
基于循环生成对抗网络的超分辨率重建算法研究
2022-02-24 08:56蔡文郁张美燕郭嘉豪
电子与信息学报 2022年1期
蔡文郁 张美燕 吴 岩 郭嘉豪
①(杭州电子科技大学电子信息学院 杭州 310018)
②(浙江水利水电学院电气工程学院 杭州 310018)
1 引言
图像超分辨重建(Image Super-resolution reconstruction, SR)是指低分辨率(Low Resolution,LR)图像转换为具有更好的视觉质量和精细节的相应高分辨率(High Resolution, HR)图像[1],目前已广泛应用于机器视觉的各个领域,例如视频监控[2]、遥感[3]、医学图像[4],还可以作为图像分类[5]、识别[6]、去噪和检测的预处理方法[7,8]。图像超分辨率重构方法可以分为以下3类:基于插值、基于重建和基于学习的方法。基于插值的超分辨率重构主要包括最近邻插值[9]、双线性插值[10]以及双三次插值[11]等。基于插值的方法非常简单,但它们不能为重建提供任何额外的信息,因此无法恢复丢失的频率。基于重构的方法比较有代表性的是迭代反投影方法(Iterative Back-Projection, IBP)[12]、凸集投影法(Projection Onto Convex Sets, POCS)[13]、最大后验概率法(Maximum A Posteriori, MAP)[14]。这类方法大部分通过一组高度相关的 LR 图像序列进行重构,但是重建模型的参数很难估计,当使用场景无法提供足够信息时,提高图像分辨率变得非常困难。
Dong等人[15]在2014年首次将深度学习应用在图像超分辨率重建领域,提出了SRCNN并取得了优于此前传统算法的重建结果。从此,众多国内外研究者提出了不同的深度学习网络进行图像超分辨率重建。2015年, Dong等人[16]提出了FSRCNN,通过重新设计SRCNN网络结构,减少了冗余运算,提高了网络的训练速度, 首次使用反卷积层进行重建。2016年, Kim等人[17]提出了VDSR,首次将经典的VGG网络应用在超分辨率领域,采用深层次的网络结构取得了更好的重建结果。同年,Shi等人[18]提出了ESPCN,其中的亚像素卷积层使网络能够在LR空间进行训练,减少了网络参数,提高了训练速度和特征利用率。