
基于前缀分组的改进自适应多叉树防碰撞算法
2022-03-01 01:14白乐强曹科研
计算机仿真 2022年1期
白乐强,刘 杰,曹科研
(沈阳建筑大学信息与控制工程学院,辽宁 沈阳 110168)
1 引言
智能化科技的点滴进步,都将带领社会生产力的显著提升。随着大数据开发、自然语言处理、图形图像处理、“互联网+”等一系列尖端技术的日益成熟,一个万物相息、互联互通的时代即将到来。无线射频识别(RFID)技术作为物联网产业的中流砥柱,发挥着不可替代的作用。RFID系统[1]主要由阅读器和标签组成,两者通过无线电波传递处理数据。标签与阅读器内部各嵌入一个天线,当两天线靠近时会产生电磁场,标签从电磁场中获得能量,将自身ID等数据通过天线发送给阅读器。然而,当多个标签同时发送数据给阅读器时,会导致通信信道堵塞,阅读器无法正常接收标签数据并对其执行读写操作,这就是标签碰撞[2]。
目前主要存在三类RFID标签防碰撞算法:ALOHA非确定性防碰撞算法、树型确定性防碰撞算法、混合防碰撞算法[3]。经典防碰撞算法识别效率不高,国内外研究人员在经典算法基础上提出诸多优异的防碰撞算法。丁治国等人提出一种自适应多叉树防碰撞(AMS)算法[4],AMS算法能够计算碰撞因子,预测时隙内的标签数量,动态调整分裂叉树,将系统吞吐量提升至0.545。Su Jian等人提出一种基于空闲时隙消除的RFID二叉分裂防碰撞(ISE-BS)算法[5],该算法通过引进1bit随机数Q值和16bit随机数序列标识符(SID)协助标签分裂,Q值在数据交换之前传输,可以提示阅读器是否发生标签碰撞,从而减少不必要的数据交换。王汉武等人在AMS算法基础上进行优化并提出一种改进的自适应多叉树防碰撞(IACT)算法[6],算法了将四叉查询树中的空闲时隙全部消除,大大降低了通信开销。李川等人提出一种双查询前缀匹配的防碰撞(DPPS)算法[7]来提高RFID系统的识别效率,标签接收指令过后若与第一个查询前缀匹配则,立即传输剩余ID号给阅读器,否则延迟r个(r为完整ID长度减去查询前缀长度)比特时间响应,以此消除空闲时隙和减少碰撞时隙。
本文针对AMS算法中识别周期长、碰撞时隙多等缺点,提出一种基于前缀分组的改进自适应多叉树防碰撞(PGAMT)算法。在标签识别过程中,曼彻斯特编码可以准确判断标签碰撞位,从而将查询树切割成若干分支,标签识别在各分支内进行;识别过程中采用改进自适应多叉树防碰撞算法查询,根据碰撞因子动态调整树的分裂叉树,从而有效减少总时隙数,加快识别速度提高系统吞吐量。
2 算法思想
