
基于自注意力机制的文本生成单目标图像方法
2022-02-24 12:37鞠思博李岩芳
计算机工程与应用 2022年3期
鞠思博,徐 晶,李岩芳
长春理工大学 计算机科学技术学院,长春 130022
基于文本描述的图像合成(text to image,t2i)涵盖了计算机视觉和自然语言处理等技术,是一个跨学科跨模态的综合性任务[1]。基于输入的自然语言描述,模型应合成与描述内容相符、语义信息完整的图像。该任务不仅需要计算机理解文本的语义信息,还要将语义信息转化为像素,生成一幅高分辨率与高真实性图像,这是一项极具挑战性的任务。它有着广泛的应用潜力,未来可在计算机辅助设计,刑侦画像生成等方面发挥重要作用。
深度学习的迅猛发展,带来了计算机视觉以及自然语言处理在理论和技术上的巨大进步,推动基于文本描述图像合成的任务朝着高分辨率、高真实性、高可控性迈进。Reed等人[2]使用生成对抗网络(GANs)[3],通过使用字符级别的循环神经网络提取文本描述的句子特征,连同噪音作为cGAN网络[4]的输入。为了降低基于GANs的高分辨率图像合成的难度,Zhang等人提出包含两个生成对抗网络的StackGAN[5]:第一阶段生成低分辨率图像,第二阶段基于低分辨率图像进行细化,逐步合成高分辨率图像。为提高合成图像的质量,Zhang等人提出StackGAN++[6],除使用多个GANs生成多尺度图像外,他们在损失中加入颜色一致性的正则化设置,能够使得在训练时保持不同尺度图像的一致性,降低GANs训练的不稳定性。Xu等人在AttnGAN[7]引入了全局注意力机制[8],并提出了深层注意多模态相似模型,利用单词级别和语句级别的文本特征作为输入,提高了文本与图像的匹配度。
但GAN-INT-CLS[2]、StackGAN[5]与StackGAN++[6]方法仅使用句子级别特征作为文本特征,丢失了重要的合成图像细节,这里借鉴AttnGAN[7],同时提取句子级别与单词级别特征作为文本嵌入,提高了语义对齐性。此外AttnGAN网络虽然对文本图像一起使用了全局注意力机制,增加了生成图像的细节信息,但是经常会生成不符合自然规律的小鸟,例如“两个脑袋”“两只眼睛”等错误图像。针对AttnGAN生成不符合语义的鸟类图像,提出一种基于GAN的t2i网络模型,在模型的初始阶段使用自注意力机制,使合成低分辨率图像时更好地学会图像中重要的空间与位置信息,提高初始阶段图像生成的准确性,从而改善高分辨率图像合成的正确性。
本文贡献在于以下两点:
(1)基于AttnGAN模型,本文提出在初始阶段增加自注意力模块,改善原模型生成不符合常态的鸟类图片,并优化了在CUB[9]数据集的IS与FID指标得分,数据分析与实际生成效果表明,本文所提出的SA-AttnGAN网络模型能够生成逼真自然的鸟类图片。
(2)还制作了文本生成图像服装数据集,为其他研究者扩展了t2i技术的应用领域,奠定了数据基础。
1 相关工作
早期文本描述的图像合成主要结合检索与监督学习[1]。首先,通过关键字(或关键短语)与图像之间的相关性来确定信息与“可图像化”的文本单元;然后,基于当前文本条件,文本单元检索最有可能与图像内容相关的区域,并最终优化为图像布局,从而将文本描述与图像内容进行关联。然而,由于训练方式有限,此方法只能改变特定图像的特征,无法依据文本描述合成具有全新内容的图像。随着研究的深入,Yan等人提出能够将每个图像建模为前景和背景的组合Attribute2Image[10]方法。Attribute2Image根据所给属性进行学习,因此可以生成包含不同属性的图像,如性别、头发颜色、年龄等。
虽然上述方法可合成相对逼真的图像,但仍然受制于有限的描述属性。随着多模态学习的发展,涌现了一批基于生成式对抗网络和深度卷积解码器的图像合成模型[2,5-7,10-27]。由Goodfellow等人[3]所提出的生成式对抗网络(GANs)主要由鉴别器和生成器组成。生成器试图生成合成的图像,进而“欺骗”鉴别器;鉴别器则试图区分真实图像与合成图像。基于此类特点,GANs可以应用在基于文本描述的图像合成领域,将对抗训练的目的定义为基于文本描述的图像合成:通过真实图像与“虚假图像”的不断“生成”与“判别”,逐步提升图像内容与文本描述关联性,最终达到基于文本描述合成图像的目的。
Reed等人率先提出基于深度卷积的GANs(DCGANs)[11]用于文本-图像合成[2]。DC-GANs使用字符级别的循环神经网络提取文本描述中的语句特征向量,并将之连同噪音作为cGAN[4]的输入。StackGAN[5]侧重于改善合成图像的质量,在词特征向量的基础上,通过两个GANs,将合成图像的分辨率从64×64提高到256×256。作为进一步拓展,StackGAN++[6]将StackGAN改进为端到端(End-to-End)网络,在降低GANs训练的不稳定性的同时,增加了颜色损失函数,提升了合成图像的色彩表达程度。鉴于注意力机制在深度学习各个领域的成功应用,AttnGAN[7]首先将全局注意力机制引入文本合成图像领域。AttnGAN利用文本编码器,提取语句和单词级别的文本特征向量,计算其与全局图像特征和局部图像特征的相似度,并通过提出的DAMSM预训练方式,提升了合成图像与描述文本的关联性以及清晰程度。随着研究的不断深入,基于文本描述的图像合成在高分辨率、多目标以及可控性上都取得了瞩目的成绩:HD-GAN[12]使用级联化的网络结果,将分辨率提高到512×512。Obj-GAN[13]可合成布局复杂的多目标图像,从布局、形状到内容逐步生成,改善复杂图像合成中存在的模型崩溃问题。为了解决因特定文本属性(颜色、目标)更改而导致整体构图重置问题,ControlGAN[13]基于AttnGAN结构,提出使用通道与空间注意力机制,增加单词-图像区域特征匹配性与感知损失等约束。
2 网络模型(SA-AttnGAN)
与AttnGAN类似,本文所提出的SA-AttnGAN网络结构分为预训练网络和多阶段生成对抗网络。在预训练网络中,引入AttnGAN中的DAMSM模块[7],此模块包含文本编码器与图像编码器,用于提取特征,并计算DAMSM损失作为生成器损失函数的一部分;而生成对抗网络则由三对生成器和鉴别器组成,分别处理64×64、128×128、256×256阶段的图像。
与大多数基于GAN的t2i模型相似,本文提出的基于自注意力机制的文本生成图像网络(SA-AttnGAN)采取多阶段的高分辨率图像合成策略(如图1所示)。其中,生成器G0、G1、G2分别合成64×64、128×128、256×256分辨率的图像。

