
基于作者偏好的学术投稿刊物推荐算法
2022-02-26 06:57董永峰屈向前李林昊
计算机应用 2022年1期
董永峰,屈向前,李林昊*,董 瑶
(1.河北工业大学人工智能与数据科学学院,天津 300401;2.河北省大数据计算重点实验室(河北工业大学),天津 300401;3.河北省数据驱动工业智能工程研究中心(河北工业大学),天津 300401)
0 引言
发表科研论文是学术工作者最关心的事情,找到合适的发表刊物是论文发表[1]过程中极为重要的一步。对于学术工作者而言,选择一个合适的出版刊物尤其重要。向合适的刊物提交论文将提高论文的被录用可能性,反之,如果提交论文的主题不满足学术刊物的录用要求,论文作者不仅将面临被拒稿的风险,还会浪费宝贵的时间[2]。借助推荐系统,如基于聚类和矩阵分解的协同过滤推荐算法[3]、基于用户偏好的信任网络随机游走推荐算法[4]等,根据不同的影响因素为每一篇文章找到最佳的出版刊物成为许多科研工作者的关注点。学术投稿刊物推荐系统(Academic Journal Contribution Recommendation System,AJCRS)主要应用于文章编辑完成后为作者找到合适的发表刊物。
科研工作者们为了给学术文章推荐一个满意的学术投稿目标刊物,探索了各种影响因素。一种是探索文章的内在特征,Yang 等[5]结合文章内容和文体特征,建立了一个文章写作风格分析系统,通过比较不同文章的写作风格,得出不同文章的相似性。Medvet 等[6]提出了基于文章摘要的主题匹配程序,并相应推荐了刊物。Dehdarirad 等[7]在2020 年基于数据来源、评价方法、未来方向等几乎所有要素,建立了出版刊物推荐系统。Dai 等[8]结合双向长短期记忆网络和分层注意网络,在推荐刊物时从摘要、标题、关键词和研究领域中提取作者关注点。另一种是探索作者的一些社会关系,强调与其他文章或作者的外部关系,并尝试构建集成内部组件和外部关系的联合模型。Luong 等[9]基于作者网络分析建立了一个框架,通过参考相关合著作者信息,为论文作者找到合适的学术投稿目标刊物,其核心思想是图论与概率论的结合。Pham 等[10]提出通过聚类的方法为社会信息建立模型,并学术投稿目标刊物推荐领域取得一定的效果。Chen 等[11]将社交网络用图建模,用基于随机游走的算法求解。Yu等[12]在合著者网络上运行了一个带重启的随机游走模型,由此产生并利用合作出版频率、关系权重和研究人员学术水平三种信息来完成最终推荐。Xia 等[13]进一步探索了研究人员的学术背景,将研究人员的研究兴趣纳入AJCRS 中,也整合了科研工作者的学术追求。最近,文章的文本相似性和作者的社交网络被整合在一起,形成了一个个性化的学术投稿目标刊物推荐系统[14],并根据学术投稿目标刊物推荐任务的特点,对已有的算法进行了调整。Alshareef 等[15]探索引文网络中潜在的关系信息,构建有效的学术投稿刊物推荐系统。
