
基于平衡迭代规约层次聚类的无线传感器网络流量异常检测方案
2022-02-24 08:58郁滨熊俊
电子与信息学报 2022年1期
郁 滨 熊 俊
(战略支援部队信息工程大学 郑州 450000)
1 引言
无线传感器网络(Wireless Sensor Networks,WSN)流量异常检测技术运用数据挖掘、机器学习等方法对流量数据进行统计分析,以判断网络是否存在异常运行或入侵行为,对维护网络安全具有重要意义,如何及时、准确地检测出异常流量是当前WSN流量异常检测技术亟需解决的问题[1]。目前,网络流量异常检测技术主要包括基于神经网络模型、基于统计分析方法和基于聚类分析算法[2]。
在WSN流量异常实时检测中,直接通过连续采样获得的流量数据是没有标记的,考虑到通常需要利用大量带标签的数据训练神经网络模型以增强模型的泛化能力[3,4],因此,基于神经网络模型的检测技术不适用于实时的WSN流量异常检测环境。基于统计分析方法的检测技术在检测实时性、算法计算复杂度等方面具有优势,但现有方案大多缺乏合理的异常判决机制,且忽略了统计误差对判决结果的影响,检测准确度较低[5—7]。基于聚类分析算法的检测技术无需预先处理输入样本,通过分析网络流量数据内部特征的相关性,以聚合具有相似特征的流量,并将稀疏簇内的流量判决为异常数据,逐渐成为网络流量异常检测技术的主要研究方向[8—10]。
现有的聚类分析算法可以被归纳为层次聚类分析、划分聚类分析和智能聚类分析3类[11]。智能聚类分析技术主要基于深度学习、核函数等机器学习方法,该技术在WSN异常流量检测应用中存在与基于神经网络模型的检测技术相同的不适用性。划分聚类分析更倾向处理各个聚类簇大小比较接近的样本,因此该技术往往无法将孤立点数据或异常点数据从样本中分离出来,且聚类中心的选择也会对其聚类结果产生较大影响,同时由于划分聚类一般从总体上评判样本间的相似性,导致其不支持增量式数据源。平衡迭代规约层次聚类(Balanced Iterative Reducing and Clustering using Hierarchies,BIRCH)作为一种经典的层次聚类分析算法,仅通过一次扫描即可有效地组织大规模数据,在聚类质量、效率、稳定性和扩展性方面具有明显优势[12]。