
结合注意力卷积网络与分块特征的步态识别
2022-02-24 12:37胡少晖王修晖
计算机工程与应用 2022年3期
胡少晖,王修晖
中国计量大学 信息工程学院 浙江省电磁波信息技术与计量检测重点实验室,杭州 310018
人体步态是在行走过程中由身体不同部位的运动信息综合体现出来的生物特征。与其他生物特征相比较,步态具有非侵犯性、无需被检测者的刻意配合、无需特定的采集设备、无需高分辨率的图像、难于伪装和隐藏等优点[1]。因此,在犯罪侦查、安全检查等多种场景下,步态特征作为安全识别具有很大的应用潜力。但是,因为被识别对象的衣着变化、行走速度和采集角度等外部因素的影响,步态识别研究仍然面临着严峻的挑战。
针对步态识别的特征表达问题,Han等人[2]首先提出了一种新的时空步态表示方法,即步态能量图(gait energy image,GEI),并利用一种轮廓图像失真分析方法合成步态能量图以解决缺乏训练步态数据的问题,然后借助于统计特征融合方法在真实和合成的步态能量图中获取步态特征进行个体识别。Jeevan等人[3]在提出了GPPE方法对步态时域特征进行表征的基础上,采用主成分分析和支持向量机进行特征提取和步态分类,该方法在一定程度下能够减小外观变化带来的影响。王修晖等人[4]提出了一种基于连续密度马尔可夫模型的人体步态识别方法,该方法借助Cox回归分析的自适应算法对训练过的步态模型进行参数自适应和步态识别。More等人[5]提出一种融合两种特征的步态识别方法,首先使用交叉小波变换和二部图模型提取动态特征和静态特征,归一化之后进行特征融合,最后将通过k均值聚类获得每个特征向量和聚类中心之间的欧式距离用作相似性度量。马勤勇等人[6]提出了一种瞬时步态能量图,相对于步态能量图增加了步态的运动信息,与步态能量图共同构成步态特征,最后用最近邻算法进行步态分类。鲁继文等人[7]提出了一种基于独立成分分析和多视角信息融合的步态识别方法,先通过对提取的步态特征使用独立成分分析进行压缩,再用支持向量机进行步态分类和识别,最后通过融合不同视角下的步态特征完成多视角下信息融合的步态识别。Wang等人[8]通过Gabor小波提取不同的方向和比例信息形成步态能量图,然后采用二维主成分分析减小特征空间维数,最后使用支持向量机进行步态识别。综上所述,目前传统机器学习方法已经大量地在步态分类中得到应用,并取得了一定的成果,但是在存在较大视角变化和着装差异的情况下,步态识别正确率仍然难以满足身份识别等实际应用的要求。
近年来,深度学习技术在运动目标检测与跟踪、图像分类与识别等方面受到日益广泛的关注,在步态识别研究中也得到了一定的应用。相对于传统方法,卷积神经网络能够更有效地提取特征的有用信息,从而提高实验效果。Chen等人[9]提出基于特征图池化的步态识别网络(feature map pooling,FMP),从步态轮廓序列中提取和聚合有用信息,而非通过平均轮廓图像简单地表示步态过程,然后采用特征图池化策略来聚合序列特征。