
基于Deeplab V3 Plus的自适应注意力机制图像分割算法
2022-02-26 06:58彭小宝朱强强殷志坚
计算机应用 2022年1期
杨 贞,彭小宝,朱强强,殷志坚
(江西科技师范大学通信与电子学院,南昌 330013)
0 相关研究
图像的语义分割在计算机视觉领域是一项具有挑战性的工作,与基于像素块分类的目标检测任务不同,它要求对图像中每个像素点进行精确分类,因此语义分割更复杂,对设备的性能要求更高。目前,图像的语义分割广泛应用于自动驾驶[1]、卫星图像分析[2]、医学图像分割[3]、物体缺陷检测[4]和精准农业[5]。
当今,图像分割技术由传统图像分割和基于深度卷积神经网络的图像分割组成。传统分割方法有边缘与阈值法[6]、图割法[7]、小波变换法[8]和主成分分析法[9]等;基于深度卷积神经网络的图像分割算法主要有全卷积网络(Fully Convolutional Network,FCN)[10]、U-net[11]、SegNet[12]、金字塔场景解析网络(Pyramid Scene Parsing Network,PSPNet)[13]及Deeplab V1&V2&V3&V3 Plus[14-17]。
Long 等[10]提出了全卷积网络(FCN)用于图像分割,其核心思想是去掉网络结构的全连接层(Fully Connected layers,FC),通过最后卷积层的特征图来完成预测,从而使得全卷积网络可预测图像中每个像素点的类别。除此之外,在图像语义分割任务中,为了获取图像的高语义信息并将特征图像恢复至原始图像尺寸大小,需要经过下采样和上采样两个步骤。图像分割通过下采样步骤获取特征图易造成图像细节信息丢失,再通过上采样重构图像内容会造成像素点之间相关性较弱的问题。针对上述问题,研究人员提出了相应的解决方案和改进方法:上下文和空间信息、改进的上采样操作和注意力机制。然而要生成高质量的特征图,上下文信息和空间信息非常重要:1)图像的上下文信息可以增强对像素属性关联性的理解;2)图像的空间信息可以增强对图像或者特征图不同通道间相互关系的理解,还可以通过像素间的空间信息去计算像素的关联性。因此,为了获取更为丰富的上下文信息,通常使用改变感受野和多尺度特征图融合的方法。Deeplab V2&V3[15-16]、密集上 采样卷 积(Dense Upsampling Convolution,DUC)[18]和判别特征网络(Discriminative Feature Network,DFN)[19]通过使用不同空洞率的卷积来获取不同感受野的上下文信息,而PSPNet[13]使用金字塔池化模型获得多个尺度的特征图,以此来获得多尺度的上下文信息。此外,为了得到丰富的图像空间信息,通常使用特征融合的方法来进一步获取图像的多尺度信息,如Deeplab V2&V3&V3 Plus[15-17]均使用空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling,ASPP)的方法去采样不同层次特征图的内容信息,并将其聚合到一起。双重注意力网络(Dual Attention Network,DANet)[20]和交叉注意力机制语义分割(Criss-Cross attention for semantic segmentation,CCNet)[21]则基于充分利用自身相似性的方法去融合低层次和高层次特征图的空间信息。