在过去的几年里,学术刊物推荐领域多以以下两个方面的研究为主:1)探讨文章内容信息与刊物之间的联系;2)分析作者合著者网络;但没有深度挖掘刊物的热度和学术焦点与时间的潜在联系。本文提出基于作者偏好的学术投稿刊物推荐算法(Academic Journal Contribution Recommendation algorithm based on Author Preferences,AP-AJCR),该算法是一种融合作者主题偏好和历史发刊记录的学术投稿刊物推荐模型。首先,使用潜在狄利克雷(Latent Dirichlet Allocation,LDA)主题分布模型,从标题中提取潜在的主题信息,并将所有文章分类成簇;然后,进一步探讨文章标题、日期和学术投稿目标刊物之间的联系,建立主题-刊物、时间-刊物图模型,使用大规模信息网络嵌入(Large-scale Information Network Embedding,LINE)概率模型来学习异构图节点的嵌入;接着,使用了两个参数来平衡作者主题偏好和历史发刊记录的向量表达;最后,求得在不同权重下融合作者主题偏好和历史记录的刊物得分,并向作者完成推荐。
1 相关工作
与本文相关的工作主要包含以下2 个方面:1)大规模信息网络嵌入(LINE)模型;2)基于图嵌入的推荐算法。
1.1 大规模信息网络嵌入模型
Tang 等[16]在2015 年提出了一个大规模信息网络嵌入(LINE)模型。此模型主要解决低维向量空间中嵌入超大信息网络的问题,该问题在可视化、节点分类、链接预测等任务中均有应用。
Tang 等[16]将信息网络定义为图的结构G=(V,E),其中:每个节点定义为一个数据对象,而V表示节点集合,E表示图节点之间的边信息。每个e∈E都表示一个有序对e=(a,b),且都有关联的正权重wab表示关联强度。给出了如下定义:
1)一阶相似度:一阶相似度是网络中两个节点的局部相似度。若节点a和b之间有边(a,b),则使用边的权值wab表示a和b之间的一阶相似度;如果a和b之间没有可以观察的边,则一阶相似度设为0。对于每条边(a,b),其连接可能性的定义如式(1)所示,其中p1=1/(1+exp(-x))是一个常规概率函数,a∈Rd是节点a的低维向量表示,p(·,·)是|V|*|V|向量空间下的一个分布,它所验证的概率可以被定义为,其中W=。为了保留一阶相似度,可以直接最小化式(2)目标函数,其中d(·,·)表示两个分布的距离。
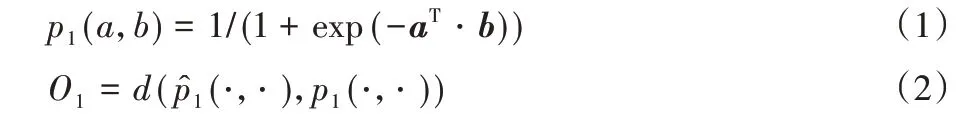
通常d(·,·)选择使用KL(Kullback-Leibler)距离,KL 距离主要用于衡量两个随机变量的差异程度,计算方法如下:
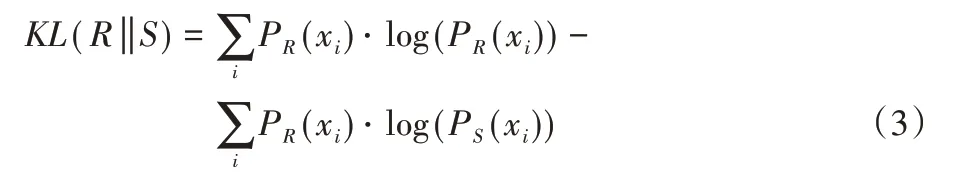
其中:x表示一个随机变量,R和S表示两个分布,PR(xi)和PS(xi)表示两个事件发生的概率。
通过寻找使式(4)最小化的节点的嵌入向量,可以在d维空间里表示相应节点。

2)二阶相似度:网络中一对节点(a,b)之间的二阶相似度是它们相邻网络结构的相似度。使用sima=(wa,1,wa,2,…,wa,|V|)描述节点a与其他节点的一阶相似度,那么a与b的二阶相似度取决于sima与simb之间的相似度。如果没有从a到b连接(或从b到a)的中间节点,则a和b之间的二阶相似度为0。二阶相似度定义如下:
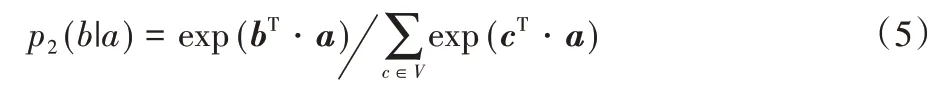