图1 SA-AttnGAN网络结构图Fig.1 Architecture of SA-AttnGAN
在G0阶段,首先利用条件增强模块F ca,即图1中CA[5]模块用于处理语句特征向量eˉ,得到低维度的文本条件向量。随后将之与噪声向量z∈ℝ100相连,作为包含多个上采样块F0的输入,如式(1)所示:

其中,h0′表示隐藏节点,包含初始阶段待生成的图像信息。
与AttnGAN不同的是,在初始阶段,本文引入自注意力机制[17],通过对图像特征映射间的自主学习,分配不同的权重信息,使最终得到的特征图包含更多的空间与位置信息,进一步提升高分辨率图像合成的效果,降低模型生成崩溃的可能。
如图2所示,首先,将h0′转化到特征空间f和g,其中W f、W g是感知层,如式(2)、(3)所示:

图2 自注意力机制(SA)Fig.2 Self-attention(SA)

并计算权重信息βj,i,计算公式如式(4)所示:

其中s j,i=f(h0′)Tg(h0′)。βj,i表示合成图像第j个区域时的第i个位置的权重信息,它通过自监督机制学习特征图中空间与位置信息,为图像中重要的细节信息赋予了更大的权重值,有利于初始阶段生成更有意义的图像。之后再将h0′转换到第三个特征空间u,如式(5)所示:

其中,W u是特征空间u的感知层,用于改变特征的维度大小。随后将权重图βj,i与u(h0′)相乘得到带有注意力机制的图像特征矩阵m j,如式(6)所示:

最后使用conv_1×1使得到的图像特征矩阵m j转换到特征空间v,如式(7)所示,从而使得到的图像特征尺寸与输入的图像特征尺寸大小相同。

使用h0表示F sa(即图1中SA模块)的输出结果,通过利用注意力机制,此时初始阶段生成图片将包含更多有意义的位置与空间信息,如式(8)所示:

在G1、G2阶段,使用不同阶段隐藏节点h i作为输入,使用表示不同分辨率的生成图像,如式(9)、(10)所示:FGAi是第i阶段的全局注意力生成模块[14],Fi是第i阶段包含上采样块等神经网络层。

其中,生成器损失函数定义如式(11)所示:

其中:

