
基于改进深度Q学习的网络选择算法
2022-02-24 08:58陈海波
电子与信息学报 2022年1期
马 彬 陈海波 张 超
(重庆邮电大学重庆市计算机网络与通信技术重点实验室 重庆 400065)
(重庆邮电大学计算机科学与技术学院 重庆 400065)
1 引言
随着无线移动通信的发展,由5G异构蜂窝网络、无线局域网等多种接入技术构成的超密集异构无线网络,可为终端提供多种接入方式,支持终端的无缝移动。超密集组网会带来较高的能耗问题,引入休眠机制会一定程度降低能耗,同时,会进一步增强网络的动态性,导致终端服务质量和网络吞吐量等性能均下降。如何在高动态的超密集异构无线网络,保证终端所获得的吞吐量,并提升网络系统综合切换性能,成为当前研究需要解决的重要课题[1]。
目前,国内外相关研究工作较多,从采取的研究方法来划分,网络选择算法大致可以分成两类:(1)基于参数阈值的网络选择算法[2—5],主要是以接收信号强度(Receive Signal Strength, RSS)等参数进行网络选择判决。文献[4]基于RSS的阈值,通过比较候选网络的RSS数值大小,从而进行网络选择。该类算法实现简单,选网参数易于获取,计算复杂度较低;但是,该类算法容易导致乒乓效应,无法完全体现接入网络的服务质量。(2)基于模糊逻辑或强化学习等人工智能方法的网络选择算法[6—14]。文献[6]采用模糊逻辑算法,根据终端应用对QoS参数的需求,通过设计不同的隶属度函数,合理地选择网络。该类算法选网效率较高,但是需要事先建立相应的模糊推理规则库,在输入参数增加的情况下,模糊规则库的数量会激增,导致推理时间复杂度过大。文献[8]基于神经网络算法,根据不同业务类型,对分类后的参数进行训练,从而进行网络选择。该类算法具有强大的学习能力,能够根据环境自适应地进行调整。文献[11]提出一种基于体验质量(Quality of Experience, QoE)感知的网络选择方案,将QoS的网络参数映射成QoE参数,然后利用QoE参数构造回报函数,最后采用Q学习算法进行网络选择。该类算法能够通过不断的学习强化已有收益,从而选择高收益网络;但是,如果网络环境过于复杂,会导致网络控制模块学习效果下降,继而导致无法选择到最佳网络。
