
基于GCN的虚假评论检测方法
2022-02-24 12:34曹东伟李邵梅陈鸿昶
计算机工程与应用 2022年3期
曹东伟,李邵梅,陈鸿昶
1.郑州大学 中原网络安全研究院,郑州 450000
2.中国人民解放军战略支援部队信息工程大学,郑州 450000
互联网与电子商务的迅速崛起改变了众多消费者的消费模式,线上消费所占比例日益增加。线上消费的在线评论成为影响商家与消费者进行决策的重要因素。真实的用户评论能够引导消费者做出正确的消费决策,然而由于商业利益、个人偏见等原因发布的不符合产品真实特性的虚假评论则会干扰用户的消费决策,对商家信誉造成不良影响。因此,寻找有效的检测方法,准确检测出点评网站的虚假评论对提升用户体验、维护良好的市场秩序具有重要意义。
自Jindal等[1]首次提出垃圾评论识别之后,虚假评论作为垃圾评论检测任务中最困难的一类,一直是学者研究的热点。目前,该研究方向主要还沿用Jindal的检测原理,认为检测虚假评论可以转化为检测复制的评论,例如,同一评论多次用于评论不同的商品或同一商品存在多条类似评论,将具有此类特点的评论归为虚假评论。
虚假评论检测的本质是文本分类问题,为此,随着自然语言处理技术的发展,很多新的文本分类方法,如基于图卷积网络[2-3]的文本分类方法也被引入进行虚假评论检测[4]。
Li等[5]利用GCN对闲鱼网站中的虚假评论进行检测,通过商品、用户、评论异质网络图及评论与评论同质图[6-7]相结合,提出闲鱼虚假评论检测模型GAS(GCNbased anti-spam),基于闲鱼网站评论数据与GBDT(gradient boost regression tree)、CNN等模型相比较,检测效果均优于其他模型。Wang等[8]研究发现,虚假用户的行为越来越复杂,并且跨平台评论的特点使得检测更加困难。因此,作者提出基于GCN的半监督检测模型,首先在大量节点中找出可疑度较高的节点作为种子节点,利用GCN网络中节点之间信息相互传播,找出与种子节点相似度高的节点,实现虚假评论检测。Manaskasemsak等[9]针对现有检测方法往往需要耗费大量成本来标记训练数据这一现象,提出了基于用户图的检测方法,与文献[8]类似,首先提取一组特征,然后通过连接共同拥有这些特征的用户构建用户图,通过子图逐次迭代扩散发现更多与其相似度大的节点,在Yelp数据集上证明其具有效性。这些方法有的需要用到评论外的商品信息或者用户行为信息,有的需要指定种子节点,而开源的虚假评论数据集通常难以满足上述需求。
为此,本文借鉴文献[10]中首次提出的基于图卷积神经网络文本分类模型Text-GCN(text-graph convolution networks),对基于评论内容的虚假评论检测展开研究。文献[10]的作者在构建图过程中,连边信息只考虑了词汇间的共现关系,很明显该方法对词汇重合度较高的评论文本有更好的检测效果,但是实际应用中,水军可以通过变换词汇或模板的方法规避检测,所以该方法具有一定的局限性[11]。为了弥补该不足,本文提出一种融合语义信息的虚假评论检测方法Sem-GCN(sematic-graph convolution networks),在构建词汇-词汇之间的连边时,不仅考虑基于窗口的共现关系而且也考虑词汇之间的语义相似性关系。通过构建融合共现关系和词汇相似度的词汇-评论异质网络图将虚假评论检测问题转化为节点分类问题,利用GCN可以很好地捕捉节点与节点之间高阶特征信息的特点[12],从而提高虚假评论检测的效果。在同一数据集上与K均值聚类方法、CNN、LSTM及Text-GCN进行实验对比,验证了本文方法的有效性。
1 Text-GCN
1.1 GCN
图神经网络是一种多层神经网络,利用谱聚类的思想,将传统的离散卷积应用在图结构数据上,在对特征学习时综合考虑了来自邻居实体的所有信息[13]。图结构可以用G=(V,ε)表示,其中节点v∈V,边e∈ε。节点初始特征X=H0∈Rd0,其中d0代表节点的特征维度。模型中节点v第l层的隐藏向量可表示为H l∈Rd l,其中dl代表第l层的向量的维度。
GCN学习方式遵循逐层学习,所有节点同步更新[14]。每层学习过程可分解为两个步骤:聚合与合并,其过程可以表示为式(1):