Wolf等人[10]利用3D卷积神经网络学习步态运动的时空特征。Shiraga等人[11]提出步态能量图网络(GEINet)。GEINet以GEI为输入样本,由两组卷积池化归一层和两个连续的全连接层组成,最后用softmax进行分类。Chao等人[12]研究的跨视角步态识别方法是首先使用度卷积VGG-D提取特征,然后用主成分分析进行降维,最后用联合贝叶斯进行步态分类。Takemura等人[13]研究的是一种基于输入/输出结构的神经网络跨视角步态识别方法,它们设计了一个用于验证的暹罗神经网络和用于标识具有高级差异结构的CNN的三元组网络。Zhang等人[14]研究的是一种采用距离度量学习来驱动相似度量的暹罗神经网络,该方法中通过减小同一人和不同人的步态对的相似度量差值大小来实现步态识别;Tong等人[15]提出了一种应用于步态识别的新型时空深度神经网络(spatial-temporal deep neural network,STDNN),STDNN包括时间特征网络(temporal feature network,TFN)和空间特征网络(spatial feature network,SFN),丰富了步态特征。Wu等人[16]提出了一种通过深度卷积神经网络(DeepCNNs)进行相似度学习的步态识别方法。
综上所述,现在的很多步态识别方法通过卷积块获取全局特征,忽略了对一些重要信息的加权和可以反映局部信息的步态特征。针对上述问题,本文提出了一种基于注意力卷积神经网络和分块特征的跨视角步态识别方法,以步态轮廓图作为输入。首先经过注意力卷积神经网络进行有效信息的提取和增强,然后水平分成两块处理用以获取局部特征,最后将两部分的步态特征融合后进行步态分类。通过在两个经典步态数据集上的对比实验,证明了本文方法相对现有的方法,具有较好的识别效果。
1 模型算法
本文提出的基于注意力卷积神经网络和分块特征的具体网络模型如图1所示。该网络主要由注意力卷积神经网络和分块特征网络组成。使用无序的步态序列作为输入,首先用卷积神经网络提取帧级步态特征。在卷积神经网络中添加了通道和空间注意力机制[17](convolutional block attention module,CBAM)来增加特征在空间和通道上的表现力,在卷积神经网络的后部分使用了多通道卷积特征融合技术使步态特征具有多样性。然后帧级特征进行全局最大池化处理成能代表个人身份的特征块。分块特征网络主要是将输出的特征块水平分成上下两部分,然后每部分通过池化处理各生成一条一维矢量特征。最后联合triplet loss和softmax loss进行训练,增强网络的特征提取能力并有利于收敛。测试时通过计算训练时保存的序列特征与待测序列之间的欧式距离来预测待测人的身份。
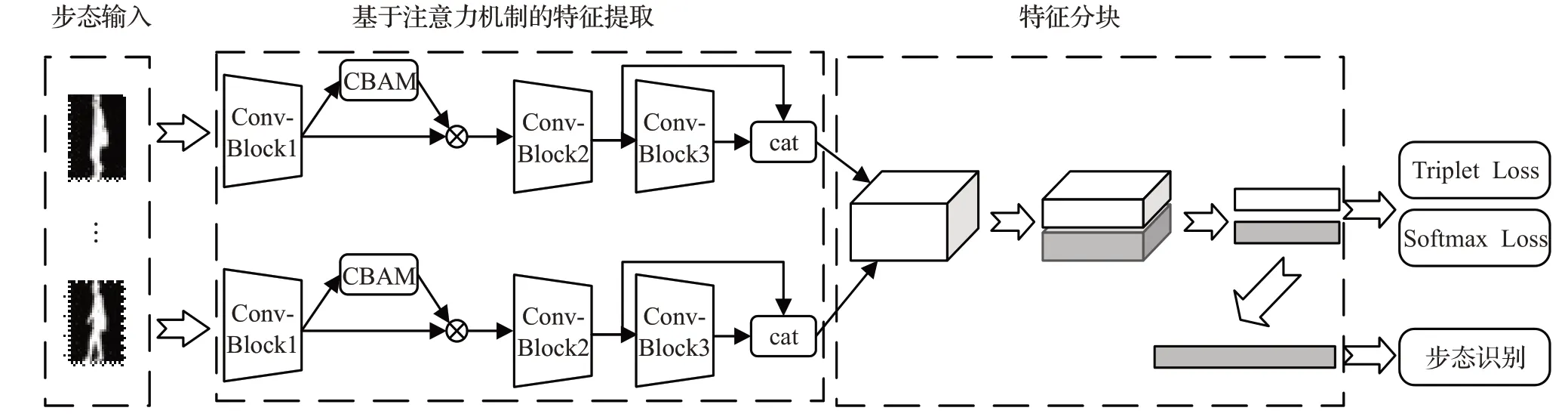