基于前缀分组的自适应多叉树防碰撞算法将标签识别过程抽象成一颗庞大的四-二叉树,树的分支节点为识别过程中的碰撞时隙,树的叶子节点为识别时隙。采用标签前缀分组方法,将查询树分割成若干分支,各分支互不干扰,以此缩减数据发生碰撞的概率。通过计算碰撞因子动态选择树的分裂叉树,若标签在四叉树部分响应,则采用消除空闲时隙的动态四叉树算法,若标签在二叉树部分响应,则采用碰撞跟踪树(CTT)算法[8]。若该分支内存在的标签被全部识别,则算法开始识别下一分支,直至标签全部被识别。
2.1 前缀分组
阅读器需要使用一个查询周期确定范围内标签的前缀,并把查询前缀压入栈中。具体操作流程为:阅读器选择最优的标签分组的前缀长度为,设为K比特,之后发送分组指令REQUEST(1…10…0),其中比特1的个数为K,剩余比特为0,总位数为标签ID长度。标签接收到分组指令后将自身ID中的前K位转换成十进制数S,并回送给阅读器一个长度为2K比特的数据,其中从右往左第S位为1,剩余位均为0。阅读器接收到标签的回送信息后,利用曼彻斯特编码判断标签的碰撞位置,再将十进制数表示的碰撞位置转换成对应的二进制数,通过此操作可以得到区域内所有标签的前K位查询前缀,并把查询前缀压入堆栈。
假设阅读器工作区域有6个标签待识别,其ID分别为:Tag1(00011111)、Tag2(00100011)、Tag3(00101010)、Tag4(10010000)、Tag5(10001111)、Tag6(11001100)。假设分组前缀长度为K,前缀分组阶段标签回复阅读器的比特位要少于标签ID长度,即需要2K≤8,K≤3,为使防碰撞算发性能达到最大化,K取3,前缀确定表1如下。

表1 前缀确定表
根据阅读器接收到的数据可知标签ID第0、1、4、6位碰撞,将其转换成二进制000、001、100、110并压入堆栈,之后的标签查询操作都是在这四个分支下进行。
2.2 改进自适应多叉树防碰撞算法
曼彻斯特编码是控制数据流传输的一种编码方式,每位编码都会发生跳变。当标签传输给阅读器的数据既包含比特1又包含比特0时,此位编码相互抵消,数据流不会发生跳变,能够推断出此位发生了碰撞。丁治国等人利用此特性提出了一种自适应多叉树防碰撞算法,该算法通过计算碰撞因子μ

(1)
动态调整树的分裂叉树,当μ≥0.75,标签数目较多选择动态四叉查询树识别,反之选择动态二叉查询树识别,其中,nc代表碰撞比特,n代表响应比特。自适应多叉树防碰撞算法在一定程度上减少了空闲时隙产生,提高了识别效率,但是并没有完全消除空闲时隙,并存在较多的碰撞时隙,导致系统吞吐量在0.5~0.6左右。
基于前缀分组的改进自适应多叉树防碰撞算法对自适应多叉树防碰撞算法中的动态查询部分进行了改进。阅读器给周边标签发送查询指令REQUEST(q1,q2,…,qu),只有查询前缀完全匹配的标签作出回应并将自身除查询前缀之外的剩余位传输,阅读器接收到标签传送的剩余位信息后判断μ值:
1) 若μ≥0.75时,采用无空闲时隙动态四叉查询树算法,响应标签接收到阅读器查询指令后检测自己的ID最高两位碰撞位是否连续,若连续,则根据二-十进制代码发送信号,阅读器接收信号后利用曼彻斯特编码解码并将查询前缀进栈;若不连续,则采用碰撞跟踪树算法查询,首先利用曼彻斯特编码的特性,得到所有回复标签中的正确位和碰撞位位置,阅读器将首位碰撞位设置为0和1,之后将首碰位撞位之前的正确位同首碰撞位压入堆栈中。

表2 二-十进制代码
例如,对于查询前缀q1q2…qu,如果收到的响应为r1r2…rc-1rc,其中,qi,ri∈{0,1},rc是首位碰撞位,之后阅读器扩展新的查询前缀,即:q1q2…qur1r2…rc-10和q1q2…qur1r2…rc-11。
2) 若μ<0.75,表明此分支中存在较少数目的标签,则采用碰撞跟踪树算法查询。
2.3 算法流程
步骤1:阅读器向范围内的标签发送一个长度等于标签ID长度的前缀分组指令,指令格式为REQUEST(1…10…0),其中比特1的个数为K,剩余比特均为0。
步骤2:若阅读器工作区域内没有标签待识别则转至步骤1,否则待识别标签回送给阅读器一个长度为2K比特的数据,其具体比特位按照前缀分组原则设置。
步骤3:阅读器利用曼彻斯特编码可以准确检测碰撞位的特性,对标签回送的数据进行处理,即将十进制代表的碰撞位置转换成二进制序列并压入堆栈S。
步骤4:从堆栈S中弹出栈顶元素,阅读器广播查询指令REQUEST(q1q2…qu),与查询前缀q1q2…qu匹配的标签将除查询前缀外的剩余ID发送。
步骤5:阅读器利用曼彻斯特编码判断响应标签的数目:
步骤5.1:如果有唯一标签响应,该时隙为识别时隙,与该标签进行数据交换。
步骤5.2:如果有多个标签同时响应,该时隙为碰撞时隙,阅读器判断碰撞位个数,如果碰撞位只有一位,则在标签中该位非0即1,阅读器无需发送信息即可同时识别这两个标签;如果碰撞位个数大于1,则通过计算碰撞因子μ,按照改进自适应多叉树防碰撞算法查询标签。
步骤6:判断栈S是否为空,若栈S不为空,则转至步骤4,继续识别标签;若栈S为空,则表明阅读器范围内的所有标签已被成功识别,算法结束。
3 理论分析
在RFID系统中,评价一个防碰撞算法好坏的重要指标有2个:总时隙数和系统吞吐量。
3.1 总时隙数
PGAMT算法将标签查询过程划分为前缀分组和标签识别这两个阶段。假设标签ID编码长度为96位,前缀分组长度为K比特,最多产生2K种查询前缀,由于前缀分组阶段标签回复阅读器的比特位要少于标签ID长度,即2K≤96,K≤6。在前缀分组阶段,阅读器可以使用一次查询确定通信范围内标签前K比特的查询前缀,在标签识别阶段,阅读器需要对组内标签逐一识别。