BIRCH的基本思想是通过肯定每一个样本点的差异性,先将他们视作一个个单独的聚类簇,再根据簇之间相似性的高低将他们分层合并。通过这种方式,BIRCH聚类分析算法不需要预先设定聚类值和聚类中心,在处理离散点方面表现突出,可以将异常点数据划分到独立的簇中,相较于划分聚类分析技术,更适用于网络流量异常检测。Pitolli等人[13]利用BIRCH聚类算法对样本特征进行分类,用以识别海量软件样本集中的恶意数据,具有较高的检测率和计算效率。Peng等人[14]提出一种基于主成分分析的P-BIRCH聚类算法,时间成本随着聚类数的增加而线性减少,有效地解决移动云环境下的大数据入侵检测问题。
一方面,通过连续采样获得的WSN流量是典型的连续时间序列。根据时间序列相邻值之间具有的时间相关性[15],针对出现在网络流量平稳阶段或固定周期的突变流量,对比其前后一段时间内的采样流量可以发现,这些流量的急剧变化是反常的,有理由相信他们为异常流量。然而,由于流量值仅仅体现了网络在该采样周期内的流量大小,如果利用BIRCH对单一维度的流量序列进行聚类分析,会因为忽略了流量与其前后临近流量的相关性,从而导致将异常突变流量划分到高峰期或低谷期流量对应的聚类簇中,使得异常检测结果存在较大的偏差。
另一方面,Lorbeer等人[16]指出经典BIRCH基于相同距离划分簇类,存在不能处理自然数据形状集合,对样本输入顺序高度敏感等不足。针对此,Guo等人[17]提出一种基于链接的LBIRCH算法,通过建立邻居表实现对任意形状进行聚类。同时,由于经典BIRCH采用全局静态阈值建立聚类特征树(Clustering Feature Tree, CF-Tree),只能获得具有相同体积的聚类。因此,尚家泽等人[18]结合朴素贝叶斯算法,提出一种基于自适应阈值的改进BIRCH,一定程度上解决了其不适用于聚类体积差异较大簇类的局限性,但算法执行效率明显下降。
综上所述,针对WSN流量异常实时检测需求,该文提出一种基于BIRCH的WSN流量异常检测方案。首先,扩充WSN流量的特征维度,在此基础上,设计一种优化特征聚类树(Optimized Clustering Feature Tree, OCF-Tree)结构对BIRCH进行优化。然后,提出基于拐点的综合判决机制,进一步弥补聚类偏差对检测结果的影响。最后,根据基于仿真平台获得的WSN流量数据,对比该文方案与其他方案的流量异常检测效果。
