
结合多头注意力机制的旅游问句分类研究
2022-02-24 12:34姜丽婷王路路吐尔根依布拉音艾山吾买尔早克热卡德尔新疆大学软件学院乌鲁木齐830046
计算机工程与应用 2022年3期
吴 迪,姜丽婷,王路路,吐尔根·依布拉音,艾山·吾买尔,早克热·卡德尔 .新疆大学 软件学院,乌鲁木齐 830046
2.新疆大学 信息科学与工程学院,乌鲁木齐 830046
随着人们生活水平的日益提高,越来越多的人在节假日选择外出游玩的方式来释放日常工作学习的压力。然而由于对周围环境的不熟悉,外出旅行的人们在非居住地游玩的过程中会面临各式各样的问题,与此同时当地政府也难以充分利用旅游业的巨大潜力以提高就业率和经济发展水平[1]。若依赖人工解决上述困难则需消耗巨大的财力、物力,而且不能及时解决游客在游玩时面临的个性化问题。如今迅猛发展的人工智能技术使得为游客提供自动化、个性化的服务成为了可能,若开发旅游的自动问答系统能有效解决上述问题。问句分类作为自动问答系统的第一步,其精度直接制约着问答系统的效果[2]。旅游问句文本长度有限且其表达方式口语化现象比较普遍,使得机器难以准确理解其意图完成分类。针对上述难点,本文首先通过双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU)[3]对问句语义信息进行学习,缓解其因长度有限而造成的语义匮乏问题,而后应用卷积神经网络(convolutional neural network,CNN)的卷积层(convolution layer)[4]学习其局部依赖,通过不同大小的卷积核(filter-size)对不同词组的语义信息进行卷积,后用多头注意力机制(Multi-Head-Attention)[5]对卷积后的语义信息分配权重,从不同的语义空间减少歧义词组对结果的负面影响。最后利用Softmax输出预测概率最大的类别作为结果。通过上述方式提高问句语义信息及关键特征的利用率,完成旅游领问句分类。本文做出如下贡献:(1)构建了一个旅游问句的数据集,为以后继续研究提供了基础。(2)本文提出了一种旅游问句的分类模型,在表述不规范且长度较短的旅游问句分类任务中取得的较高的精度,优于现有的主流机器学习模型和深度学习模型。
1 相关工作
问句分类是一个经典的自然语言处理任务。很多学者对此进行研究并提出了诸多解决办法。以往的分类包括两大类方法:传统的机器学习和深度学习。
传统的问句分类方法多基于机器学习的方法,如:支持向量机(support vector machine,SVM)[6]、朴素贝叶斯(Naive Bayesian model,NBM)[7]和K最近邻(K-nearest neighbor,KNN)[8]等。也有学者对传统的机器学习方法进行改进以完成问句分类,如:Bae等[9]提出了一种基于词权重加权和相关反馈的自动扩展词生成技术组合的方法应用到问句分类中,在多个语种中取得了优于TFIDF的成果。
得益于神经网络强大的非线性拟合能力,目前许多学者采用深度学习的方法。杨志明等[10]应用字词向量结合的文本表示方法通过CNN完成问句分类,有效地规避了现有分词方法可能造成的分词不准确的问题,但没有考虑问句的时序信息。Xia等[11]在长短时记忆网络(long short term memory,LSTM)隐藏状态中应用注意力机制(attention mechanism)分配权重完成问句分类,加深了模型对局部重要信息的理解,但该文仅考虑了文本单个方向的语义,没有采用双向的神经网络结构对问句依赖进行捕捉。姚苗等[12]通过堆叠双向长短时记忆网络(stack bidirectional long short term memory,Stack-LSTM)获取文本语义依赖关系,结合自注意力机制(self-attention mechanism)加深模型对局部重要信息的学习,提高了分类的准确率。Liu等[13]利用注意力机制对Bi-GRU获得的语义信息进行权重分配,再通过CNN完成其局部语义信息的学习,取得了很好的问句分类效果。但上述方法都仅使用注意力机制对文本的加强模型对文本重要信息的理解,没有从不同语义空间学习文本局部语义信息。Banerjee等[14]结合了多种深度模型,采用投票等融合方法,完成问句分类,其效果虽然相比与单一分类器,提高约4%,但投票结果的准确率依赖于不同模型本身对问句数据集的拟合程度及模型间的独立程度,其解释能力较差。也有学者在深度学习的基础上引入了机器学习的方法,如:梁志剑等[15]用TF-IDF对Bi-GRU提取到的特征进行权重赋值完成分类。Mohammed等[16]结合了改进TF-IDF和word2vec方法对问题进行分类取得了很好的效果,但相比于注意力机制,TF-IDF仅能根据词频选取较为重要的语义信息,有很大的局限性。Somnath等[17]在深度学习的模型中加入了特征工程,在数据集MSIR16上将问句分类的结果提高了近4%,但特征工程的引入很大程度上降低了模型的泛化能力。
2 模型设计
问句分类任务定义:给定一个旅游问句T将其进行向量化表示为(w1,w2,…,wn)作为模型输入,问句分类就是对该短文本进行语义理解,判定其所属类别,从而达到分类的目的。
以“新疆八日游哪里有有什么好的路线景点规划?”这一问句为例,该问句预处理、分词结果为“新疆八日游哪里有有什么好的路线景点规划”,应归属到“地点”类别,但是该问句的表述并不完全按照语法规范,且文本长度较短。针对旅游问句特殊性,本文首先通过两层Bi-GRU获取的语义信息和词向量拼接的方式来捕获问句长距离语义依赖,优化文本向量化表示,缓解问句文本长度短而造成的数据稀疏的问题。然后使用CNN的卷积层通过不同的卷积核大小对得到的语义信息进行不同词组的卷积,加强模型对局部信息的认知,对“新疆”和“八日游”进行卷积,对“好”“的”和“路线”进行卷积,通过Multi-Head-Attention对卷积后的语义信息进行筛选,放大正确卷积对文本语义理解的作用,减少错误卷积的负面影响,如“有”“有”和“什么”的卷积等。通过上述方式有效缓解了文本表述不规范的问题,并增强了模型的可解释性。最后通过Softmax完成问句分类。
以下简称BGCMA模型,其结构图如图1所示。