对于引入休眠机制的超密集异构无线网络环境,随着该网络环境下基站数量的激增,同时引入休眠机制以节能,导致基站数量发生动态改变,继而导致网络动态性增强,网络拓扑结构时变性提高。同时,终端自身的移动性和基站之间由于密集布网所产生的干扰,导致网络动态性进一步加剧,而现有的相关文献,解决的是常规异构无线网络下的网络选择问题,并未考虑到如此高动态的网络环境,这样会使终端在通过现有选网算法切换到目标网络之后,可能因目标网络突然休眠,导致所获得的吞吐量出现快速下滑,无法为终端提供持续稳定的吞吐量,基站之间产生的干扰又会严重影响到终端的服务满意度,最终发生系统切换性能严重降低的问题。因此,上述算法对于这一严峻问题,关注不足。
通过上述对引入休眠机制的超密集异构无线网络环境进行动态性分析,可以得出,该网络环境具有高动态特性,会使现有的网络选择算法出现切换性能严重下降的问题。因此,本文基于一种改进深度Q学习算法,以保证终端所获得的网络吞吐量,缓解系统因高动态性网络环境导致的切换性能严重降低的问题。同时,针对传统的深度Q学习算法在进行网络选择时,由于在线训练神经网络导致时延过大,出现算法失效的情况,本文利用迁移学习,加速训练神经网络,以降低在线选网的时间复杂度。综上,本文的主要贡献可概括为:
(1)针对由无线局域网络和引入休眠机制的超密集蜂窝网络异构而成的超密集异构无线网络环境,进行动态性分析,以期缓解系统切换性能降低的问题。
(2)本文采用迁移学习对深度Q学习算法进行改良,提出一种基于改进深度Q学习的网络选择算法,降低了传统深度Q学习算法在线上选网过程中的时间复杂度。
2 算法流程
本文算法的流程图如图1所示,主要包括参数采样及初始化过程、深度Q学习选网模型、最优策略及网络选择3个阶段。第1阶段通过周期性采样网络参数的值来初始化深度Q学习选网模型,该模型由线下训练模块与线上决策模块构成,上述两个模块均采用深度Q网络构建;第2阶段利用迁移学习对线下训练模块和线上决策模块进行协同交互;第3阶段通过深度Q学习选网模型得到最优策略并进行网络选择。图1的历史信息数据库包含网络参数的采样值以及历史选网信息数据,作为深度Q学习选网模型的训练数据。