在图像的语义分割任务中,通常需要下采样获取图像的高层结构信息,然而,对图像进行下采样的操作将会使得输出的特征图尺寸小于原图像,因此,为了将特征图还原至输入图像大小,需要进行多次上采样操作。因此,上采样操作是基于卷积网络图像分割算法的重要组成部分,其中常采用的上采样操作方法有双线性插值法、反卷积法和解池化法。在全卷积网络图像分割算法中,PSPNet[13]首先使用金字塔池化策略获得多层次特征图,再利用双线性插值法进行上采样,最后得到一致尺寸的特征图以完成融合;与PSPNet 模型不同,上下文先验知识的场景分割(Context Prior for scene segmentation,CPNet)[22]对网络输出的最后一层特征图进行8 倍双线性插值完成上采样以计算分割损失,而Deeplab V3[16]同样也进行了8 倍上采样操作将特征图恢复至原始图像大小。与上述方法不同,FCN[10]使用反卷积操作,进行8倍、16 倍或32 倍的跳跃上采样操作以保证输出特征图和原始图像尺寸一致;反卷积单阶段检测器(Deconvolutional Single Shot Detector,DSSD)[23]则使用反卷积操作融合高层次特征和低层次特征,以获取图像的细节信息;堆叠反卷积网络(Stacked Deconvolutional Network,SDN)[24]通过堆叠反卷积层来丰富上下文信息完成上采样操作。与双线性插值和反卷积算法不同,SegNet[12]通过最大池化索引的解池化法将特征图进行上采样恢复。此外,反卷积网络(Deconvolution Network,DeconvNet)[25]使用反池化和反卷积相结合的方法使得稀疏的特征图逐步变得稠密,最终和原始图像尺寸保持一 致。数据依 赖上采 样(Data-dependent Upsampling,DUpsampling)[26]为了使得特征图在上采样恢复过程中像素点间有一个较好的依赖关系,提出了数据依赖型上采样的方法:首先利用相关矩阵对标签图像进行降维,使得其分辨率与特征图分辨率一致,再利用相关矩阵对特征图进行线性映射,最后恢复至原始图像大小。内容感知重组特性(Content-Aware ReAssembly of FEatures,CARAFE)[27]则提出了先将特征图增加A2通道数,之后将其对应展开并与需要上采样的特征图对应相乘,最后再将特征图恢复至原图像的分辨率。
注意力机制模块已经被广泛应用于图像分类、目标检测和跟踪任务中,均取得了较好的效果。视觉注意力循环网络模型(Recurrent Models of Visual Attention)[28]和残差注意力网络(Residual Attention Network for Image Classification)[29]均利用注意力机制生成高层次的特征图来指导网络的前向传播。挤压和 激励网 络(Squeeze-and-Excitation Networks,SENet)[30]将特征图通道压缩成一点以得到通道间的类别属性,最后通过门机制将通道关系融合到原始特征图以获得最终特征图。Encnet[31]和DFN[19]则使用通道注意力机制的方式来获取图像的全局上下文信息,以构建各类别之间的依赖关系。与此同时,自我注意力机制模型也广泛应用在图像的语义分割领域,其中文献[32]中最早提出了自我注意力机制,并利用自我注意力机制来获取输入信息的全局依赖关系,最终将其应用到了机器翻译领域。此外,自我注意力生成对抗网络(Self-Attention Generative Adversarial Networks,SAGAN)[33]引入自我注意力机制模块去学习一个更好的图像生成器,以生成效果更佳的图像。DANet[20]则采用自我注意机制和通道注意力机制分别在空间维度和通道维度上建立一个长远的上下文依赖关系。