图1 基于注意力卷积神经网络和特征分块的网络模型Fig.1 Network model based on convolutional neural network with attention and part-level features
1.1 基于注意力卷积神经网络的特征提取
1.1.1 注意力机制
相对于传统方法,卷积神经网络能够更有效地提取特征的有用信息,但是在卷积和池化的操作中也会导致步态图像很多重要信息的丢失,使用注意力机制可以提高对步态重要信息的关注度。因此本文在使用卷积神经网络的基础上加入了注意力机制CBAM以更好地对步态特征进行提取。
CBAM表示卷积模块的注意力机制模块,结构如图2所示。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。相比于SENet[18](squeeze-andexcitation networks)只关注通道(channel)的注意力机制可以取得更好的效果。
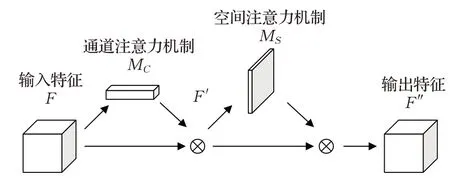
图2 注意力结构图Fig.2 Attention module map
一幅输入的特征图为F=ℜC×H×W要经过一维的通道注意力M C=ℜC×1×1和二维的空间注意力M S=ℜ1×H×W,过程表示为:

(1)通道注意力模块
将输入的特征进行空间维度压缩时,首先分别经过基于宽和高的全局最大池化和全局平均池化,得到两个不同一维矢量特征在一定程度上可以信息互补。然后分别经过一个共享的多层感知机。最后将多层感知机输出的特征进行基于elementwise的加和操作,再经过sigmoid激活操作,生成最终的通道注意特征图。通道注意力模块可以表示为:
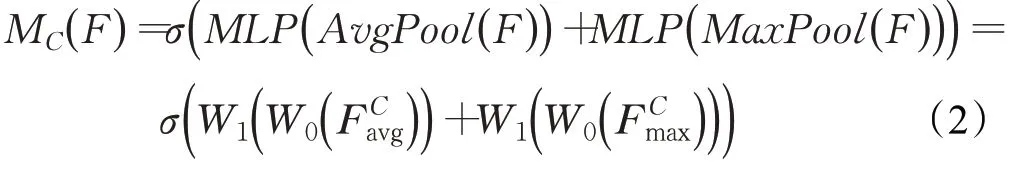
其中,F表示输入特征,W0和W1代表多层感知机模型中的两层参数,σ代表sigmoid函数。
(2)空间注意力模块
将通道注意模块输出的特征图作为本模块的输入特征图。首先做一个基于通道层面上的的全局最大池化和全局平均池化,得到两个二维的特征F Savg∈ℜ1×C×H和F Smax∈ℜ1×C×H。接下来将这2个二维特征按通道维度拼接起来。然后经过一个卷积(卷积核尺寸为7×7)操作,降维为1个通道。再经过sigmoid生成最终的空间注意特征。通道注意力模块可以表示为:
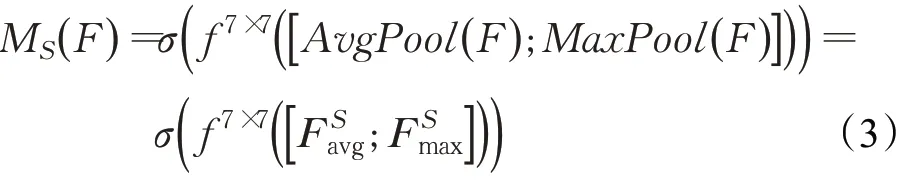
其中F表示输入特征,f7×7表示网络的卷积核尺寸是7×7。
对于一幅输入的步态图像,通道注意力和空间注意力分别关注图像中的特征内容和特征位置,在一定程度上相互补充,提升了网络的特征提取效果。经过多次实验之后,将该注意力机制放在第一个卷积层之后可以获得更好的效果。
1.1.2 网络结构设计