亚像素卷积层对基于深度学习的超分辨率算法有十分深远的影响,后续几乎所有的网络都使用亚像素卷积层来进行重建。2017年,文献[19]首次将生成对抗网络(Generative Adversarial Network, GAN)应用在超分辨率领域,提出了新型的SRGAN[20],改进了之前网络中的损失函数,引入感知损失和对抗损失,缓解了以往算法得到的重建结果不真实的问题。同年,Lim等人[21]提出EDSR,改进了SRGAN的生成器网络SRResnet,移除了其中的批归一化(Batch Normalization, BN)层,降低了参数量和显存占用,并进一步构建出了更宽的网络进行训练。2018年,Zhang等人[22]提出了RCAN,首次将注意力机制引入图像超分辨率领域。RCAN参照SE模块构建了空间注意力模块CAB,并添加在EDSR基本残差块的末端,用更少的参数量实现了比EDSR更好的重建效果。同年, Shocher等人[23]提出了ZSSR,这是首次将无监督学习应用在超分辨率领域,将测试图片缩小作为输入进行训练,得到模型后再将测试图片作为输入,从而得到重建结果。因此,ZSSR不需要大规模的预训练,也不消耗过多的计算资源。
目前深度学习方法依然是图像超分辨率重建的主流,相关研究都以卷积神经网络、残差网络[24]、亚像素卷积层[18]为基础,通过修改网络结构来提高算法的速度和精度。但是,这些算法仍然存在两个主要问题:一是以巨大的参数量来换取强大的网络特征提取能力,这将会消耗大量计算资源,难以进行工程实现;二是超分辨率重建后得到的图像过于平滑,缺少细节纹理信息,不够逼真。图像超分辨率重构作为低级图像处理任务,要求尽可能保留图像的底层信息,因此本文研究一种基于循环生成对抗网络的超分辨率重建算法。
2 基于循环生成对抗网络的超分辨率重建算法
本文提出了一种基于注意力机制的改进多级残差网络(Multi-level Residual Attention Network,MRAN)进行超分辨率重建:通过引入注意力机制,改进残差网络结构,增强了网络的特征提取能力,在降低算法复杂度的同时提高了图像的重建质量。针对SRGAN模型的不足之处,本文构建了新型CycleGAN结构,并且从生成器网络结构、判别器判别方式、损失函数等方面对SRGAN做了改进。