受以上研究方法的启发,针对目前Deeplab V3 Plus 语义分割框架易造成细节信息或小目标丢失的问题。本文利用残差网络和通道注意力策略,将自适应注意力机制模块嵌入到主干网络中。此模块目的是将单元输入特征图的细节信息补充到输出特征图中,以此延缓细节信息丢失的趋势。本文提出的方法由以下四部分组成:1)使用通道压缩的方法(即全局平均池化)将单元输入特征图的每个通道压缩成一个点;2)将压缩点进行双线性插值上采样,恢复至和单元输出特征图分辨率一致;3)引入一个权重值α,将其与双线性插值恢复的图像相乘,以此达到约束注意力机制模块信息量的目的;4)将注意力机制模块的特征图与单元输出特征图在通道上进行相加(即融合后的特征图通道数量保持不变)。
1 Deeplab V3 Plus网络
Deeplab V3 Plus 是基于空洞分离卷积的编解码语义分割网络,其结构可分为下采样过程中的编码网络和上采样过程中的解码网络。其中,在编码网络中使用了空洞分离卷积,此操作既保留了输入特征图的空间信息又增大了卷积核的感受野,并且还极大减少了网络的参数量,如图1 所示。
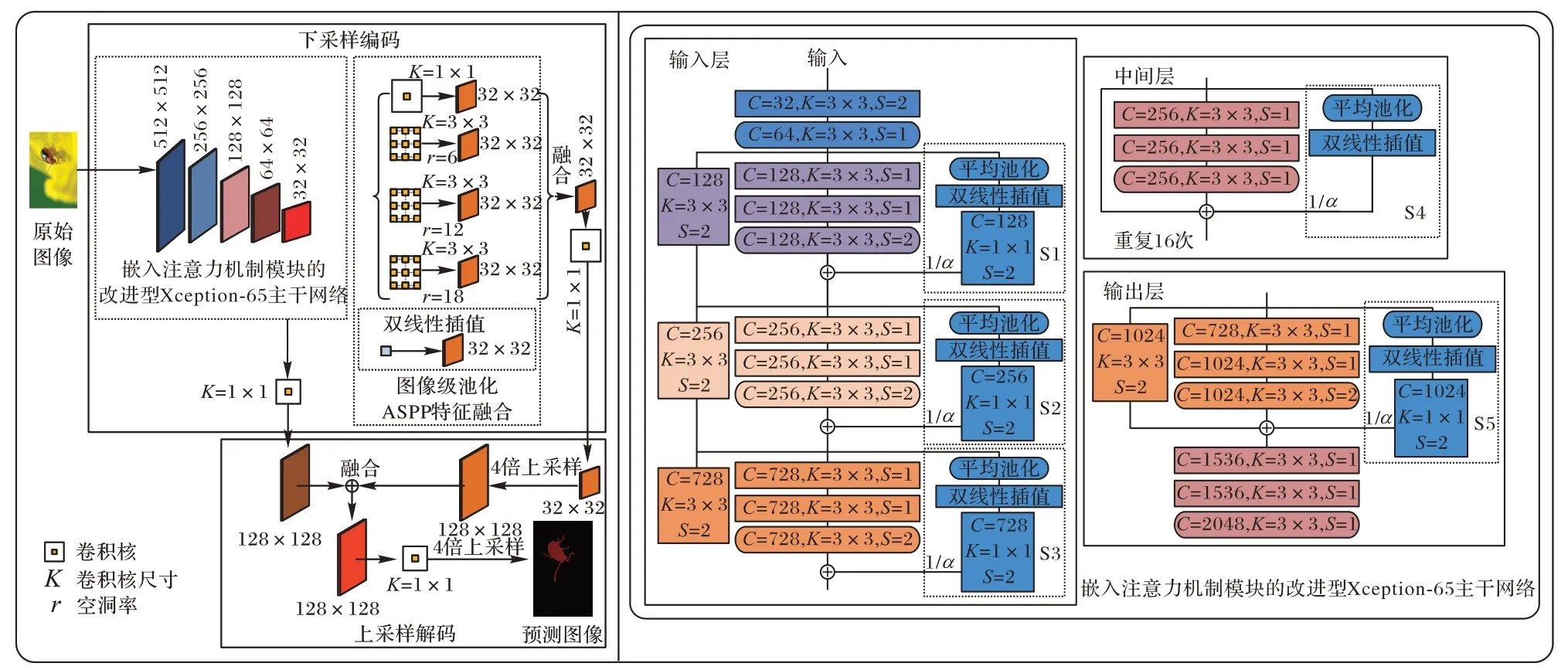
图1 嵌入自适应注意力机制模块的Deeplab V3 Plus网络结构示意图Fig.1 Structure schematic diagram of Deeplab V3 Plus network embedded with adaptive attention mechanism module
1.1 下采样编码结构
在图像语义分割中,下采样是提取图像高级语义信息的过程,在这个过程中需要将稠密的原始图像或者特征图进行稀疏采样,得到一个分辨率更低的特征图(即编码过程),而下采样通常在主干网络中完成。目前主流的主干网络有VGGNet、GoogLeNet、ResNet、Xception[34]等,而本文使用的主干网络是改进的Xception 网络。
1.1.1 改进的Xception-65主干网络
考虑设备性能,本文使用改进的Xception-65 主干网络(图1),其内部的卷积核采用的是深度可分离卷积,并且卷积核的空洞率可以自行设置。与ResNet 主干网络相比,改进的Xception-65 网络参数量更少。如图2 所示:(a)展示了普通卷积核与特征图进行卷积的过程;(b)展示了带空洞的深度可分离卷积核与特征图进行卷积的过程。假设普通卷积核与带空洞的深度可分离卷积核的尺寸大小都是K×K,输入特征图的通道数为C1,输出特征图的通道数为C2,普通卷积核与特征图卷积后产生的参数量为W1,如式(1)所示。而带空洞的深度可分离卷积核与特征图卷积后产生的参数量为W2,如式(2)所示:
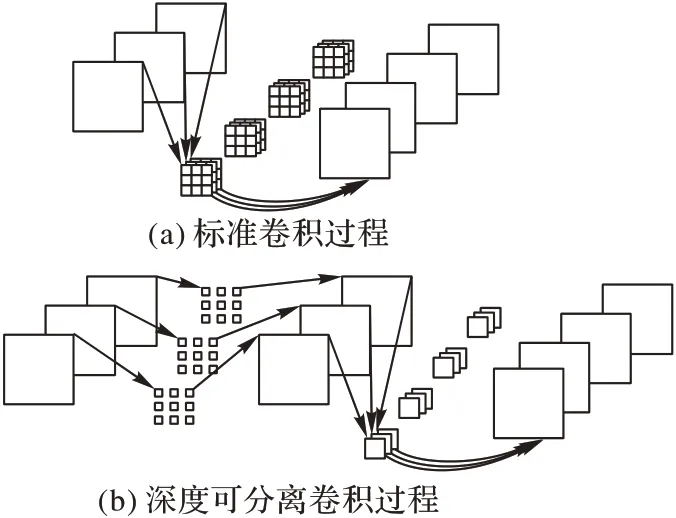
图2 标准卷积与带空洞的深度可分离卷积Fig.2 Standard convolution and atrous depthwise separable convolution
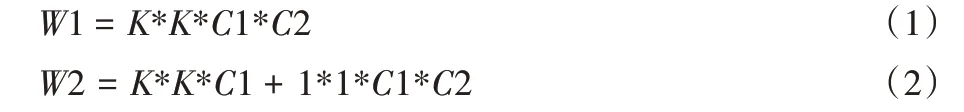
原始图像在输入改进的Xception 主干网络之前会先进行一个尺度变换操作,将原始图像通过裁剪和填补的方式全部变换为512× 512 的分辨率。变换后的原始图像进入改进的Xception-65 网络后,通过带空洞的深度可分离卷积进行4次下采样操作,之后将输出含有高级语义信息的特征图,其尺寸将变为原图的1/8。
1.1.2 ASPP特征融合
