
基于访问控制日志的访问控制策略生成方法
2022-02-24 08:55刘敖迪杜学绘单棣斌
电子与信息学报 2022年1期
刘敖迪 杜学绘 王 娜 单棣斌 张 柳
(战略支援部队信息工程大学 郑州 450001)
(河南省信息安全重点实验室 郑州 450001)
1 引言
基于属性的访问控制(Attribute-Based Access Control, ABAC)机制[1,2]使用实体属性作为访问控制的基本要素,适用于解决大数据、物联网等新型开放计算范式所面临的大规模、细粒度动态授权问题[3],得到了广泛地关注与研究。美国联邦政府[4]将ABAC设定为推荐的访问控制模型。Gartner公司预计[5]在2020年,全球将有70%的企业使用ABAC作为主导机制来保护其关键信息资产。但是,原有应用系统可能存在特定的访问控制机制。特别是在开放计算范式中存在大量的实体(用户、设备、资源等)且不同实体间又具有不同的属性信息,将原有访问控制系统迁移到ABAC系统的代价是昂贵且耗时的。如何在满足系统安全性和可用性的前提下,实现ABAC策略的生成是实施访问控制的前提。
现有研究大多致力于基于角色的策略生成研究[6—10],利用角色在用户和权限间建立关联来生成策略。如Dong等人[8]利用Bipartite Networks来生成基于角色的策略,通过剔除不合适的边来提高策略生成质量。周超等人[11]提出了基于形式概念分析的语义角色挖掘算法,通过概念格间相似性分析为角色赋予语义内涵。目前也存在一些针对ABAC的策略生成研究。Xu等人[3]通过遍历用户-权限元组构造候选策略的种子,用约束替换属性表达式中的连接来泛化每个候选规则,以此覆盖用户权限关系中的其他元组生成策略。Medvet等人[12]将ABAC策略挖掘问题转化为多目标优化问题,采用遗传进化算法实现策略的生成,但由于解的搜索空间过大,性能较低。Karimi等人[13]提出了一种基于无监督学习算法的策略生成方法,基于K-modes聚类算法实现近似策略规则模式的抽取。但是,该方法策略生成质量的稳定性不高,且难以设定恰当的聚类值。以上方法都只关注允许类型的访问控制策略,无法解决禁止类型策略的生成问题。针对此问题,Iyer等人[14]提出了一种基于子类枚举的算法,能够同时发现允许类型的授权规则和禁止类型的授权规则,但该算法需要对用户-权限关系进行多次重复迭代计算,时间开销较大。