
结合自注意力和残差的BiLSTM_CNN文本分类模型
2022-02-24 12:34杨兴锐赵寿为张如学杨兴俊陶叶辉
计算机工程与应用 2022年3期
杨兴锐,赵寿为,张如学,杨兴俊,陶叶辉
1.上海工程技术大学 数理与统计学院,上海 201620
2.重庆大学 机械与运载工程学院,重庆 400044
3.上海工程技术大学 管理学院,上海 201620
文本分类是自然语言处理中最基本的任务之一,模型通过大量的非结构化数据学习到某种规则,将其他文本按照此规则进行分类。文本分类在情感分析、舆情分析、垃圾邮件过滤等领域内有着广泛的应用,怎样从非结构化的文本中提取出有效的信息在学术界以及工业界受到越来越多学者的关注。
文本分类任务还可以应用到其他任务领域,例如舆情分析:有关政府单位可以依据网络上人们对所在地区疫情情况的评论信息,动态地把握本地区居民的情绪,进而采取不同的措施进行疫情防护,高效率地战胜疫情。当多分类任务变为二分类时,这样的任务成为情感分析,电商网站运营人员可以依据相关产品的评论信息,对产品做出动态调整,同时还可以更好地把握店铺整体的实力情况,有利于商家进行高效率地整改。
1 相关工作
文本分类问题常见的研究步骤是分词、去停用词、建模以及预测。常见的方法主要是使用统计机器学习模型,先利用TF-IDF[1](term frequency-inverse document frequency,TF-IDF)方法将文本数据向量化并进行特征提取,然后使用支持向量机(support vector machine,SVM)、随机森林以及逻辑回归等机器学习模型建模。TF-IDF方法以“词频”来刻画词语之间的信息,各个词语之间相互独立,忽略了词语的顺序,同时该方法并没有考虑到词语的语义信息。因此,有学者提出用神经网络模型对文本建模并将文本进行向量化。Bengio等人[2]提出了神经网络语言模型(NNLM)用于求解二元语言模型,但是该模型隐藏层到输出层之间的计算较为复杂。于是Mikolov等人[3]提出了Word2vec词向量模型来获得更加高效的词向量,建立了CBOW(continuous bagof-words,CBOW)和Skip-Gram两种方法,其中CBOW方法利用周围词建立概率语言模型预测中间词,Skip-Gram利用中间词建模预测周围词。这两个模型方法与NNLM模型相比,最大的区别在于没有隐藏层,使得计算更加高效。
Word2vec模型提出后,一系列结合深度学习模型的算法被运用到文本分类任务中。由于循环神经网络(recurrent neural network,RNN)模型存在梯度消失以及梯度爆炸问题,为了改善这些问题,有学者在模型中使用Relu激活函数以及将输入数据进行归一化处理。其中,Hochreiter等人[4]提出了长短期记忆网络(long short-term memory,LSTM),该模型主要通过遗忘门、输入门以及输出门控制信息的遗忘、输入以及输出,能够很好地避免长期依赖以及梯度消失的问题。
为了更好地学习到词语之间的双向信息,Schuster等人[5]提出了双向长短期记忆网络(bi-directional long short-term memory,BiLSTM),该模型是前向LSTM和反向LSTM的组合,用于对文本建立上下文信息。在含有程度不同的褒义词和贬义词等词语的情感分析任务中,则要求进行更加细粒度的文本分类,需要模型对情感词、肯定词以及程度副词等之间建立较好的交互。因此,通过BiLSTM模型能更好地捕获双向语义信息。