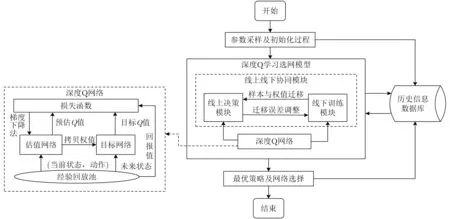
图1 本文算法流程图
3 参数采样及初始化过程
3.1 参数采样
由于本文采用深度Q学习算法对网络选择行为进行建模,因此,在通过深度Q学习算法进行建模的过程中,需要周期性采样网络参数的值来构建深度Q学习的动作空间、状态空间和回报函数,以初始化深度Q学习选网模型,本文采样的参数如下。
(1)接收信号强度表示为
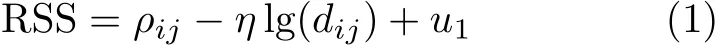
其中,dij为用户终端i到网络接入点j的距离,ρij为用户终端i接收到网络接入点j的发射功率,η为路径损耗因子,u1为服从均值为0、标准差为σ1的高斯白噪声。
(2)终端所获下行吞吐量可表示为

3.2 初始化过程
本文将超密集异构无线网络环境中终端可以接入的候选网络(基站和访问点)用集合N={n1,n2,...,ni}表示;其中终端在t时刻接入候选网络ni表示为at(ni),则本文的动作空间可定义为At={at,at ∈{at(n1),at(n2),...,at(ni)}}。
本文将状态空间定义为St=(rsst,ct,ψt,pt),其中, rsst表示在t时刻各候选网络的接收信号强度集合,ct表示在t时刻各候选网络的吞吐量集合,ψt表示在t时刻各候选网络的干扰影响因子集合,pt表示在t时刻各候选网络的休眠概率集合。

4 深度Q学习选网模型
4.1 改进深度Q学习算法
本文将引入休眠机制的超密集异构无线网络环境下的选网问题,基于深度Q学习算法进行建模求解,该算法过程利用Q函数实现。Q函数表示在状态S下执行动作a,以及采取后续动作所产生累计回报值的期望,定义为
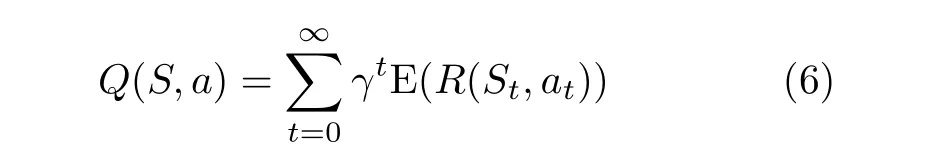
其中,γt ∈[0,1]为折扣因子,用于调整对未来回报的重视程度,随着时刻t的增加而呈现指数型下降趋势,E(·)为期望函数。