Mocanu等人[15]通过日志来训练一个受限的玻尔兹曼机(Restricted Boltzmann Machine, RBM)来提取策略规则。但只给出了算法在策略空间中第1个阶段的初步结果,算法的最后一个阶段并未实现。另外,还有一些研究[16—18]使用自然语言处理和机器学习技术从文本中提取ABAC策略。但该问题比较复杂,目前为止解决的都是子问题,比如分析自然语言文本来识别与访问控制相关的句子和属性。
基于此,本文提出一种基于访问控制日志的ABAC策略生成方法。利用递归属性消除法实现策略属性的筛选,基于信息不纯度提炼出日志中蕴含的属性-权限关系,结合实体属性选择的结果,实现ABAC策略的生成。并设计了基于二分搜索的策略生成优化算法优化策略生成过程。实验结果表明,只需原始实体属性集中32.56%的属性即可实现对日志中95%的策略覆盖,并能将策略规模压缩为原有规模的33.33%,证实了本方法的有效性。
2 相关定义
定义1 访问控制日志实体是对用户操作行为的记录,可以用4元组{u, o, ac, r}进行表示。其中,u∈User表示主体用户标识,o∈Object表示客体资源标识,ac∈Action表示动作标识,r∈{Permit, Deny}表示操作执行结果,分别为允许操作和禁止操作。因此,日志可按照操作执行结果进行二元分类,分为允许类别日志和禁止类别日志。访问控制日志集是访问控制日志实体组成的集合,蕴含有系统访问控制策略的相关信息。
定义2 候选属性集是指系统中包含的所有属性关系,分为主体用户属性集Cu和客体资源属性集Co。用户属性集包含用户-属性授予关系Ru→a,描述了不同主体用户所对应的属性信息。客体资源属性集包含客体-属性授予关系Ro→a,描述了不同客体资源所对应的属性信息。属性能够从不同的维度和粒度对访问控制的实体进行准确的描述,包括连续值属性和离散值属性。如年龄、时间等属性为连续值属性,性别、单位等属性是离散值属性。
定义3 策略属性集是指访问控制策略中实际用到的用户属性集Au和客体资源属性集Ao以及对应的用户-属性授予关系Ru~a和客体-属性授予关系Ro~a。策略属性集是指对候选属性集进行优化计算得到的属性子集,用于实际的访问控制策略描述,减少无关属性对策略生成的干扰。