卷积神经网络(convolutional neural networks,CNN)在图像处理领域取得了突破性的进展。因此,有学者将CNN引入自然语言处理领域。Kim[6]提出了TextCNN模型,该模型主要通过卷积运算与池化运算对文本进行建模,卷积运算可以很好地捕获到文本之间的信息。TextCNN模型在情感分类任务中凭借其出色的准确率受到了学术界以及工业界的关注。何炎祥等人[7]提出了基于微博表情符号映射情感空间的深度学习模型EMCNN,有效增强了模型的情感分析效果,同时模型的训练时间也得到了缩减。李云红等人[8]提出了循环神经网络变体与卷积神经网络的混合模型(BGRU-CNN),在中文长文本分类任务中取得了较好的效果。还有学者将BiLSTM模型与CNN模型结合起来,Zhou等人[9]提出了BLSTM-2DPooling以及BLSTM-2DCNN模型,这两个模型既考虑了时间步(time-step)上的维度,也考虑了文本特征向量上的维度,因此可以捕获输入文本中更加丰富的语义特征。李启行等人[10]提出了基于注意力机制的双通道文本分类模型(DAC-RNN),利用CNN通道提取文本的局部特征,利用BiLSTM通道提取文本上下关联信息,各个通道内加入注意力机制分配权重。模型在公开数据集上测试效果良好。黄金杰等人[11]提出了一种基于CNN与BiLSTM的中文短文本分类模型,该模型能有重点地提取文本关键信息从而提高文本的准确率。徐绪堪等人[12]提出了多尺度BiLSTM-CNN情感分类模型,该模型可以对情感极性进行更为细致的分类。进一步,景楠等人[13]提出了结合CNN和LSTM神经网络的期货价格预测模型(CNN-LSTM)并在LSTM结构的末端引入注意力机制对模型进行优化,对比CNN、LSTM以及CNN-LSTM模型后发现,引入注意力机制的CNN-LSTM混合模型提高了预测的准确性。在混合模型BiLSTM-CNN中,输入的文本信息经过BiLSTM模型解码后进行卷积运算,该运算捕获词语间的语义信息并将此信息通过最大池化运算进一步降低特征维度,减少模型参数的同时提取出重要的特征,从而有效地降低了模型对数据的过拟合。但是,这样很容易损失文本的位置信息以及特征的重要信息。因此,本文考虑使用自注意力机制[14]来获取卷积运算后的特征信息权重,再将此信息进行最大池化降维运算,从而进一步提取了特征重要信息。
另一方面,除了提出自注意力机制外,Vaswani等人[14]还提出了Transformer模型,该模型由Encoder+Decoder构成,其中Encoder结构中,作者使用了数据归一化的思想,防止输入的数据进入激活函数的饱和区产生梯度消失或者梯度爆炸的问题。最后,将数据进行残差运算,让模型学习残差,从而更好地学习到新的特征。借鉴以上思想,本文将最大池化运算后的特征信息进行数据归一化处理以避免梯度消失以及梯度爆炸,接着通过添加残差层让模型更好地学习新的特征。最后,将本文构建的模型BiLSTM-CNN-self-attention-norm(BCSAN)应用到文本数据集上进行仿真实验,并在准确率和F1值上与其他深度学习模型进行对比,结果表明了本文提出的模型具有较好的分类效果。