假设待识别标签数量为N,标签ID均匀分布,理想状况下,前缀分组能将标签平均分为t组(1≤t≤2K),每组内约有n=(N/t)个标签。对其中一个分组分析,当碰撞因子μ<0.75时,采用二叉碰撞跟踪树查询标签,反之采用消除空闲时隙的动态四叉树查询标签。阅读器查询标签的结果仅有碰撞时隙(分支节点)和识别时隙(叶子节点)两种,当阅读器对标签查询时可以抽象为对一棵二-四叉树执行遍历操作,由于本算法消除了空闲时隙,则分支节点仅有度为2和4两种节点。
根据自适应多叉树防碰撞算法分析,若树的搜索深度为h,树的平均子节点为3,当搜索深度小于h时,采用四叉树查询,反之采用二叉树查询,搜索深度h=⎣log4(n/3)」。因此,自适应多叉树防碰撞算法的总时隙数TAMS为两部分时隙数相加
TAMS=T2-ary+T4-ary
(2)
当搜索深度小于h层,没有消除空闲时隙的四叉查询时隙数T4-ary为

(3)
当搜索深度大于h层,二叉查询时隙数T2-ary为

(4)
为了计算消除空闲时隙的四叉查询总时隙数,接下来计算四叉查询树的空闲时隙概率。根据数据结构中完全多叉树的性质:一棵完全四叉树,第L层中有4L个节点(层数L等同于深度h)。假设待识别标签有n个,其中有m个标签相应在同一个节点的概率服从二项分布[9]
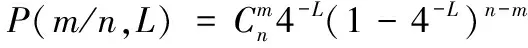
(5)
空闲时隙出现的概率为
P(0/m,L)=(1-4-L)n
(6)
四叉树中可能产生的空闲时隙数目为四叉查询总时隙数T4-ary与空闲时隙出现的概率之积[10]:
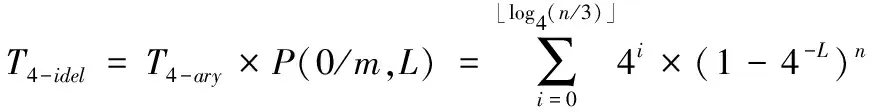
(7)
PGAMT算法在识别过程中若遇到碰撞位只有一个的情况只需一次查询就能同时识别两个标签,假设在组内四叉树部分这样的节点数为u个,二叉树部分这样的节点数为v个,则此算法识别一个小分支内需要阅读器的查询次数为
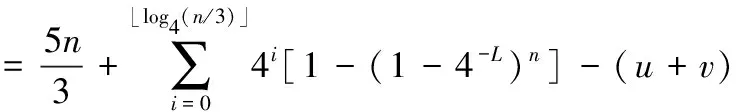
(8)
PGAMT算法总时隙数为前缀分组阶段的一次查询加上各小组内时隙数之和
TPGAMT=t(T2-ary+T4-ary-T4-idel-u-v)+1

(9)
3.2 系统吞吐量
系统吞吐量即识别时隙与总时隙之比[11],对于待识别标签N,识别时隙为N,其系统吞吐量SPGAMT为
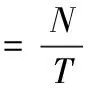
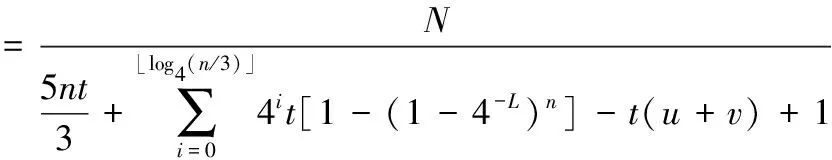
(10)
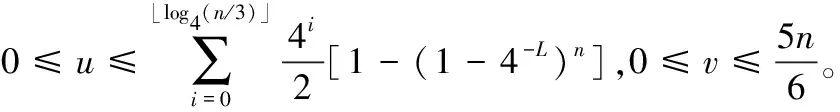
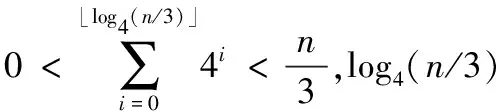
4 仿真研究