定义4 日志扩展策略向量PL是基于候选属性集对日志中涉及的实体进行扩充得到的日志扩展策略向量,可表示为{u, o, ac, r}→{A, r}。其中,A={Au, Ao, Aac},Au表示用户u的属性信息,Ao表示客体o的属性信息,Aac表示操作属性。
定义5 策略结构树T是一种树型的访问控制结构,用来对ABAC策略进行描述。其中,树T的节点可分为叶子节点和非叶子节点。非叶子节点用来表示一个属性及其相应属性值的约束条件,非叶子节点所引发的树的分支表示不同的属性取值结果或范围。若该属性是离散值属性,那么该节点的左分支代表不具有该属性,右分支代表具有该属性。若该属性是连续值属性,那么该节点的左分支代表小于该属性的约束值λ,右分支则代表大于该属性的约束值λ。叶子节点表示该策略的授权结果(允许或禁止)。从根节点开始,沿着非叶子节点进行策略结构树的深度优先搜索到达叶子节点所形成的一条完整路径代表一条完整的访问控制策略。
定义6 基于访问控制日志的ABAC策略生成问题的形式化定义如式(1)—式(3)所示。给定用户集User、客体资源集Object、动作集Action、用户-属性授予关系Ru→a、客体-属性授予数据Ro→a、访问控制日志L和制定生成策略集的策略评估指标I。目标是得到满足策略评估指标I、具有最小策略规模和策略属性规模的访问控制策略集PolicySet。
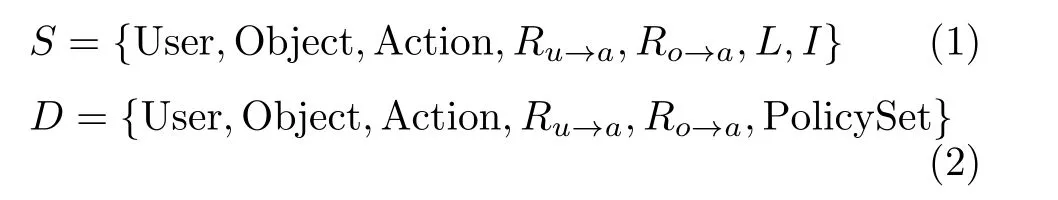

其中,PCN(L), DCN(L), ACN(L)分别表示采用生成的访问控制策略对日志中的允许类别日志记录、禁止类别日志记录、所有类别日志记录进行权限判决,且判决结果为正确的日志数量。PN(L), DN(L),AN(L)分别表示允许类别日志记录、禁止类别日志记录、所有类别日志记录的总数量。
3 策略生成流程
在策略生成过程中包括日志记录扩充、属性选择、策略生成3个阶段,策略生成流程如图1所示。
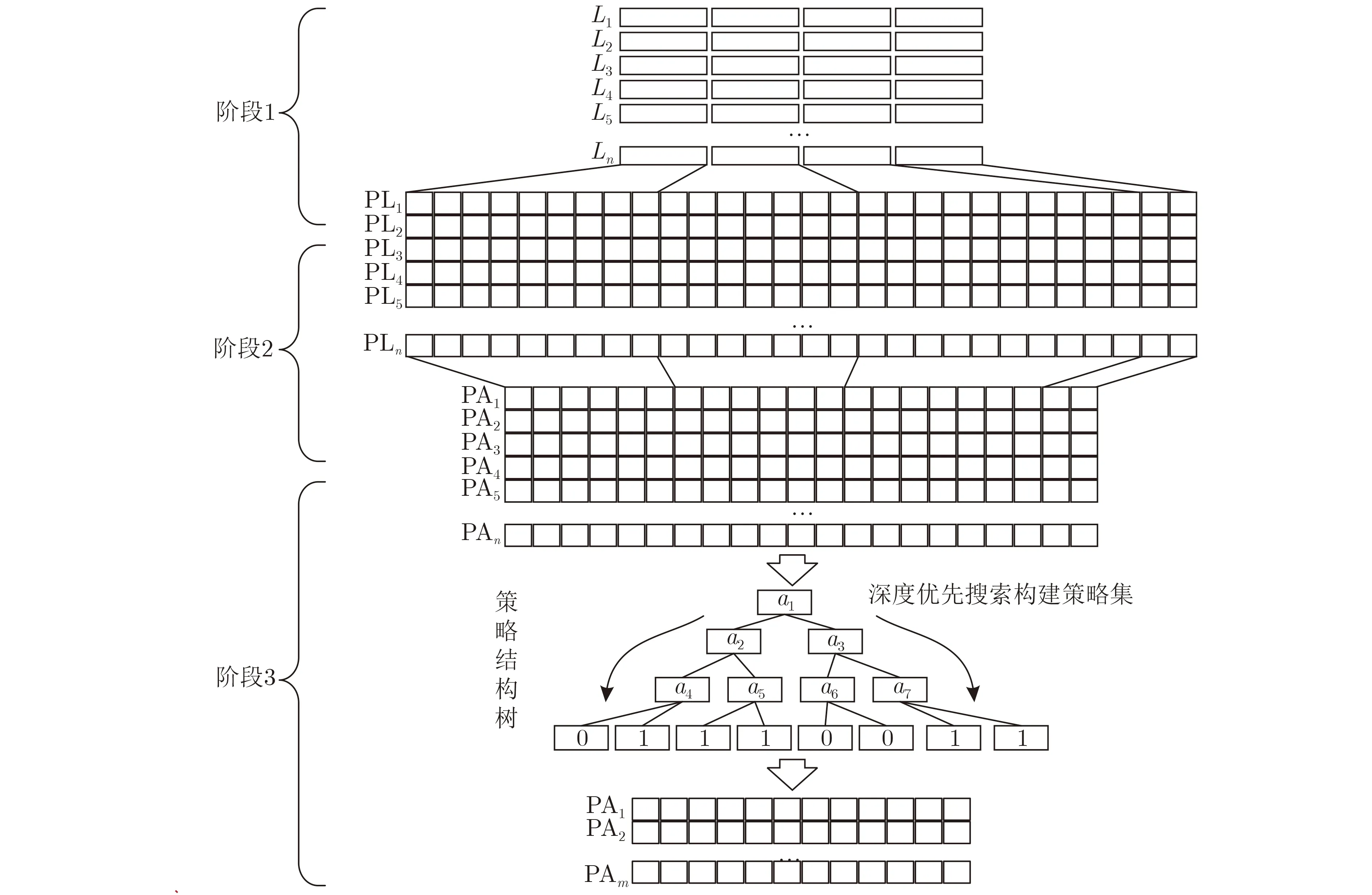
图1 策略生成流程