2 模型建立
2.1 符号与定义
为方便对方案进行描述,该文相关符号及其含义如表1所示。


表1 符号定义

2.2 流量异常检测模型
基于BIRCH的WSN流量异常检测模型如图1所示,主要包括流量特征聚类分析和流量异常判决两个关键部分。
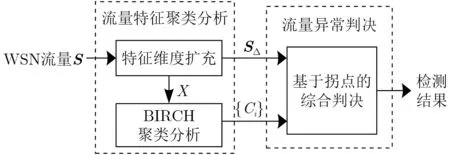
图1 基于BIRCH的WSN流量异常检测模型
2.2.1 流量特征聚类分析
流量特征聚类分析分为特征维度扩充和BIRCH聚类分析两个环节。
WSN流量预测技术以网络历史流量信息为依据推测未来一段时间内的流量趋势[20]。根据定义2和定义3可知,某时刻流量预测值代表了该时刻流量的变化趋势及基准值,即正常流量的变化可能在预测值附近小范围波动,所以流量预测序列和预测误差序列均隐含了原始流量的时序特征。因此,针对WSN流量的聚类特征维度较低的问题,特征维度扩充环节根据输入的WSN流量序列S,利用其预测序列Sˆ和预测误差序列SΔ作为原始流量的新增特征,以扩充聚类分析输入样本的特征维度。
BIRCH聚类分析环节设计一种特殊的OCTTree结构,根据流量特征X将流量划分成簇{Ci}(i=1,2,...,K),其中K为簇个数。一方面,由于WSN流量具有突发性、分布不均匀等特征,且存在稀疏的异常流量点,基于此,通过为每个聚类特征(Clustering Feature, CF) 单独设置增量式的动态阈值T,使其适用于聚类体积存在较大差异的簇。另一方面,对于经典BIRCH算法,每个节点只能容纳固定数目的CF,聚类结果不总对应于自然集群。同时,根据流量的输入顺序,特征差异较大的流量可能会被聚类到同一簇中,针对此,根据每个叶子特征CFL的邻居簇对聚类结果进行全局优化。
2.2.2 流量异常判决
流量异常判决环节根据拐点确定聚类截断阈值c l u s t e r_T 和预测截断阈值p r e d i c t_T,将cluster_T作为区分簇体积大小的依据,predict_T作为区分预测误差大小的依据。利用cluster_T从{Ci}中筛选出体积较小的簇,将小体积簇中的流量构成聚类可疑点集合P,同时利用predict_T从SΔ中筛选出预测误差较大的流量,构成预测可疑点集合Q,并基于P, Q综合判决WSN流量是否异常。