为了保留二阶相似度,从而得到目标函数(6),其中λa表示节点a的度(在有向图中,一般使用节点的出度)。
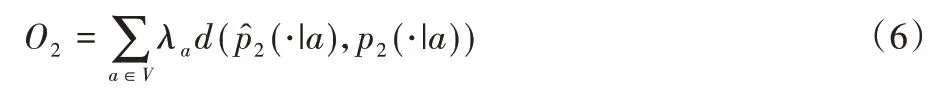
同样地,使用KL距离来代替d(·,·),得到了目标函数:

3)大规模信息网络嵌入:给定一个大型图G=(V,E),大规模信息网络嵌入的目标是把每个节点a∈V嵌入到低维向量空间Rd中,且节点间的一阶相似度和二阶相似度都被保留。
1.2 基于图嵌入的推荐算法
Xie 等[17]提出了一种基于图的兴趣点(Points of Interest,POI)嵌入学习算法,构建了三个二部图,通过使用LINE 模型的一阶相似性和二阶相似性进行嵌入学习,在推荐时,作者根据用户动态偏好建模,使用了一组直接相加的用户历史位置向量来表示用户向量,如式(8)所示。通过直接相加用户、时间片段、上下文三方面对位置的评分完成推荐,如式(9)所示。
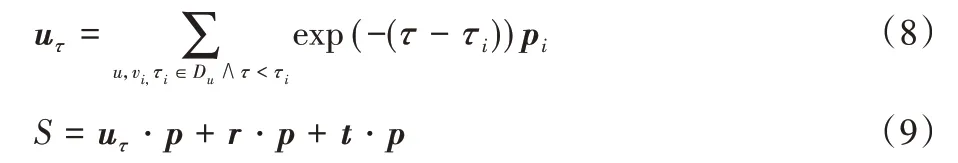
其中:uτ表示用户在τ时间段的嵌入向量,p表示兴趣点的嵌入向量,r表示位置信息的嵌入向量,t表示时间片段的嵌入向量,S表示算法计算的用户对兴趣点的得分。式(8)主要用于计算用户行为偏好,通过用户历史兴趣点的表示向量来计算用户的向量表达;式(9)则将地点因素和时间因素对最终评分的影响纳入到推荐模型中。
Hu 等[18]提出了基于图嵌入的细粒度POI 推荐算法,在Xie 等[17]的基础上,建立了5 个二部图,完成更细致的项目推荐,在表示用户偏好时,仍然是以简单直接相加表示,并未考虑不同向量在表示用户时,各个表示因素所占权重对推荐效果的影响。
2 模型算法
2.1 问题描述
在一些流行的文献数据系统(例如DBLP)中,只提供作者u、标题t、日期y、刊物v这四种信息,因此可以使用四元组(u,t,y,v)表示任意的论文发表活动。U、T、Y和V分别是所有作者、标题、日期和学术投稿目标刊物的集合。本文的研究内容为:给定一个含有论文发表行为的数据集,作者u,一篇该作者新的文章标题t,以及预计投稿的日期y(即查询q(u,t,y)),本文的目标是返回给该作者一个由期刊组成的列表,供作者选择投稿。
2.2 训练前准备
2.2.1 提取主题
在实际研究中,直接分析一个刊物和一个特定的名称之间的联系没有太大意义,所以本文从文章标题入手,提取文章主题。由于一个刊物通常与一系列的学术领域相关,本文将提取论文主题,并将其作为一个给定的标题及其所在刊物之间的桥梁。首先本文对原始数据进行预处理操作,工作内容包含数据清洗,因为一篇文章的作者署名通常根据贡献进行排序,排名靠前的作者往往占据了文章相当大的工作,本文去除作者数量超过6 的文章中第6 个作者以后的作者信息;接着去除停用词;然后删除标点符号;最后删除字母小于2 个的单词。需要注意的是,一些论文数据库中会收录一些预出版的论文,如DBLP 中会收集arXiv 中计算机领域的文章CoRR,本文在数据清洗阶段也删除了这类数据。
为了从这些标题中提取主题,本文使用LDA 模型。在本文中,主题用s表示,所有主题的集合为S;于是,构造一个新的四元组,表示为H:(u,s,y,v)。包含所有论文的整个数据集由H表示。