原始图像在通过改进的Xception-65 主干网络后,得到一个32× 32 高级语义特征图。为了获取不同尺度下的语义信息,本文使用空洞空间卷积池化金字塔(ASPP)(图1),并分别采用尺寸为1× 1、空洞率为0,尺寸为3× 3、空洞率为6,尺寸为3× 3、空洞率为12,尺寸为3× 3、空洞率为18 的卷积核对32× 32 高级语义特征图进行卷积,以得到4 个尺寸均为32× 32 的次级特征图。为了更进一步获得图像的全局语义信息,在ASPP 特征融合部分还采取了全局平均池化策略,先对主干网络输出的高级语义特征图进行平均池化得到1×1 的特征图,再对1× 1 的特征图进行双线性插值上采样恢复其尺寸,并得到一个32× 32 的次级特征图,最终将5 个32×32 的次级特征图在通道上进行连接融合。
1.2 上采样解码结构
原始图像在经过网络下采样编码操作后,其输出特征图为32× 32。然而,与目标检测任务不同,语义分割算法不能直接对下采样编码结构输出的32× 32 的特征图进行分类预测,而是需要将下采样获得的特征图进行上采样恢复,使得其与原始图像的分辨率保持一致。
由于上采样解码操作融合了多尺度特征图的信息,因此,本文首先使用双线性插值方法对得到的特征图(ASPP 融合的特征图)进行四倍上采样,以获得128× 128 的特征图;其次,从主干网络中提取一个128× 128 的中间特征图,此特征图相对于高层次的特征图来说包含更多的细节信息,从而能更加明确每个像素点的类别属性;最后,将两个尺寸为128× 128 的特征图进行连接融合,最终输出一个融合后的128× 128 特征图,使得其具备高层次的语义信息和低层次的细节信息。
在融合两个128× 128 的特征图之后,再进行一次双线性插值操作,完成四倍上采样,得到一个512× 512 的特征图。最后,进行逆向操作,使得预测图像和原始图像分辨率一致。
2 自适应注意力机制网络
在图像语义分割中通常需要获取图像的高级语义信息,以此加强对全图的理解,而在获取图像高级语义信息的下采样过程中难免会丢失图像的细节信息,尤其是一些小目标,其在图像中所占有的像素量少,在多次下采样过程中很容易丢失。然而,这些细节信息和小目标会存在于低层次特征图的通道中。
本文利用残差网络,结合通道压缩方法和注意力机制来构建自适应注意力机制模块,并将其嵌入改进的Xception-65主干网络中。在本文的自适应注意力机制模块中:
1)学习残差网络的结构。将单元的输入特征图经函数变换(通道压缩、上采样恢复和模块权重值学习)后与单元输出特征图进行融合。
2)通道压缩。由于单元输入特征图的不同通道中所包含的类别信息不同,因而将输入特征图在通道上进行全局平均池化处理,对应每个通道输出一个点,每个点所对应的类别信息将有所不同。
3)通道信息处理。将单元输入特征图各通道压缩成的点进行双线性插值上采样恢复,使得其分辨率与单元输出特征图的分辨率一致,此操作是为了方便自适应注意力机制模块的输出特征与单元输出特征图融合。
4)通道信息融合。为了更好约束自适应注意力机制模块的输出特征,引入一个权重值α与其相乘,α值可以通过学习来自动更新,最后将适应注意力机制模块的输出特征与单元输出特征在通道上进行相加。
基于本文构建的自适应注意力机制模块:首先,采用通道压缩的方式来获得单元输入特征图(前级特征图相对次级特征图包含的细节信息更丰富,小目标信息也更多)的通道信息,并将其融合到单元输出特征图(次级特征图),此操作减缓了细节信息和小目标在下采样过程中丢失的趋势;其次,引入权重值α(可通过学习自动更新)约束注意力机制模块,因此在与单元输出特征融合的过程中可以调节注意力机制模块的信息比重,以此达到更好的分割效果。图1 展示了嵌入自适应注意力机制模块的Xception-65 网络结构。