A表示节点的邻接矩阵,D为邻接矩阵的度矩阵,形式如式(2)所示,W l为第l层训练得到的矩阵。
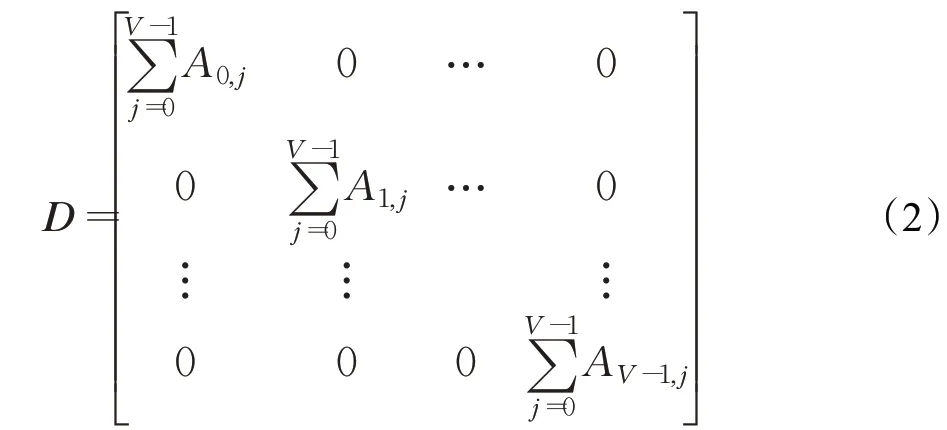
1.2 Text-GCN
Yao等[10]首次使用标准图卷积网络进行文本分类,以文档和文档中的词作为节点,构建异构文本图,将每个词及文本表示为One-hot向量作为图卷积网络的输入。其中包含词与词,词与文档两类连边,两类连边的构建方式如下:
(1)词与文档间连边构建方法
根据词在某个文档中出现与否建立词-文档之间的边。文献[10]中针对的是普通的文本分类任务,在本文的应用中文档为评论文本。评论与词之间连边的权重可以由TF-IDF特征值所表示,TF(term frequence)是词在文档中出现的次数,IDF(inverse document frequence)是指对评论总数除以包含该词的评论数所得的商取对数。

(2)词与词间连边构建方法
文献[10]通过统计在给定长度为γ的时间窗口内,词共现数作为词与词之间的权重。利用点互信息(PMI)来描述这种信息。例如节点wi与节点w j之间边的权重计算可以由式(4)~(6)表示:

p(wi,w j)表示在时间窗口λ内词wi与w j共现的概率,由式(5)所得,W(wi,w j)是评论集合在给定时间窗口内词对(wi,w j)共现的数目,W是评论集合在给定时间窗口内所有词的总数目。p(wi)是在时间窗口下wi出现的概率,W(wi)是整个评论集在时间窗口下wi出现的数目。
文本图构建完成后,送入GCN网络进行训练学习,学习过程如式(7)所示:
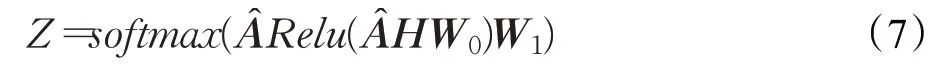
2 Sem-GCN模型
本文借鉴文献[10]描述的Text-GCN网络进行虚假评论检测,其中本文中的虚假评论对应上一章中的每个文档。作者在构建图过程中,连边信息只考虑词汇间的共现关系,但是评论文本具有的不规范性与词汇多样性导致检测效果降低,所以该方法具有一定的局限性。此外,虚假评论具有很强的迷惑性,仅利用每条文本所含信息进行检测,效果并不良好,而挖掘出每条评论在整个评论集中的全局信息更有助于提升检测效果[15]。因此,为了提高对虚假评论的检测效果,本文对Text-GCN进行改进,提出了基于Sem-GCN的检测方法。与CNN、LSTM学习模型相比,Sem-GCN通过多种方法建立连边使模型具有更好的捕获全局信息的能力,构建词与词之间的连边时,不仅利用词间共现信息,还引入基于词嵌入的相似性信息[16]。通过文本图中连边间信息迭代更新,每个节点不仅携带自身信息,还携带邻域节点信息。如图1所示。Sem-GCN在构建词-词的连边时融入了词之间的语义信息,语义信息又通过文本异质图中词与评论间的连接传递到评论与评论之间,有助于更好地得到每条评论在整个评论集合中的全局性特征信息。
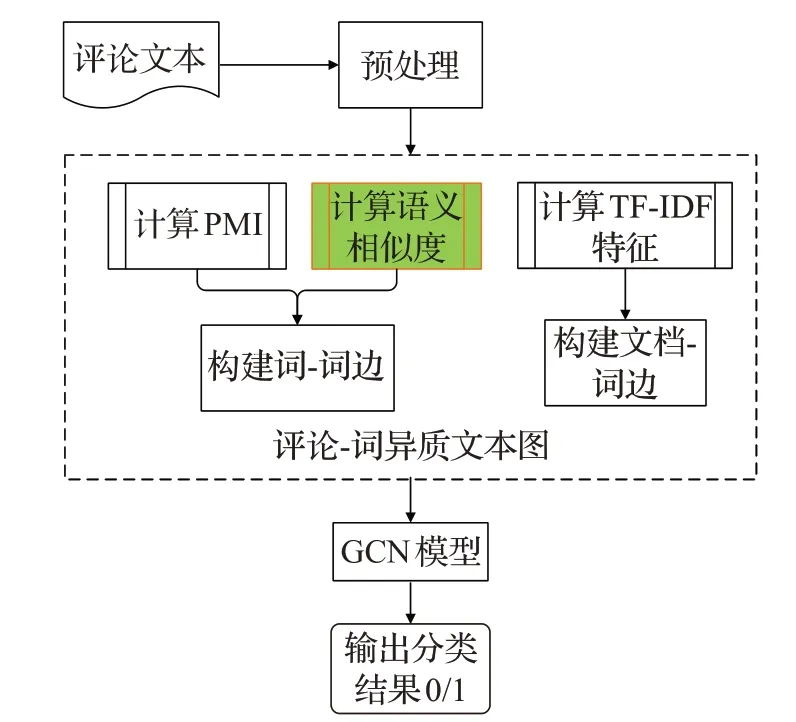
图1 Sem-GCN框架图Fig.1 Sem-GCN frames
其中,图1中基于语义相似度的边权重计算方法如下。
(1)利用BERT预训练词向量分别得到两个词wi与w j的词向量表示。
(2)对wi与w j两个词的向量表示计算余弦相似度,当相似度超出既定阈值时,则认为两个词之间存在语义关系,即建立连边。本文选取阈值为0.8,边的权重计算如式(8)所示:

其中,Ssem(wi,w j)表示单词wi与w j之间边的权重,Usem(wi,w j)表示在整个数据集的所有评论中wi与w j两个单词存在语义关系的数目。Utotal(wi,w j)是在整个评论集合中wi与w j在同一条评论中出现的次数。
本文提出的Sem-GCN进行虚假评论检测的流程如下。
首先对所有评论中的词进行统计并删去重复词构成一个词汇表;基于词汇表中的词,每个词视为一个节点,同时将每条评论也视为一个节点;然后,文本图中建立连边时遵循以下规则:若某条评论涵盖词汇表中的词,则该条评论与词建立连边;设定固定大小的窗口,若在该窗口内,同时出现在窗口内的词则分别建立连边;计算每条评论中词之间的语义相似度,若大于阈值则建立连边。最后,评论信息转化为图中的节点,评论文本图如图2所示,其中R表示评论,W表示词,可以看出词与评论之间存在一种连边,而词与词之间除基于窗口共现关系外,还存在基于语义相似度所建的连边。图2可以表示为式(9):
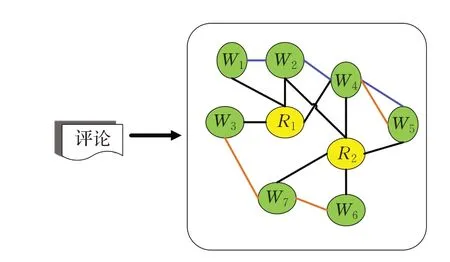
图2 评论异质文本图Fig.2 Review heterogeneous text map

其中,N={n1,n2,…,n n},代表评论与词共有n个节点。边集合由E={e1,e2,…,e s},节点ni与n j之间的连边可以表示为eij=E(n i,n j)。边的权重分为两种,一种是词汇与评论之间的权重αrw,另一种是词汇与词汇之间的权重αww。αrw由1.2节中公式(3)计算。
最终词与词之间连边的权重值由1.2节中式(4)计算的PMI与式(8)计算的Ssem共同决定,如式(10)所示。当基于窗口与语义相似度两种方法都存在连边时,则权重αww为两个权重值相加。仅基于时间窗口存在连边时权重αww=PMI(wi,w j)。仅基于语义相似度存在连边时αww=Ssem(wi,w j)。