刊物推荐任务是根据作者过去的出版记录向作者推荐学术刊物。因此,对于每个作者u,本文创建了一个用户配置文件来记录该作者所有相关的四个元组,并使用Γui:{h|u=ui,h∈H}表示。
学术投稿目标刊物推荐实际上是一个建立用户(作者)和对象(学术投稿目标刊物)之间联系模型的任务,每次提交决定都是由作者做出的。这里的作者指的是第一作者,本文认为每一篇文章的主题都是由第一作者的研究兴趣决定的。在每一篇文章中,作者、标题(主题)以及日期(时间)的联系在出版记录中都比较明确。因此,以下建立不同主题与投稿目标刊物之间、日期与刊物之间的联系模型。
2.2.2 构建主题-刊物二部图
主题-刊物二部图:记为GSV:(S∪V,eSV),表示不同主题在特定刊物的受欢迎程度。其中,S是提取的所有主题的集合,V是所有学术投稿目标刊物的集合,eSV是主题和学术投稿目标刊物之间的一组加权边。对于每个特定的边(例如,以节点si和vj之间的边为例),其权重由式(10)决定:

其中:N(·)是一个数字计数器函数,表示主题为si、刊物为vj的所有四元组H的数量与主题为si的所有四元组H的数量的比值,即刊物vj上发表的主题为si的论文在所有主题为si的论文中所占的比值。
此外,利用阈值来消除边缘的不显著性(即权值较小)。这是因为,某一刊物很少接受某一主题的文章,向编写了这个主题文章的作者推荐该刊物并不是一个合理的选择。然后,构造相应的负边,对于每个节点vj,如果没有正边连接到它,本文将不为它安排负边;相反,一旦有正边连接到它,本文在si中随机地选择数个没有连接到vj的节点来构造负边。
2.2.3 构建时间-刊物二部图
时间-刊物二部图:记为GYV:(Y∪V,eYV)。这张图主要估计了研究人员在不同时段对特定学术投稿目标刊物的关注程度。对于每条边,权值直接由每年发表论文的数量比值定义,由式(11)决定:
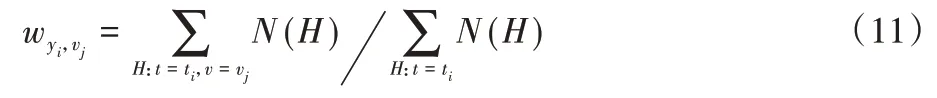
在学术投稿目标刊物推荐任务中,推荐的学术投稿目标刊物不仅由被查询的文章来确定,还由它的相关信息来确定。因此,在建立了上述单级连接之后,另一个任务是在这些节点之间找到更深层次的连接。本文从两个二部图出发,进行嵌入学习操作来寻找更多可能的连接。在嵌入过程中,通过保留部分原始连接来探索更多的潜在连接,每个节点对应的相似性和差异性都应该反映在本文最终的推荐图中。
2.2.4 建立模型
最终,在推荐图中,每个节点都由一个向量表示。使用s、y和v分别表示主题节点s、时间节点y和刊物节点v的嵌入向量。本文参考Xie 等[17]异构图节点嵌入学习方法估计了边存在的概率(例如,在节点si和vj之间)由式(12)决定:


其中:a和b是任意两个分居二部图左右两侧的节点。E是所有潜在节点的集合,即E=S∪Y∪V,wa,b是式(10)和(11)中所对应的正边的权值,是对应负边的权值。至此得到了模型的目标函数(15)。为了求解式(15),本文采用异步随机梯度下降(Asynchronous Stochastic Gradient Descent,ASGD)方法。

2.3 刊物推荐
通过执行上述节点嵌入过程,本文获得嵌入的主题s、时间y、刊物v向量。为了更好地捕捉作者对学术投稿目标刊物的偏好,本文结合了作者最近在选择目标学术投稿目标刊物时的行为。本文分别用ur、yr和tr表示新提交文章的作者、时间和标题。AJCRS 会向提交者(一般是学术工作者本人)返回查询q(ur,tr,yr)所得到的推荐刊物列表。
