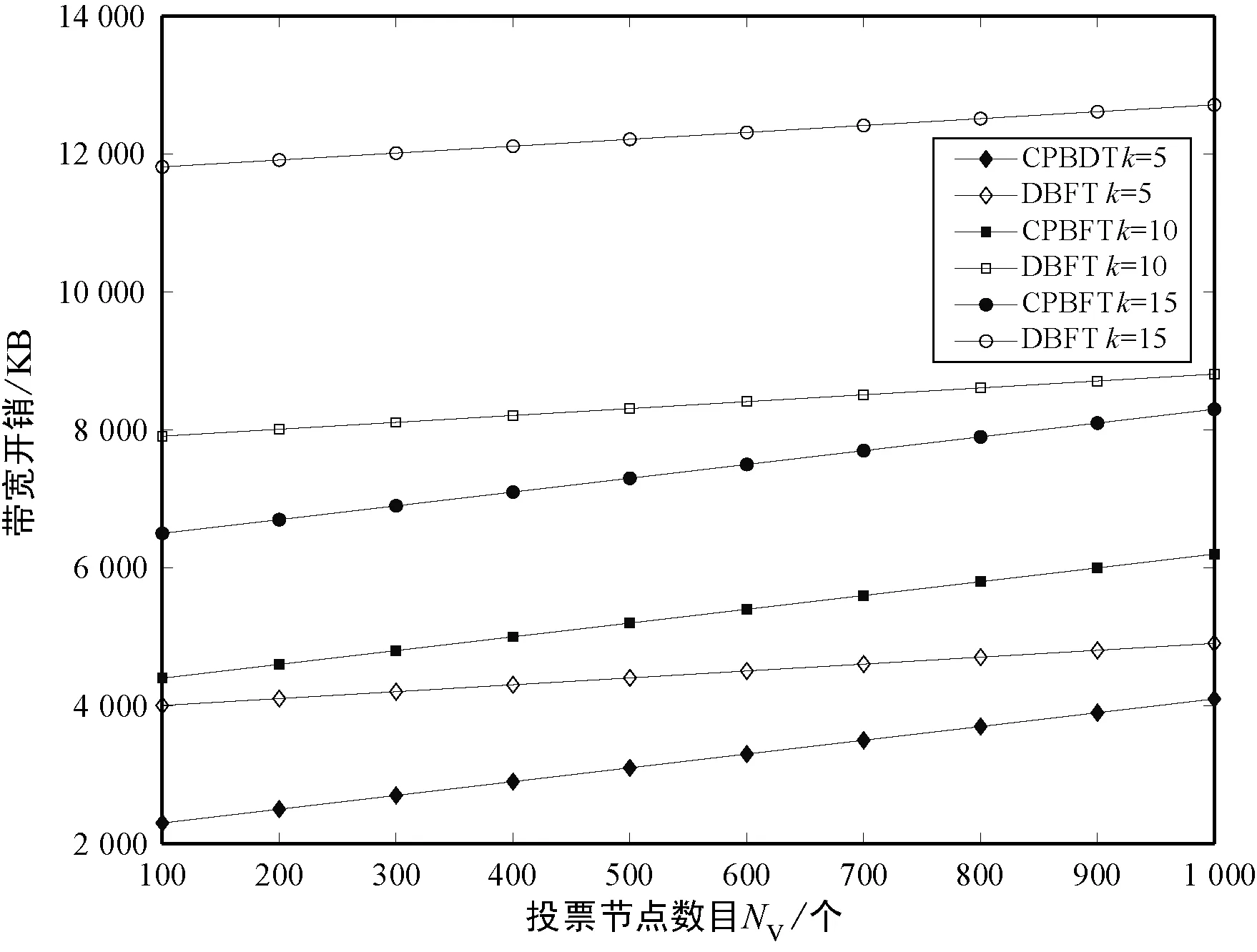
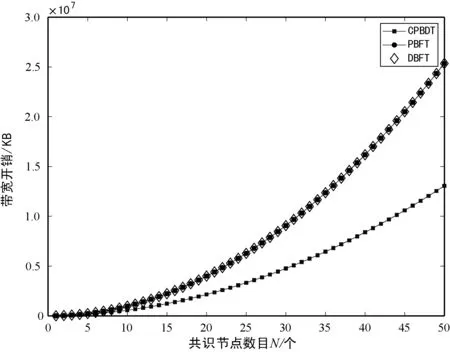
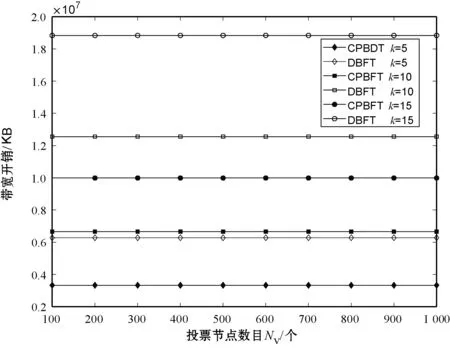
式中:Ci代表节点i的信用值;ni代表节点i获得的投票数;N代表总的投票数;K代表信用参数;t为节点添加到列表后经历的时间(0 节点信用值计算模型的描述。节点的信用值计算模型由三部分组成:初始信用值Cinit,Cinit=(ni/N)×K,由节点的初始得票情况决定;信用衰减值Cfall=(t/T)×Z,在一轮投票周期T内,随着时间t的增加,节点信用值将不断衰减;信用奖惩值Cmotiva=X,如果节点作为共识节点成功完成一轮共识,则获取信用值奖励,增加X,如果节点在共识中出现故障,则受到惩罚,减少X。根据实际的共识算法要求,设置合理的参数,可以建立合适的节点信用值计算公式。 2.2.2共识节点选举策略 经信用值计算得出节点信用值后,通过以下策略为节点划分信用等级,并选举出可信共识节点: (1) 当节点i的信用值Ci≥Cgreat时,将该节点划分为高信用等级节点。然后,将节点i添加到主节点的候选集,如果每次共识主节点的数目需求为1个,则将候选集中的节点按照信用值大小排序,轮流担任主节点; (2) 当节点i的信用值Cgood≤Ci (3) 当节点i的信用值Ci 此外,为激励节点参与维护区块链,本文设置经济激励措施来回馈共识节点的工作。每笔交易会按照比例收取一定的服务费,作为奖励金。共识完成后,所有共识节点(主节点和副本节点)均分50%的服务费,负责成块的主节点额外获得剩余50%的服务费。为最大化收益,参与节点会尽可能提高信用值,以增大成为主节点的几率。该方式利用经济博弈论思想来降低节点作恶风险。 通过节点信用评价机制,可从信用节点列表中,选举出可信的共识节点(主节点和副本节点)。可信的共识节点,将提升系统容错率,降低资源浪费。 基于上述方法,本文提出基于可信列表的改进拜占庭容错算法(CPBFT)。与PBFT算法不同,CPBFT算法的执行流程包括选举过程和共识过程,如图3所示。 图3 CPBFT共识算法的执行流程 值得注意的是:(1) CPBFT算法的选举过程并非每轮共识前都进行,而是在一轮投票周期内执行一次选举,然后支持多轮共识;(2) CPBFT算法的共识过程由PBFT算法的三阶段协议简化为二阶段协议。 算法1CPBFT共识算法 开始 选举过程 1.clientvote→primnodevote:〈〈REQUESTvote,operation,timestamp,client〉,σvc〉 //投票请求 2.primnodvote→nodevote:〈〈PREPAREvote,vote,digest〉,σvp,messagevote〉 //投票准备 3.IfHash(messagevote)=digest //投票消息校验 4.nodevote→clientvote:〈〈REPLYvote,vote,digest2,id〉,σvi,messagereply〉 //投票响应 5.IfHash(messagereply)=digest2 //响应消息校验 6.clientvote→primnodevote:〈〈RESULTvote,vote,digest3,client〉,σvcl,messageresult〉 //共识过程 