(1) 阶段1:日志记录扩充阶段。日志记录扩充阶段将访问控制日志记录转化为日志扩展策略向量。每条访问控制日志记录中都包含有该记录所对应的主体用户、客体资源、动作以及操作执行结果等信息。首先,对日志中重复、冲突的日志数据进行一致化处理。删除日志中存在的冗余重复日志记录。将操作不一致的日志记录按照时间维度进行一致化处理,保留最近时间的日志为待扩充的日志数据,删除其他冲突日志记录,构建全局一致的日志记录集合。之后,使用对应的实体属性将一致化后的访问控制日志中涉及的实体要素进行全替换,从而将实体映射到属性空间,得到对应的日志扩展策略向量。日志扩展策略向量的维度与属性空间的维度是相等的。再将实体映射到属性空间的过程中,若该实体拥有对应的属性,则该属性在向量中的对应位置被置为1,否则该位被置为0。得到的向量规模与一致化处理后的日志数据规模等同。
(2) 阶段2:属性选择阶段。属性选择阶段从候选属性集筛选出策略属性集。属性选择阶段基于机器学习分类器的递归属性消除法实现策略属性的选择。构建基于机器学习的分类器,将日志记录扩充阶段生成日志扩展策略向量中的属性作为属性向量,将操作执行结果作为属性向量的标签。采取每次删除一个属性方式,将对应的属性向量与属性向量标签输入到机器学习分类器中进行迭代训练,将训练好的分类器准确率作为被删除属性的重要性评价标准,准确率越低说明删除该属性对分类器的性能影响越大,则该属性越重要;反之,说明该属性对分类器性能影响不大,则该属性越不重要。对每一个属性重要性进行排序,得到属性选择结果。
(3) 阶段3:策略生成阶段。策略生成阶段基于信息不纯度结合属性选择结果将日志扩展策略向量构建为策略结构树,基于策略结构树生成最终的访问控制策略。首先,基于属性选择结果遍历选择出属性重要性最高的前k个属性,利用这k个属性扩充日志实体得到基于k个属性的日志扩展策略向量。借鉴了决策树算法思想,基于日志扩展策略向量计算属性的信息不纯度,选取信息不纯度最大属性作为分裂节点,逐步构建策略结构树。随后对策略结构树进行深度优先搜索,从根节点到达每个叶子节点的一条搜索路径对应一条ABAC策略,以此能够得到该策略结构树所对应的策略集,再对策略集进行评估。通过迭代计算不同k值的策略集质量,选取满足策略覆盖率要求且使属性与策略规模最小的k值对应的策略集作为最终的ABAC策略集。
4 策略生成算法
4.1 属性选择算法