2 基于自注意力机制和残差结构的BiLSTM-CNN模型的构建
模型主要由两个Block块构成,每个Block块均由BiLSTM、TextCNN、自注意力机制、残差层以及Layer-Normalization层构成,模型结构图如图1所示。
接下来,介绍模型中的每一层以及激活函数。
2.1 双向长短期记忆网络
RNN是按照时间序列展开的神经网络结构模型,LSTM模型是RNN模型的变体,主要用于解决RNN网络梯度消失以及梯度爆炸的问题。
LSTM模型的第一个计算是由遗忘门控制上一个时刻有多少信息可以参与到当前时刻,该步骤输入为h t-1和x t,输出为f t;下一步是由Sigmoid函数构成的输入门控制信息状态的更新,该步骤输入为h t-1和xt,经过激活函数后输出at、wt以及状态信息;最后一步由输出门控制状态信息的输出,以h t-1、xt和前一时刻的状态信息为输入,经过运算后得到输出。该模型t时刻的计算过程如下:
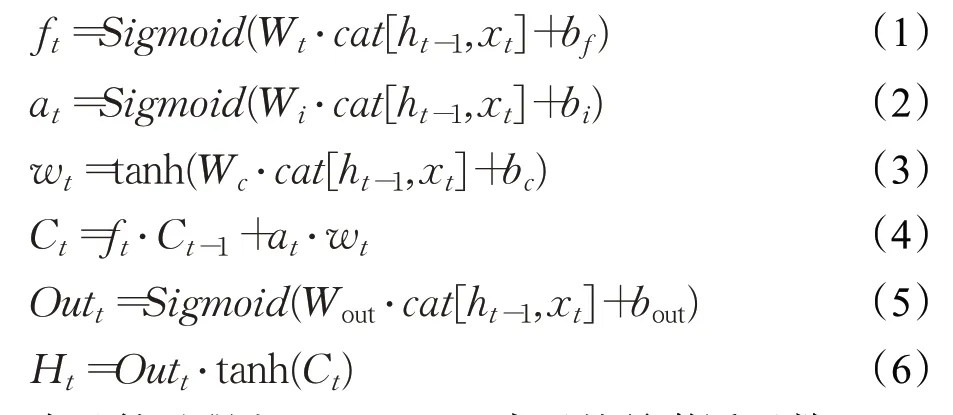
在计算过程中,Sigmoid()表示的是激活函数,Out t表示t时刻的输出,H t表示t时刻的隐藏状态输出,W*以及b*分别表示权重和偏置,cat运算表示向量之间的拼接。
LSTM模型可以更好地避免梯度消失以及梯度爆炸问题,计算效率更高,但是该模型并不能捕获句子的双向信息。对于更加细粒度的情感分析任务,如果加入句子的前向信息和后向信息则能更好地让模型对句子的情感色彩进行预测。对于多分类任务中,BiLSTM模型在处理文本时可以学习到更多的语义信息,这有利于对文本进行更好的分类。
BiLSTM模型是由前向的LSTM和反向的LSTM模型构成,每层的LSTM网络分别对应输出一个隐藏状态信息,模型的参数由反向传播进行更新。BiLSTM模型的结构如图2所示。
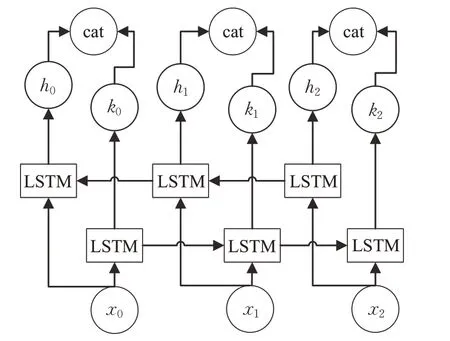
图2 BiLSTM模型Fig.2 BiLSTM model
其中,x0、x1以及x2分别表示0、1和2时刻的输入信息;h*和k*分别表示某时刻的不同隐藏状态输出;cat运算表示的是向量的拼接,即:

Ht-1表示的是t-1时刻的两层LSTM模型隐藏状态的输出拼接。
2.2 卷积神经网络
CNN主要应用在图像识别领域,当CNN应用到自然语言处理任务中时,通常记为TextCNN。CNN模型由输入层(input layer)、卷积层(convolution layer)、池化层(pooling layer)以及全连接层(fully connected layer)构成。在自然语言处理领域中,输入层由词语对应的词向量构成,然后经过卷积层运算提取词语的特征。CNN网络还可以灵活设置多个卷积核(filters)来提取更加深层次的语义特征,接着将提取的特征信息进行池化运算,用于对特征进行降维,提取更为主要的特征信息,最后进行全连接层运算得到结果。
设输入词向量为X,卷积运算的目的是利用多个卷积核来提取句子中的n-gram信息,进而更好地提取词语之间的相关性和语义信息,其运算过程为:

其中,⊗表示的是卷积运算,W和b表示的是权重和偏置,f(⋅)表示激活函数,例如Relu、Sigmoid以及Tanh函数。接着将提取的关键信息进行池化运算,进一步提取主要信息,其运算过程为:

最后将结果进行全连接运算。
2.3 自注意力机制
人们日常生活中都会产生数据,随着数据量的增大,对这些数据进行清洗、分析、建模就显得尤为重要。在建模过程中,加速模型的训练可以节省大量的时间成本。因此,有学者依据人类大脑的关注机制提出了自注意力机制[14],并成功地运用到了自然语言处理领域中。该模型的思想来源于注意力机制[15],自注意力机制较注意力机制而言可以更容易实现并行化计算。其基本结构如图3所示。
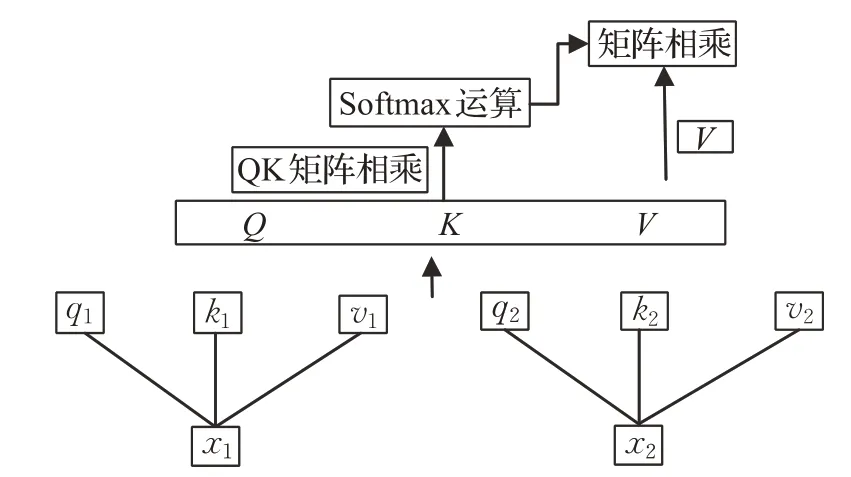
图3 自注意力机制模型Fig.3 Self-Attention model
首先,对于输入文本信息分别乘以相应的权重得到q1、k1以及v1,计算过程如下:

其中,W q、W k以及W v分别对应q、k以及v的权重矩阵;i∈[0,N],N是词库的大小。将得到的q1与k1进行点积运算,接着将结果归一化处理,最后分别乘以相应的权重v(i)得到输出内容,即:
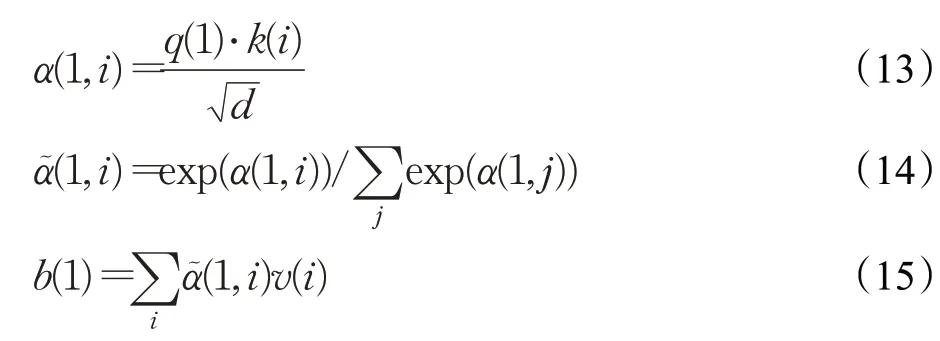
由b(i)的计算结果可以看出,每个b(i)的结果值与整个输入序列有关,这也是自注意力机制可以并行加速计算的一个原因。将上述的计算过程用矩阵的方式表示为:
其中,Q、K和V是由上述各个q i、k i和v i分别拼接而成的矩阵。因此,计算速度加快的另一个原因是自注意力机制的本质是矩阵计算。
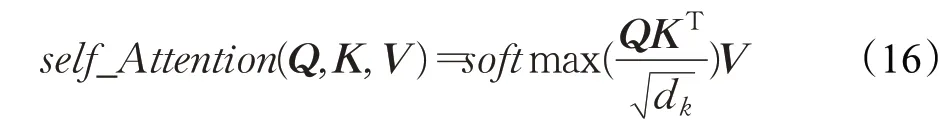
2.4 Layer Normalization结构与残差网络
随着深度学习的不断发展,网络的深度越来越大,虽然模型准确率得到了提升,但是一系列的问题随之产生,例如梯度爆炸和梯度消失。初始化权重参数显得格外重要,合理的权重值可以避免参数进入激活函数饱和区,从而减少梯度消失和梯度爆炸问题,然而随机初始化参数的方法效率低。鉴于上述不足,Bjorck等人[16]提出了Batch Normalization的方法,该方法主要通过将批数据进行归一化来使得进入激活函数的批数据在0附近波动,这种归一化的方法没有将全部数据进行归一化,仅仅将每个神经元的批数据进行归一化,保证了数据的多样性,让模型每一层都能学到不同的特征信息。Batch Normalization方法主要用于机器视觉任务中,RNN模型中主要使用由Ba等人[17]提出的Layer Normalization,即在每一层中对单个样本所对应的所有神经元进行归一化处理。具体的做法是先对每一层的单个样本对应的所有神经元求解其均值和方差。即:
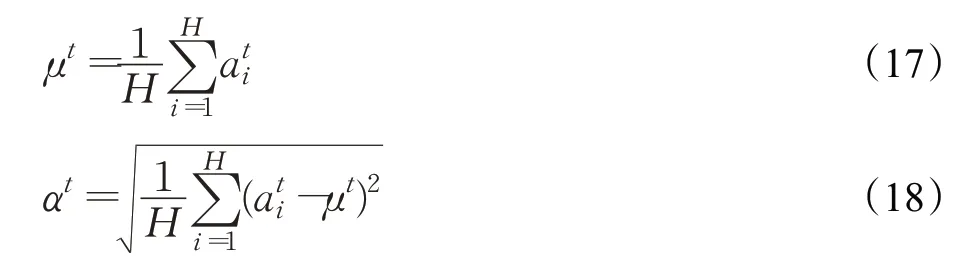
其中,ati表示的是t时刻神经网络模型的输出,H表示的是神经网络模型层的维度,然后为了保持数据的多样性,更好地保持归一化后的模型非线性能力,将归一化后的数据进行非线性激活函数运算,即:
其中,g和b分别表示基尼参数(gain parameters)和偏置(bias),⊙表示向量之间的元素乘积。