本文在设计网络时参考了经典的VGGNet[19]网络,经过多次实验,设计出了一个包含6个卷积层的网络,如图3所示(图中卷积层用C表示,池化层用P表示)。每两个卷积层后接一个池化层,后两个卷积层的后面不需要加入池化层,具体网络参数设置将在2.3节中以表格形式详细阐述。随机选择了特定帧数的步态轮廓图作为网络的输入,每帧步态图像都经过参数相同的卷积神经网络,从而输出高度抽象的步态图像特征。在模型中使用了多通道卷积特征融合技术,多通道卷积特征融合技术可以得到具有多样性特征的步态特征。如图1所示,将Conv-Block2和Conv-Block3的输出在通道维度上整合在一起作为新的输出,把多通道技术放在后层卷积的原因是后层提取的是抽象的高级图形特征,更接近目标特征,更有利于步态识别。
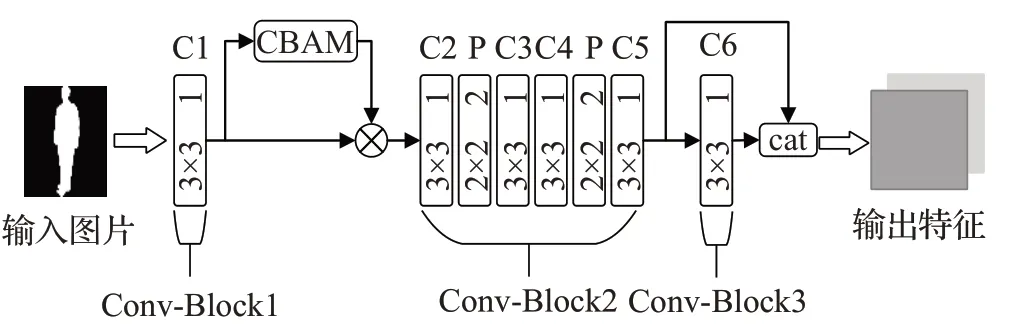
图3 注意力卷积网络结构图Fig.3 Convolutional neural network with attention module map
1.2 特征分块和损失计算
1.2.1 特征分块
现在的步态识别方法大多数只考虑全局特征,却忽略了局部特征也具有很重要的意义。不同的区域可以有不同变化特点和区分规则,给步态识别提供了不同的积极作用。头部相对来说变化幅度小,考虑的是一些本体特征,如脑袋形状等。而脚部分变化幅度大,除了本体特征之外更重要的是动态特征,如腿的动作幅度和弯曲程度等。为了更好地利用局部信息提高识别效果,将经过卷积聚合后的特征图水平切分成了两块,然后用基于宽和高全局池化分别处理两块特征,处理过程如下:
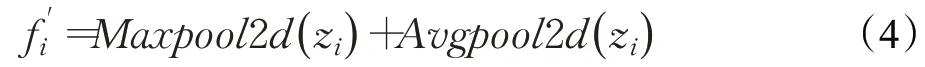
其中,f′i表示池化处理后的特征,Zi表示第i块特征(i∈1,2)。
池化后得到的是两条一维矢量特征,特征长度为C(即通道数)。接下来需要将两条特征向量进行不同的操作。训练时,将两条特征向量融合成尺寸为2×C直接进行损失训练;测试时,将两条特征向量在通道维度上进行融合得到一条长度为2C的特征向量。
1.2.2 损失函数
本文使用的Triplet loss和Softmax loss进行联合训练网络,联合使用效果高于单独使用任意一个损失函数。虽然基于Triplet loss的神经网络模型可以很好地对细节进行区分,但是三元组的选取会导致数据的分布不一定会很均匀,所以使得训练过程不太稳定,收敛慢,结合Softmax loss可以对数据分布有进一步的约束,而且加速收敛,训练过程更加稳定。
(1)Triplet loss
从训练组中随机选一个样本,称为A,然后再随机选取一个和A属于同一类的P和不同类的N,构成三元组(A,P,N),三元组损失Ltriplet由此计算:
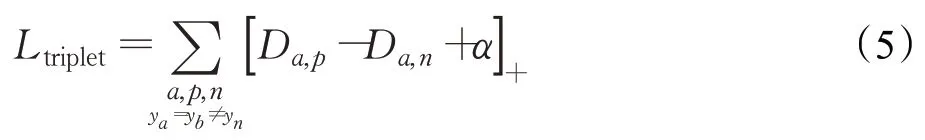
其中,ya、yb、y n分别表示属于A、P、N的一类,D a,p表示A与P之间的欧式距离,Da,n表示A与N之间的欧式距离,α表示margin。
(2)Softmax loss

其中,qtarget为真实值对应类别的预测概率。