2.1 通道压缩
通道压缩的目的是为了获得更丰富的高层语义信息,本文引入S1、S2、S3、S4 和S5 这5 个注意力机制模块,其输入对应于上一个残差块的输出特征图:首先,对注意力机制模块的输入特征图进行一次全局平均池化处理;之后,输出一个1× 1×C的特征图,其中C为通道数,与残差块输出特征图的通道数一致,其数学表达式如式(3)所示:

其 中:gC∈RC,由大小 为H×W和通道数为C的特征 图GC(i,j)生成;(i,j)表示特征图上像素点的坐标。
2.2 通道信息处理
为了将通道信息gC∈RC融合到残差网络输出的特征图中,需要将1× 1×C的特征图与相应残差网络特征图分辨率保持一致。步骤如下:首先,对gC进行双线性插值上采样以得到和对应残差块输出特征图分辨率一致的特征图fC;之后,为了更好约束fC,需使用一个1× 1 大小的卷积核对fC进行卷积以输出特征图lC,lC和fC分辨率一致;为了约束每个注意力机制块,引入了一个参数α,最终注意力模块输出的特征为(1/α)×lC,α的值是一个超参数。
2.3 通道信息融合
本文提议在主干网络的基础上增加五个注意力机制模块(S1,S2,S3,S4,S5)(如图1 所示)。这五个注意力机制模块分布在主干网络的输入层、中间层和输出层上,因此每个注意力机制模块所获取到的通道信息表征能力也将不同。主干网络的输入层特征图细节信息更为丰富,中间层具备细节信息和高层次语义信息,输出层的特征图高级语义信息则更为丰富。因此,本文测试了多种融合策略,并探索各种融合策略对最终图像语义分割结果的影响,同时引入超参数α来平衡各个注意力机制模块。
3 实验与结果分析
在实验过程中,依托实验室现有的设备和资源,本文使用基础网络Deeplab V3 Plus 为主干架构,同时通过两种模式进一步修改了此网络:1)手动设置权重经验值;2)自动更新权重值。两种模式相互对比验证,最后在PASCAL VOC2012公共分割数据集和自己制作的植物虫害数据集上,验证本文提出的算法性能。
3.1 实验环境
实验使用的操作系统是Ubuntu16.04 版本,Tensorflow 深度学习框架,CUDA11.0 版本,硬件设备为32 GB 内存、显卡1080Ti、NVIDIA GeForce 驱动程序450.57 版本,训练Deeplab V3 Plus 网络和基于自适应注意力机制的Deeplab V3 Plus 网络进行对比验证。
3.2 实验数据
为了确保结果的真实有效性,本文使用公共分割数据集PASCAL VOC2012 和自己制作的植物虫害分割数据集完成实验。
3.2.1 公共数据集
PASCAL VOC2012[35]是深度学习中常用的一个公共数据集,包含目标检测和图像语义分割两类数据集。本文使用的是PASCAL VOC2012 语义分割数据集,此数据集总共包含2 913 张带有语义标注的图像,1 464 张作为训练集用来训练图像分割模型,其余1 449 张作为验证集用来测试模型的分割精度。
3.2.2 植物虫害数据集
植物虫害数据集图像主要通过网络爬虫获得,为了使得虫害图像满足训练和测试的要求,本文采取以下操作制作植物虫害数据集:1)人工剔除相同和相似性极高的图像,最终满足要求的图片为538 张;2)依据PASCAL VOC2012 分割数据集的格式,使用labelme 软件将538 张植物虫害图片进行语义标注;3)将图片按照约4∶1 的比例进行划分,其中438 张作为训练集,100 张作为验证集。