随着深度学习模型网络深度的增大,模型非线性拟合能力会越来越强,准确率会越来越好。当深度达到一定程度时,模型的准确率又开始下降,拟合能力变差,这种现象并非欠拟合引起,这种现象称为网络退化问题(degradation problem)。因此,He等人[18]提出了深度残差模型(residual network,ResNet),该模型不仅解决了深层的网络带来的梯度消失问题,还解决了网络退化问题,同时模型的准确率得到了提升。其基本的残差结构如图4所示。
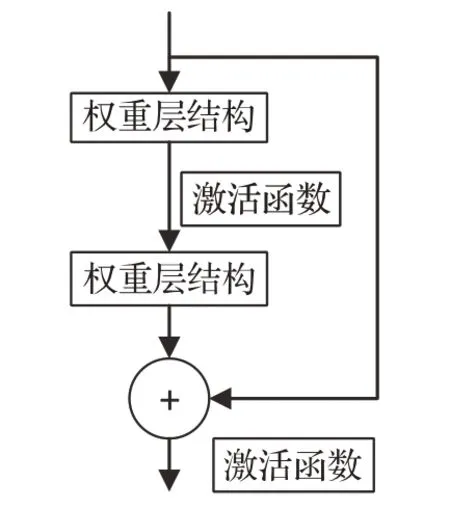
图4 残差网络模型Fig.4 Residual network model
x为信息输入,H(x)为特征的信息输出,F(x)为残差,其表达式为:

信息输入x可以直接与后边接入层相互连接,这样使得后边接入的层可以学习到残差,因此这种连接也称为捷径连接(shortcut connection)。残差结构通过恒等映射来增大模型的深度,其基本的运算为:

x L是第L层深度单元特征的信息表示,当残差值为0时,残差网络相当于进行恒等映射,这样保证模型的训练精度不会下降。事实上,由于数据的复杂性与多样性,残差值不会为0,这样就相当于模型在不断地堆叠层,进而更好地学习新的特征。
2.5 模型激活函数
对输入的文本数据向量化处理得到词向量[x1,x2,…,x n],接着进行BiLSTM运算得到最终的输出单元向量[h1,h2,…,h n],接着将此特征信息进行维度扩充,继续进行TextCNN模型运算提取到更多的特征信息。在建模运算的过程中将特征信息进行激活函数非线性化处理。本文采用的激活函数是Mish函数,该函数由Diganta[19]提出,传统的深度学习任务中,激活函数的选择大多是Relu函数,这两个激活函数的公式分别为:

对应的函数图像如图5所示。对比Relu函数,Mish函数的优点是:Relu函数存在零边界,Mish函数没有边界的限制,从而不会出现梯度饱和现象,该函数允许较小的负梯度值流入,可以更好地保证特征信息的流动;从图像可以看出,Mish函数的梯度较Relu更加得光滑,这样就会导致更多有用的信息流入神经网络中参与计算,得到更好的准确率和泛化能力。现有实验表明了使用Mish激活函数在大多数深度学习任务中得到的准确率优于Relu、Sigmoid以及Tanh函数。
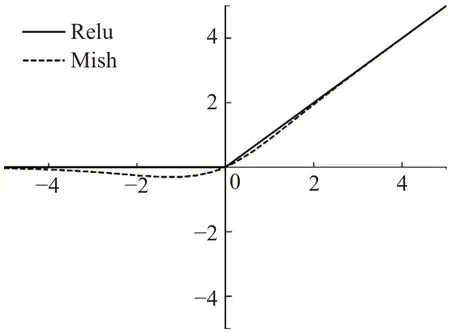
图5 激活函数图像Fig.5 Activation function
3 实验分析
3.1 实验环境及数据概述
深度学习实验往往需要GPU的计算加速,为了保证实验可以顺利进行,本文的实验环境如表1所示。
表1 实验环境配置信息Table 1 Experimental environment configuration information
本文选取的数据集是清华大学THUCTC网站开源的一部分新闻文本数据20万条,同时加入互联网上搜集到的最新的新闻文本数据集10万条一起训练,总计30万条文本数据,随机选择26万条训练集,2万条测试集与2万条验证集进行实验,共计10个新闻类别。具体的新闻名称及类别如表2所示。
表2 新闻类别及其名称Table 2 News category and its name
3.2 数据预处理