LDAMSM是使用预训练网络得出的损失函数,λ是决定DAMSM模块对于生成器损失函数影响大小的超参数[7]。
如图1所示,本文采用的D0、D1、D2多鉴别器并行计算,输入图像尺寸分别为64×64、128×128、256×256。鉴别器D i由两部分组成,其中,i=0,1,2,每部分包含不同的判别内容,D1i判别图像的真实程度,D2i判别图像与文本的语义一致性,定义如式(13)所示:

Luncondition1用于鉴别输入的图像是否是真实,Lcondition2用于鉴别输入的图像是否与文本相关,计算公式如式(14)、(15)所示:

3 实验与结果分析
3.1 数据集
本文选择CUB数据集用于训练模型,CUB是剑桥大学制作的有关于t2i领域公开数据集[19],包含一万多张200余种鸟类的图片。其中,8 855张照片用于训练,2 933用于测试。每张图片配以10句文本描述。其描述内容涵盖鸟的头、嘴、胸脯、羽冠等10余种属性。
3.2 评价指标
为了保证实验结果的可对比性,本文选择Inception Score[29](IS)与Frechet inception distance(FID)[30]进行比对。IS该指标由StackGAN专门为CUB提出一套完整评价算法(https://github.com/hanzhanggit/StackGANinception-model),并在其他t2i工作中得到广泛使用。算法原理如下:

其中,x表示生成的样本,y表示通过算法预测的标签,通过计算p(y|x)与p(y)分布的Kullback-Leibler散度,值越大代表模型生成结果越好。IS指标越高,代表生成图像越清晰,多样性更高,模型稳定性越好。FID是另一种常用的评估指标,它计算真实样本,生成样本在特征空间之间的距离,算法原理如下:

其中,μr表示真实图片特征的均值,μg表示生成的图片特征的均值,Σx表示真实图片特征的协方差矩阵,Σg表示生成图片特征的协方差矩阵,tr表示对矩阵求迹。FID值越低则表示图片的质量和多样性越好。
3.3 实验设置
本文选择AttnGAN作为对比模型,AttnGAN是在文本生成图像领域中使用注意力机制,以句子级别和单词级别的文本特征作为输入,提升了合成图像的清晰度。
在文本编码器中,采用层数为1的Bi-LSTM[31],词嵌入大小为300,文本特征的维度为256。在图像编码器中,采用inception-v3[32]网络用于提取图像特征,全局图像特征维度为2 048,局部图像区域特征包含768个通道,每个通道维度为289,与AttnGAN[7]网络各通道参数相同。在训练阶段采用Adam[33]作为优化器,学习率设置为0.000 2。网络损失函数中,超参数λ设置为5。batch_size设置为10。
3.4 实验结果与分析
3.4.1 指标对比
本文提出的SA-AttnGAN模型在1块11 GB显存的RTX TITAN V显卡上共训练600个epoch,生成约30 000张测试集照片进行指标对比,结果见表1。
如表1所示,与其他众多具有代表性的方法相比,本文模型IS指标值最高,取得了4.52±0.03的成绩,FID指标最低,取得了14.25的成绩。与AttnGAN相比,IS指标提升了0.16,FID指标降低0.13。