7.clientcon→primnodecon:〈〈REQUESTcon,operation,timestampcon,clientcon〉,σc〉 //共识请求 8.primnodecon→replica:〈〈PRE-PREPAREcon,view,n,digestcon〉,σp,messagecon〉 //预准备 9.IfHash(messagecon)=digestcon //共识消息校验 10.replica→primnodecon,replicai:〈〈COMMITcon,view,n,digestcon〉,σi〉 //提交 11.primnodecon,replica→clientvote: 〈〈REPLYcon,view,timestampcon,clientcon,id_node,response〉,σi〉 结束 CPBFT算法的选举过程包括投票请求、投票准备、投票响应和广播结果四个阶段。 (1) 投票请求阶段。客户端向投票主节点发送请求消息〈〈REQUESTvote,operation,timestamp,client〉,σvc〉,其中:client是请求投票的客户端号,timestamp是申请投票的时间,σvc是投票客户端对消息的签名。 (2) 投票准备阶段。投票主节点首先为客户端的投票请求分配编号,然后向各普通节点发送投票准备消息〈〈PREPAREvote,vote,digest〉,σvp,messagevote〉,其中:vote是提案号,messagevote是投票请求消息,digest是请求消息的数字摘要,σvp是投票主节点对消息的签名。 (3) 投票响应阶段。普通节点首先验证投票准备消息的合法性,通过验证后向客户端发送投票响应消息〈〈REPLYvote,vote,digest2,id〉,σvimessagereply〉,其中,id是各节点的身份证明,messagereply是投票响应消息,digest2是响应消息的数字摘要,σvi是普通投票节点对消息的签名。 (4) 广播结果阶段。客户端验证投票响应消息的非法性,通过验证后向各节点(包括投票主节点和普通节点)发送投票结果消息〈〈RESULTvote,vote,digest3,client〉,σvc1,messageresult〉,其中:messageresult是投票结果消息,digest3是结果消息的数字摘要,σvc1是投票客户端对投票结果消息的签名。 CPBFT算法的共识过程包括请求、预准备、提交和响应四个阶段。 (1) 请求阶段。客户端向共识主节点发送请求消息〈〈REQUESTcon,operation,timestampcon,clientcon〉,σc〉,其中:clientcon是请求共识的客户端号,timestampcon是申请共识的时间,σc是客户端对消息的签名。 (2) 预准备阶段。主节点首先为客户端的请求分配编号,然后向各副本节点发送预准备消息〈〈PRE-PREPAREcon,view,n,digestcon〉,σp,messagecon〉,其中:view是视图号,n是提案号,messagecon是共识请求消息,digestcon是消息的数字摘要,σp是主节点对消息的签名。 (3) 提交阶段。副本节点首先验证预准备消息的合法性,通过验证后,副本节点广播〈〈COMMITcon,view,n,digestcon〉,σi〉消息,通知其他节点某个提案n在视图view中已处于准备阶段,当接收到至少2f+1个验证过的COMMITcon消息后,说明提案通过。 (4) 响应阶段。所有节点处理完请求后,将处理结果〈〈REPLYcon,view,timestampcon,clientcon,id_node,response〉,σi〉返回客户端,其中:id_node是节点编号,response是节点回复,σi是节点对消息的签名。客户端统计收到的处理结果,当接收到至少f+1个来自不同节点的相同结果,则该结果作为最终结果。 为综合评价CPBFT共识算法的性能,以交易吞吐量、交易时延和通信带宽开销三个指标为衡量标准,进行仿真实验。其中吞吐量是衡量算法执行效率的指标,时延是衡量算法响应能力的指标,带宽开销是衡量算法通信复杂度的指标。 吞吐量是指每秒完成的交易数,定义吞吐量的计算式为: TPS=SizeBlock/SizeTx/Tblock (3) 式中:TPS代表吞吐量;SizeBlock代表区块的存储容量;SizeTx代表交易的大小;Tblock代表成块的时间,即共识达成的时间。以比特币的工作量证明算法(PoW)为例,成块时间约为10分钟,在现有的大多数区块链平台中,区块的存储容量约为1 MB,交易的大小约为250 B,因此,比特币的交易吞吐量TPS约为7笔/秒。 对于单笔交易,时延是指请求时间(t1)和共识完成时间(t2)的差值(t2-t1)。对于一组交易,时延是指一组交易中第一笔交易的请求时间和最后一笔交易共识完成时间的差值,即最大单笔交易时延。 为评价CPBFT算法的吞吐量和时延情况,在配置为Intel Core i7-6700M @3.40 GHz处理器和16 GB内存,安装了64位Windows 7系统的PC,通过Eclipse2018平台用Java语言编程实现了PBFT和CPBFT算法,并进行了时延和吞吐量测试。其中,PBFT算法的实现与测试利用了Github平台上的pbftSimulator项目所共享的部分代码。每组实验独立运行10次并求平均值作为测试结果,主要参数设置如表1所示。 表1 吞吐量和时延实验参数表 图4展示了吞吐量和交易数量的关系,随着交易数量的增加,除在交易数为7 000时有拐点外,两个算法的吞吐量整体均呈线性增加趋势。当交易数量小于100时,CPBFT算法的吞吐量小于PBFT算法;当交易数量大于1 000时,CPBFT算法的吞吐量大于PBFT算法,且随着交易数量增加,吞吐量差值逐渐增大。 图4 吞吐量和交易数量的关系 在不考虑时延的情况下,讨论吞吐量是不严谨且无意义的,并且时延也是衡量算法响应能力的指标,因此本文还测试了时延和交易数量的关系,结果如图5所示。可以看出,随着交易数量的增加,两个算法的时延均呈线性增加,且当交易数小于100时,CPBFT算法的时延大于PBFT,当交易数大于1 000时,CPBFT算法的时延小于PBFT算法。 图5 时延和交易数量的关系 由图4和图5可见,随着交易数量的增加,吞吐量和时延均呈线性增加,但是在实际的联盟链应用中,一般要求时延小于3秒。由图5可知,3秒时延对应的交易数量约为4 000笔;再由图4可知,4 000笔交易对应的吞吐量约为1 400笔/秒。因此,基于实际应用考虑,讨论CPBFT和PBFT算法的吞吐量和时延比较,应限制在时延小于3秒和交易数低于4 000笔的范围内。