由式(6)可得,Q(S,a)在t →+∞时才能收敛到最佳Q值,在实际的网络选择过程中很难实现。因此,深度Q学习算法利用神经网络构建Q(S,a;θ),其中,θ为权值,使得Q(S,a;θ)≈max(Q(S,a))来进行近似求解。
对于传统的深度Q学习算法,终端需要多次进行交互以获取足够样本,但是,这样会使神经网络的训练时间过长,导致算法因延迟过高而失效。综上,本文引入迁移学习[17],提出一种改进深度Q学习算法,来解决上述问题,该算法能够减少终端与网络环境实时交互的次数。同时,相比传统深度Q学习算法以随机赋权值的方法来训练神经网络,迁移线下训练权值之后,使得训练的起点更加接近神经网络收敛条件,从而加速了算法的收敛性。
4.2 线上线下协同模块
4.2.1 样本与权重的生成及迁移
本文所提的深度Q学习选网模型由线下训练模块与线上决策模块构成,而上述两个模块均由深度Q网络构建。为了加速线上决策模块的神经网络训练过程,通过迁移线下训练模块的训练样本与权值,并对迁移后上述两个模块产生的训练误差进行校正,直到误差恒定,整个迁移学习过程结束。其中,训练样本与权值的生成及迁移过程如下:
神经网络的训练样本是由历史信息数据库中不同时刻的当前状态、动作、回报值以及未来状态所构成的,即,其中,。在深度Q网络中,为了高效地训练神经网络,通过设置经验回放池,以缓解训练过程中出现的迭代不稳定问题。因此,本文将线下训练模块的训练样本迁移到线上决策模块中,利用迁移的线下训练样本以及线上学习样本,构建线上决策模块的经验回放池,表示为
(St,at,Rt,St+1)t ∈(0,+∞)

4.2.2 迁移误差调整
在神经网络进行迭代训练时,由于线下训练模块与线上决策模块之间在训练样本、权值存在差异的情况,可能出现训练样本、权值迁移过后,线上决策模块的神经网络训练效果不佳,从而导致神经网络的收敛速度未能达到预期效果。为了解决上述问题,本文将线下训练与线上决策模块之间产生的训练误差定义为策略损失,为了将策略损失降至最低,采用策略模仿机制,通过线下训练模块中,预估Q值Qoff(St,at;θoff)的玻尔兹曼分布,将线下训练模块的估值网络转化为线下策略网络πoff(St,at;θoff),表示为