基于循环生成对抗网络的超分辨率重建网络MRA-GAN系统架构如图1所示,由重建网络G、退化网络F和两个判别器DLR, DHR组成。重建网络G负责将LR图像重建为HR图像,退化网络F负责将HR图像降采样为LR图像,判别器DLR负责鉴别真实LR图像和通过退化网络降采样得到的LR图像,判别器DHR负责鉴别真实HR图像和通过重建网络重建得到的HR图像。
2.1 重建网络
重建网络的任务是将LR图像重建为HR图像,基于注意力机制的改进多级残差网络(Multi-Residual Attention Network, MRAN)作为重建网络,包含低级特征提取模块、残差集合和上采样重建模块。低级特征提取是从3通道RGB图像中提取低级特征作为后续网络的输入;上采样重建模块通过亚像素卷积层将LR图像重建为HR图像,并利用1个卷积层将图像恢复为3通道RGB图像。残差集合包含若干个残差组RG(Residual Group),用来学习LR图像与HR图像之间的非线性映射关系。残差组RG的结构如图2所示,每个残差组RG由4个残差块(Residual Block)、1个通道注意力模块和1个用于调整通道数的卷积层组成。由于低层网络通常拥有更多的底层信息,为了充分利用这些信息,本文引入了残差聚合概念,将4个残差块的输出通道拼接在一起,经通道注意力模块后最终输出,解决了现有网络特征提取导致参数量巨大的问题。对于每一个残差集合的输入,输出可以表示为
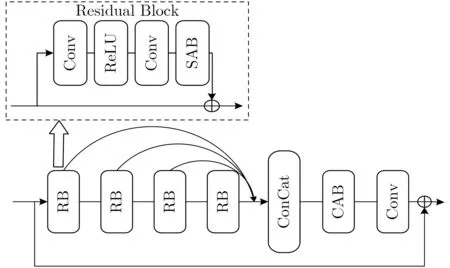
图2 MRAN的残差组RG结构
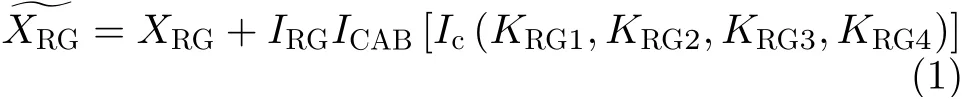

SRResnet和EDSR都设计了残差块RB来构建网络,其结构示意图分别如图3(a)和图3(b)所示。本文算法的RB架构在移除BN层的同时,还添加了位于末端的空间注意力模块SAB(Spatial Attention Block),如图3(c)所示。本文通过引入通道注意力模块和空间注意力模块,使残差网络能够在训练的过程中学习出相应的通道权重和空间权重,从而分别提高了网络在不同通道和不同空间区域上提取关键信息的能力。通道注意力机制能够在不增加网络宽度的情况下,给予这些重要通道更高的权重,以提高网络提取关键信息的能力。而空间注意力机制则是在一张特征图的内部分配注意力资源,使网络给予特征图中的纹理、边缘等重要的高频信息更多关注,从而提高网络提取信息的能力,使最后的重建结果更接近真实图像。