3 流量特征聚类分析算法
WSN流量的特征维度扩充如图2所示,分别将流量序列作为第1维特征,预测序列作为第2维特征,预测误差序列作为第3维特征,合并S,Sˆ和SΔ,组成3维流量特征序列X=[X1,X2,...,Xn],其中Xi=[sisˆiΔsi]T,i=1,2,...,n。特征维度扩充基于流量预测技术,由于目前已有较为成熟的研究,众多流量预测算法具有计算复杂度低、预测速度快、预测精度高等优势[21],因此m-p流量预测函数Γm-p(·)的内部结构不在该文讨论范围内。
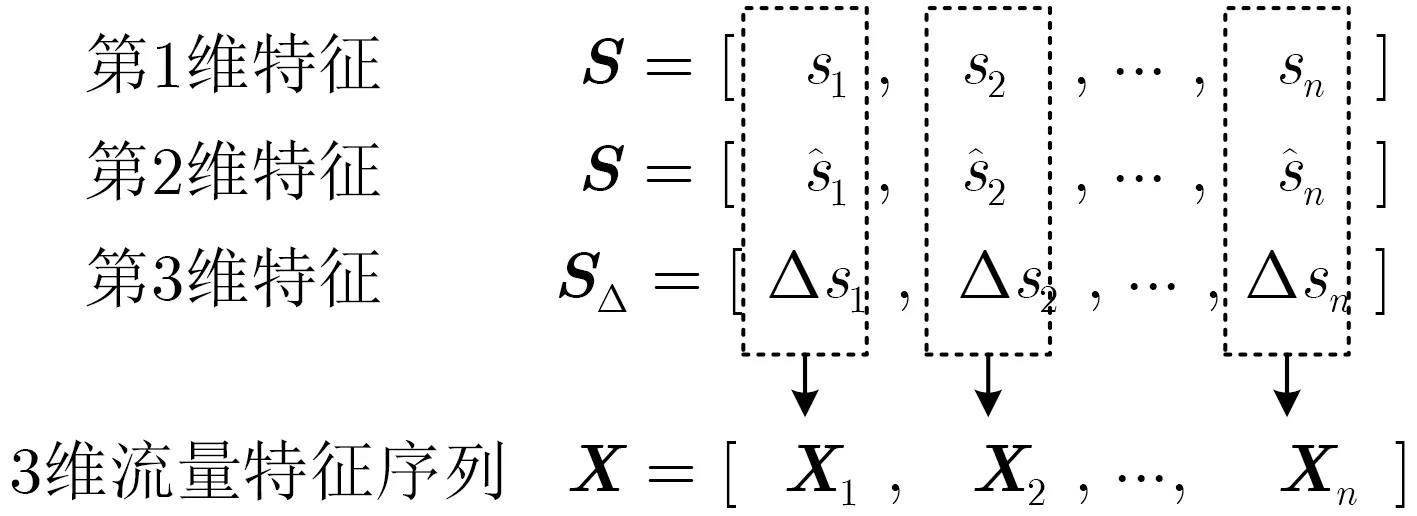
图2 特征维度扩充示意图

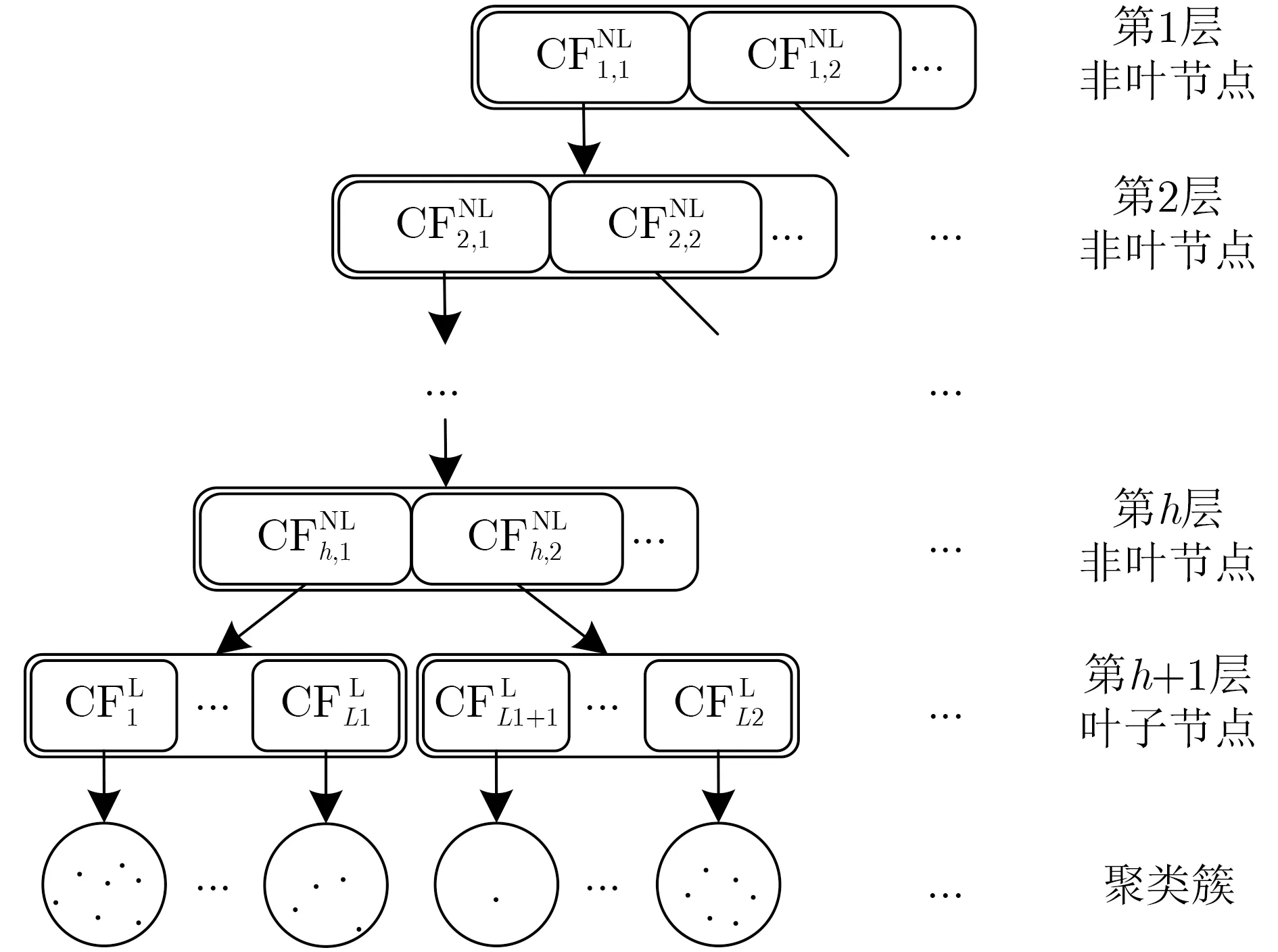
图3 优化聚类特征树结构



值得注意的是,BIRCH聚类算法所需内存与阈值T有关。T越大,构建的CT-Tree规模就越小,则所占用的内存也越小。然而,如果T过大,会导致单个聚类簇的规模较大,则聚类程度十分粗略,从而影响聚类效果。由于本文着重研究如何提高BIRCH的聚类质量,因此,假设流量特征聚类分析算法步骤均在内存足够的前提下进行。
4 流量异常判决方法

基于此,流量异常判决环节设计一种基于拐点的综合判决机制,利用拐点确定区分聚类簇体积大小的截断阈值,如图4(a) 所示。进一步,利用拐点确定区分流量预测是否失真的截断阈值,如图4(b)所示,以避免当网络流量出现突发性变化或流量预测误差较大时,正常流量被划分到小体积的簇中的情况。流量异常判决方法具体步骤如下:


图4 截断阈值选取
根据上述方法步骤,实现对WSN流量异常的综合检测。
5 实验及结果分析
实验基于Ubuntu系统平台,利用NS-2网络模拟器进行WSN仿真实验,采用Python3.6语言和eclipse环境检验该文方案的有效性。
5.1 实验数据与参数配置
5.1.1 实验数据
实验利用NS-2网络仿真平台搭建WSN仿真环境,配置如表2所示。

表2 WSN仿真环境配置