属性选择之前需要将实体属性进行离散化处理。对于离散值属性,直接使用独热编码One-hot形式对属性进行编码,0表示该实体不具有该属性,1表示该实体具有该属性。对于连续值属性,需要将连续值按范围划分为离散值属性,再使用One-hot形式进行属性编码。例如,以1 h为时间间隔,将连续的时间属性[7:00 am~11:00 am]离散化为4个离散值属性[7:00 am~8:00 am, 8:00 am~9:00 am,9:00 am~10:00 am, 10:00 am~11:00 am]。使用离散化后得到的实体属性集对日志进行属性扩展得到日志扩展策略向量。
利用基于机器学习分类器的递归属性消除法[19]实现策略属性的选择。日志扩展策略向量中包括了该记录中涉及的属性信息与操作执行结果。将属性信息构成的属性特征向量作为训练数据,操作执行结果作为训练数据的标签输入到机器学习分类器中进行模型训练,以后向排序方式对策略属性规模进行约简,按照规则迭代删除重要性最低的属性,该方法是一种基于贪心消除的策略属性选择算法。最后得到的策略属性选择重要性序列是属性删除序列的倒序。算法的伪代码描述如表1所示。

表1 属性选择算法
具体步骤如下所示:
(1) 输入日志扩展策略集L={l1, l2, ···, ln}、候选属性集C={c1, c2, ···, cm}以及排序后的属性集A*={}。
(2) 使用候选属性集C训练一个分类器classifier。
(3) 遍历计算候选属性集C中每一个属性ci的得分score(score为无该属性条件下分类器classifier的准确率)。
(4) 依据属性得分对候选属性集C中的属性进行重要性排序。
(5) 挑选出重要性最高的n个属性构成策略属性集A*。
4.2 策略生成算法
通过属性选择算法计算得到策略属性集,再利用策略属性集对日志实体进行扩充得到策略生成算法的输入数据。策略生成算法的核心目标是构建策略结构树,这里借鉴了决策树算法[20,21]思想,使用基尼系数(Gini coefficient)计算实体属性的信息不纯度。将信息不纯度作为属性节点分裂的依据,用来决定策略结构树构建的最优切分点。若以一个非叶子属性节点的信息来进行策略权限判决时的结果不唯一,则将该属性节点进行分裂,分为2个子节点。策略结构树的构建过程,就是属性节点的信息不纯度逐渐降低,挖掘属性-权限内在关系,以此构建访问控制策略的过程。基尼系数Gini的计算方法如式(7)所示其中,Gini(D, A)表示属性A对不同类别的日志样本集合D的不确定性。基尼系数越高表示该属性节点所包含的权限类别越混合。即该信息的不纯度就越高,基尼系数与熵的概念相类似。通过选取信息不纯度最高的属性作为策略结构树的分裂属性,来确保策略覆盖率最高。