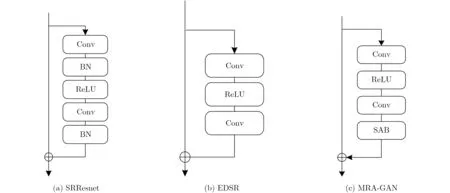
图3 SRResnet, EDSR, MRA-GAN的残差块RB结构
2.2 退化网络
退化网络的任务是将HR图像退化为LR图像,可以认为是重建网络的逆过程,如图4所示。其中Interpolate表示插值降采样操作,退化网络先将HR图像降采样到低分辨率空间,然后利用MRAN中提出的残差集合学习HR与LR的映射关系,最终通过一个卷积层重建得到预测的LR图像。

图4 退化网络结构
2.3 DLR, DHR判别器
本文算法采用的判别器结构参考了由Radford等人[25]提出的判别器网络,如图5所示。该相对判别器网络本质上是一个二元非类,如式(2)所示:
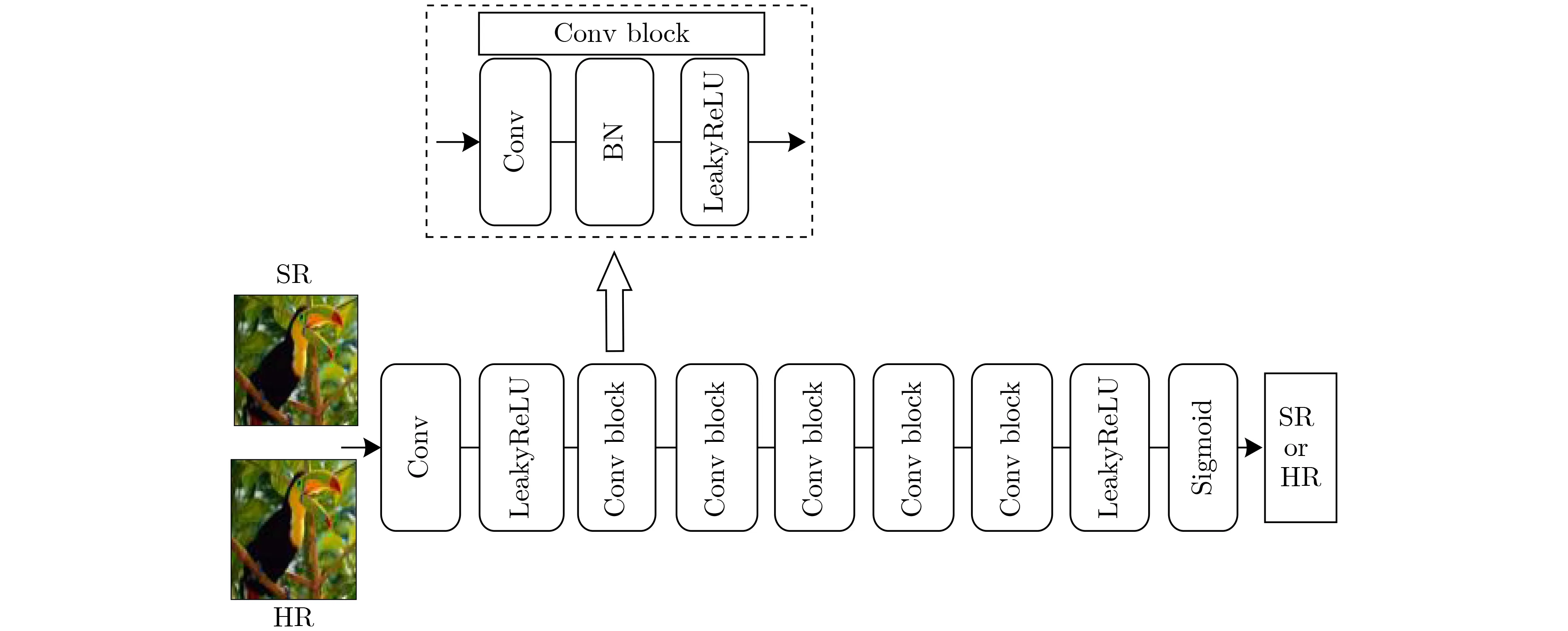
图5 判别器网络结构

2.4 损失函数设计


本文算法中重建网络G的损失函数设计由4部分组成,如式(3)所示:由式(4)可知,将计算误差由计算差的平方修改为计算差的绝对值,因此能够降低运算量,同时提高模型收敛速度,缓解重建图像过于模糊的问题。
(2)感知损失(Perceptual Loss, LP)
本文算法使用的感知损失函数使用VGG19网络进行特征提取,因为使用未激活的特征图能够更全面地衡量两幅图片的感知差距,因此选用了ReLU激活层之前的特征图来计算损失。感知损失函数如式(5)所示

由式(7)可知,生成器的对抗损失部分不仅包括重建图像,还包括高分辨率原图,因此二者都促进了重建网络的训练。而在SRGAN模型中,仅有重建图像会对网络起到积极作用。因此使用相对判别器能够提高网络的学习能力,帮助网络重建出更加真实的图像。
(4) 循环一致性损失(Cycle Consistency Loss)
通过对抗损失,可以分别对重建网络、退化网络和判别器进行训练。但是在超分辨率重构中,低分辨率图像与高分辨率图像并不是一一对应的,因此网络根据某一组固定的输入可能会生成多组不同输出。为了保证不丢失输入图像的特征信息以及真实性,在本文算法的循环结构中,引入了循环一致性损失,能够保证输入X经过一个循环后得到输出y仍旧接近输入X,即