首先,本文引用作者的历史出版记录来查询作者在不同时间的发刊数据。为了自适应地表示作者的动态行为,本文进一步安排一个时间系数,作者的历史出版记录的时间越接近提交日期,系数越大,反之,那些日期久远的文章将对本文的推荐产生很小的影响。具体基于作者历史发刊记录向量计算公式由式(16)给出:
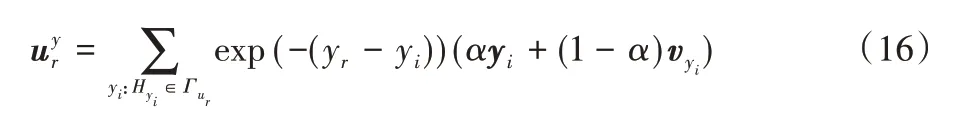
其中:yr是作者预计投稿时间,α是用于平衡嵌入向量的参数。然后,可以通过简单地将刊物的嵌入的向量与这个作者偏好向量进行比较,即对不同刊物vi进行评分,如式(17)所示。最接近作者偏好的刊物将被推荐。

其次,作者的研究兴趣在于多个主题,这也可以从用户配置文件中的记录中体现出来。本文使用ur发表过的刊物和主题来构建主题偏好向量。为了得到严谨的推荐结果,一篇文章一般涉及几个主题。文章与第k个主题相关的概率由多项式朴素贝叶斯算法计算。作者的主题偏好向量由学术投稿目标刊物向量和历史主题向量的加权线性组合表示,如式(18)所示:

其中:ρk表示提交文章与第k个主题相关的概率,β是用于平衡嵌入向量的参数。可以通过将刊物的嵌入的向量与这个作者主题偏好向量进行比较,即对不同刊物vi进行评分,如式(19)所示。最接近作者主题偏好的刊物将被推荐。

最后,本文将作者历史发刊记录评分和主题偏好评分结合,得到一个综合评分作为最终推荐决策的评分标准。

参数η平衡了主题偏好和历史发刊记录的影响,其最佳值将在本文的实验中进一步探索。基于式(20)。本文可以计算出所有候选刊物的得分,并据此做出推荐。
2.4 算法流程
结合上述操作,基于作者偏好的学术投稿刊物推荐算法的流程如下:
输入 数据集中所有四元组H:(u,s,y,v)形式的发刊记录,标题集合T,日期集合Y,学术投稿目标刊物集合V,和一个查询q(ur,tr,yr)。
输出 由N个学术投稿目标刊物组成的列表。
步骤1 数据预处理,进行数据清洗,去停用词,去除字母少于两个的单词,去标点符号等;
步骤2 使用LDA 主题提取模型算法从标题集T中获得主题集S;
步骤3 建立两张二部图:通过式(10)和式(11)分别建立主题-刊物二部图GSV:(S∪V,eSV),时间-刊物二部图GYV:(Y∪V,eYV);
步骤4 使用异步随机梯度下降方法训练模型;
步骤5 通过式(16)和式(17)分别计算作者的历史发刊记录向量和各个刊物的得分;
步骤6 通过式(18)和式(19)分别计算作者的主题偏好和主题偏好下各个刊物的得分;
步骤7 通过式(20)计算各个学术投稿目标刊物对每个作者的最终得分,并由高到低排序,将最高的N个刊物返回给学术工作者。
3 实验结果及分析
3.1 数据集
DBLP 数据集 DBLP 是计算机领域内对研究的成果以作者为核心的一个计算机类英文文献的集成数据库系统,按年代列出了作者的科研成果,包括国际期刊和会议等公开发表的论文。DBLP 提供计算机领域科学文献的搜索服务,但只储存这些文献的相关元数据,如标题、作者、发表日期等。