图1 BGCMA模型Fig.1 BGCMA model
2.1 文本特征表示
自然语言处理的第一项任务就是提取文本的语义特征,进而完成后续的下游任务。早期学者多采用One-hot向量进行词表示,这种表示方法的结果导致词与词之间没有联系也容易产生维数灾难。Google于2013年提出并开源了Word2Vec,相比于One-hot向量它更加高效,能有效体现词语之间的联系。Word2Vec的基本思想是将不同词语a、b进行,判定组合(a,b)是否符合自然语言的语法规则。它有两种训练方式:CBOW(根据附近词来预测中心词)、Skip-gram(根据中心词来预测附近词)[18]。
2.2 问句依赖关系学习
循环神经网络(recurrent neural network,RNN)[19]被很多学者证明适用于文本处理的深度学习任务中,但面对长文本时,靠后序列的梯度很难反向传播到靠前的语义信息。门循环单元网络(gated recurrent neural networks,GRU)作为RNN的变体,使用了重置门、更新门来决定如何舍弃、更新信息,成功解决了长期依赖的问题。相比于另一种解决该问题的长短时记忆网络(long short-term memory,LSTM)[20],GRU的参数量更少、易于计算。其单元在t时刻更新过程如图2所示,公式如式(1)~(4)所示:


图2 GRU模型Fig.2 GRU model

其中,r t为重置门,z t为更新门,x t为t时刻的输入数据,σ为激活函数,b r、b z、b h为偏置,W r、U r、W z、U z、W h、U h为权重矩阵,⊙表示点乘运算,h t为t时刻GRU的输出。
本文利用Bi-GRU对问句的语义信息进行初步的理解,Bi-GRU是前向h tl和后向h tr融合的GRU,它得到的语义信息更加充分、准确。通过该结构捕获上下文隐含语义关系,公式如所示(5)、(6)所示:

Bi-GRU当前的隐层状态由上述前向h tl、后向h tr和词向量W三部分共同决定。本文将Bi-GRU获取的语义信息和词向量进行拼接,如公式(7)所示:

本文采用两层Bi-GRU,以突出深层次隐含强依赖关系的捕获,通过词向量和Bi-GRU获取的语义信息拼接的方式,获取词汇本身和上下文的依赖关系以得到更丰富的文本表示向量,有效缓解了问句因长度较短而造成的语义稀疏的问题。
2.3 局部关键信息学习
卷积神经网络CNN最初被用于解决图像处理的问题,后被应用到自然语言处理中,现已成为最流行的深度学习模型之一。它由卷积层(convolution layer)、池化层(pooling layer)和全连接层(fully connected layer)组成。其中卷积层的作用是提取局部文本语义信息,这样的操作会产生巨大的计算量,为了防止过拟合,进一步降低网络参数过拟合程度,对卷积后的信息采取池化操作,一般有两种方式,平均池化(mean pooling)和最大池化(max pooling),前者计算列向量的平均值而后者直接取出列向量的最大值。但是这两种池化操作都存在不同程度的信息丢失现象,且会丢失文本的位置信息。所以本文摈弃池化层,仅使用卷积操作提取问句局部关系依赖。
获得Bi-GRU层提取的全局语义信息后,本文使用CNN的卷积操作捕捉局部语义信息相关性,采用k=2、k=3和k=4作为不同大小的卷积核对问句语义信息的局部特征进行感知,即用k维大小的卷积核在问句的语义信息上滑动提取特征。公式如(8)、(9)所示:

其中,b表示偏置,W k表示不同卷积核所对应的权值矩阵,i为第i个特征值,k为卷积操作中卷积核的大小,f为激活函数,y i表示卷积后的输出结果,操作⊕为向量拼接操作,Y为得到的最终特征。
自Mnih等[21]用RNN和Attention机制对图像进行分类,Attention机制被广泛应用于图像、自然语言处理的任务中。其本质是通过Query和Key计算对应Value的权重系数,之后进行加权求和。Multi-Head-Attention是将Query、Key、Value首先进过一个线性变换,然后输入到放缩点积Attention,该操作进行h次(即多头),而且每次Q、K、V进行线性变换的参数W是不一样的,及参数间互不共享。最后将多次计算的结果进行拼接和线性变换得到最终结果,相比于单头的注意力机制,多头的计算方式能够从不同的语义表示子空间里学到更多有价值的信息,该结构如图3所示。

图3 多头注意力机制模型Fig.3 Multi-Head-Attention model
将上述获得的语义信息由Multi-Head-Attention对语义信息进行处理,而非简单的最大池化或者平均池化运算。公式如(10)、(11)所示:

其中,Q、K、V分别表示Y经过线性变换后的得到的Query、Key、Value,d k为输入维度,操作⊕为向量拼接操作,W o为拼接后做线性变换需要的矩阵,h为模型的头数。
基于CNN和Multi-Head-Attention结合的方法优势有三点,第一,有效避免了信息的流失;第二,通过不同filter相邻词卷积弱化了口语的表达方式对结果的不良影响;第三;通过Multi-Head-Attention机制完成对各个语义信息的权重分配,可以更加准确的问句实际要表达的意图。
2.4 Softmax分类
自通过上述对文本的语义信息表示及处理操作后,利用Softmax分类器进行问句分类。将输入值转换成概率值。模型在最后输出概率最大的类别。公式如式(12)所示:
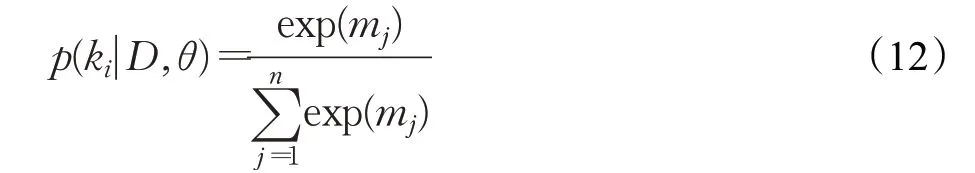
其中,i为分类的标记,本文实验用到了6个标记类别,所以i∈{1,2,3,4,5,6},D为输入问句,θ表示模型训练学习到的参数,模型最后输出p(k i|D,θ)概率值最大的类别。
3 实验
3.1 实验设置
3.1.1 实验环境说明
为验证方法可行性,本文设计了以下实验。硬件配置:GPU为RTX-2080Ti,CPU为i7-9700。软件环境:操作系统为Ubuntu18.04,编程语言为Python3.6,框架为
PyTorch1.1.0。
3.1.2 数据集
由于没有公开的旅游问句数据集,本文在携程、去哪儿等各大旅游网站爬取问句并对其进行了筛选、清洗、标注等预处理操作,共计9 536条。人工标注了六个类别,分别是:时间(1 970条)、描述(2 383条)、地点(1 732条)、具体金额(1 714条)、人物事迹(201条)、综合(1 536条)。具体示例见表1。