结合后的损失为:

其中Ltriplet代表Triplet loss,Lsoftmax代表Softmax loss,β代表Triplet loss和Softmax loss之间的平衡因子,设为0.1。
2 实验与分析
2.1 评价指标
为了验证该方法的有效性,选择在CASIA-B步态数据库和OU-ISIR-MVLP步态数据集上进行实验评估,并与一些方法做对比。测试时给定待测样本库(Probe)中的一个序列p,输入到网络中生成待测步态特征Feature_p,目标是在目标样本库(Gallery)中遍历全部序列找到相同的ID的样本g。同样g也经过网络生成目标步态特征Feature_g,待测步态特征与样本步态特征通过计算欧式距离来判断一次命中的识别正确率,即Rank1识别率。具体步骤如图4所示。
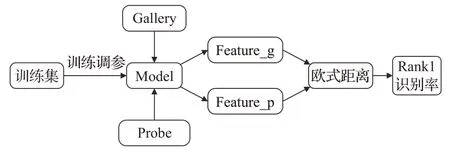
图4 Rank1识别率的计算步骤Fig.4 Rank1 recognition rate calculation steps
2.2 实验数据与实验环境配置
CASIA-B数据集是目前使用最广泛的跨视角步态数据集之一。该数据集提供了124个人的步轮廓图,每个人有正常条件(NM)、背包条件(BG)和穿大衣条件(CL)三种条件,每种条件又包含了11种不同的视角(0°,18°,…,180°)。每个人都有10组步态序列图像,其中正常条件下的步态序列图像有6组,背包条件下的步态序列图像有2组,穿大衣条件下的步态序列图像有2组。图5展示了CASIA-B数据集中同一个人在不同条件下的步态轮廓图。OU-ISIR-MVLP数据集是目前世界上最大的公共步态数据集。包含10 307个人,每个人有14个视角(0°,15°,…,90°;180°,195°,…,270°)。每个视角分为00和01两个序列。这两个数据集都属于目前步态识别领域最常用的经典步态数据集。

图5 CASIA-B数据集中的样图展示Fig.5 Sample graph display in CASIA-B dataset
实验中三元组损失的margin选择的是0.2,用于控制三元组类间和类内的距离。选择Adam作为优化器,网络初始学习率设为1E-4。编程环境为Pycharm,Python版本为3.6.0。深度学习框架是PyTorch,使用的GPU型号为NVIDIA GeForce GTX TITAN X。
2.3 在数据集CASIA-B上的实验结果及分析
在数据集CASIA-B的实验中,所有输入图片的大小经过调整后为64×44,批尺寸为(8×16),即随机选择8个人,然后每个人中随机选择16张序列图,迭代次数为80 000次。在特征提取部分的网络参数如表1所示。
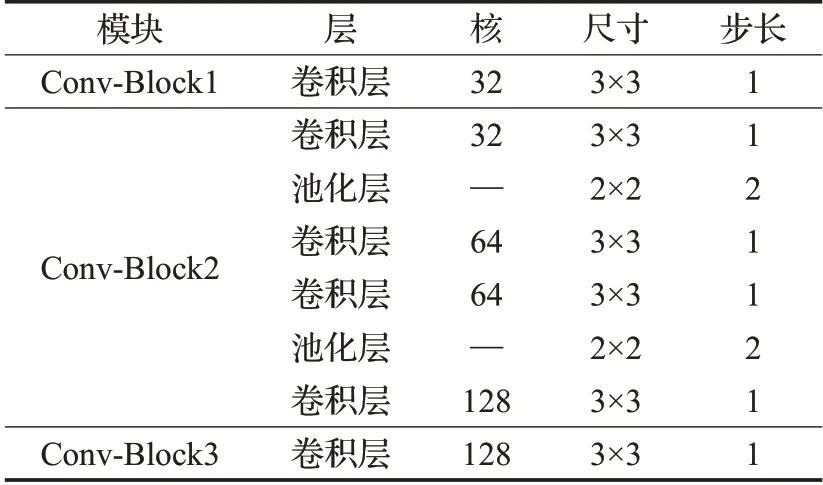
表1 在数据集CASIA-B上的卷积模块具体参数Table 1 Specific parameters of convolutional module on CASIA-B dataset