PubMed 数据集 PubMed 是一个提供生物医学方面的论文搜寻以及摘要,并且免费搜寻的数据库,其数据主要来源 有:MEDLINE、OLDMEDLINE、Record in process、Record supplied by publisher 等。
在DBLP 数据集中,本文的测试数据为DBLP 2019 年的记录。训练数据包括DBLP 中2009—2018 年期间的所有记录。记录的详细信息见表1。本文的评估标准是Recall@N。Recall@N会估计真实提交出现在Top-N推荐列表中的情况。DBLP 测试数据由122 739 个样本组成,测试任务是从1 407名计算机科学领域的投稿刊物中,推荐Top-N学术投稿目标刊物。此外,PubMed 数据集中,大部分文章只有标题,这与本文的研究动机一致。由于计算能力有限,本文使用了PubMed 中的部分记录。
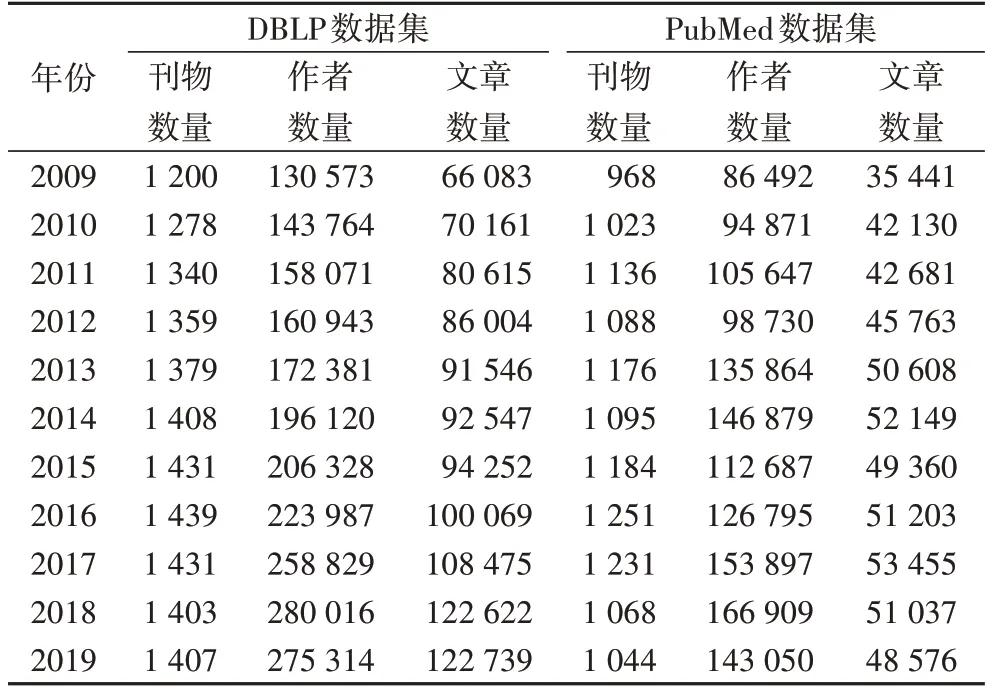
表1 实验中使用的数据集Tab.1 Datasets used in experiments
3.2 实验配置
3.2.1 参数设置
本文使用手工估算的方法分别在DBLP 和PubMed 数据集上测试了式(16)、(18)和(20)中的参数α、β和η的取值,结果如图1 所示。
其中,图1(a)是在DBLP 数据集上测试的α、β和η三个参数取值,图1(b)是在PubMed 数据集上测试的α、β和η三个参数取值。从中可以发现,选择过大或过小的参数值都会降低算法的性能。本文在调整参数α时,首先将η设置为1,根据式(20)可知,此时仅考虑作者历史发刊记录、各个刊物学术焦点和时间的潜在联系;而在调整参数β时,将η设置为0,根据式(20)可知,这时本文仅考虑主题与刊物之间的联系。通过上述操作分别得到了参数α和参数β的最优值,通过调整η的取值,可以得到本文模型的最好的推荐效果。由图1 可见,对于DBLP 数据集,在α=0.60、β=0.35 和η=0.45 时得到最优值;对于PubMed 数据集,在α=0.60、β=0.30 和η=0.40 时得到最优值。
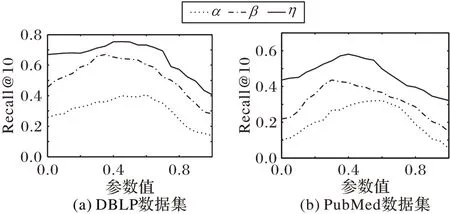
图1 两个数据集上不同参数设置的比较Fig.1 Comparison of different parameter settings on two datasets
3.2.2 主题数量对实验结果的影响
本文通过实验分析了主题提取数量对推荐Recall@10 的影响,结果如图2 所示。对于DBLP 数据集,主题提取的数量在少于40 时,对结果的影响比较大;主题数量在40~80 时,结果相对稳定;而主题数量多于80 时,算法结果略有下降,本文推测是因为当LDA 算法提取主题数量太大时,会导致在图嵌入时一些刊物和主题间的潜在联系消失,同时也出现了过拟合等问题。对于PubMed 数据集,当主题数量少于60时,对最终推荐效果影响较大;主题数量在60~100 时,推荐效果比较平稳;而当主题数量在100 以上时,算法推荐效果会略微下降。综上,本文设定主题数量为60。
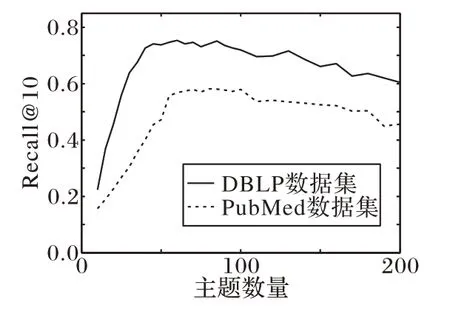
图2 主题数量对推荐结果的影响Fig.2 Influence of topic number on recommendation result