算法的伪代码描述如表2所示。

表2 策略生成算法
在策略生成过程中,策略的数量与属性的数量呈现正向相关性,而策略的数量与策略覆盖率也呈现正向相关性。策略生成的目标是在保证生成策略的策略覆盖率尽可能高的同时,策略数量尽可能低。实际的策略生成过程是一个动态规划过程。在达到目标策略覆盖率的前提下,尽量搜索得到属性规模n较小的策略属性集。若使用遍历搜索,最坏情况下的时间复杂度为O(n)(n为属性空间中的实体属性个数)。为了提高最优属性规模的搜索效率,采用分治策略,设计了基于二分搜索的策略生成优化算法(Policy Generation Optimization algorithm based on Binary Search, PQO-BS),该算法最坏情况下的时间复杂度为O(lg n),显著降低了算法的时间复杂度。算法的伪代码描述如表3所示。

表3 策略生成优化算法
5 实验评估
5.1 实验设置
为了验证本文方法的有效性,基于University-Dataset数据集[15]进行仿真实验。该数据集是一个操作类别平衡的数据集,涵盖了16000条用户的访问控制日志信息,其中,8000条为允许类别日志,8000条为禁止类别日志,实体涉及43个类别的属性信息。实验环境如下:操作系统为Win10 64 bit,CPU为Intel(R) Core(TM) i7- 4710MQ@ 2.5 GHz,GPU为GeForce GTX 850 M,内存大小为16 GB,Python版本为3.6。本文分别设计了属性选择性能对比、策略生成性能对比、策略优化性能对比3个实验来对策略生成的性能进行评估。
5.2 实验结果
5.2.1 属性选择性能对比
在属性选择性能对比实验中,本文分别实现了基于随机森林分类器(Random Forest, RF)、逻辑回归分类器(Logistic Regression, LR)、支持向量机分类器(Support Vector Machine, SVM)以及梯度提升分类器(Gradient Boosting, GB)的属性选择算法。图2是采取不同分类器算法的不同属性评分的比较。由图2的结果能够看出,采取不同的分类器算法,对不同属性的重要性评分结果是存在较大差异的,从而导致属性的选择节点也存在差异。