3 实验
3.1 数据集
实验数据为Ott等人利用众包平台获取的标准数据集,这也是唯一公开可用的虚假评论数据集。Ott等人雇佣人员为20个旅馆进行评论,共收集400条虚假评论。此后,Ott等及Li等基于此数据又进行扩充,内容涵盖酒店、餐饮等领域。数据总量为1 600条评论数据,其中真实评论与虚假评论各800条。实验中按7∶2∶1比例将这些数据分为训练集、测试集、验证集三类。
3.2 评价指标
本文实验结果评价指标采用精确率(P),召回率(R)与F1值。
精确率表示测试数据中被正确预测的评论数占所有评论的比例。计算方法如公式(11)所示。式中,TP表示被正确预测的评论数,FP表示被错误预测为真实的评论数。

召回率表示测试评论中被正确预测的评论数占所有真实评论数的比例,由公式(12)可以得出。其中,FN为被错误预测为虚假+评论的数量。

F1值用来综合评价算法,由召回率与精确率计算,如公式(13)所示:

3.3 实验结果分析
3.3.1 实验1
本文实验环境为系统版本Ubuntu16.04,硬件环境为TITAN XP处理器,模型包括两层GCN网络,每一层GCN隐藏层大小设置为200,窗口大小设置为15,学习率为0.01,训练50轮次,训练结果如图3所示。
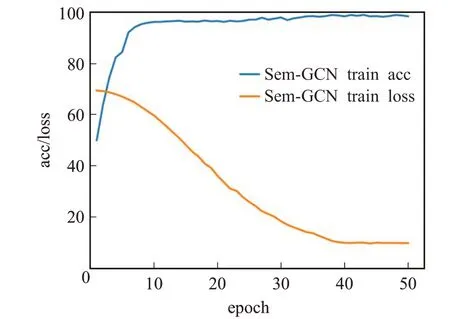
图3 训练结果Fig.3 Training result
在epoch=10以前,模型训练还未达到最优。分析原因是对于Sem-GCN网络,节点信息需要进行图内传播,当达到10轮左右,图的全局信息在训练过程中充分传播,检测效果明显提升。模型训练时长为24 s,其中构建评论文本图耗费20 s,文本图训练耗费4 s。训练时间如图4所示。
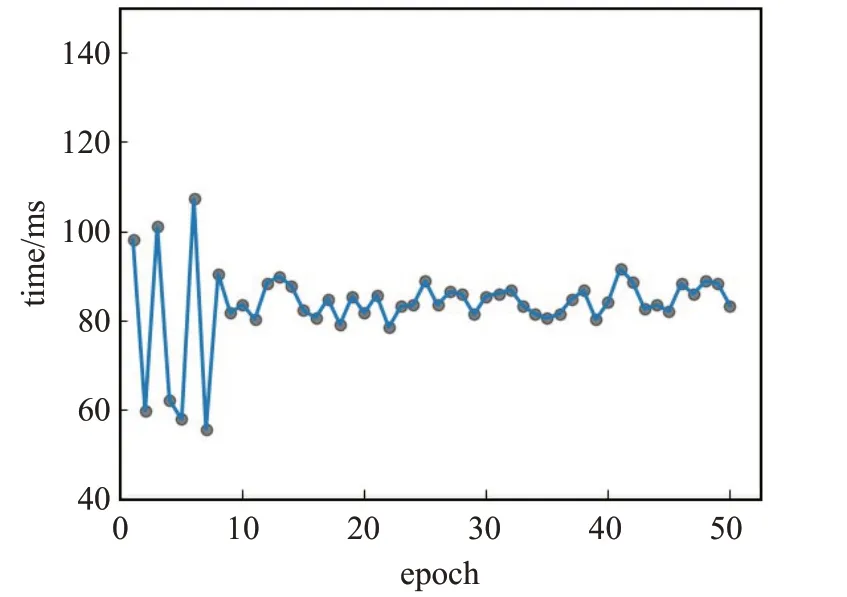
图4 训练时间/轮次Fig.4 Training time/epoch
因为训练开始,邻域信息需要在评论图中聚合传播,所以训练时间波动较大,同样可以看出在经过10轮左右,每一轮次的训练时间趋于稳定,证明在训练10轮左右文本图中全局信息充分传播。评论检测结果如图5所示,标签0代表真实评论,标签为1代表虚假评论。