5 最优策略及网络选择

图2 终端移动模型图


6 仿真结果与分析
6.1 系统模型和仿真参数设置
本文采用5G异构蜂窝网络和无线局域网(Wireless Local Area Network, WLAN)组成超密集异构无线网络环境,无线接入网络均采用正交频分复用(Orthogonal Frequency Division Multiplexing, OFDM)技术。仿真场景如图3所示,并在MATLAB平台进行仿真。仿真场景中,有2个5G宏基站、4个5G微基站和3个WLAN接入点,5G宏基站的半径均为800 m,5G微基站的半径均为300 m,WLAN的半径均为80 m。假设用户随机分布在仿真区域内,每隔一段时间随机改变运动方向。仿真过程中,假设终端在网络选择决策时刻k获得的候选网络参数如表1所示。
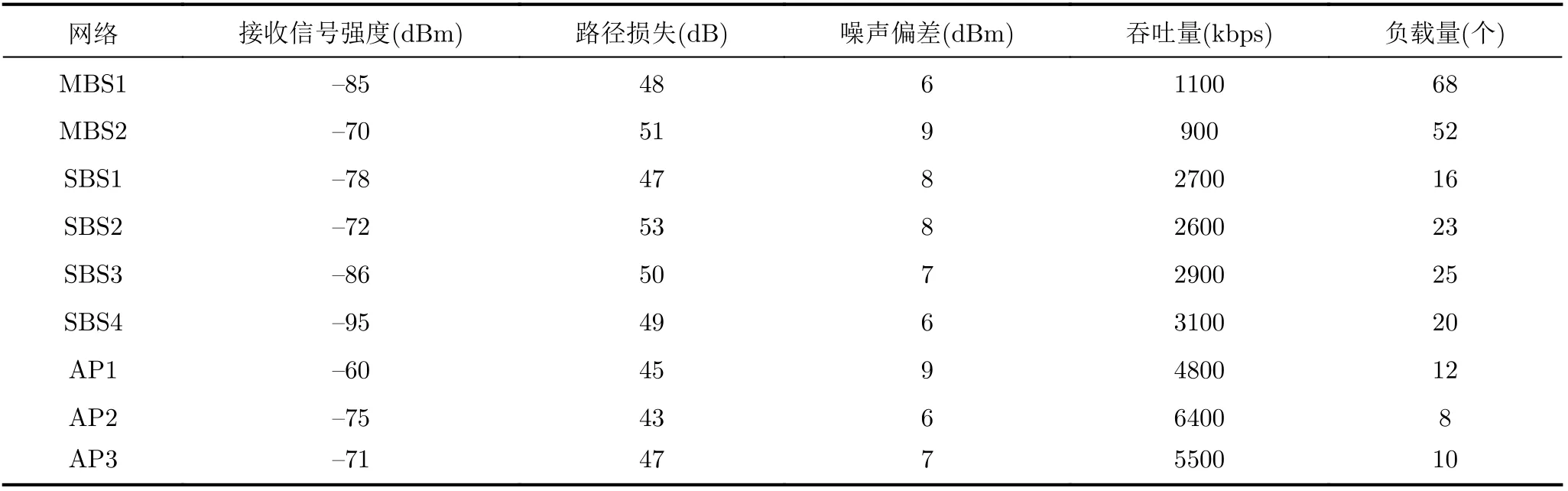
表1 候选网络的参数值
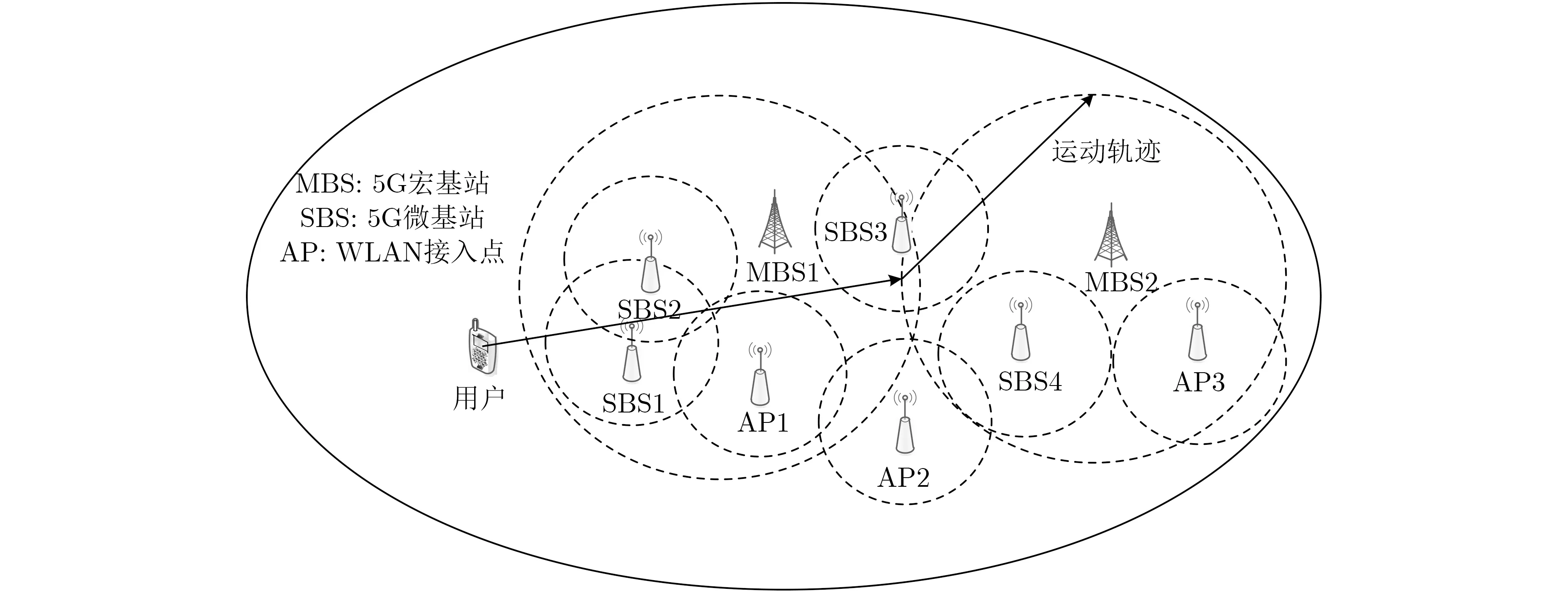
图3 超密集异构无线网络仿真场景图
仿真对比了本文算法与现有基于Q学习(Qlearning)的网络选择算法[11]、基于深度Q学习网络(Deep Q-Network, DQN)的网络选择算法[12]以及基于长短期记忆神经网络(Long Short-Term Memory,LSTM)的网络选择算法[13]。
6.2 时间复杂度分析
时间复杂度是网络选择算法的一个重要指标,本文算法与另外3种算法的时间开销对比如图4所示,随着迭代次数的增加,4种算法所消耗的时间都在增加;但是,本文所采用的算法时间增加的幅度明显慢于另外3种算法。这是因为本文算法采用迁移学习对传统深度Q学习算法进行改进,极大地减少了神经网络训练时间,从而使整个算法的时间消耗降低。对于Q学习算法,在状态与动作空间迅速增大的时候,计算能力持续下降,耗时逐渐加大,与本文算法的时间差距逐渐拉开。而DQN算法和LSTM算法,则直接采用深度神经网络进行迭代运算,在迭代次数巨大的情况下,它们与本文算法的时间消耗差距将更为显著。