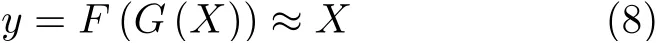
循环一致性损失由两个循环结构的输入与输出之间的平均绝对误差求和求得

3 实验结果与分析
实验采用的基准测试集Set5, Set14, BSD100,Urban100和Manga109中都包含了高分辨率原图和与之对应的2, 3, 4, 8倍降采样低分辨率图片。近年来基于深度学习的超分辨率算法基本都采用上述测试集进行测试和结果对比,为方便对比,本文也选用这5个基准测试集进行测试。实验平台为64位Ubuntu操作系统,使用GPU(Nvidia GeForce RTX 2080Ti)训练网络,算法实现采用了Pytorch深度学习框架。
实验设置如下:MRA-GAN使用RGB 3通道图像进行训练,图像在输入前做了随机旋转和随机翻转的增强处理,每一批输入是16幅尺寸为48×48的图像,这些小的图像块均从数据集原图中提取得到。训练过程使用L1损失函数和Adam优化器,其中β1= 0.9,β2= 0.999,ε= 10-8,学习率设置为10-4。在训练开始时,分别先对重建网络和退化网络进行10轮预训练,再使用与训练好的模型和判别器进行交替训练,迭代30000轮,模型训练时间约为72 h。具体参数值如表1所示。
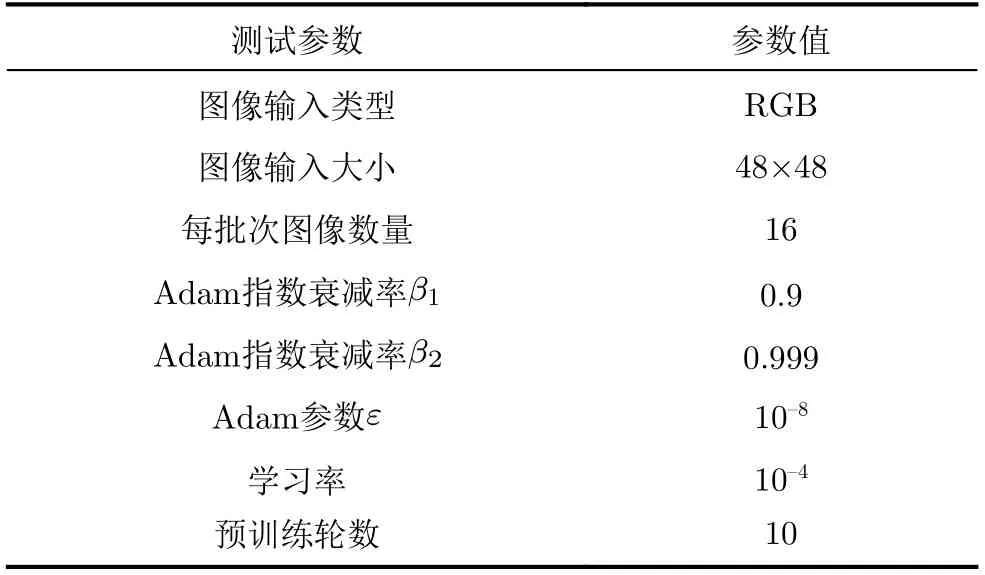
表1 测试参数设置
MRA-GAN通过残差集合来学习LR图像到HR图像的映射,残差组的数量将会影响网络整体的参数量和结果。为平衡算法的精度与速度,训练不同数量残差组并在Set5数据集上进行4倍重建测试。表2比较了不同数量残差组时,网络总参数量和取得的重建结果对比效果。从表2可以看到残差组的数量由8增至32时,重建图像的质量在不断提升。当增至48甚至64时,网络的参数量已经十分庞大,但是重建图像并没有明显提升,甚至还会有小幅下降。因此,本文最终确定MRAN中使用32个残差组来构成残差集合。
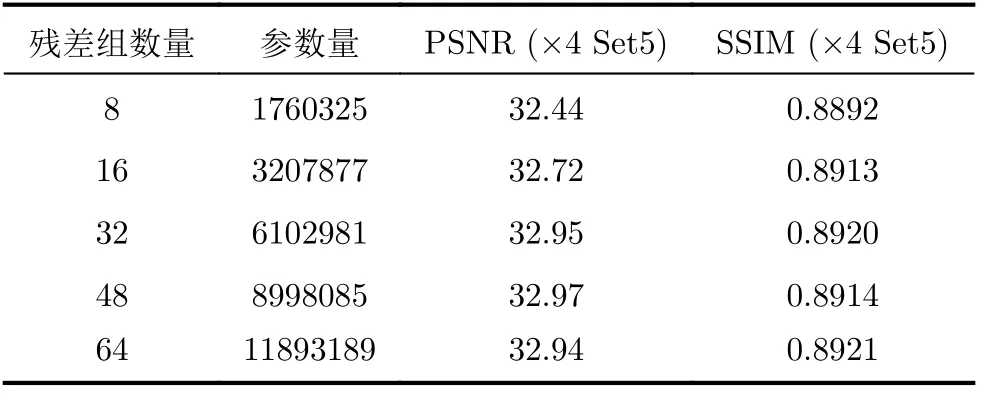
表2 不同残差组数量实验结果