对于文本建模,常见的方法是先将文本进行分词操作,接着去除和模型训练无关的停用词,将分词结果进行向量化表示,常用的向量化方法是基于神经网络的Word2vec,本文使用的是搜狗新闻语料库中通过Word2vec模型的前馈神经网络(Skip-Gram)方法训练得到的词向量,通过大量的新闻文本数据进行训练以实现词语的语义信息与词语特征的分布式表示,最后得到词向量的维度为25~300维。
神经网络训练往往需要大量的数据,对这些大量数据的收集是一件繁琐的工作。因此,为了获得较好的神经网络模型,就需要使用数据增强技术,该方法最早来源于机器视觉任务中,常见的数据增强方法有图像的反转、平移以及旋转等方法来对训练数据进行扩充。在自然语言处理任务中,常见的数据增强方法有随机删除、打乱顺序以及同义词的替换等等。因此,本文对分词后的结果进行数据增强,不仅可以提高数据的量,还可以在训练过程中抑制模型的过拟合,提高模型的泛化能力,使得训练出来的模型具有鲁棒性。
3.3 评价指标
分类问题最常见的评价指标是精确率(Precision)、准确率(Accuracy)、F1(F-Measure)以及召回率(Recall)。其中,准确率描述的是所有分类样本中,分类正确的样本所占比重,精确率描述的是所有预测为正实例的样本中,是正实例所占的比重,召回率描述的是所有正实例的样本中,被分为正实例的样本所占比重,F1值是精确率与召回率的加权平均,综合度量了精确率与召回率的结果。精确率和召回率由混淆矩阵(confusion matrix)计算得出。混淆矩阵如表3所示。

表3 混淆矩阵Table 3 Confusion matrix
精确率(precision)和召回率(recall)由下式给出:

3.4 模型参数的设定
参数的设定决定了深度学习模型训练结果的好坏。因此,本实验所设定的参数如表4所示。

表4 模型参数设置Table 4 Model parameters
神经网络在进行梯度反向传播更新参数的过程中,本文使用的优化器是Adam,该优化算法是随机梯度下降算法的优化版本,计算效率更高,收敛速度较快。因此,为了更好地发挥该优化算法的效率,本文对学习率进行调整,绘制了不同学习率下,模型在测试集上准确率和F1值的曲线图,如图6所示。
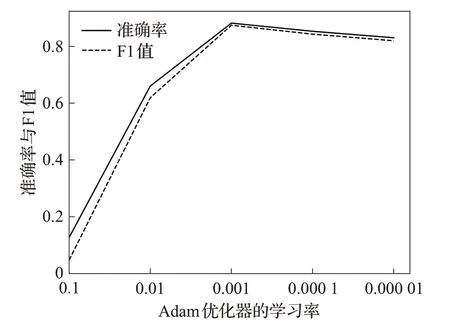
图6 不同学习率下在测试集中的准确率与F1值曲线图Fig.6 Accuracy and F1 in test set with different learning rates
由图6可以看出,当Adam优化器对应的学习率为0.1时,模型在测试集上的准确率最小,当学习率为0.001时,模型在测试集上的表现最好。因此,本文实验中,Adam优化器的学习率设定为0.001。
模型的训练过程中,本实验加入了Dropout[20]方法。Dropout的取值也是一个重要的参数,恰当的取值可以让模型更好地收敛,同时能够在保证精度的前提下抑制模型过拟合。因此,本文设定Dropout的取值分别为[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]并进行模型的训练、测试以及验证,通过模型在测试集上的表现来选择最佳的Dropout值。最终绘制了测试集上准确率变化曲线如图7所示。曲线图中可以看到,当Dropout的取值为0.4时,模型在测试集上的表现最佳,当Dropout的取值开始逐渐增大时,模型在测试集上的表现开始逐渐下滑,因此,本文选择Dropout取值为0.4进行实验。