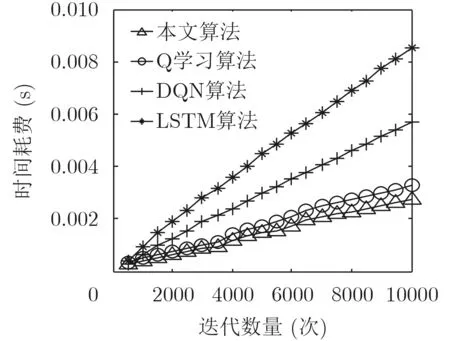
图4 算法时间开销
6.3 信干噪比分析
图5给出了随着仿真次数的增加,终端在4种算法下受到的平均信干噪比数值情况。通过对比可以看到,采用本文算法所得到的平均信干噪比,高于另外3种算法。这是因为本文考虑到终端所受到的干扰,将干扰因素考虑进来,成功预测了基站未来对终端所造成的干扰影响情况,最大限度地降低了因基站所产生的干扰而对终端造成损失;同时,通过引用干扰影响因子参数来构建深度Q学习算法的回报函数,有效缓解了干扰对终端产生的影响,从而为用户带来更高的信干噪比。对于其他3种算法,由于没有专门考虑终端受到干扰的情况,为用户设计合适的回报函数来降低干扰影响,导致了平均信干噪比没有本文算法高。
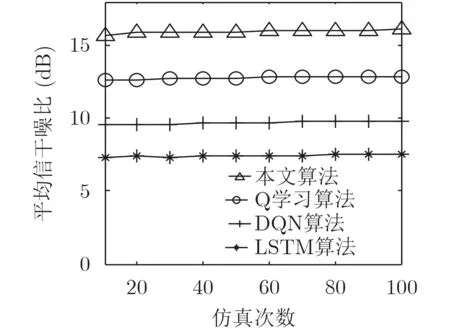
图5 平均信干噪比
6.4 网络吞吐量分析
图6给出了随着仿真次数的增加,终端在4种算法下平均吞吐量变化情况。通过对比可以得出,采用本文算法所得到的平均吞吐量,远高于另外3种算法。这是因为本文采用深度Q学习算法成功预测了基站未来因休眠机制所导致的状态变化情况,使得终端可以根据网络未来发生的动态性变化合理地选择网络,极大地降低了由于基站干扰和休眠情况造成的吞吐量损失;同时,本文根据用户获得的吞吐量定义深度Q学习算法的回报函数,更加符合用户的实际需求。对于3种算法,由于它们既没有充分考虑在未来网络环境下基站的状态,也没有为用户设计合适的回报函数来增加网络吞吐量,从而导致了吞吐量没有本文算法高。
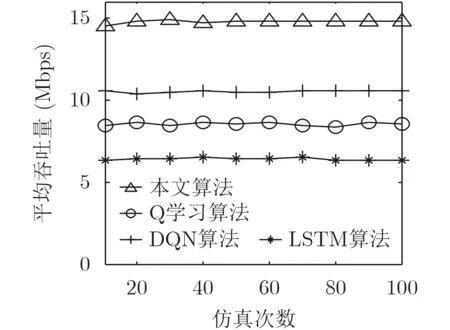
图6 平均吞吐量
6.5 掉话率分析
图7为4种算法的掉话率与用户数之间的比较。由图可以看出,虽然4种算法的掉话率都在缓慢增加,但是,在用户数增加到40以后,本文算法的掉话率增加幅度最小,另外3种算法增加幅度明显高于本文算法。这是因为本文算法相比较其他3种算法,在网络动态性持续增加的情况下,能够预测到未来网络的变化情况,继而为用户提供较高质量的网络进行选择,有效地降低了切换失败的可能性。对于Q学习算法,由于不能够准确地对网络状态进行预测,在用户数增加的情况下,掉话率急剧增加。同样,对于DQN和LSTM算法,由于在训练深度神经网络的过程中,会造成选网时延较高的结果,使得掉话率上升明显。