图5 分类结果Fig.5 Classification result
3.3.2 实验2
为了更好验证该方法的有效性,在标准数据集上,本文与基线模型K均值聚类,CNN、LSTM模型以及文献[10]中的Text-GCN方法进行对比实验,结果如表1所示。其中,K均值聚类方法为任亚峰[17]在Ott等人合成的标准数据集上进行检测的方法。实验表明,与CNN、LSTM等深度学习模型相比,本文方法的准确率均得到不同程度的提升,并且处理效率也优于LSTM。本文认为主要原因是Sem-GCN将评论文本转化为以词汇为节点构图,不仅利用节点的文本信息,还将评论与评论之间通过词汇关联起来,更好地利用节点之间的邻域信息,弥补评论不规范的特性,缓解数据的稀疏性。值得强调的是,本文提出的Sem-GCN的检测效果优于Text-GCN,证明本文提出的模型在构建文本图过程中引入语义信息的有效性,融入语义信息后,在评论中某些表达含义相近的词在基于语义相似度的方法下同样也会建立连边,有效缓解连边信息只考虑词汇间的共现关系,因评论文本不规范,词汇多样性导致检测效果降低的状况。

表1 实验结果对比Table 1 Comparison of experimental results
此外,实验发现本文提出的Sem-GCN在训练样本数较少时也可具有很好的效果,为了研究Sem-GCN在小样本情况下的检测性能,相同的实验环境下,采用训练数据集的40%进行模型训练,观测其检测效果,结果如图6所示。在训练样本数降到40%,训练评论数只有448条的条件下,准确率也可达到87%;相同条件下,CNN和LSTM的准确率分别只有79%与82%。实验结果表明GCN可以很好地将特征信息传播到整个图上,具有捕获全局信息的能力,在小样本条件下相对于其他模型的检测效果优势更明显。
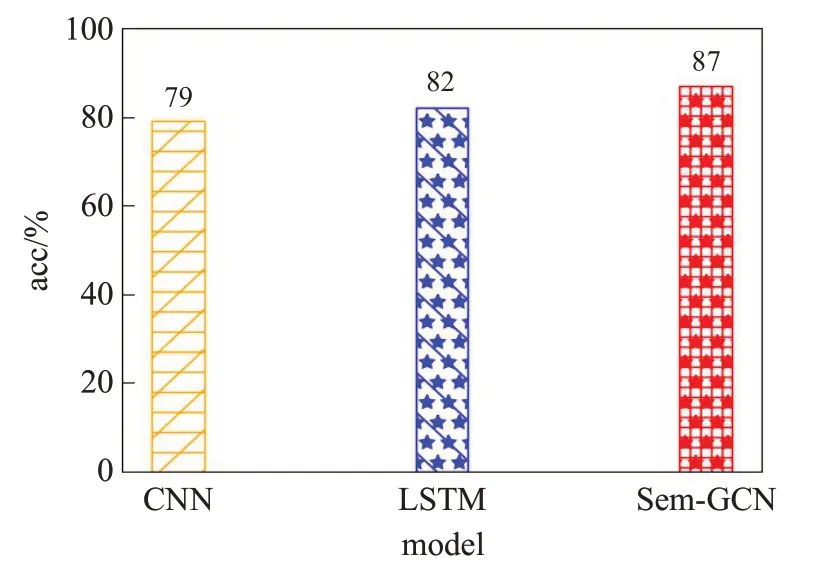
图6 40%训练数据效果Fig.6 40%training data effect
4 结语
本文基于GCN网络对虚假评论检测进行研究,提出利用文本图来捕获上下文语义信息,基于共现关系的上下文信息及评论与评论之间的关系信息,并对图中的连边赋予不同的权重。在Ott等人利用众包平台获取的标准数据集上与LSTM、CNN等模型进行比较,检测准确率均有不同程度的提升,证明了在顺序上下文信息的基础上融入语义信息,检测效果有一定程度的提升。同时,证明了在小样本情况下,本文提出的Sem-GCN模型同样可以达到较好效果。未来的工作中,还可以融合用户行为特征,构建多类型异质网络,丰富节点信息,提高检测效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
机械工业标准化与质量(2022年6期)2022-08-12
中华胰腺病杂志(2021年1期)2021-02-26
装备制造技术(2020年2期)2020-12-14
山东医药(2020年34期)2020-12-09
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
开放教育研究(2020年2期)2020-03-31
中华胰腺病杂志(2019年4期)2019-08-29
中国修辞(2017年0期)2017-01-31
长江学术(2016年4期)2016-03-11