本文以MATLAB2018a为仿真平台对PGAMT算法进行仿真分析,遵循EPCglobal编码标准,阅读器工作区域内的标签数量取值为100~1000,标签ID均匀分布,固定为96bit长度,仿真50次取平均值。图1、图2表示PGAMT算法与AMS算法、ISE-BS算法、IACT算法在碰撞时隙数、总时隙数和系统吞吐量三个方面的比较。
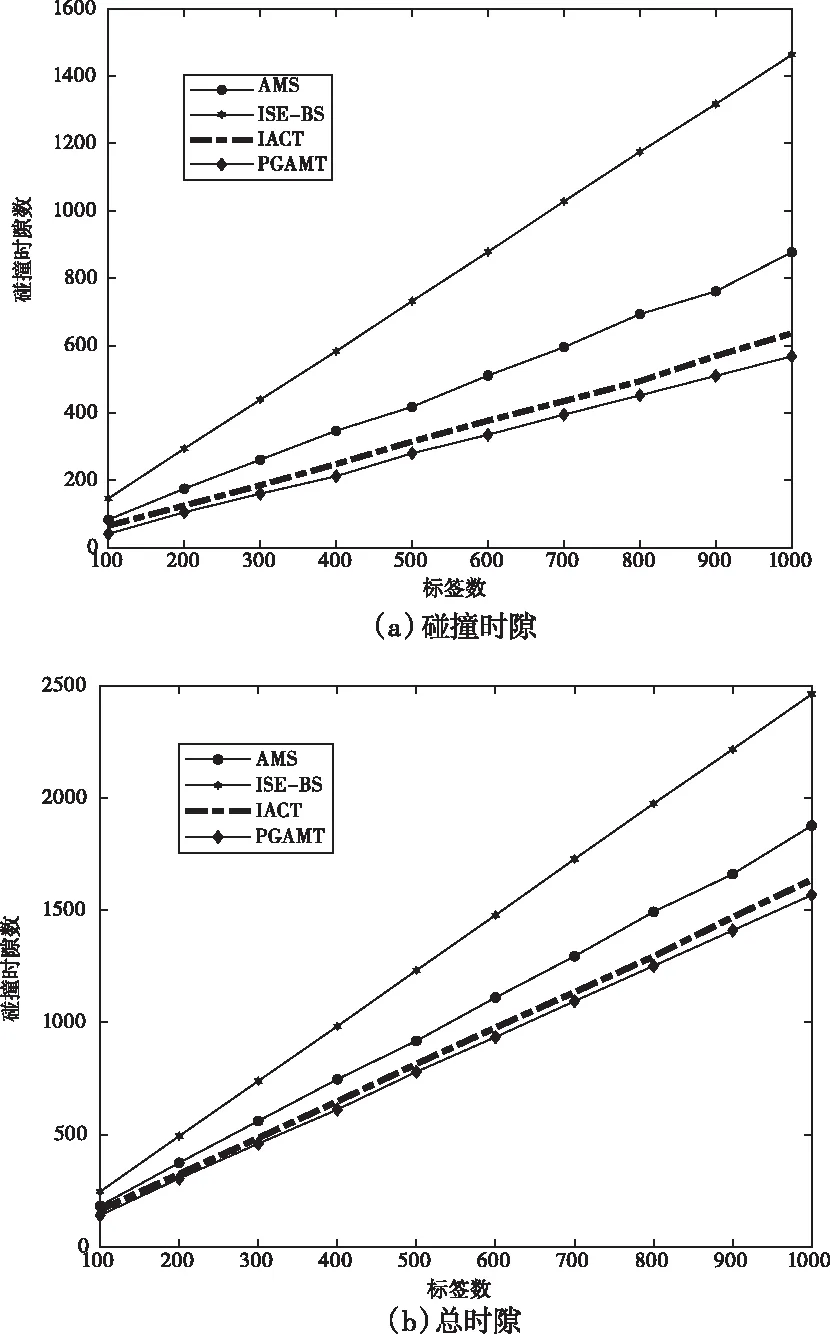
图1 四种算法的性能比较

图2 吞吐量
图1表示PGAMT算法与其它三种算法碰撞时隙和总时隙之间的比较。PGAMT算法消除了AMS算法中存在较多空闲时隙的问题,当识别过程中只有一位碰撞位,则阅读器不用继续搜索即可同时识别两个标签,以此消减了部分碰撞时隙。从图1可以看出,PGAMT算法性能明显优于ISE-BS算法和AMS算法,随着标签数量增多,PGAMT算法与IACT算法的差距也在逐渐拉大。在标签数量达到1000时,ISE-BS算法识别所有标签需要2463个时隙,AMS算法需要1877个时隙,IACT算法要1636个时隙,而PGAMT算法需要1568个时隙。结果表明,在标签数量较多时,PGAMT算法优势明显。
图2表示PGAMT算法与其它三种算法系统吞吐量之间的比较。从图中可以看出,PGAMT算法吞吐量明显高于其它三种算法,最高达到0.709,随着标签数量的增加,PGAMT算法吞吐量稳定于0.641。IACT算法最高只有0.618,稳定于0.613,AMS算法和ISE-BS算法吞吐量仅有0.535和0.405。结果表明,PGAMT算法虽然波动幅度较大,但吞吐量明显高于其它防碰撞算法。
5 总结
本文针对自适应多叉树防碰撞算法存在查询周期长,系统识别效率低等缺点,提出一种基于前缀分组的改进自适应多叉树防碰撞算法。在前缀分组阶段,将一棵复杂的多叉查询树切割,以此减少碰撞时隙的产生,提高系统吞吐量。在标签识别阶段,通过计算碰撞因子,预测标签数量,动态选择分裂叉树,在标签数量较少的分支采用跟踪碰撞树算法,在标签数量较多的分支采用无空闲时隙的动态四叉树算法。理论分析和仿真证明该算法标签识别全程没有产生空闲时隙,大幅度提高了系统吞吐量和查询速度,在庞大的物联网产业中,具有一定的实用价值。
猜你喜欢
数字技术与应用(2022年7期)2022-08-03
英语世界(2020年10期)2020-11-06
英语世界(2020年2期)2020-03-08
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
科学与技术(2018年23期)2018-06-17
意林·少年版(2018年1期)2018-02-07
中国新通信(2016年4期)2016-03-24
CHIP新电脑(2016年3期)2016-03-10
山东工业技术(2016年5期)2016-03-04