表1 数据集示例Table 1 Examples of data sets
按照7∶2∶1切分数据为训练集(6 656条)、验证集(1 920条)、测试集(960条)。数据集类别及分布如表2所示。

表2 数据集分布Table 2 Distribution of data set
3.1.3 对比模型介绍
为了验证BGCMA模型在旅游问句任务中的性能,本文选取了若干主流的文本分类模型进行对比实验。
(1)NBM:以贝叶斯原理为基础,用概率统计的方法完成问句的分类任务。
(2)SVM:本文在该任务中分类效果最好的Linear作为核函数。
(3)KNN:通过聚类的方式完成问句分类任务。
(4)CNN:CNN模型通过卷积、池化、全连接对问句进行分类。
(5)GRU:通过单向的GRU网络捕捉旅游问句语义依赖,进行问句分类。
(6)Bi-GRU:由前向GRU和后向GRU组合而成,双向的GRU可以更好地捕捉其语义信息。
(7)Bi-GRU+CNN:在Bi-GRU后面接CNN,在捕获全句的语义依赖的基础上通过CNN加强对局部信息的理解。
(8)Bi-GRU+Attention:在Bi-GRU的基础上增加Attention机制,对Bi-GRU学习到的语义信息进行权重分配,完成问句分类。
(9)Transformer:通过以Multi-Head-Attention为基础的Encoder部分,对语义信息进行学习完成分类任务。
3.1.4 评价标准
在本文的实验中,采用三个精度评价指标来评估模型,分别是精准率(Pre)、召回率(Rec)、F1值(F1-score),计算公式如(13)~(15)所示:
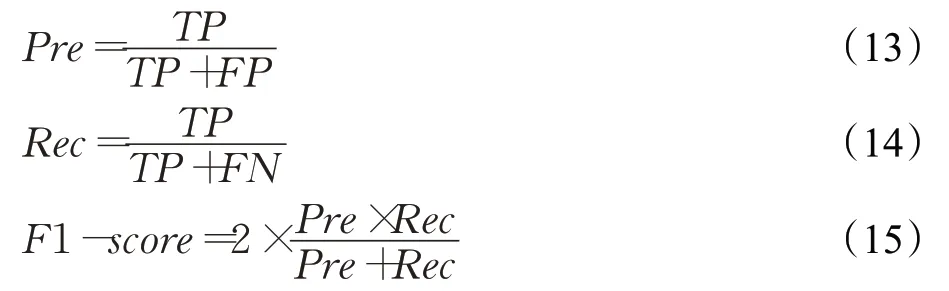
其中TP、FP、FN、TN的含义如表3所示。

表3 混淆矩阵Table 3 Confusion matrix
为进一步验证模型的时间效率,本文引入了时间指标用于评估不同模型在同一任务下的训练时间和测试时间,单位为s。
3.2 实验结果与分析
在旅游问句数据集上,将本文提出的BGCMA模型与NBM、SVM、KNN、CNN、GRU、Bi-GRU、Bi-GRUCNN、Bi-GRU-Attention、Transformer多种机器学习和深度学习模型进行对比实验,实验结果如表4所示。