在本文实验条件下,当交易数为4 000时,CPBFT算法的时延为2 812 ms,PBFT算法的时延为2 900 ms;CPBFT算法的吞吐量为1 422笔/秒,PBFT算法的吞吐量为1 379笔/秒。此时,相较于PBFT算法,CPBFT算法的吞吐量提升了约3.12%,时延降低了约3.03%。 CPBFT算法的执行选举和共识过程均产生通信带宽开销。其中,选举过程包括投票请求、准备、响应和广播结果四个阶段,共识过程包括请求、预准备、提交和响应四个阶段,定义其带宽开销为: Bandwithcpbft=k×[1+(N-1)+N×(N-1)+N]×message+ [1+(NV-1)+NV+NV]×Vote= k×(N2+N)×message+3NV×Vote (4) 式中:Bandwithcpbft为通信带宽开销;N为总的共识节点数目;NV是总的投票节点数目(NV≫N);message为验证消息;Vote为投票消息;k为一轮投票周期内执行的共识次数。 将CPBFT算法应用于区块链中,共识过程验证的消息为区块数据(SizeBlock),选举过程传递的数据为投票数据(Vote),SizeBlock≫Vote,此时带宽开销为: Bandwithcpbft=k×(N2+N)×SizeBlock+3NV×Vote (5) 同理,PBFT[19]算法仅执行共识过程,包括请求、预准备、准备、提交和响应五个阶段,定义其带宽开销为: Bandwithpbft=k×[1+(N-1)+(N-1)×(N-1)+ N×(N-1)+N]×message= k×(2N2-2N+N+1)×message (6) 将PBFT算法应用于区块链中,带宽开销为: Bandwithpbft=k×(2N2-2N+N+1)×SizeBlock (7) DBFT[22]算法执行选举和共识两个过程,选举过程包括广播节点身份一个阶段,共识过程包括请求、预准备、准备、提交和响应五个阶段,定义其带宽开销为: Bandwithdbft=k×(2N2-2N+N+1)× message+NV×Vote (8) 将DBFT算法应用于区块链中,带宽开销为: Bandwithdbft=k×(2N2-2N+N+1)× SizeBlock+NV×Vote (9) 其中,由于广播节点身份的数据量和投票的数据量大致相当,为便于对比,本文用投票数据Vote替代广播节点身份的数据。 为评价CPBFT算法通信带宽开销情况,在相同配置的计算机上进行仿真,通过MATLAB 2018a对CPBFT、PBFT和DBFT共识算法进行数学计算仿真,参数设置如表2所示。 表2 带宽开销实验参数表 第一组仿真是为比较不同算法的带宽开销情况。图6展示了不同算法的带宽开销和共识节点数目的关系,该实验中固定NV=1 000,k=5。随共识节点数目的增加,三种算法的带宽开销均呈指数递增,且CPBFT算法的增长率较小,PBFT和DBFT算法的增长率相近且较大;在共识节点数少于15时,算法带宽开销由大到小排序为CPBFT算法、DBFT算法、PBFT算法,这是由于CPBFT和DBFT算法与PBFT算法相比,增加了选举过程的通信开销;当共识节点数目大于25后,算法带宽开销由大到小排序为DBFT算法、PBFT算法、CPBFT算法,且PBFT算法带宽开销有超越DBFT算法的趋势。在本文实验条件下,当节点数目为50时,PBFT算法的带宽开销约为2.576×104KB,DBFT算法的带宽开销约为2.476×104KB,CPBFT算法的带宽开销为1.475×104KB,此时,CPBFT算法较PBFT算法带宽开销下降了约42.74%,较DBFT算法带宽开销下降了约40.43%。