3.3 性能比较及实验分析
本文选取NMF(Non-negative Matrix Factorization)、DeepWalk、SVD(Singular Value Decomposition)、SVD++、KNN、CF 六种常用推荐方法,在推荐刊物列表长度为N的召回率(记为:Recall@N)方面进行比较,其中N=1,5,10,20,30。结果如表2所示。
从表2 可以看出,本文提出的AP-AJCR 算法在两个数据集上的表现均优于其他方法。在DBLP 数据集上,相较于SVD、SVD++、KNN、CF、DeepWalk 和NMF 方法,AP-AJCR 在Recall@10 上分别提升了0.525 0、0.479 6、0.382 7、0.548 0、0.087 4 和0.445 5;在PubMed数据集上,分别提升了0.375 9、0.358 9、0.354 5、0.358 2、0.024 1 和0.299 5。相较于其他方法,本文提出的AP-AJCR 算法总是能把作者“感兴趣”的刊物排在推荐列表靠前的位置。次优的方法是DeepWalk 方法,在进行图嵌入时,DeepWalk 方法通过随机游走的方式捕捉图的结构,适用于无权图,而本文提出的APAJCR 算法可以充分利用网络结构中边的信息,信息利用率高,故AP-AJCR 算法要优于DeepWalk 方法。通过表2 中数据可以得出,在仅使用论文内容信息中的标题数据的情况下,AP-AJCR 算法仍然有较高的推荐质量,由此证明了所提出的推荐方法的有效性和鲁棒性。
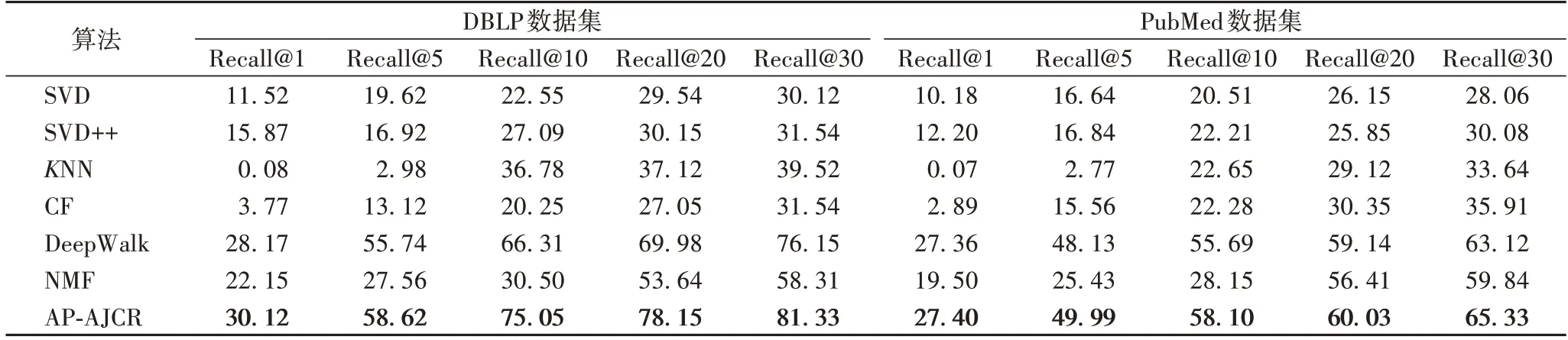
表2 不同算法在DBLP数据集和PubMed数据集上的推荐性能比较 单位:%Tab.2 Comparison of recommendation performance of different algorithms on DBLP dataset and PubMed dataset unit:%
然后本文将训练数据集的大小由10 年数据缩小到7 年和4 年进行了实验分析,即将2009—2018 年的训练集大小分别缩小至2012—2018 年和2015—2018 年,以探究不同时间跨度对推荐算法鲁棒性的影响,结果如图3 所示。在训练数据充足的情况下,本文算法会给出有效的推荐结果,在DBLP数据集上,10 年时间跨度的Recall@10 达到0.750 5,7 年时间跨度的Recall@10 有0.605 5,4 年时间跨度的Recall@10 仅有0.250 9;在PubMed 数据集上,10 年时间跨度的Recall@10 达到0.581 0,7 年时间跨度的Recall@10 有0.501 3,4 年时间跨度的Recall@10 仅有0.198 5。

图3 本文算法在不同时间跨度的训练集上的推荐鲁棒性比较Fig.3 Comparison of recommendation robustness of the proposed algorithm on training sets with different time spans