表2为各方法在CASIA-B数据集上小训练样本情况下的Rank1识别率对比。对比方法为基于局部运动特征选择的支持向量回归模型(support vector regression based on local motion feature selection,SVR)[20]、相关运动联合聚类模型(correlated motion co-clustering,CMCC)[21]、视角不变判别投影模型(view-invariant discriminative project,ViDP)[22]、深度卷积神经网络(Deep CNNs)[16]、非周期性步态识别模型(aperiodic gait recognition,AGR)[23]、注意力时空融合网络(attentive spatialtemporal summary networks,ASTSN)[24]。实验结果数据来自文献[16]和文献[24],且用前24人作为训练,后100人用于测试,该实验只针对正常条件(NM)下的步态测试。本文的模型在54°和126°的Rank1识别率与0°和90°的Rank1识别率有比较明显的差距,说明角度是影响识别率的一个重要因子。同时本文模型在0°、54°、90°和126°的Rank1识别率比ASTAN的效果高3.65、12.51、9.13和12.82个百分点,比DeepCNNs的效果高2.4、1.5、3.4、3.5个百分点。由实验结果对比证明本文方法在CASIA-B数据集上训练数据较小的情况下识别结果较优,同时在小训练数据样本情况下本文模型没有出现过拟合问题。
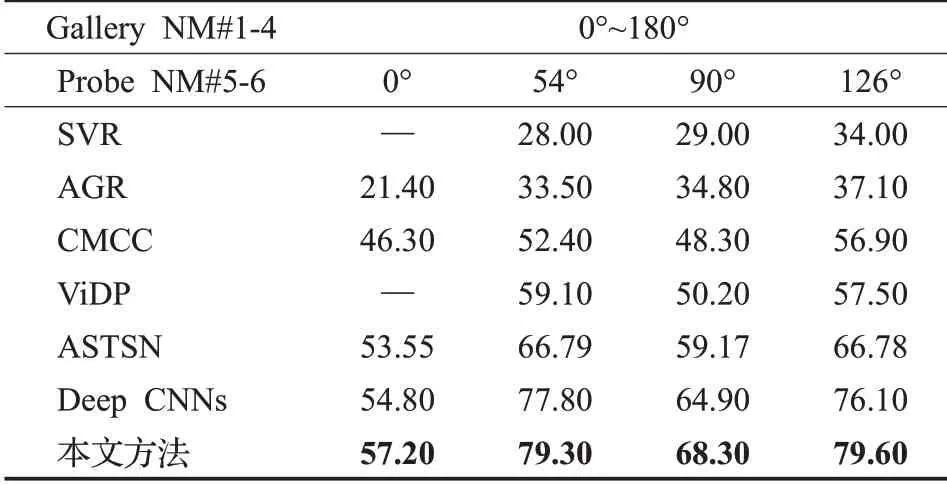
表2 各方法在CASIA-B数据集上小训练样本情况下的Rank1识别率Table 2 Rank1 recognition rate of each method in case of small training samples on CASIA-B dataset %
为了展示训练数据较充足情况下的跨视角步态识别效果,表3为各方法在CASIA-B数据集上的Rank1识别率。除了用前62个人训练,其余的实验配置与表2相同。对比实验包括基于自动编码器的不变特征提取深度模型(auto-encoderfor invariant gait extraction,AE)[25],生成对抗网络模型(GaitGAN)[26],多任务生成对抗网络模型(MGAN)[27]。为了证明本方法在各种条件和角度下都有一定效果,本次实验包括了三种条件和各个角度。由表结果对比可知,本文的模型在正常条件(NM)下的效果最好,其次是背包条件(BG),最后是大衣状态(CL)。原因可能是大衣对人的体型干扰严重导致特征的辨识度降低,最终影响步态识别的效果。本文模型在正常条件、背包条件和大衣条件下11个角度的平均识别精度比MGAN方法分别高19.6、20.5、19.5个百分点。本文方法在CASIA-B数据集训练集较充足的情况下识别效果依然明显。