3.3 模型训练策略
由于设备性能的限制,在PASCAL VOC2012 和自己制作的植物虫害数据集上进行训练时,所选取的批处理(batch size)设置为2。在随机 梯度下 降(Stochastic Gradient Descent,SGD)优化算法中,动量(momentum)设置为0.9,权重衰减(weight decay)设置为0.000 04,神经元失活率(dropout rate)设置为0.5,基础学习率设置为0.001,并且使用了“poly”衰减策略,并使用基础学习率乘上,其中将PWR设置为0.9。在PASCAL VOC2012 分割数据集上训练时,最大迭代步数设置为150 000;在植物虫害数据集上训练时,最大迭代步数设置为90 000。注意力机制模块的权值为手动设置,不需要训练α;在自动更新注意力机制模块权重时,α根据损失函数的梯度进行更新。
模型训练使用像素交叉熵损失函数,其表达式如式(4)所示:

其中:c表示类别数;yi为独热编码向量,若该类别与标注类别相同则取1,否则取0;pi表示预测样本属于i的概率。
3.4 分割精度评估标准
本文采用图像语义分割中最广泛的两种评估方法:交并比(Intersection over Union,IOU)和平均 交并比(Mean Intersection over Union,MIOU),其数学表达式如式(5)和式(6)所示。

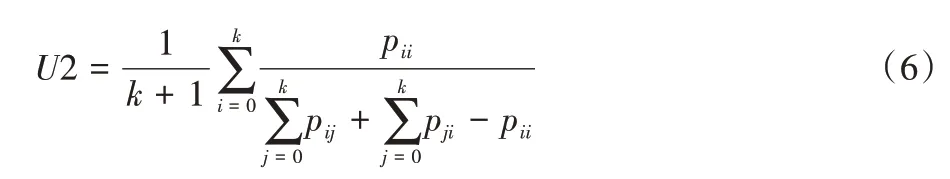
其 中:U1 表 示IOU,U2 表 示MIOU;k+1 表示类别数;TP=pii表示真正例,FP=pji表示假正例,FN=pij表示假负例;i表示正确类,j表示其他类。
3.5 自我注意力机制实验策略
为了探索注意力机制模块对原始网络框架的影响,本文在实验的第一阶段使用了一些策略来获取注意力机制模块的权值,称之为经验值,之后将经验值手动设置到注意力机制模块中;在实验的第二阶段,探索了几种注意力机制模块的融合方法;在实验的第三阶段,尝试自动更新注意力机制模块的权重值对图像语义分割结果的影响。
3.5.1 权值手动设置
本实验由三部分组成:1)初步获得一个模型可使用的经验值α;2)通过对α值进行交叉验证,获取α值对分割精度影响的趋势;3)确定α最终值。
第一步,初步获得模型可使用的α值。由于在实验的初始阶段无法得知注意力机制模块的权重值α应设置为何值。因此实验中先将α在同一个数量级上设置3 个值,随后进行模型训练。实验现象如表1 所示,α值太小会导致网络训练终止,α值设置为10 模型训练较为平稳,因此将10 定为α的初步经验值。

表1 不同α值对应模型训练的现象Tab.1 Phenomena of different α values corresponding to model training
第二步,获取α值对分割精度的影响趋势。首先将α值设置为10,训练并获得模型,随后对模型展开测试,多次改变α的值,得到不同的分割精度。实验结果如表2 所示:
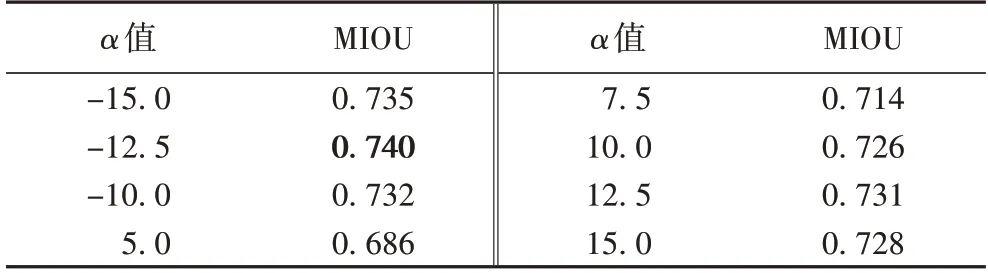
表2 测试模型时改变α的值对应的分割精度Tab.2 Segmentation accuracy corresponding to changing α value when testing model
1)α设置为正数,在α=12.5 时模型获得最高分割精度,并且以α=12.5 为中心,向两边呈递减趋势;
2)α设置为负数,在α=-12.5 时模型获得最高分割精度,并且以α=-12.5 为中心,向两边呈递减趋势;