表1 CUB数据集上方法对比Table 1 Index comparison based on CUB data set methods
图3中展示了600个epoch的IS指标变化,横坐标为epoch迭代次数,纵坐标为IS指标值,在450 epoch后本文方法的指标值优于AttnGAN的指标值。
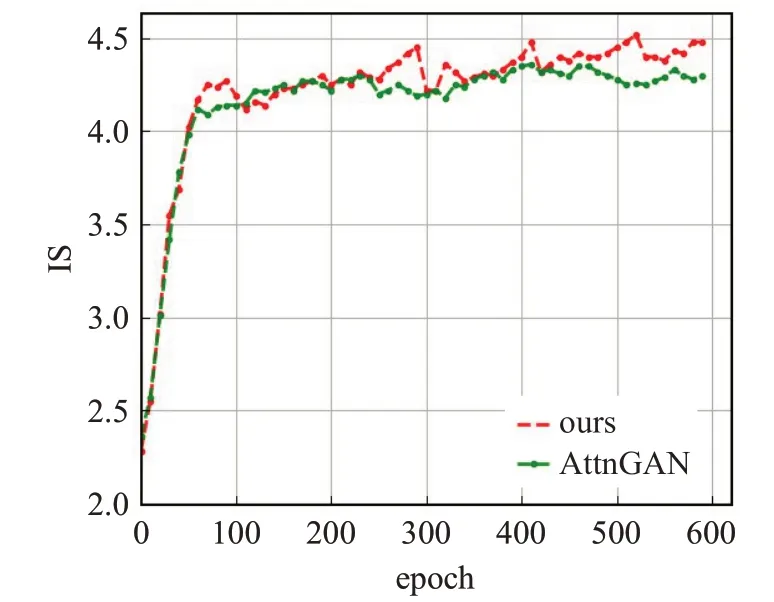
图3 不同epoch下IS指标变化图Fig.3 IS at different epochs
图4 中展示了600个epoch的FID指标变化,横坐标为epoch迭代次数,纵坐标为FID指标值,在380 epoch后本文方法的FID值优于AttnGAN的方法值。
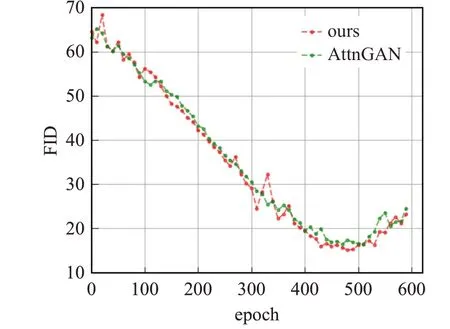
图4 不同epoch下FID指标变化图Fig.4 FID at different epochs
上述图表表明本文由于在初始阶段使用自注意力机制,通过自主学习图像间的特征信息,生成权重掩码图,使初始阶段最终生成特征图融合更多的空间与位置信息,使模型能够生成结构性信息更加完整的图像,从而进一步改善高分辨率图像合成的效果,提高了图像合成的清晰度与多样性。并且同时使用句子级别与单词级别的文本特征,提取更多的文本信息,提高了文本与图像间的语义一致性。
如表2所示,还计算了超参数λ在不同取值的情况下对两个指标的影响。λ是DAMSM网络模块[7]对于整体网络的影响程度,在分别取值为0.1、1、5、10后,λ=5时指标效果最优。

表2 不同超参数指标变化对比Table 2 Comparison of different hyperparameter indicators
3.4.2 合成效果对比
图5展示了SA-AttnGAN与众多具有代表性的方法的实验效果对比图。其中,HDGAN[10]、StackGAN++[6]、AttnGAN[7]方法分别使用官方实现的模型进行实验,在同一实验环境下对2 933条测试集文本进行测试。HDGAN模型是受StackGAN[5]启发,提出一种端到端模型,并且引入了伴随层次嵌套对抗性目标,侧重于提高图像生成的分辨率,但是并没有关注生成图像的结构性信息,鸟的部分属性生成不自然,如第三组实验,HDGAN生成的小鸟眼睛比例不协调。StackGAN++[6]模型是在StackGAN[5]模型的基础上,将其改变为端到端的模型,加入颜色正则化损失,重点改善多阶段生成图像的颜色一致性,但是该方法也缺少对生成图像的空间与位置信息的学习,如第三组实验,生成的小鸟与背景融为一体,整体生成失败。AttnGAN[7]使用注意力机制,并且使用了句子级别与单词级别的文本特征,增强了文本-图像的语义对齐性,但是对于鸟的重要的属性权重不能很好地学习,对部分属性过于关注,如第十组实验,生成了两只嘴,而第三组实验缺少嘴部等细节信息。而SA-AttnGAN方法在初始阶段加入自注意力机制模块,使模型能够学习到正确的属性权重分配情况,如第三组实验,生成的小鸟完整自然,表明该方法改善了文本生成单目标图像的视觉质量。

图5 测试效果部分展示Fig.5 Part of test results
图6中展示了加入自注意力机制模块的消融实验,SA-AttnGAN表示使用了自注意力机制,AttnGAN表示没有使用自注意力机制。图6分成四大组,每组有六小组对比实验。其中前三组展示了SA-AttnGAN与AttnGAN方法均合成出逼真自然的鸟类图片,如第三组第一句文本合成的效果图均符合文本语义,包含“brown bird”“white belly”等细节信息。第四组实验展示了部分生成有误的图像。如第四组第二句文本AttnGAN合成出了“多头”鸟,第二句话AttnGAN生成鸟类失败,而SA-AttnGAN合成出了正确的鸟类照片,后面将具体围绕这两部分进行实验分析说明。除此之外,第四组实验也展示了SA-AttnGAN与AttnGAN方法都生成失败的部分图像,如第四组实验第三、四、五、六句文本,分析原因是由于“Large bird”“Large wings”等文本描述会合成飞翔的鸟类照片,但是由于数据集中有关于翱翔姿态的照片较少,所以模型没有充分学习到该种图像的分布,最终影响了图像的生成结果。(1)“多头”“多嘴”等错误图像分析