可以得出,在共识节点数目较多的情况下,CPBFT算法具有更低的带宽开销。 图6 通信带宽开销和共识节点数目的关系 图7展示了在不同共识执行次数k下,带宽开销和投票节点数目的关系,该实验中固定N=20。当执行次数k相同时,随投票节点数目的增加,CPBFT和DBFT算法的带宽开销均呈线性增加,且CPBFT算法的增长率更大;当投票节点数目NV相同时,随执行次数k的增加,CPBFT和DBFT算法的带宽开销均增加,且DBFT算法增长幅度更大。可以得出,CPBFT算法的带宽开销受投票节点数目的影响更大,DBFT算法的带宽开销受执行次数的影响更大。 图7 通信带宽开销和投票节点数目的关系 第二组测试是为比较不同算法应用于区块链中时的带宽开销情况。应用于区块链时,共识是以包含多条交易的一个区块为最小单元进行的,这不同于第一组实验中以一条交易为最小单元的共识过程,其测试结果如图8所示。图6和图8变化趋势相似,不同点在于PBFT和DBFT算法的曲线几乎重合,而CPBFT算法的曲线一直处于两者的下方。在本文实验条件下,当节点数目为50时,PBFT和DBFT算法的带宽开销相近且约为2.535×107KB,CPBFT算法的带宽开销约为1.306×107KB,此时CPBFT算法较PBFT和DBFT算法的带宽开销下降了约48.48%。 图8 通信带宽开销和共识节点数目的关系(应用于区块链) 图9所示为应用于区块链时通信开销和投票节点数目的关系。图7和图9差别在于,当执行次数相同k时,随投票节点数目NV的增加,带宽开销几乎不变。这是由于共识过程验证的消息为区块数据SizeBlock,其数据量远大于投票消息message的数据量,相较于共识过程,投票过程的带宽开销占比极小。 图9 通信带宽开销和投票节点数目的关系(应用于区块链) 由上述仿真结果可以得出,相较于PBFT和DBFT算法,CPBFT算法具有更低的通信带宽开销。 本文针对PBFT算法存在的灵活性差、容错率低和资源耗费高的不足,提出了一种基于可信列表的改进拜占庭容错算法。首先,建立了一个信用节点列表,将共识节点的参与方式由静态改进为动态,节点可动态进入或退出;其次,设计了一种节点信用评价机制,作为共识节点选举的依循,提升了系统容错率;最后,基于信用评价机制,将PBFT算法的三阶段协议简化为二阶段,进一步减少了通信开销、降低了算法时延。区块链作为一种公开的账本系统,交易信息被收集并详细记录其中,任何参与者都可以查询链上信息,故其面临严重的隐私泄露风险。下一步将重点研究区块链隐私保护问题。2.3 改进共识算法

3 仿真分析
3.1 吞吐量和时延分析

3.2 通信带宽开销分析
4 结 语
猜你喜欢
——稳就业、惠民生,“数”读十年成绩单人民周刊(2022年17期)2022-10-21电脑知识与技术(2021年22期)2021-09-14电脑知识与技术(2021年22期)2021-09-14现代信息科技(2021年21期)2021-05-07花火B(2019年3期)2019-04-27科学与财富(2017年23期)2017-09-24集装箱化(2017年4期)2017-05-17集装箱化(2016年11期)2017-03-29集装箱化(2016年12期)2017-03-20声屏世界(2015年7期)2015-02-28