3)根据上述1)和2)的递减趋势,将α设置为-12.5 再次训练,能获得更佳的分割模型。
第三步,确定α最终值。根据第二步中,α值对分割精度的影响趋势,α分别设置为-10、-12.5、-15,训练并验证模型。实验结果如表3 所示:1)α=-12.5 模型获得最佳分割精度;2)依然保持了以α=-12.5 为中心,向两边呈递减趋势;3)确定α=-12.5 为手动寻找到的最终值。

表3 验证不同α值对应的分割精度Tab.3 Verification of segmentation accuracy of different α values
3.5.2 注意力机制模块融合策略
为了进一步探索本文结构中各个注意力机制模块对原始网络性能的影响,本实验将经验值α设置为-12.5,同时探索了三种注意力机制模块的融合方式(图1):1)仅将输入和输出层中的S1、S2、S3、S5 融入原始网络;2)仅将中间层S4 融入原始网络;3)将所有层中的S1~S5 都融入原始网络中。在上述三种融合方式中,第一种融合方式得到的分割精度最高,这表明注意力机制模块间的融合策略也会影响网络的性能。在本实验所使用的数据为PASCAL VOC2012 公共分割数据集(实验结果如表4 所示)。
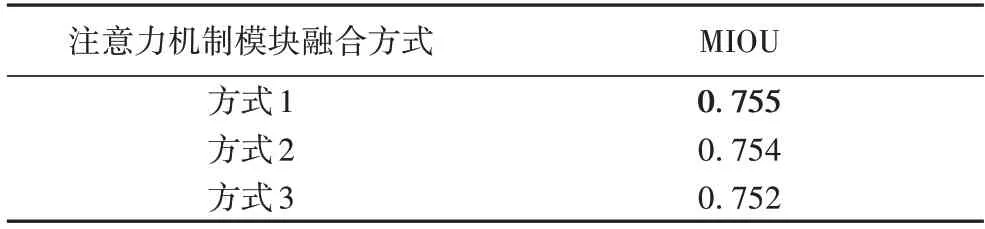
表4 三种注意力机制模块融合策略对应的分割精度Tab.4 Segmentation accuracies of three attention mechanism module fusion strategies
3.5.3 权值自动更新
在手动确定α=-12.5,并且确定最佳注意力机制模块融合方式后。将α改为根据损失函数的梯度自动更新,注意力机制模块融合方式则为:仅将输入和输出层中的S1、S2、S3、S5 融入原始网络,表5 展示了模型获得最佳分割精度的α值。图3 展示了S1、S2、S3、S5 模块α值的收敛曲线。

表5 模型最优时各注意力机制模块的α值Tab.5 α value of each attention mechanism module when model is optimal
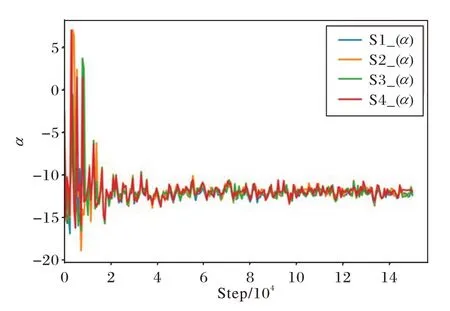
图3 S1、S2、S3、S5模块α值的收敛曲线Fig.3 Convergence curve of α value of S1,S2,S3 and S5 modules
3.6 结果分析
图4 展示了五种不同方式在训练过程中损失函数的收敛曲线。五种不同方式在VOC2012 分割数据上的分割精度如表6 所示,方式1 以原始基础网络Deeplab V3 Plus 的分割结果作为基准;方式2 仅嵌入S1、S2、S3、S5 注意力机制模块,α设置为-12.5;方式3 仅嵌入S4 注意力机制模块,α设置为-12.5;方式4 加入S1、S2、S3、S4、S5 所有的注意力机制模块,α设置为-12.5;方式5 仅嵌入S1、S2、S3、S5 注意力机制模块,α通过损失函数的梯度自动更新。图5 展示了上述五种不同方式的分割效果。
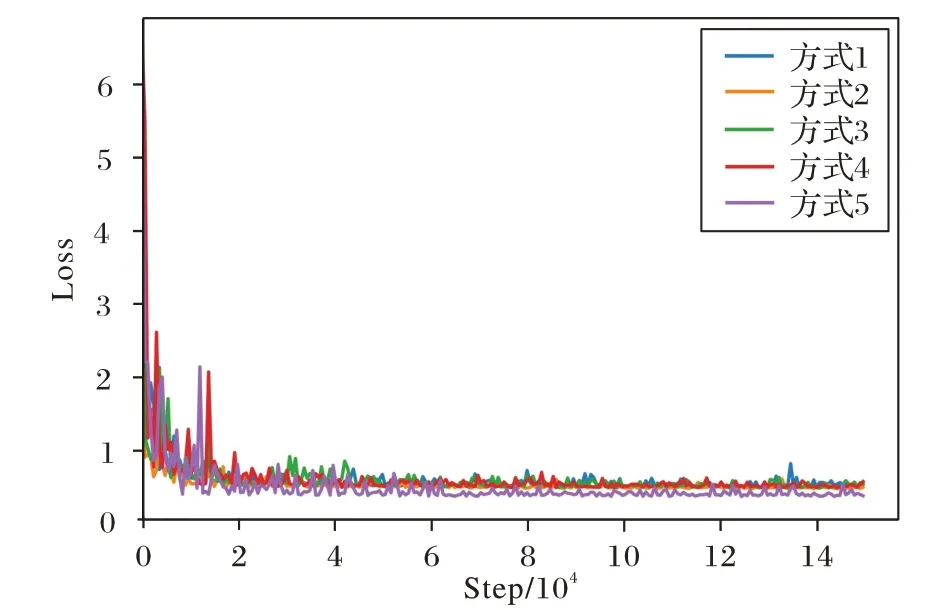
图4 五种不同方式在训练过程中损失函数的收敛曲线Fig.4 Convergence curves of loss function in training process of five different methods
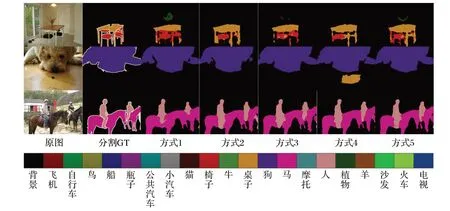