图3、图4以及图5分别展现了不同的分类器算法在不同的属性规模条件下,肯定策略覆盖率、否定策略覆盖率以及全策略覆盖率的变化情况。在肯定优先的策略评估中,GB方法的性能是较好的,在属性规模为3时,即可达到对允许类策略的全覆盖。在否定优先的策略评估中,RF方法的性能是较好的,在属性规模为18时,可达到对禁止类策略约93%的策略覆盖率。在综合评估的策略评估中,前半段,GB方法的性能较好,后半段RF方法的性能较好。GB方法的策略覆盖率率先突破90%,RF方法的策略覆盖率率先突破96%。综合评估的实验结果表明了只需原始实体属性集中32.56%的属性信息即可实现对日志中95%的策略权限覆盖,能够将策略规模压缩为原有规模的33.33%,证实了本方案的有效性,能够为访问控制策略管理提供有力支撑。因此,安全管理人员可根据不同属性规模及策略覆盖率的应用要求,灵活选取不同方法实现属性的选择。
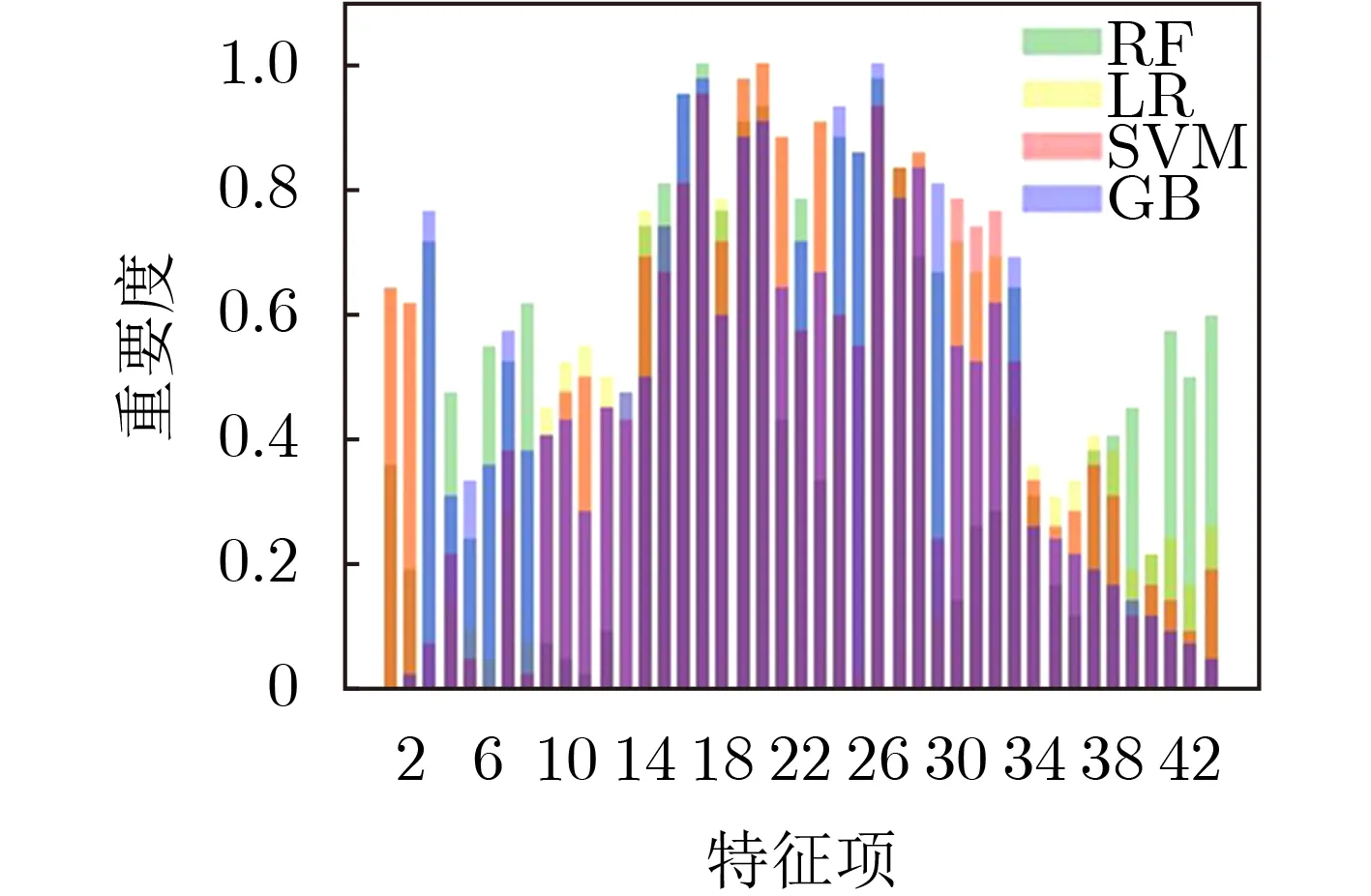
图2 不同算法的属性评分比较
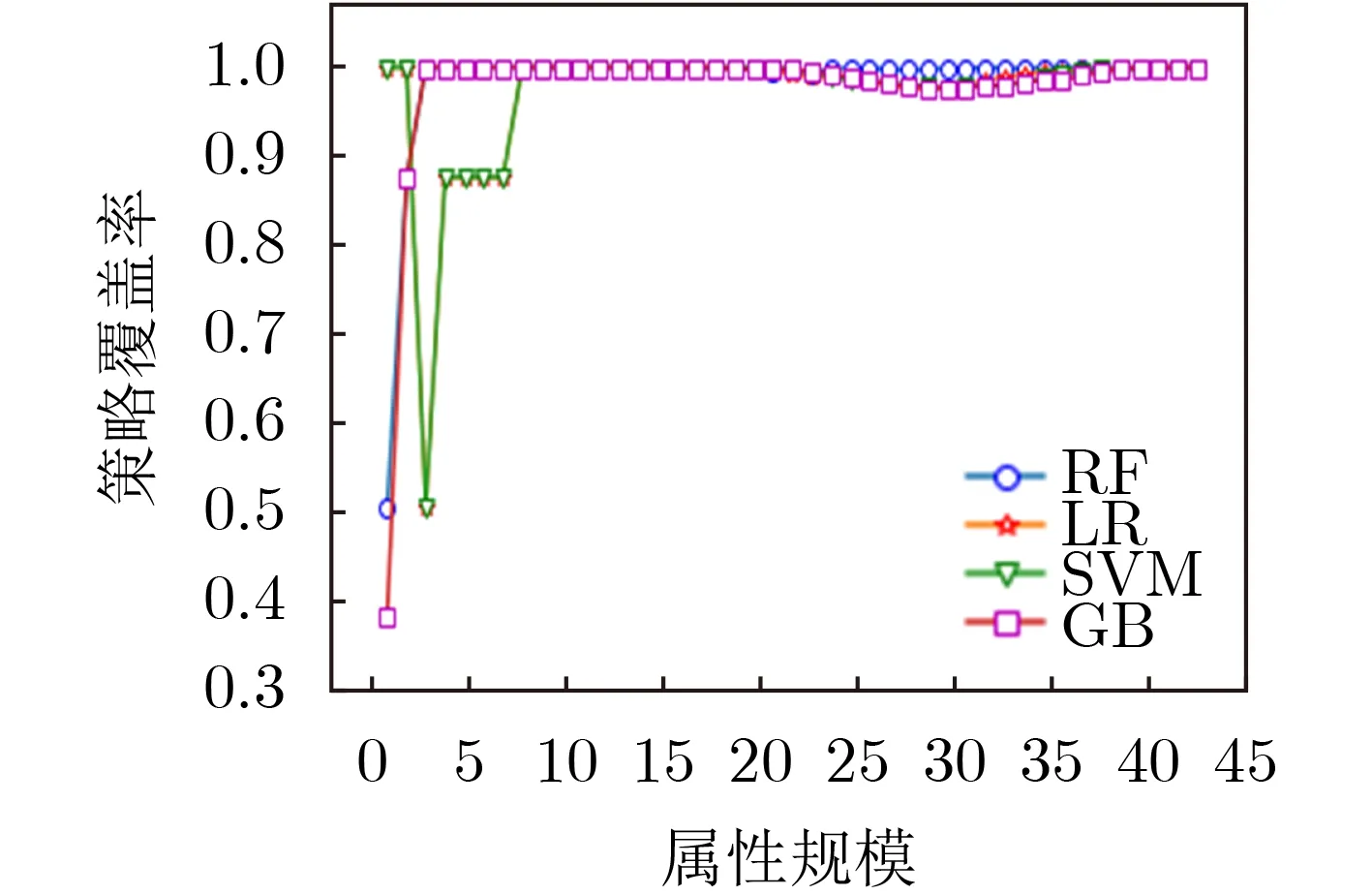
图3 属性规模与肯定优先的关系
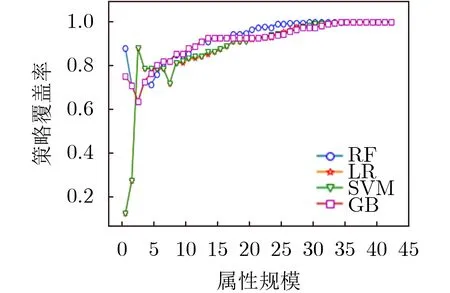
图4 属性规模与否定优先的关系

图5 属性规模与综合评估的关系
5.2.2 策略生成性能对比
如图6所示,为不同属性规模条件下,不同算法生成的访问控制策略规模的对比。策略规模的曲线呈现出了先增长后下降的走向。这说明选取恰当的属性是十分重要的,不恰当的属性将直接影响生成策略的表达能力。属性规模为19是策略生成性能的分界点。当属性规模小于19时,GB方法生成的策略规模较少。而当属性规模大于19时,RF方法生成的策略规模较少。当属性规模为43时,不同方法间没有策略规模方法的性能差异。如图7所示,为不同属性规模条件下,不同算法的策略生成时间开销的对比关系。不同算法的时间开销由大到小分别是GB, RF, SVM和LR。
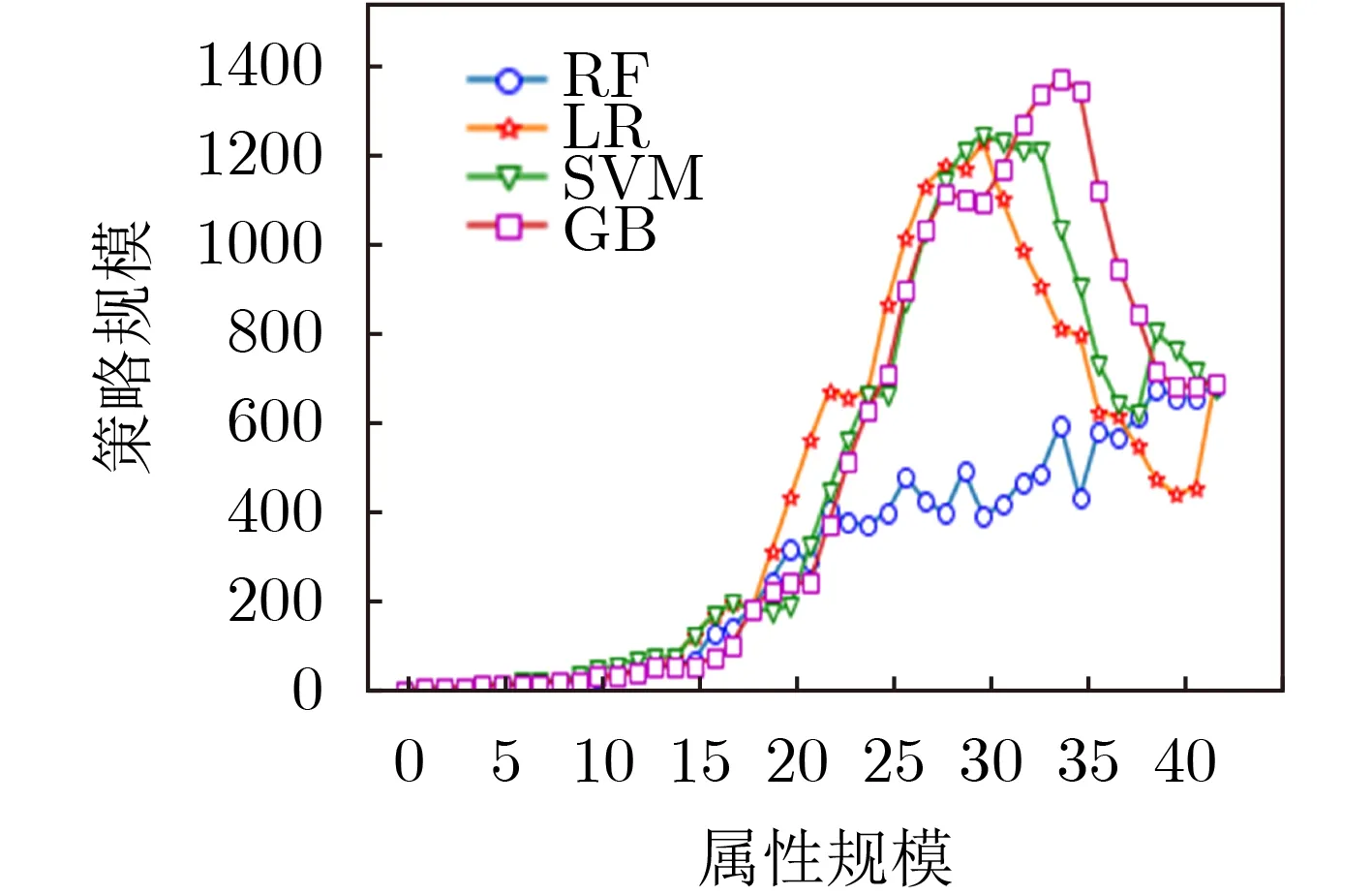
图6 属性规模与策略规模的关系
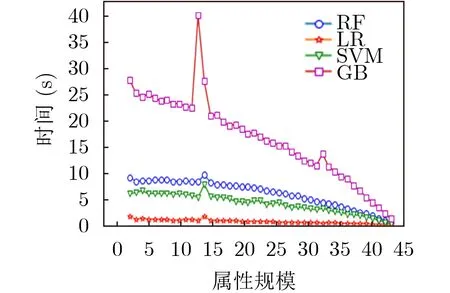
图7 策略生成的时间开销
5.2.3 策略优化性能对比