图6 加入自注意力机制的消融实验Fig.6 Ablation experiment with self-attention mechanism
图6 中展示了部分生成状况良好的鸟类合成照片,但是在测试过程中AttnGAN方法也会合成一些错误图像,如图7中展示了六组AttnGAN模型与本文模型生成的高分辨率图像。可以发现AttnGAN经常会生成“多头”“多嘴”“多眼”等不符合常态的鸟类图片,如图7-1-2、7-3-2、7-4-2中AttnGAN方法生成了两只鸟头,7-2-2、7-6-2生成了两只鸟嘴,7-5-2生成了多只眼睛,而本文方法,在初始阶段使用自注意力机制,使模型不仅能够学习到背景等颜色等像素信息,还能够捕捉到目标的结构信息,正确生成鸟头、鸟嘴、鸟眼睛的位置与个数,改善了AttnGAN明显与文本特征不符的鸟类图片合成问题。

图7 “多头”“多嘴”等情况消融实验对比图Fig.7 Comparisonchartofablationexperimentsin“multi-head”and“multi-mouth”situations
(2)鸟类整体生成失败图像分析
自注意力机制不仅能够学习到重要的空间与位置信息,改善“多头”“多嘴”等错误情况,还可以提升t2i模型的稳定性,生成出更加逼真的鸟类图片。如图8-4-2、8-5-2中AttnGAN生成的图片无法看出是鸟,8-2-2、8-6-2等图片细节信息丢失,生成的小鸟不符合现实中鸟类的形状,与之相比,本文所提出的模型,能够合成与文本特征信息关联性较强的图像。以图8中第三组对比实验为例,本模型所合成的图像8-3-1能够正确地反映“whiteandbrown”“multicoloredbeak”等文本属性,且在构图上保证了合成图像内容与文本描述的一致性以及与背景图像特征的高区分性,而AttnGAN方法合成的8-3-2图像失真,没有正确生成文本语义信息。

图8 鸟类整体生成失败情况消融实验对比图Fig.8 Comparisonchartofablationexperimentsonoverallfailureofbirdgeneration
(3)图像生成细节分析
为了进一步解释本模型的效果,如图9所示,可视化了图像合成过程中的注意力权重图,保存了64×64、128×128、256×256的生成结果,例如在第一组实验中,对比发现AttnGAN在64×64的分辨率图像中将鸟尾生成了鸟头,后续在这种错误的图像信息上继续生成,导致高分辨率图像合成了错误的信息,而本文方法在初始阶段使用了自注意力机制,学习到了正确的目标图像信息,并且可视化了第三阶段生成图像时的文本与图像的注意力分配情况,选取前5个权重值最高的单词,文本与图像语义基本一致,所以初始阶段的生成图像对高分辨率图像合成具有重要意义。

图9 生成过程多阶段可视化Fig.9 Visualization of generation process at multi-stage
(4)t2i技术服装领域扩展应用
本文方法在服装数据集上也进行了测试,服装数据集中的图片是由cp-vton提供[34],包含14000多张照片,其中涵盖T恤、连衣裙、背心等6种女士服装,在此基础上为每张图片添加了一句中文文本描述,共计14000余条文本。从领子、袖子、颜色、功能等方面进行形容。由于服装数据集图片尺寸与CUB数据集不同,直接使用原网络无法生成完整的服装图片。因此在训练阶段通过膨胀边缘白色部分,重新裁剪至299×299,其余参数没有变化,通过测试发现,迭代第65次模型效果最佳,可以生成完整的服装图片,如图10所示。当迭代次数过多时,模型出现了过拟合现象,衣服颜色失真,生成效果不佳。

图10 服装数据集测试效果Fig.10 Synthetic images on fashion dataset
通过服装数据集的测试,证明本文方法基于自注意力机制文本生成单目标图像具有良好的泛化性,不仅可以生成自然逼真的鸟类图片,也可以生成效果自然的服装图片,并且中文英文均可以合成符合语义信息的图像。
4 结束语
本文提出了一种基于GAN的t2i网络模型,通过对自注意力机制的引入,提升模型的稳定性,在CUB数据集上,优化了IS指标与FID指标。实验结果表明,本文提出的网络能够生成清晰自然、逼真多样单目标图像,且具有一定的泛化性。此外,也进一步丰富了中文t2i数据集。未来的研究重点将关注文本生成服装图像在可控性方面的工作,将之应用在服装的生成与设计领域。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
当代陕西(2019年10期)2019-06-03
文苑(2018年21期)2018-11-09
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年9期)2015-11-10
中国卫生(2014年3期)2014-11-12
中国火炬(2014年4期)2014-07-24