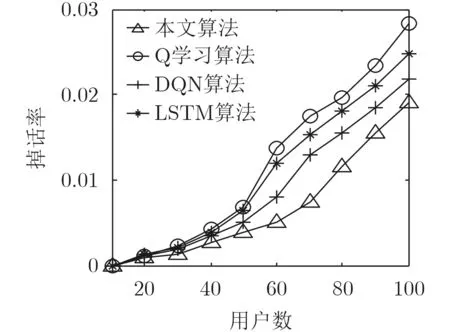
图7 网络掉话率
6.6 乒乓效应分析
图8为用户采用4种算法后产生的总切换次数。由图可以看出,在用户数不断增加的情况下,采用本文算法产生的网络总切换次数,在所述4种算法中始终处于最低。这是因为本文考虑了因网络环境动态性增强,导致算法切换失效率增加,从而发生频繁切换的情况。本文算法成功预测了用户在进行网络选择之后的网络状态变化情况,从而使发生切换的次数大大降低。而另外3种算法,由于均未妥善解决基站因休眠机制带来的网络高动态性影响,导致网络的切换频发,乒乓效应加剧;因此,本文算法能够有效地降低无谓的网络切换。
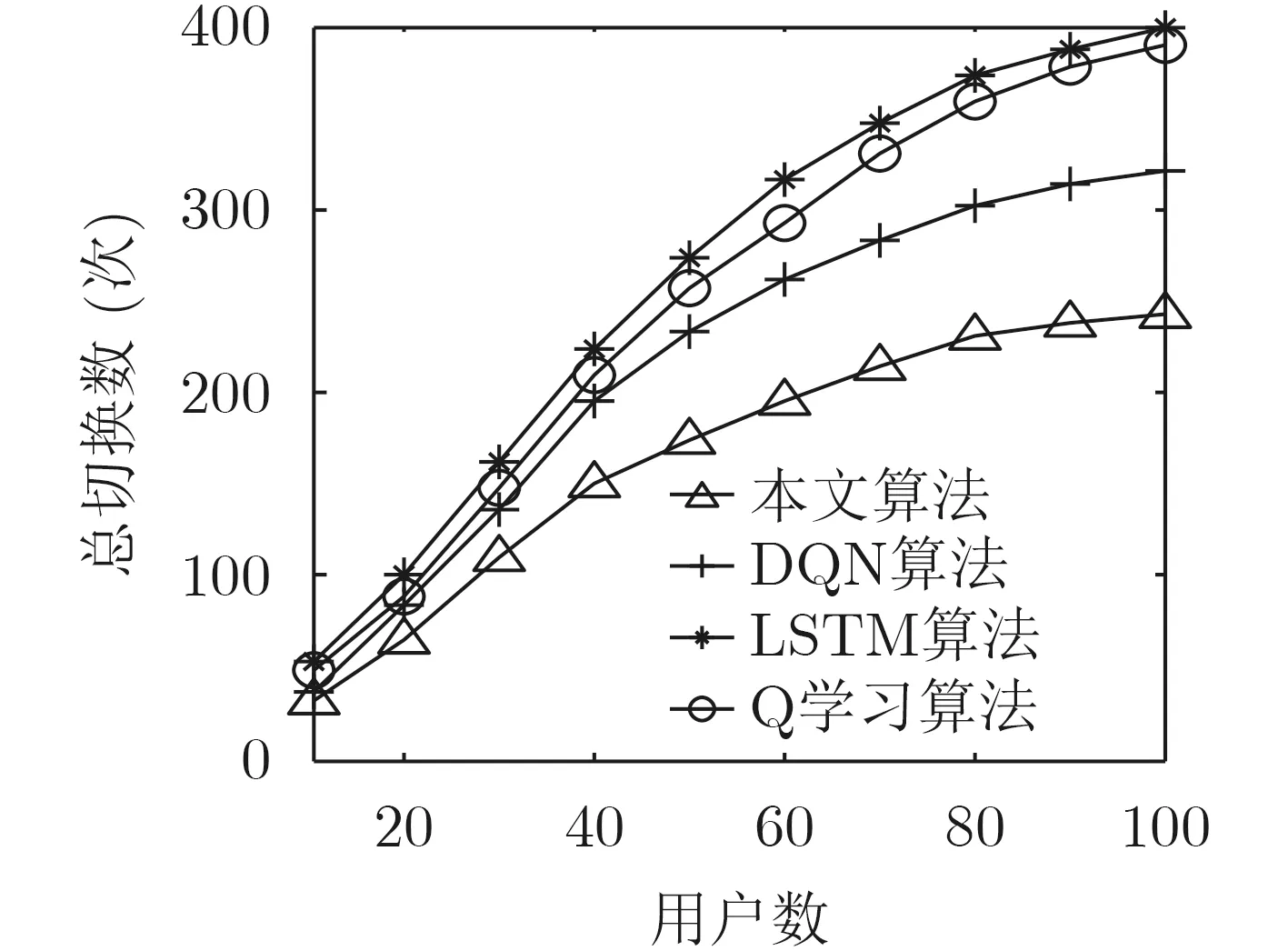
图8 网络总切换次数
7 结束语
本文提出一种基于改进深度Q学习的网络选择算法,缓解了在引入休眠机制的超密集异构无线网络中,由于网络动态性的明显提升而引发系统切换性能降低的问题。通过利用网络参数来构建回报函数,从而尽可能地降低引入休眠机制后,网络高动态性所造成的影响;同时,通过迁移学习对传统的深度Q学习算法进行优化,使得算法的时间复杂度大大降低。实验结果表明,该算法在提升网络吞吐量的同时,降低了时间复杂度,减少了网络切换次数。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
逻辑学研究(2021年3期)2021-11-24
心理学报(2021年6期)2021-06-11
南开管理评论(2021年1期)2021-04-13
通信技术(2020年2期)2020-03-26
恋爱婚姻家庭·青春(2019年9期)2019-12-10
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
电子制作(2017年8期)2017-06-05