由图8—图11的实验结果可知,通过二分优化搜索算法能够显著提升策略生成算法的性能,显著降低策略生成算法搜索最优属性规模的开销。在未使用优化算法的条件下,随着策略覆盖率需求的增加,时间开销呈指数增长。而在使用优化算法、不同策略覆盖率需求的条件下,时间开销基本稳定,不受影响。另外,由图7、图10和图11的实验结果发现,虽然单次的策略生成时间开销GB方法要比RF方法高,但是在最优属性规模搜索问题上,GB方法的性能比RF方法更好,能够在更短的时间内达到收敛。图12是不同方法在达到最优策略覆盖率条件下的性能对比,由图12的实验结果发现,本文所提出的方法与当前的主流的子类枚举方法(subenum)相比具有至少约61.28%的性能提升,能够更好地满足策略生成需求。
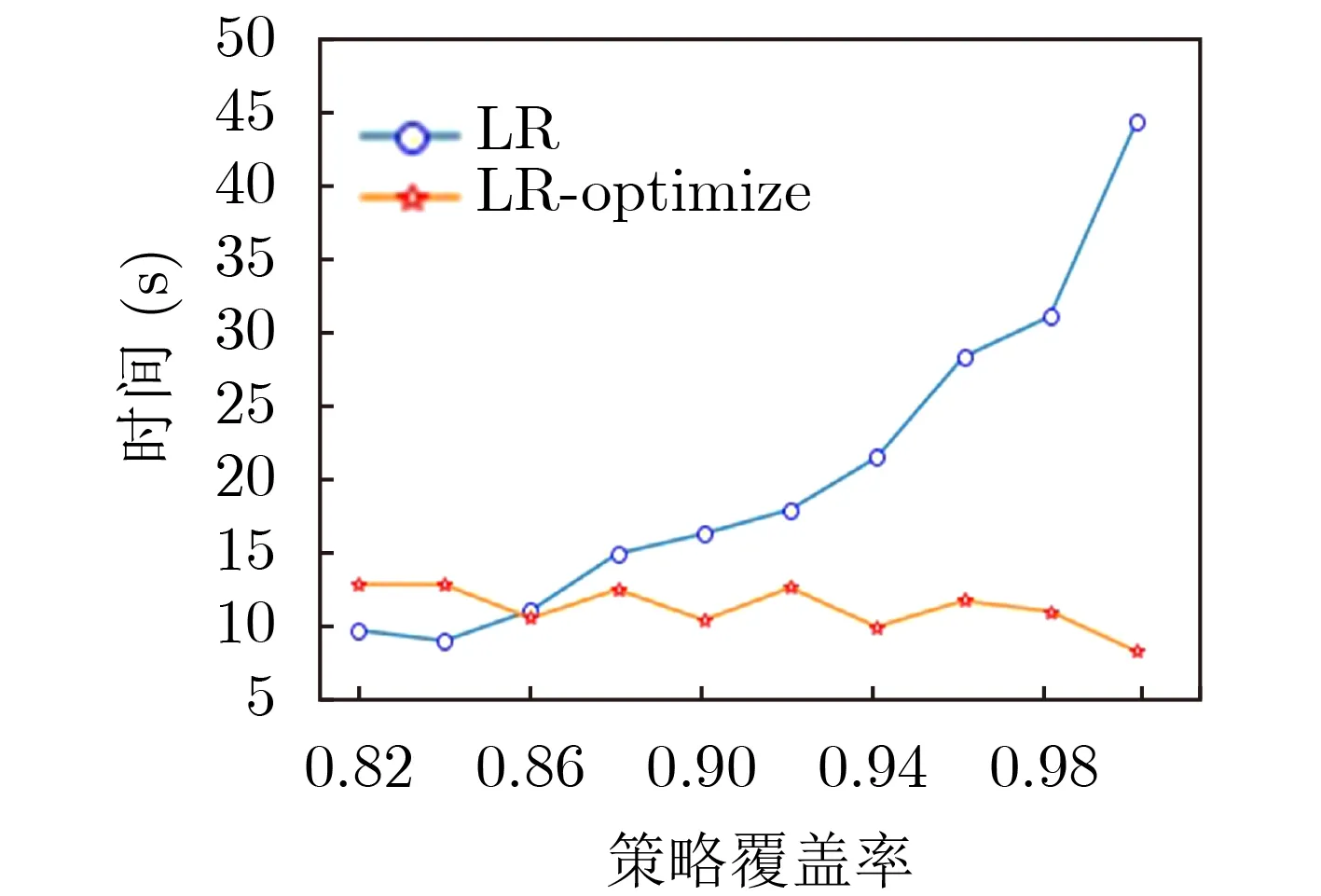
图8 逻辑回归方法性能对比
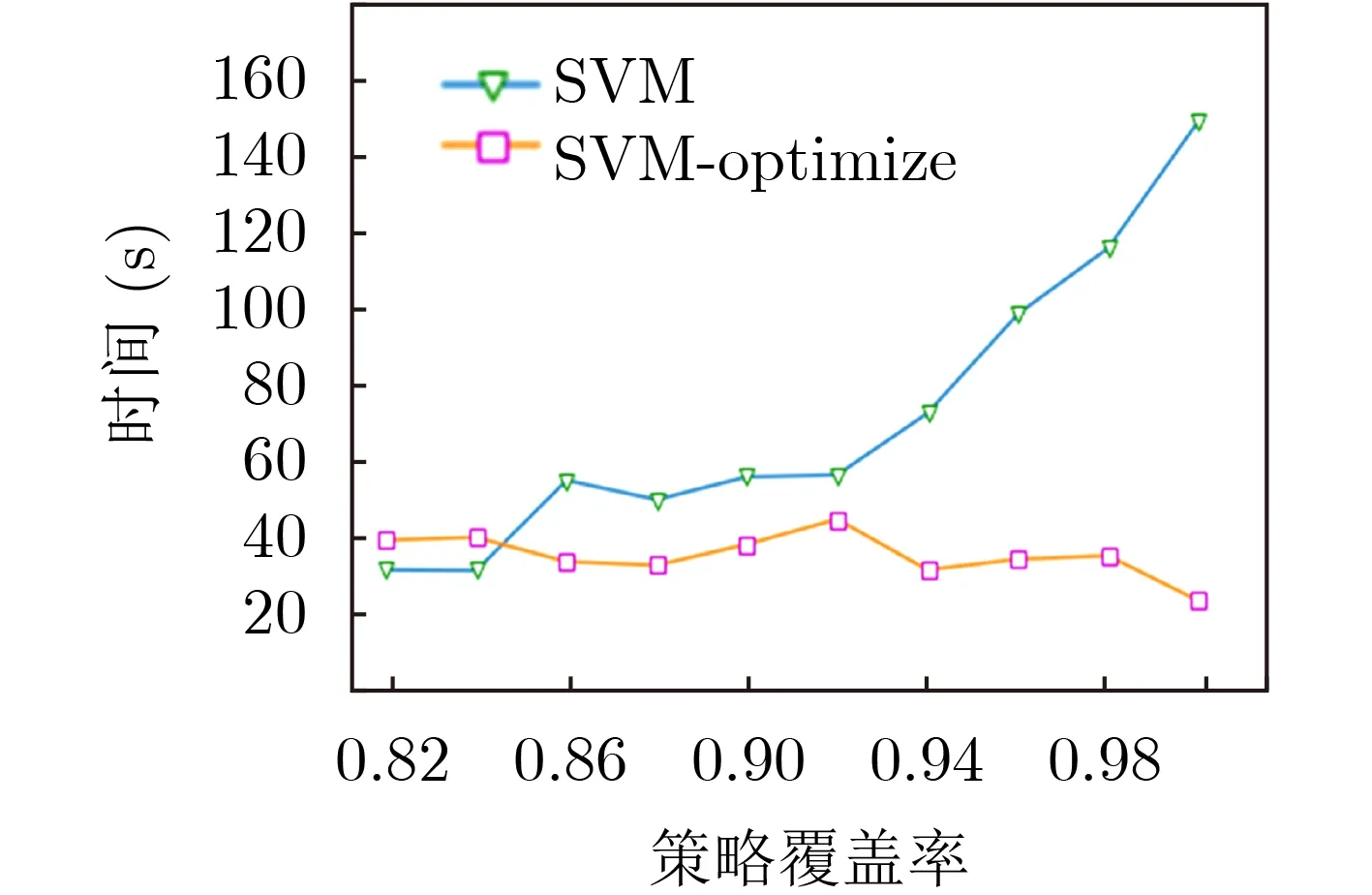
图9 支持向量机方法性能对比
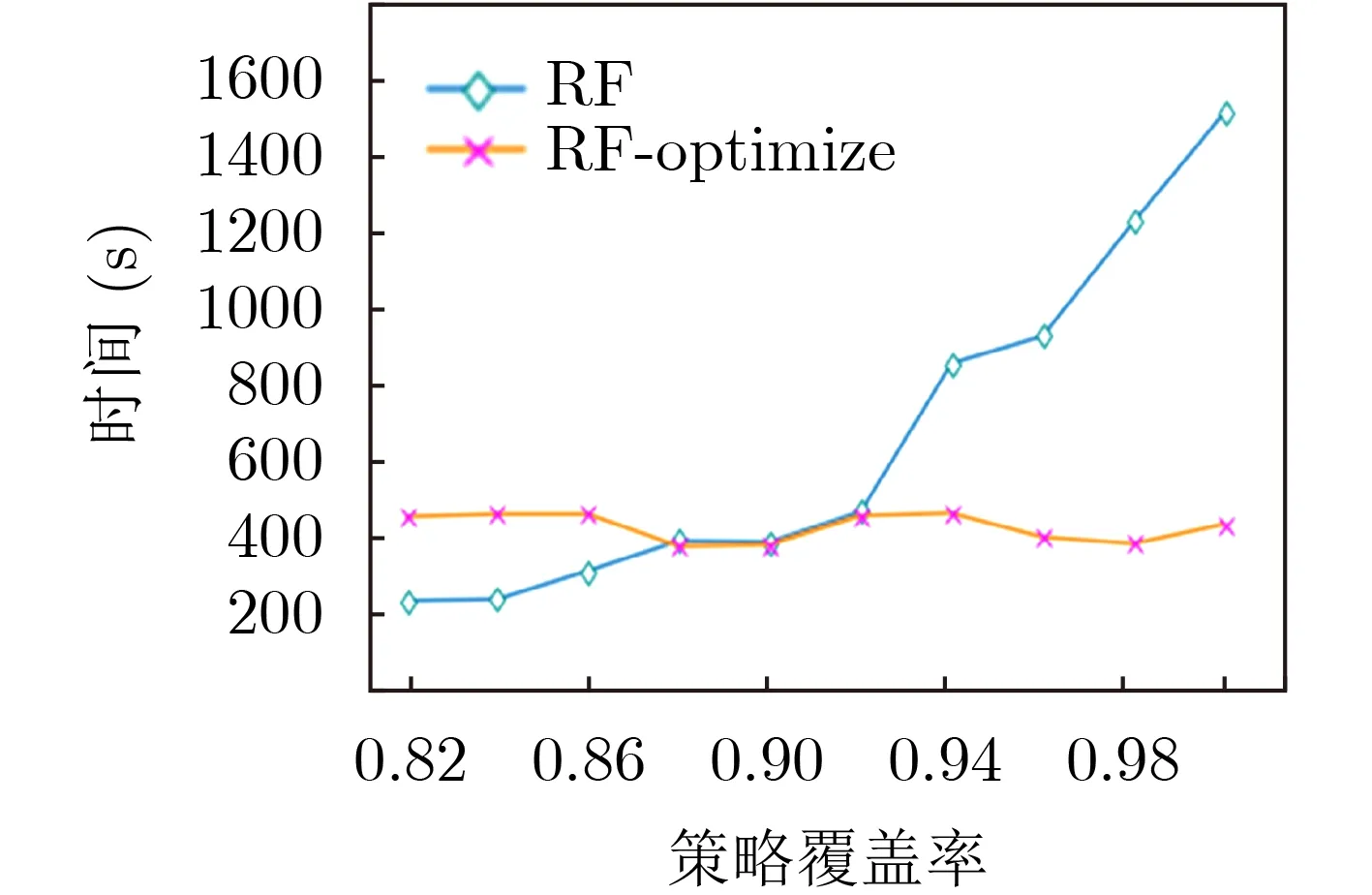
图10 随机森林方法性能对比
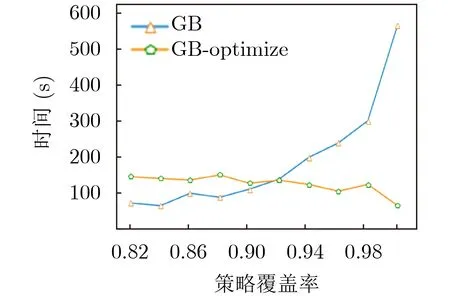
图11 梯度提升方法性能对比
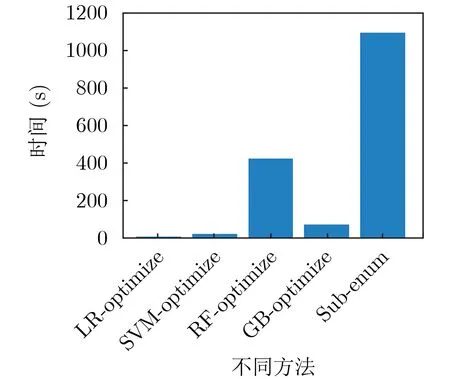
图12 不同方法的性能对比
6 结束语
针对ABAC策略生成问题,本文提出一种基于访问控制日志的ABAC策略生成方法,从日志中提炼蕴含的属性-权限关系,实现ABAC策略的自动化生成,为从其他访问控制机制向ABAC机制迁移提供策略支撑。实验结果验证了本方法的有效性,能够为访问控制系统的策略管理提供有力支撑。
猜你喜欢
电子元器件与信息技术(2022年7期)2022-09-07
华人时刊(2021年13期)2021-11-27
计算机系统应用(2021年2期)2021-02-23
心声歌刊(2020年4期)2020-09-07
电子技术与软件工程(2019年18期)2019-11-18
网络安全技术与应用(2019年4期)2019-04-18
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电子技术与软件工程(2017年14期)2017-09-08
中国新通信(2017年3期)2017-03-11