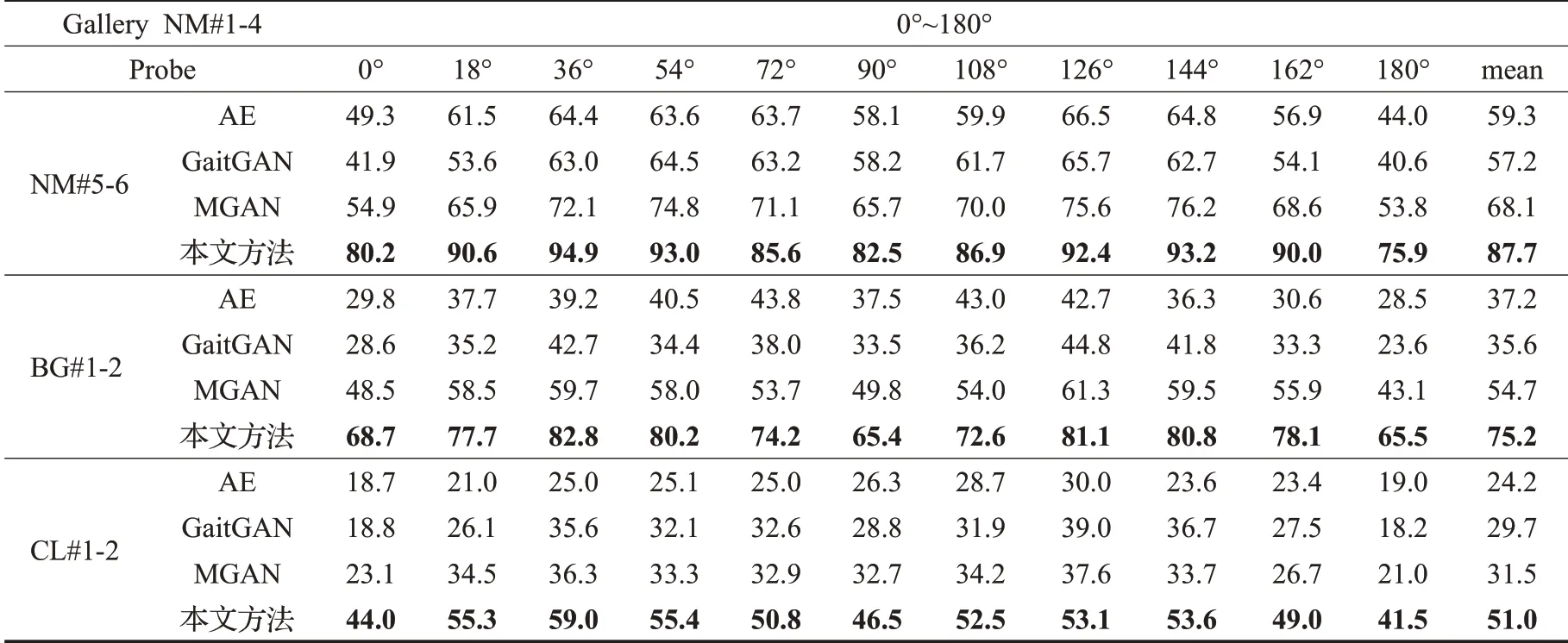
表3 各方法在CASIA-B数据集上训练样本较充足情况下的Rank1识别率Table 3 Rank1 recognition rate of each method in case of sufficient training samples on CASIA-B dataset %
2.4 在数据集OU-ISIR-MVLP上的实验结果及分析
在OU-ISIR-MVLP的实验中,由于实验数据偏大,所以将批尺寸设置为20×10。将用5 153个人进行训练,5 154个人进行测试。00作为目标样本集(Gallery),01作为待测样本集(Probe)。网络结构参数与数据集CASIA-B上的相同。迭代次数为1 500 000次。表4为各方法在OU-MVLP数据集上的Rank1识别率。对比实验包括GEINet[11]、输入输出结构卷积神经网络模型(input/output)[13],由于目前很少有针对14个视角的实验,因此本文实验抽取四个视角(0°、30°、60°、90°)方便进行实验对比。由表4结果对比可知,本文方法的识别效果明显优于其他两个对比实验的结果。这是因为相较于对比实验,本文模型不仅对全局特征进行提取,还通过特征分块对局部特征进行获取。这使得最终的特征更具表现力。综上可知,本文方法在OU-ISIR-MVLP数据集这种人数很多有挑战性的数据集上依然可以取得不错的结果。

表4 各方法在OU-MVLP数据集上的Rank1识别率Table 4 Rank1 recognition rate of each method on OU-MVLP dataset %
2.5 消融实验
为了证明本文提出的方法的有效性,将进行消融实验进行验证。实验将分为以下几部分:
(1)Baseline。此基线方法具体为先经过卷积网络,然后直接进行全局池化(分块),损失函数全为
Triplet loss。
(2)Baseline+Part-level。在(1)的基础上进行了分块处理,设置该实验的目的是证明特征分块的有效性。
(3)Baseline+Part-level+CBAM。在(2)的基础上加入了注意力机制CBAM,目的是证明CBAM的有效性。
(4)Baseline+Part-level+CBAM+Cat。在(3)的基础上加入了多卷积特征融合技术,目的是证明多通道卷积技术的有效性。
(5)Baseline+Part-level+CBAM+Cat+Softmax loss。在(4)的基础上将只用Triplet loss改成Triplet loss和Softmax loss联合使用,目的是证明联合损失的有效性。