实验数据基于上述WSN仿真环境,以采样频率0.25 Hz统计WSN区域内的流量以模拟实时采样环节,得到500个流量样本点。将第1至400个样本点作为Γm-p(·)输入,以预测第401至500个流量样本点,作为流量特征的扩充维度。针对本文方案提出的m-p流量预测函数Γm-p(·),采用文献[21]提出的优化FAEMD-OSELM流量预测模型,其中m=400, p=100。
在上述流量采样过程中,分别采用Blackhole,Flooding和Grayhole攻击模型[22]在第451至480个样本时间段模拟网络异常情况,如图5所示。将包含异常流量的第401至500个网络流量分别作为Blackhole, Flooding和Grayhole测试数据集,其中第451至480个为网络异常时的采样流量,其余为网络正常时的采样流量。
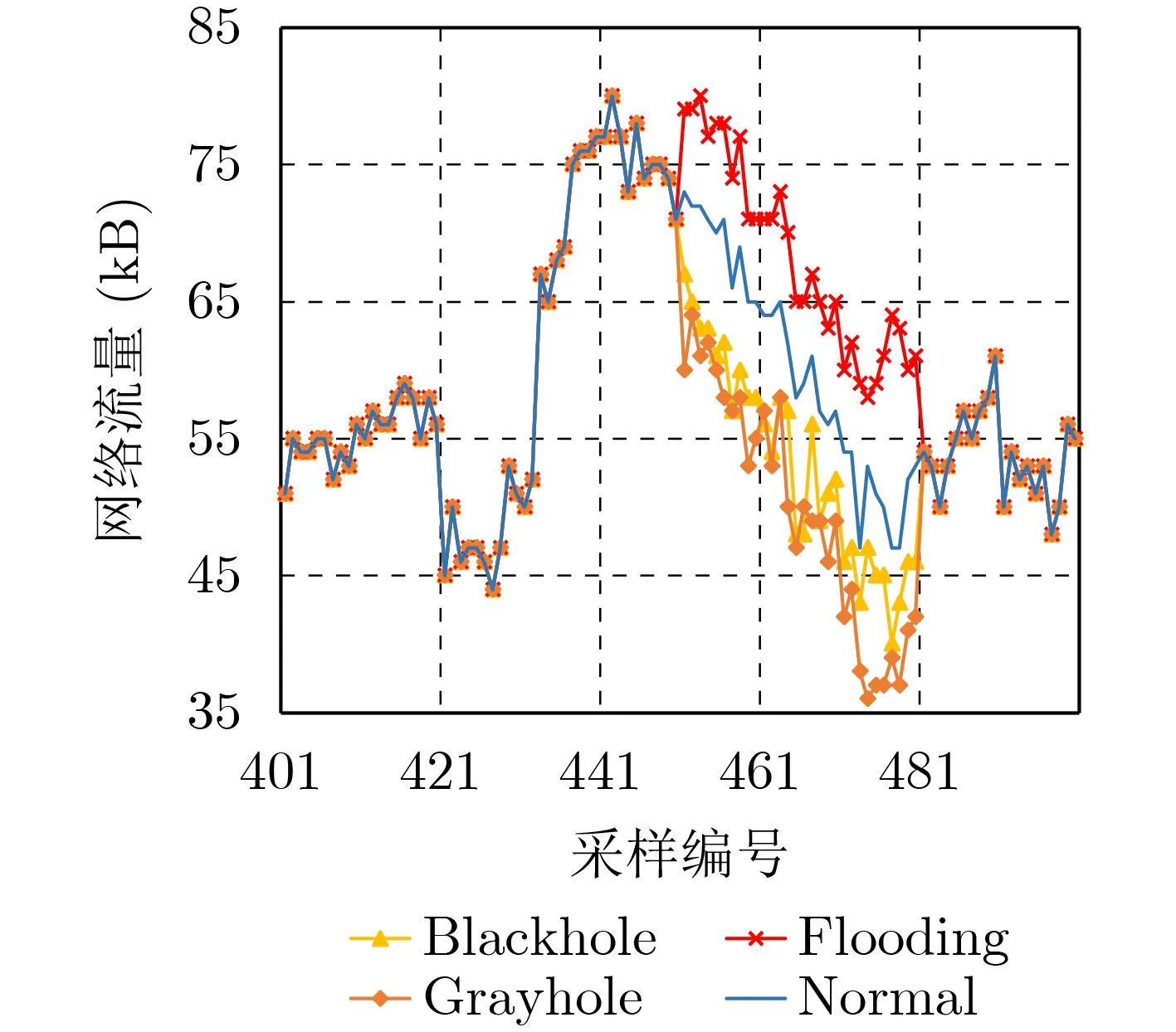
图5 WSN异常流量数据
5.1.2 实验参数设置
实验选择文献[23]中的ENDTW-O-CFSFDP流量异常检测模型、文献[24]中的BasisEvolution流量异常检测模型和文献[14]中的BIRCH流量异常检测模型与本文方案进行对比,结合Blackhole, Flooding,Grayhole 3种测试数据集,综合比较方案的流量异常检测性能。相较于基于PCA-BIRCH的方案,本文方案设计的启发式阈值T无需人为设定,更具自适应性,其初始值T0由测试数据集Blackhole,Flooding, Grayhole确定,分别为4.18, 3.89, 3.94。
本文方案需要设定的参数为非叶节点分支因子B和叶子节点分支因子L,通常B取4, 5, 6,L取4,5, 6, 7为最佳聚类效果经验值。由于B, L一定程度上决定了OCF-Tree的形状以影响聚类效果,因此实验针对3种测试数据集,分别设置B取2至10,L取1至10,研究B, L取值对本文方案检测结果的F1值和准确率的影响。如图6所示,若选取的B或L过大,距离簇质心较远的正常样本将被划分成独立的聚类簇,并被判决为异常流量,从而增加了正常样本被错误判决的比例;相反地,若选取的B或L过小,受限于OCF-Tree的节点分支数量,异常样本将被强制划分到距离最近的聚类簇中,并增大该聚类簇的规模,导致其被判决为正常流量,从而增加了异常样本被错误判决的比例。在上述两类情况下,本文检测结果的F1值、准确率较低,检测效果较差。因此,实验选择聚类效果最好时的B=4, L=5作为本文方案的实验参数。