图7 不同Dropout值下在测试集中的准确率与F1值曲线图Fig.7 Accuracy and F1 in test set with different Dropouts
词向量维度也是一种重要的参数,维度越大意味着模型能学习到越多的特征信息,同时模型产生过拟合的风险也越大。而词向量维度越低,模型越容易产生欠拟合的风险。因此,选择合适的词向量维度在模型训练过程中起到了关键的作用。本文在25~300维词向量下使用Relu激活函数分别进行实验来探索最佳的词向量维度,将最终的结果绘制成曲线图,如图8所示。
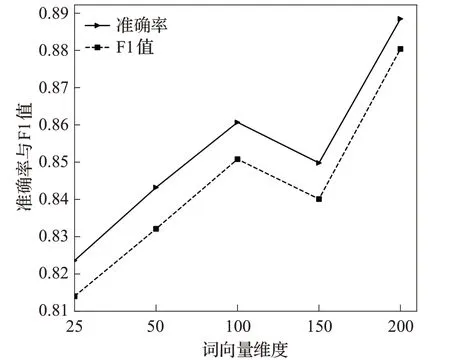
图8 不同词向量维度下各模型准确率图Fig.8 Accuracy of each model for different word vector dimensions
由该曲线图可以看出,随着词向量维度的增加,准确率和F1值基本线性增加,其中,本文模型在300维的时候,模型可以学习到更多的语义信息,准确率和F1值达到最大。因此,本文选择300维进行实验。
3.5 实验结果
为了验证模型的有效性,本文选择多个单一模型与多个在相同数据集上效果较好的先进模型进行对比,其对比的模型包括BiLSTM、TextCNN、BiLSTM-Attention、BiLSTM-CNN、BGRU-CNN、DAC-RNN、C-LSTM[21]以及模型。共做了两组实验,其中一组激活函数为Relu,另外一组激活函数为Mish。其对比结果如表5和表6所示。
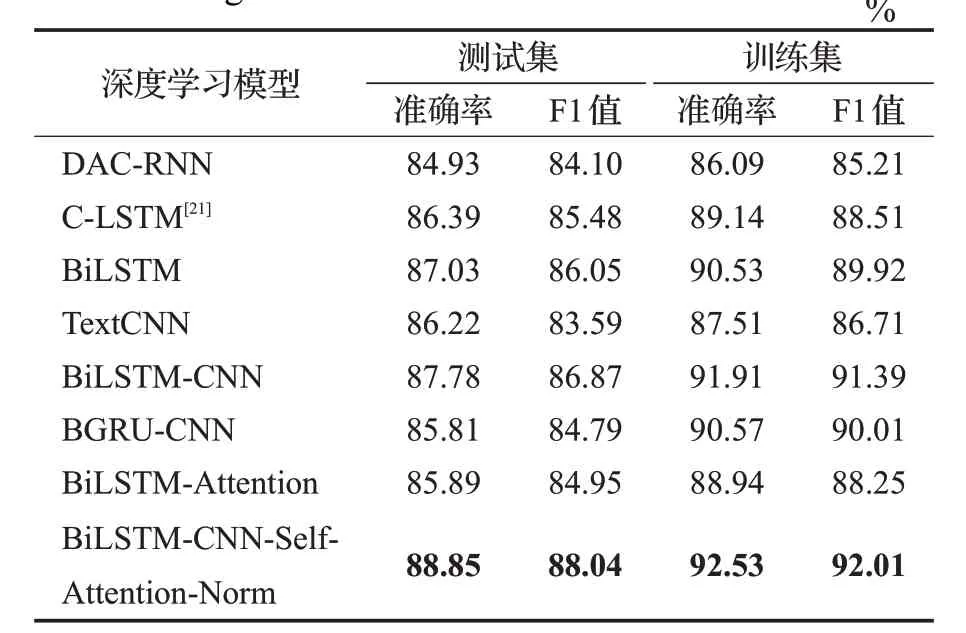
表6 加入Mish激活函数的深度学习模型实验结果对比Table 6 Comparison of experimental results of deep learning model with Mish activation function
由表中的数据结果可以看出,本文提出的方法较其他深度学习模型实验结果均有所提高。在表5中,本文模型较BiLSTM、TextCNN、Bi LSTM-CNN、C-LSTM、Bi LSTM-Attention、DAC-RNN和BGRU-CNN模型准确率分别提高了2.8%、3.2%、2.1%、3.1%、2.2%、4.8%和2.3%、F1值分别提高了3.2%、3.7%、2.1%、2.3%、2.4%、5.1%和2.4%。对比以往模型BiLSTM、TextCNN、C-LSTM和BiLSTM-Attention,BiLSTM-CNN模型无论准确率还是F1值均有所提高,BiLSTM-CNN模型可以捕获到更多的文本语义信息,其得到的精度高于其他模型。DAC-RNN和BGRU-CNN模型在清华大学THUCTC网站数据集上与其他模型对比取得了较高的准确率,但是在表5中,可以看出本文模型在测试集上准确率为87.57%,比这两个最新的模型准确率高。由于BiLSTM模型可以学习到句子的前向与反向信息,本文实验使用的文本句子平均长度为32,因此,BiLSTM可以很好地学习到这些短文本信息并避免长期依赖问题,其训练的结果较TextCNN模型好。通过对比C-LSTM、BiLSTM与BiLSTM-Attention模型的准确率可知,加入自注意力机制使得模型的准确率得到了提升。因此,对比上述模型结果,本文通过使用残差网络与自注意力机制的方法,能充分发挥BiLSTM与CNN对文本特征信息的提取能力,模型结果均高于其他深度学习模型,证明了本文方法的有效性。