表4 实验结果对比Table 4 Comparison of experimental results
由表4可知,在旅游问句分类的任务上,NBM、SVM和KNN这一类机器学习的算法精度要明显低于深度学习模型,但是这类模型的训练时间相对较短。其中,NBM的训练时间和测试时间均为最短,这是因为该模型的核心思想是条件概率的计算,它假设所有特征的出现相互独立互不影响,每一特征同等重要,但在实际语义表达中并非如此,所以该模型只取得了82.26%的F1值。KNN的计算量较大,是时间消耗最长的机器学习模型,然而本文实验的数据集较小,导致了该模型在旅游问句的分类任务上的精度表现最差,仅取得了78.50%的F1值。相比于KNN,SVM对小样本数据集的适应性较好,在三种机器学习模型中,该模型的精度最高,在Pre、Rec和F1-score三个指标中分别取得了84.60%、84.68%和84.15%的性能。
由表4可知,在旅游问句分类的任务上,深度学习模型的精度要明显高于机器学习。CNN和GRU模型相比,GRU取得了90.07%的F1值,比CNN模型高0.35个百分点,这是由于GRU模型考虑了问句的时序信息,而CNN模型对文本的时序信息不够敏感所导致的,但CNN不需要像GRU一样逐词地完成运算,其训练时间为所有深度学习模型中最短。GRU和Bi-GRU模型相比,Bi-GRU模型在问句分类任务的性能优于GRU模型,原因在于Bi-GRU模型在GRU模型的基础上增加了一个反向的GRU,前后向信息融合,更好地获取了问句上下文的语义信息,但是Bi-GRU需要完成前向和后向两次运算,需要的时间较GRU长。Bi-GRU+CNN模型和Bi-GRU+Attention模型性能均比Bi-GRU模型好,这是因为Bi-GRU+CNN模型在Bi-GRU模型基础上增加了CNN,利用了CNN局部卷积思想,加强了局部语义信息的理解和学习,而Bi-GRU+Attention模型在Bi-GRU模型基础上增加了Attention机制,对获取的语义信息赋予权重,能够有效甄别更重要的信息。由于在实验中设置了早停,所以Bi-GRU+Attention的收敛速度较快,完成训练的时间较快。而以多头注意力机制为基础的Transformer,利用位置信息编码,有效考虑了问句的时序性特征,通过不同子语义空间的Attention机制,在Pre、Rec和F1-score三项指标中取得了91.14%、91.04%和90.97%的结果,多头注意力机制的效果较Bi-GRU+Attention的单头注意力机制的性能更好,但是Transformer的时间复杂度为O(n2),训练时间和测试时间均比较长。但Bi-GRU+CNN的在旅游问句数据集的表现稍优于Bi-GRU+Attention和Transformer,这是因为旅游问句数据集的长度较短,无用的信息相对较少,所以采用CNN进行局部特征的学习要强于Attention机制。
BGCMA模型首先通过两层Bi-GRU学习问句的上下文信息,捕获其长距离语义依赖,和预先训练好的词向量拼接充分学习问句语义信息,缓解旅游问句语义稀疏的难点。然后通过CNN的卷积层对不同词组进行卷积,学习其局部关系依赖,最后利用Multi-Head-Attention替代传统的池化层对卷积后的结果进行进一步的学习和感知,通过注意力的方式筛选正确的正确词组的卷积,提高了分类精度。BGCMA结合了Bi-GRU、CNN、Multi-Head-Attention的优点,在Pre、Rec、F1-score三个指标中分别取得了92.14%、92.19%和92.11%的结果,在精度指标中全面优于现有主流的深度学习模型和机器学习模型。但为了解决模型对不规则表达的问句的学习,该模型的训练时间为最长,但是其测试时间较SVM和KNN短,能够为自动问答系统的后续工作提供高效的支持。
3.3 消融实验
模型实验参数取值如表5所示。为评估BGCMA模型中关键因素的贡献,本文进行了消融实验。

表5 实验参数设置Table 5 Experimental parameter settings
3.3.1 Learning-rate对实验性能的影响
学习率(Learning-rate)的作用是控制模型的学习进度,会影响模型的最终实验效果。在旅游问句分类任务中,Learning-rate分别选取0.01、0.003、0.001、0.000 3、0.000 1进行实验,结果见表6。
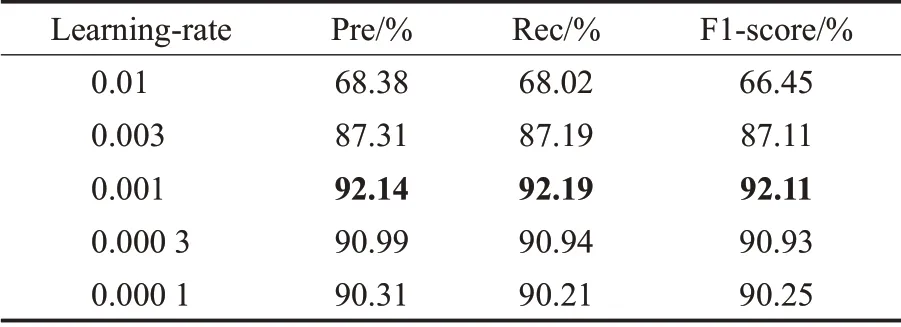
表6 学习率对模型性能的影响Table 6 Effect of learning-rate on model performance
由表6可知,Learning-rate的取值为0.001时,模型的结果最优。但当学习率增大到0.01时,模型的性能在Pre、Rec、F1-score分别下降了23.76、24.17、25.66个百分点,这是因为学习率过大,在训练过程中跨过最优值,长时间无法收敛,模型无法取得最好的训练效果。当学习率降低至0.000 1时,模型的性能在Pre、Rec、F1-score分别下降了1.83、1.98、1.86个百分点,这是因为学习率过小,模型容易陷入局部最优点。
3.3.2 Bi-GRU的层数对实验性能的影响
神经网络的层数与模型的复杂度直接相关,会影响模型与实验数据的拟合程度。对Bi-GRU的层数取1层、2层、3层进行实验,结果见表7。