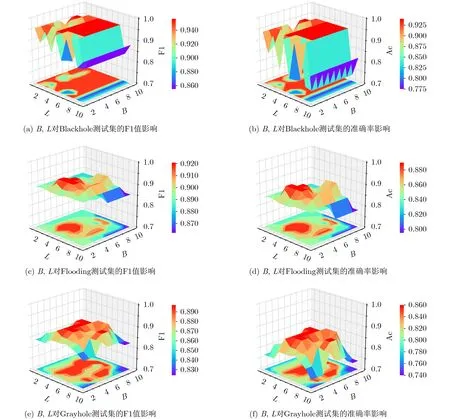
图6 B, L的取值对F1值和准确率的影响
5.2 结果分析
实验选择精确率 (Precise, Pr) 、召回率 (Recall,Re) 、F1值和准确率 (Accuracy, Ac) 作为方案流量异常检测效果的评价指标。Pr为被正确判决的正常样本占所有被判决为正常点的比例,Re为被正确判决的正常样本占所有正常样本的比例,F1为反映方案整体检测效果的综合评价指标,Ac为被正确判决的样本占所有样本的比例,其中Pr, Re,F1∈[0,1],其值越大表明方案检测效果越好。通过20次独立重复实验,检测方案针对3种测试数据集的Pr, Re, F1和Ac如表3所示。

表3 各方案检测性能对比(%)
针对3种测试集,基于BasisEvolution方案将网络流量判决为异常样本的数量明显高于其他方案,虽然该方案可以正确检测出大部分的异常流量,在Pr方面具有绝对优势,但同时也将较多的正常流量错误地判决为异常样本,导致其Re较低。相反地,基于ENDTW-O-CFSFDP方案正常流量的误判率低于其他方案,在Re方面具有一定的优势,且略高于该文方案,但由于该方案的异常流量检出率较低,其Pr较低。基于BIRCH的方案仅根据BIRCH聚类结果判断流量是否异常,缺乏合理的异常判决机制,其Pr与Re均低于该文方案。
进一步,相较于基于ENDTW-O-CFSFDP,BasisEvolution, BIRCH的方案,在综合指标F1值方面,本文方案对Blackhole测试集分别提高了5.3%, 3.3%, 11.0%,对Flooding测试集分别提高了5.8%, 5.4%, 12.4%,对Grayhole测试集分别提高了8.9%, 9.1%, 14.0%;在Ac方面,本文方案对Blackhole测试集分别提高了9.0%, 4.0%, 17.0%,对Flooding测试集分别提高了9.0%, 6.0%, 18.0%,对Grayhole测试集分别提高了15.0%, 10.0%, 20.0%,表明本文方案在检出异常流量的同时,可以有效避免将正常样本判决为异常样本,且针对不同网络攻击造成的流量异常现象都具有较好的检测能力。