MRA-GAN与其他网络不同模型在不同迭代轮数下重建结果如图6所示,其中横坐标表示迭代轮数,纵坐标分别表示在DIV2K数据集上进行验证时得到的PSNR和SSIM指标。从中可以看出MRAGAN在DIV2K验证集的重建结果明显优于网络结构简单的SRCNN和VDSR,略优于EDSR。
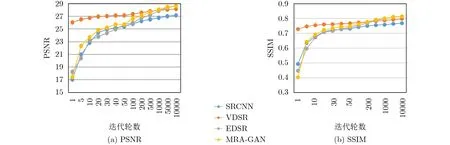
图6 DIV2K验证结果
表3详细给出了MRA-GAN与其他方法在各个基准数据集上分别进行2, 3, 4, 8倍重建后图像的PSNR和SSIM结果,黑体和下划线分别标记了每项的最优结果和次优结果。
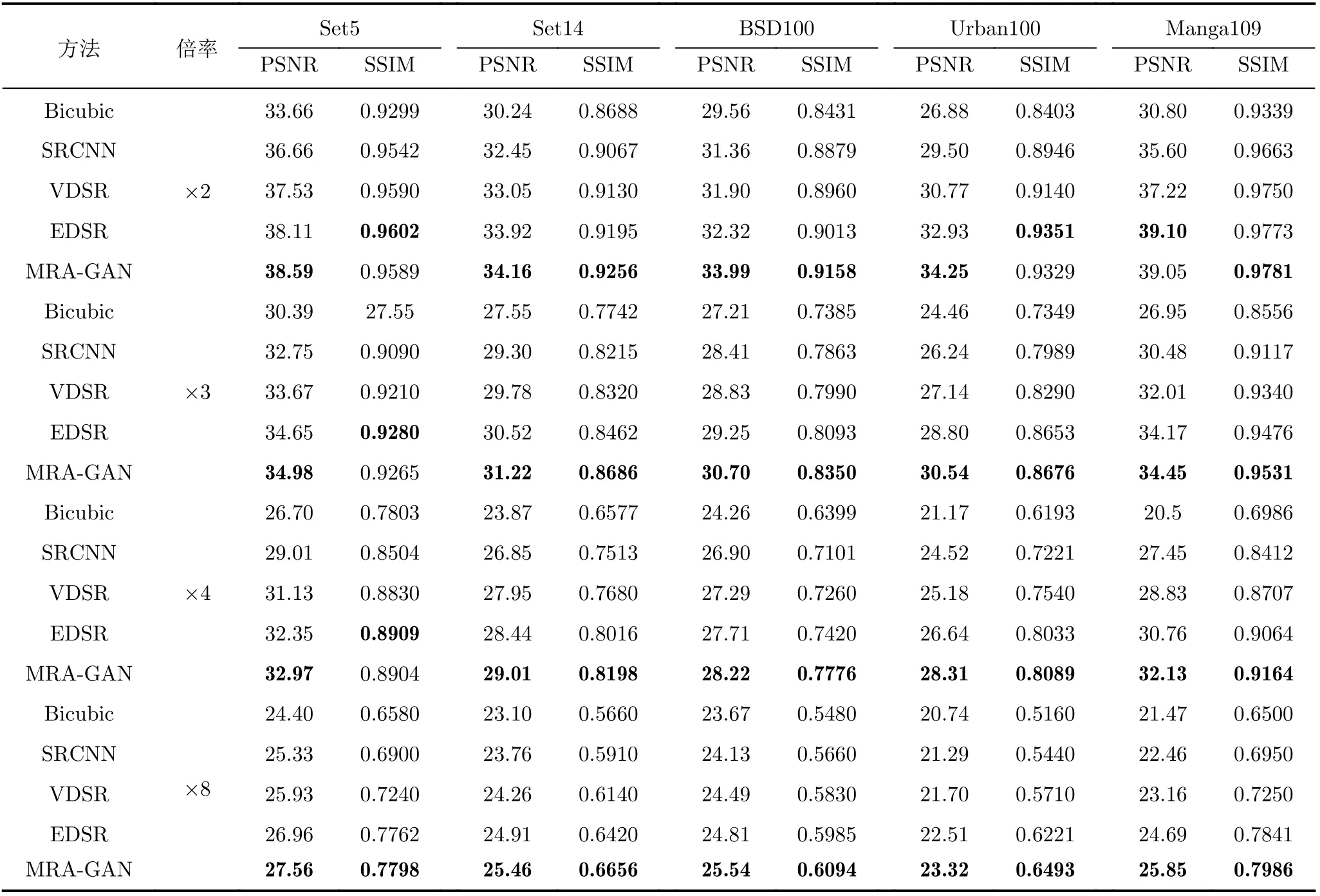
表3 实验结果对比
从实验数据表3中可以发现,在4倍和8倍重建结果中MRA-GAN的结果均优于EDSR, CDSR,SRCNN, Bicubic等算法。但是在2倍和3倍重建的情况下,在小部分测试集中MRA-GAN的结果略差于EDSR,这是由于重建倍率较小,输入图片的内部已经包含了明显的特征信息,使用EDSR就已经能够充分提取到关键信息。同时,由于MRA-GAN强大的特征提取能力和更高的特征利用率,结果也说明在不增加额外参数的前提下,本文算法能够在高倍率的图像超分辨重建中取得更好的结果。
图7展示了在各个基准测试集中使用各种重构方法所得到的测试图像,从中可以验证MRA-GAN得到的重建结果细节更丰富,纹理更清晰,因此体现了更好的主观视觉体验。

图7 基准测试集测试结果
4 结束语
本文通过引入注意力机制,构建多级残差网络,参考循环生成对抗网络结构,提出了一种新的图像超分辨率重建算法MRA-GAN。在标准测试集的验证实验结果验证了本文算法相较于以前的超分辨重建方法,在客观评价量化上都拥有更好的性能提升。后续研究将本文方法扩展应用到多视角图像的超分辨率重建领域,并将方法应用于多媒体传感器网络中。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
甘肃教育(2020年22期)2020-04-13
北京航空航天大学学报(2019年9期)2019-10-26
家庭影院技术(2018年9期)2018-11-02
第二课堂(课外活动版)(2016年2期)2016-10-21
微型计算机(2009年4期)2009-12-23