表7 层数对模型性能的影响Table 7 Effect of number of layers on model performance
由表7可知,Bi-GRU的层数取2时,模型取得了最好的效果。当层数增加至3层时,Pre、Rec、F1-score分别下降了1.14、1.67、2.13个百分点,这是因为层数过大使得模型在测试集上的泛化能力下降,出现了过拟合的现象。而层数取1层时,Pre、Rec、F1-score分别下降了2.48、2.61、3.87个百分点,这是因为层数过小适合模型出现了欠拟合的现象,模型无法很好的拟合数据集。
3.3.3 Filter-size对实验性能的影响
CNN卷积核大小的选取,会影响到文本词语表征的提取,进而影响模型与实验数据的拟合程度。对CNN的filter-size取(2,3,5)、(2,3,4)、(3,4,5)进行实验,结果见表8。
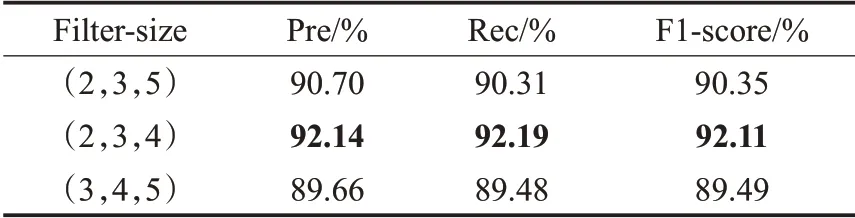
表8 卷积核对模型性能的影响Table 8 Effect of filter-size on model performance
由表8可知,CNN的卷积核取(2,3,4)时,模型的性能最好。当卷积核大小取(2,3,5)或者(3,4,5)模型的性能在Pre、Rec、F1-score的值上都有不同程度的下降。这是因为卷积核选取的偏大时,模型会引入过多的噪声,从而导致模型性能有所下降。
3.3.4 Number-heads取值对实验性能的影响
多头注意力机制可以在不同的空间对语义信息进行理解,其Number-heads会影响注意力的效果进而影响模型的最终结果。对多头注意力Number-heads取4、8、12进行实验,结果见表9。
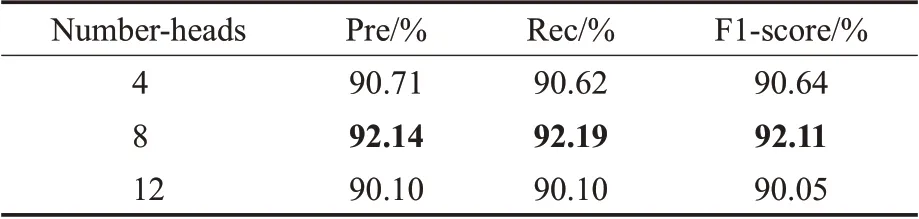
表9 头数对模型性能的影响Table 9 Effect of number-heads on model performance
由表9可知,Multi-Head-Attention的头数取8的时候,模型性能最好。当头数增加到12时,Pre、Rec、F1-score分别下降了2.04、2.09、2.06个百分点,这是因为头数过大会导致模型的结构更加复杂,过多的注意力会引入噪声使得模型性能下降。而当头数减少到4时,Pre、Rec、F1-score分别下降了1.43、1.57、1.47个百分点,这是因为头数过小会导致模型无法捕捉到多方面的信息。
4 结束语
针对旅游问句的文本长短较短和口语化的特点,本文提出了BGCMA模型,实验结果表明,该模型在旅游问句任务中取得了较高的精度,优于主流的机器学习和深度学习模型,验证了其优越性,为解决旅游问句分类提供了参考。在未来的工作中,将继续扩展数据集,考虑引入知识库,在保持高精度的同时降低模型的训练耗时,期望取得更快更好的问句分类效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
甘肃教育(2020年22期)2020-04-13
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