图5 五种不同方式在VOC2012分割数据集上的分割效果Fig.5 Segmentation effect of five different methods on VOC2012 segmentation dataset

表6 五种不同方式在VOC2012分割数据集上的分割精度Tab.6 Segmentation accuracies of five different methods on VOC2012 segmentation dataset
表7 展示了FCN-8S[10]、Deeplab-MSc-CRF-LargeFOV[14]、Deeplab V2[15](使用多尺度输入,并在MS-COCO 上预训练)、嵌入自适应注意力机制的Deeplab V3 Plus(即本文方法)在VOC2012 val 数据集上的实验结果对比(val 为validation 的缩写,VOC2012 val 数据集是VOC2012 数据集中的验证集)。

表7 四种不同分割网络在VOC2012 val数据集上的分割结果Tab.7 Segmentation results of four different segmentation networks on VOC2012 val dataset
表8 展示了在植物虫害数据集上的分割精度实验结果,五种不同方式的分割效果如图6所示。
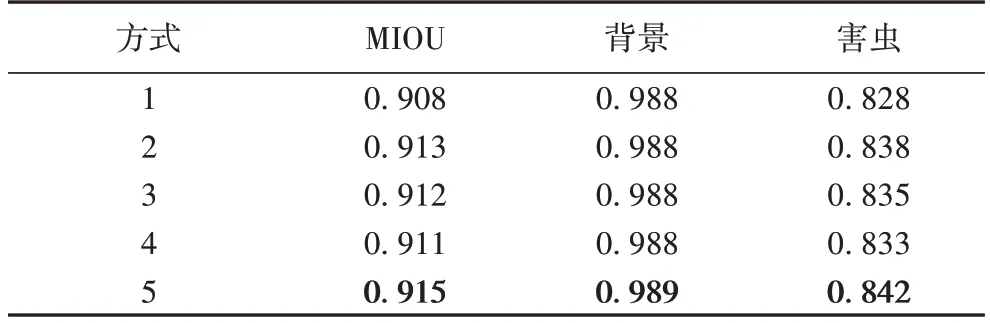
表8 五种不同方式在自建植物虫害数据集上的分割精度Tab.8 Segmentation accuracy of five different methods on self-built plant pest dataset

图6 五种不同方式在自建植物虫害数据集上的分割效果Fig.6 Segmentation effect of five different methods on self-built plant pest dataset
根据表1~6、8 的实验数据分析得出:1)注意力机制模块的引入实质是引入了信息量,这些信息量的比重不能无约束的引入,无约束的引入很有可能将导致网络在训练过程中梯度消失,无法正常训练;2)在无法获取到注意力机制模块权值较好的经验值(α)时,需要采取科学的实验方法逐步逼近较好的经验值;3)在原始网络中引入注意力机制模块时,不同模块对原始网络的影响程度不同;4)通过自动更新注意力机制模块的权重值与手动获取到的经验值对比,发现自动或手动得到的注意力机制模块权重值基本吻合,这也进一步验证了手动获取经验值方法的有效性;5)通过对比手动获取注意力机制的权重值和自动更新注意力机制的权重值,可找到模型的局部最优解,但是仍然不能确保其是模型的全局最优解;6)适量的通道信息融入原始网络可以获得较好的分割结果。
4 结语
本文制作了植物虫害数据集,并探索了将注意力机制模块引入Deeplab V3 Plus 结构中,以期获得较好的图像语义分割结果。实验结果表明,在PASCAL VOC2012 和制作的植物虫害数据集上,本文的方法均获得了图像分割精度的提升。但本文方法存在两个不足:第一,对于网络中各通道信息的处理还不够细化,后续可深入探索通道的具体关系,在此基础上分配相应权重系数进行约束;第二,植物虫害数据集较为单一,数据量较少,后续可进一步扩充数据集。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2015年1期)2015-02-27
中学英语之友·高一版(2008年10期)2008-12-11