造成这种结果的原因是当数据不充足时,时间-刊物二部图GYV会受到很大的影响,时间跨度缩小会出现两个问题:1)刊物的学术焦点在很短的时间段内难以捕捉,作者对刊物的潜在的动态偏好很难展现出来;2)对于科研工作者而言,他们通常需要一定时间的研究与实验,才能完成自己的学术成果,数据集时间跨度较短时,数据稀疏性问题对推荐效果的影响明显。但是,在实际情况下,大部分公共学术发刊活动数据集都有相当长的历史,出版记录丰富且完备,故本文基于图嵌入的作者偏好推荐算法在实际情况下是可靠的,在实际应用中具有良好的普适性。
最后,本文测试了算法的训练阶段和推荐阶段的时间消耗,详细信息见表3。
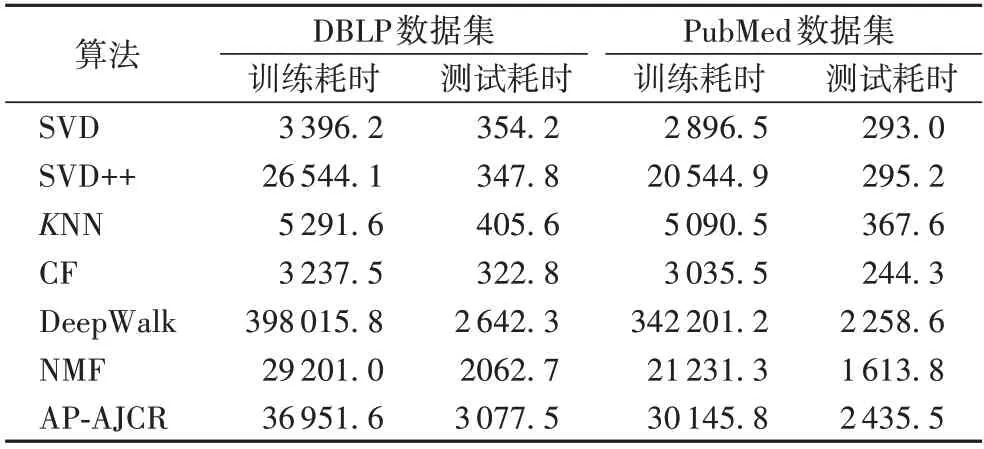
表3 不同算法在训练阶段和测试阶段的耗时比较 单位:sTab.3 Comparison of time consumption of different algorithms in training stage and testing stage unit:s
通过对比表中数据发现,SVD、SVD++、KNN、CF 方法无论是在训练阶段还是测试阶段,耗时都明显较低,而DeepWalk、NMF 和AP-AJCR 耗时相对较高。对精度要求不高,但对测试阶段耗时要求比较高的情况下,KNN 和SVD++可以胜任工作;对精度要求不高,对训练阶段耗时要求较高的情况下,推荐使用KNN 算法;在要求推荐精度的情况下,AP-AJCR、KNN、NMF、DeepWalk 都可以胜任工作,KNN 耗时小、精度相对较低;AP-AJCR 和NMF 方法耗时处于同一量级,但AP-AJCR 推荐效果明显优于NMF;虽然AP-AJCR 和DeepWalk 推荐质量相差不大,但AP-AJCR 相较于DeepWalk,在训练阶段可以节省90%左右的时间。
4 结语
本文提出了一种基于作者偏好的学术刊物投稿推荐算法。在实际任务中,文章的所有信息并不一定是对所有人可见的,而且这些信息的预处理操作在各种推荐算法中耗时较长,因此本文提出了一个仅适用作者、标题、发表时间和发表刊物的推荐系统。在所提出的系统中,将作者主题偏好分数(即作者对主题的偏好)和作者历史发刊记录(即作者投稿刊物偏好的变化趋势)结合起来,并产生最终的推荐。在DBLP和PubMed 上的实验结果表明,与其他算法相比,所提出的推荐算法不仅在大多数情况下足够有效,而且减少了对元数据和知识库的信息需求,但是对时间的需求较高。未来,本文将探索一种自适应的、分层的从标题中提取主题的方法,挖掘潜在的自我联系(如主题-主题、刊物-刊物),以及作者合著者之间的联系,以完善现有的推荐系统。
猜你喜欢
小学生学习指导(爆笑校园)(2022年4期)2022-05-05
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
飞天(2020年10期)2020-10-26
现代国际关系(2020年8期)2020-10-14
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
环球时报(2010-02-20)2010-02-20
环球时报(2010-02-01)2010-02-01
中学生博览(2008年1期)2008-01-09