在CASIA-B数据集上进行上述5次实验对比,本次实验使用74个人作为训练,得到的结果如图6~8所示,图6、图7和图8分别为NM、CL、BG条件下的对比结果。
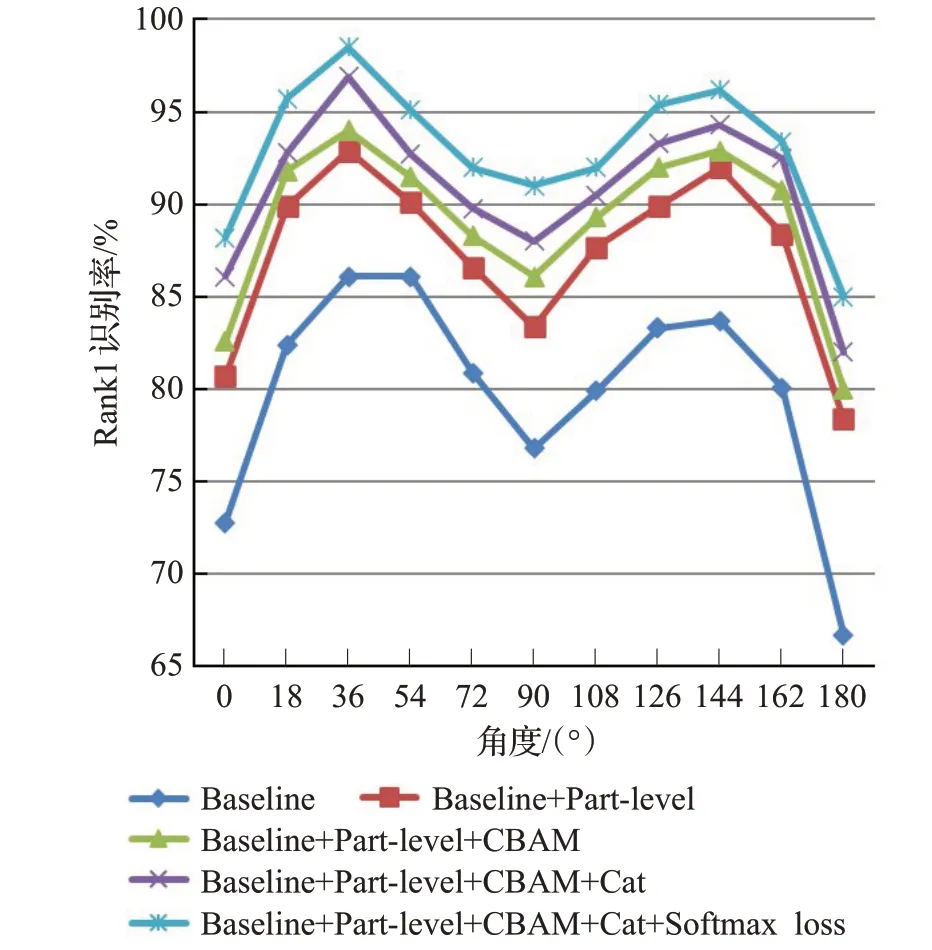
图6 NM条件下的实验结果Fig.6 Evalutation results under NM
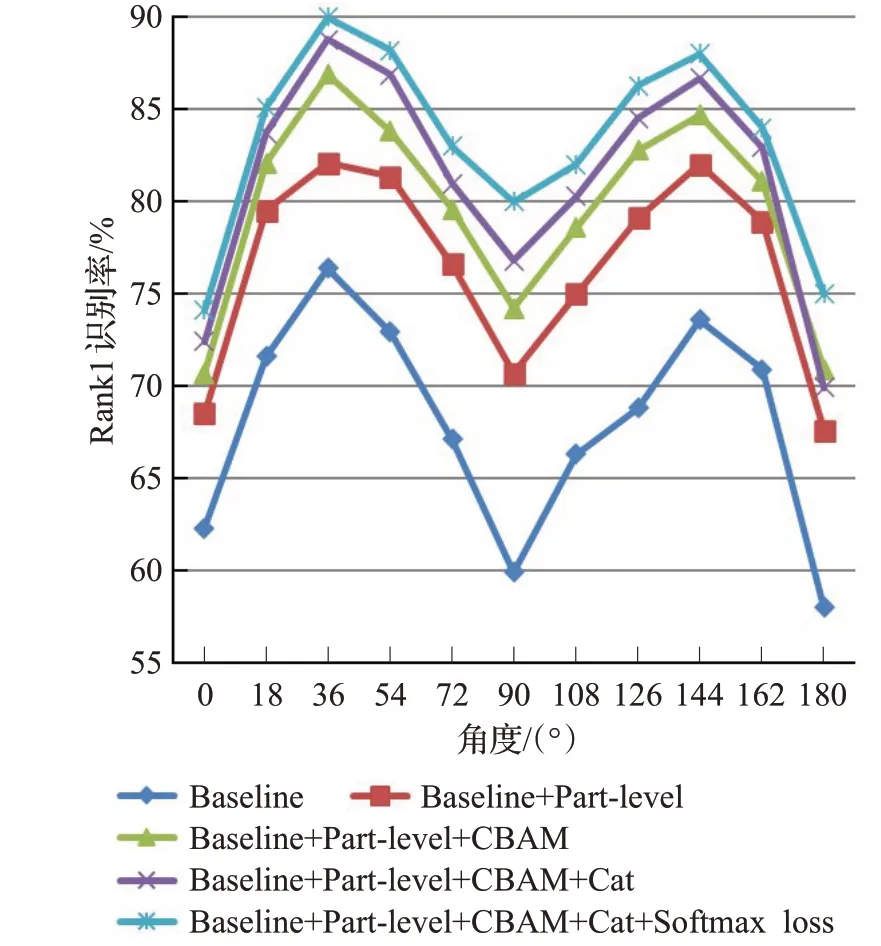
图7 BG条件下的实验结果Fig.7 Evalutation results under BG
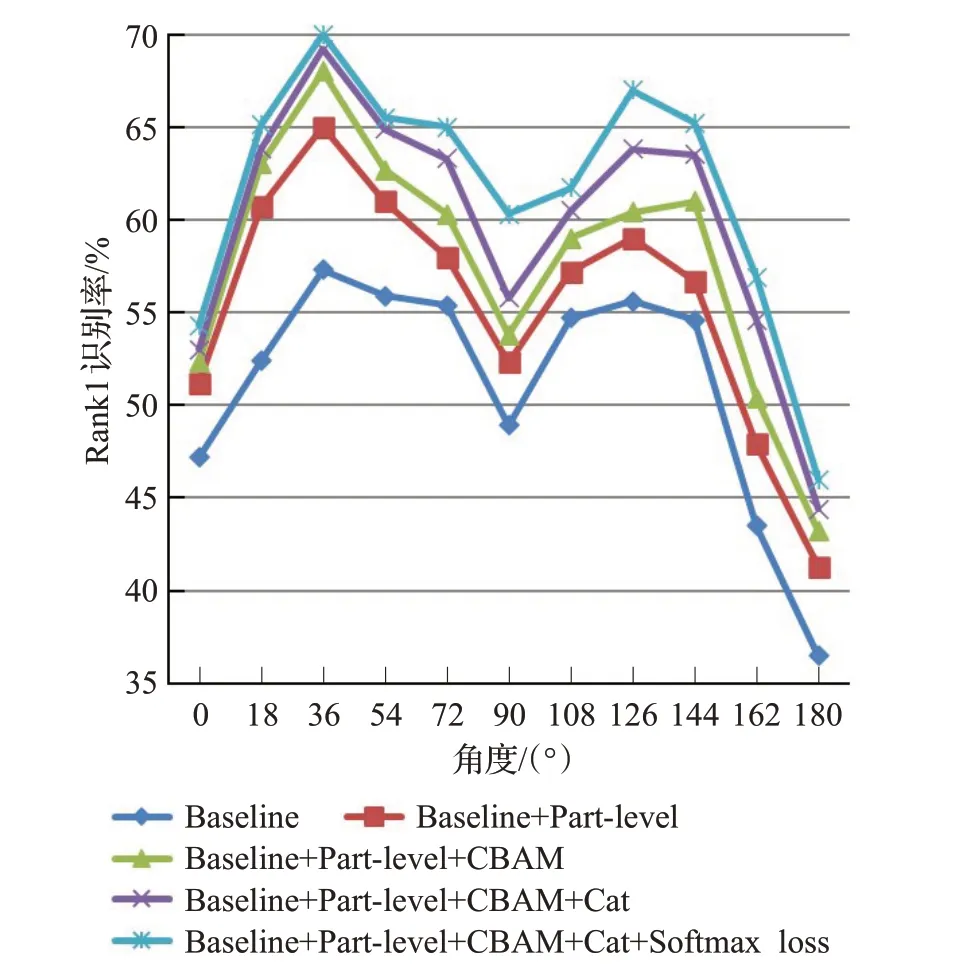
图8 CL条件下的实验结果Fig.8 Evalutation results under CL
由图中对比结果可知,本文提出的各部分方法对步态分类的结果都有一定的贡献度。尤其是特征分块,在各条件下的提升效果都尤为显著。经过特征分块,NM条件、BG条件和CL条件下的平均Rank1识别率分别提高了7.38、8.5和4.39个百分点。这说明局部特征的关注对步态识别有明显的提升精度价值。加上注意力机制CBAM之后NM条件,BG条件和CL条件下的平均Rank1识别率在上面的基础上分别又提高了1.76、3.09和2.17个百分点,说明了该注意力机制通过对通道和空间的特征处理有效地提升了特征的表现力。多通道卷积技术和联合损失函数对本文模型的效果也有一定的贡献度,同时联合损失函数可以加快步态识别收敛速度,更快捷地实现步态特征的提取。综合上述实验可得,本文方法在各种尺寸和环境的数据集中都有较强的识别效果,同时应用性很强。
3 结束语
为了更好地利用步态的局部信息,本文提出一种基于注意力卷积神经网络和分块特征的跨视角步态识别方法,该方法首先以步态轮廓图作为输入,经过相同的注意力卷积神经网络处理后融合成一个整体特征,然后通过将整体特征进行分块处理实现模型训练和步态识别。最后,在两个公开数据集上进行的对比实验,证明了本文方法与现有方法相比,具有较好的识别效果。
不足之处是,本文在分块时只是粗略地分成了两块,没有对各区域的具体作用大小进行深入探讨。曾尝试分成多块处理,但是没有明显提升而且增大计算量。今后将研究更加具体的分类方法和各分块对识别效果的作用大小,以提高分类精度。
猜你喜欢
现代仪器与医疗(2022年4期)2022-10-08
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
曲阜师范大学学报(自然科学版)(2021年3期)2021-08-26
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
电子制作(2018年18期)2018-11-14
科学之谜(2018年4期)2018-09-17
中山大学学报(自然科学版)(中英文)(2018年4期)2018-08-08
中国交通信息化(2018年3期)2018-06-13