如表4所示,相较于基于ENDTW-O-CFSFDP,BasisEvolution, BIRCH的方案,本文方案F1值的均值分别提高了6.7%, 6.0%, 12.5%,Ac的均值分别提高了11.0%, 6.7%, 18.3%,具有较好的异常流量的检出能力,表明本文方案对整个测试样本的正负类判别准确度较好。同时,本文方案根据网络流量特征之间的差异先筛选出可疑流量点,再结合预测值综合判决流量是否异常,因此,本文方案对应的F1值与Ac的标准差最小,表明本文方案针对不同类型网络攻击造成的异常流量都具有较为稳定的检测性能。

表4 各方案F1值、Ac的均值(%) 与标准差对比
综上所述,本文提出的流量异常检测方案可以有效检测由不同WSN网络攻击导致的异常流量,且检测性能稳定。
6 结束语
本文在深入研究网络流量异常检测技术的基础上,提出了一种基于BIRCH的WSN流量异常检测方案。本文方案设计了基于OCF-Tree的BIRCH聚类分析算法,有效克服样本的特征类型和输入顺序对BIRCH造成的影响,提高了聚类的质量和稳定性。同时,提出一种基于预测的特征维度扩充方法,通过在流量特征中增加隐含流量时序关系的预测序列和误差序列,以适应BIRCH聚类分析算法。进一步,根据流量序列特征分析,定义拐点概念,设计基于拐点的综合判决机制,减少BIRCH聚类分析过程对检测结果的影响,保证了流量异常检测的准确性。实验结果表明,相较于同类方案,本文方案在检测效果和性能稳定性方面具有明显优势。
下一步研究中,将针对OCF-Tree结构中分支因子B, L的选择,设计启发式算法求解最优值,同时,解决如何在保证聚类质量的前提下尽可能减小构建OCF-Tree所需内存的问题。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
玩具世界(2022年2期)2022-06-15
房地产导刊(2021年8期)2021-10-13
出版人(2020年4期)2020-11-14
铁道通信信号(2019年6期)2019-10-08
微型电脑应用(2019年8期)2019-08-22
北京航空航天大学学报(2017年7期)2017-11-24
雷达学报(2017年6期)2017-03-26
电子制作(2017年23期)2017-02-02