表5 加入Relu激活函数的深度学习模型实验结果对比Table 5 Comparison of experimental results of deep learning model with Relu activation function
表6为各个深度学习模型将Relu激活函数替换为Mish后的结果,为了更好地对比加入Mish和Relu激活函数的结果,绘制了模型在测试集上的对比曲线图如图9所示。

图9 Relu与Mish激活函数在各模型下的准确率Fig.9 Accuracy of Relu and Mish activation functions under each model
由该曲线图看出,加入Mish激活函数后的结果均得到了提高。其中,本文模型较这些模型准确率分别提高了4.6%、2.8%、2.1%、3.1%、1.2%、3.5%以及3.4%。进一步证明了加入Mish激活函数后本文模型的可行性。
继续对比本文模型BiLSTM-CNN-Self-Attention-Norm(BCSAN)在各个词向量维度下准确率的关系如图10所示。
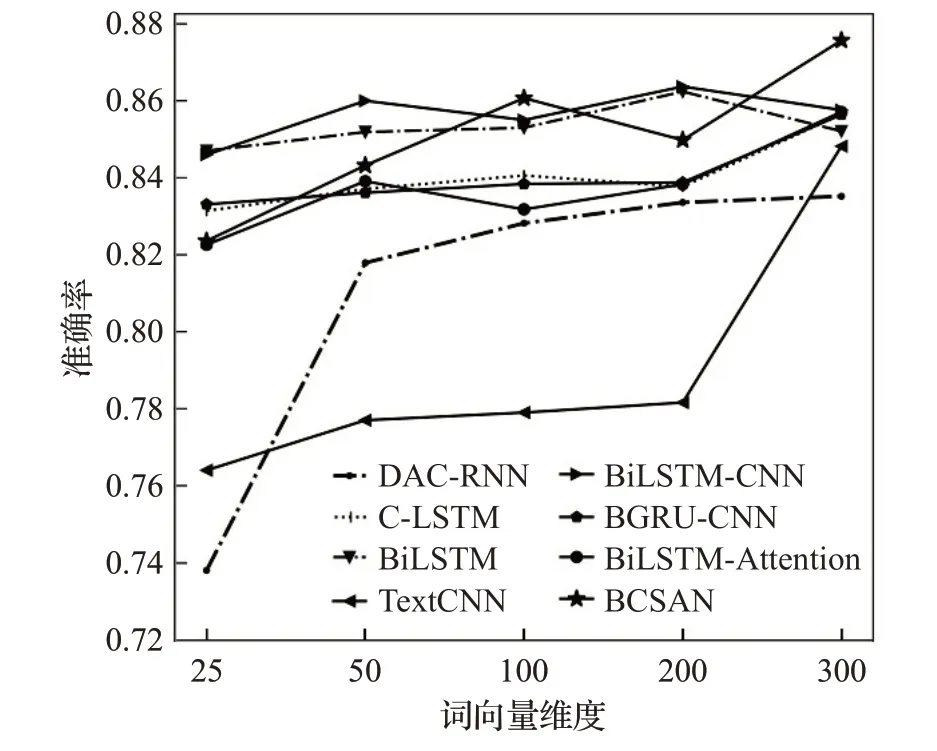
图10 不同词向量维度下模型的准确率Fig.10 Accuracy of models under different word vector dimensions
随着词向量维度的增加,各个模型的精度成线性增加,其中,本文模型的准确率在300维度时达到最大,均高于其他主流深度学习模型。
4 结语
本文提出了一种基于深度学习方法的文本分类模型。将文本信息分词之后进行文本数据增强,然后将文本信息输入到BiLSTM模型中得到特征信息,接着输入到TextCNN模型中,将卷积运算提取的信息使用自注意力机制自动地学习相应的权重信息,有效地把握句子中各个词语的信息。随后进行池化运算,进一步降低特征信息的维度,提取对分类结果有较大影响的特征信息。为了加速模型的训练和保证文本信息的多样性,对池化运算后的特征信息进行Layer Normalization处理,并让模型学习残差,保证模型没有过拟合的前提下进一步提高模型的训练精度。本文的方法为自然语言处理文本分类任务的研究提供了一定的帮助,在自然语言处理的发展中具有一定的参考价值。
本文提出的模型没有分析模型复杂度与如何降低模型复杂度问题,这是进一步研究的方向。另外,在进一步的研究中,将会重点关注以数据,模型以及任务为驱动点来更好地选择模型的参数、提高模型学习的效率,节省时间成本。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
电子制作(2018年1期)2018-04-04
北京航空航天大学学报(2017年12期)2017-04-23
