
基于改进Slope One的大数据智能化推荐研究
2022-03-01 01:14徐永华雷东升
计算机仿真 2022年1期
徐永华,雷东升
(1. 金陵科技学院计算机工程学院,江苏 南京 211169;2. 北京工业大学,北京 100124)
1 引言
互联网与云计算时代将网络用户的需求由资源获取转向为兴趣资源获取。在飞速发展的网络时代中,对不同用户的学习、工作、生活等方面均有着重要提取作用的推荐技术[1]应运而生,其凭借自身的高效优势,广泛应用于电影、社交等自媒体领域中。推荐算法[2]作为技术核心,决定着推荐技术的应用性与适用性,并已经成为近几年的热点研究课题之一。
基于上述背景,文献[3]根据五免费午餐定理与rice算法,选取推荐系统结构,根据问题特征与算法性能间的相关性,转化推荐问题为多分类问题,引用多分类支持向量机算法完成智能推荐;文献[4]利用软命题逻辑、软决策规则以及软真度等,完成逻辑语义解释、决策信息系统转换以及决策规则评价,得到一种智能推荐算法。
但是尽管文献方法已被普及使用,但随着高新技术与算法的不断提出,推荐方法性能要求也在逐渐提升。因此,本文通过改进Slope One算法,提出大数据智能化推荐方法。结合使用者与项目相似度的度量策略,抑制使用者评分预测过程中非相似项目造成的干扰,以及使用者之间的影响,增加预测精准度;通过进一步划分使用者属性特征类别,使评分更有参考价值,推荐结果更具客观性。
2 Slope One算法
作为基于使用者评分的Slope One算法,一般情况下,可通过下列一元线性回归模型来预测评分
F(u)=u+b
(1)
式中,使用者为u,代数项矩阵的偏差均值为b。让使用者w、x、y、z给两个项目分别打分,得到表1所示的不同使用者评分矩阵。
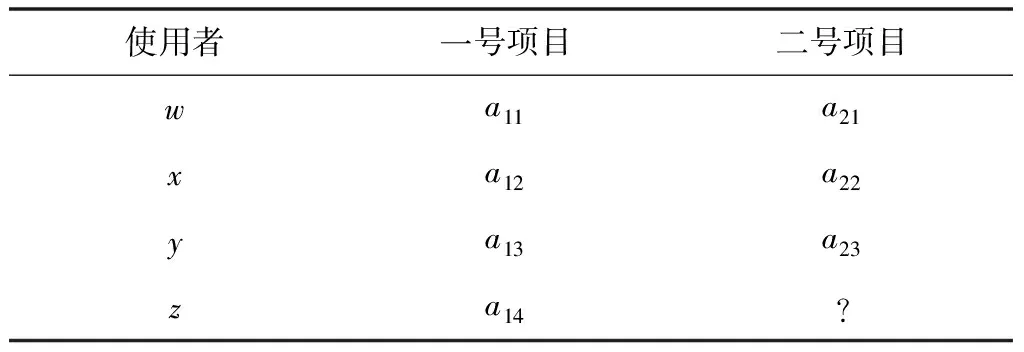
表1 基于各项目的不同使用者评分矩阵
因此,使用SlopeOne算法的一元线性回归模型式(1),预测二号项目的使用者z打分结果,如下所示:

(2)
当目标使用者和其他使用者存在一致评分或者两者一并给出同一项目的评分时,SlopeOne算法才能达成预测目的。
假设训练集合为χ,i、j,分别表示待评分的项目,对两项目给出过评分的使用者集合为Si,j(χ),有card(Si,j(χ))个使用者对两项目一并给出过评分,则采用下列计算公式求解Slope One算法偏差

(3)
若与项目j一并给出评分的项目集为Rj,因此关于项目j的使用者u评分预测表达式为

(4)
由于SlopeOne算法只面向项目的使用者评分均差求解,缺乏项目的重要性考量,因此,通过在SlopeOne算法中赋予各项目权值,得到一种加权SlopeOne算法,并将其作为改进的基本算法,以用于完成大数据智能化推荐任务。该算法的项目偏差权值为一并对两项目给出过评分的使用者个数,若j是待预测的目标项目,则下式即为加权SlopeOne算法下目标使用者u对该项目的预测评分

(5)
3 改进Slope One算法
当使用者评分矩阵中使用者x与使用者y的偏好存在差异较大时,根据使用者x的打分结果去预测使用者y,会大幅降低预测精准度,因此,基于上述SlopeOne算法,结合使用者与项目相似度的度量策略,提出一种SlopeOne优化算法,以抑制使用者评分预测过程中非相似项目造成的干扰,以及使用者之间的影响。
3.1 基于使用者相似度的Slope One优化算法
从使用者角度出发,构建一种信任机制[5]的SlopeOne优化算法,度量各个使用者之间的相似性。当推荐系统中的信任相关性显著时,网络传播将助推使用者间信任相关性的延伸,若使用者ue对使用者uf具有信任显著,使用者uf对使用者ug具有信任显著,则即使使用者ue与使用者ug间无明显信任相关性,依然存在一定的信任相关性。假设使用者ue与uf明显信任的相关性及其最短间距分别为tueuf、d,因此推导出信任值的计算公式,如下所示:

(6)
信任值t′ueuf取值范围为[0,1],1与0分别描述两使用者间信任相关性的有与无。随着明显信任最短间距d的增加,内耗、噪声以及误差不断升高,因此,以简化运算流程、减少内耗为目标,将间距d限制在3以下。
综上所述,为求解项目i、j之间的误差,改写偏差计算式(3)为下列表达式
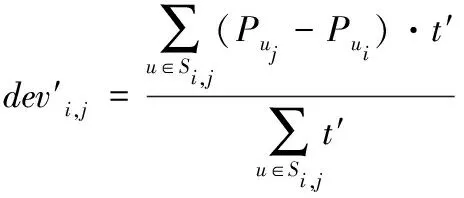
(7)
根据上式解得的项目i、j误差值dev′i,j,结合加权SlopeOne算法式(5)解得的预测评分结果P′u,j,获取基于使用者相似度的预测评分。
3.2 基于项目相似度的Slope One优化算法

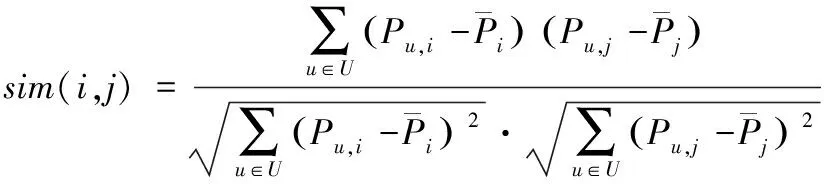
(8)
该相似度sim(i,j)的取值范围为sim(i,j)∈[-1,1],在不同取值区间中,项目i、j存在不同的相关性,如下列条件方程式所示

(9)
由此可知,当项目i、j存在正比关系时,sim(i,j)趋近于1,相似性较大;当关系是反比关系时,sim(i,j)趋近于-1,相似性较小;当两者不相关时,无相似关系。
综上所述,基于项目相似度,用户u对项目j的预测评分结果如下所示

(10)
根据上式解得的预测评分,结合下列加权Slope One算法解得的项目误差结果dev″i,j,获取项目相似度的最终预测评分

(11)
式中,使用者集Si,j的人数为|Si,j|。
4 改进Slope One算法下大数据智能化推荐
为提升智能化推荐结果的精准性,融合使用者相似度SlopeOne算法与项目相似度SlopeOne算法的预测结果,通过进一步划分使用者属性特征类别,使评分更有参考价值,推荐更具客观性。
引用蚁群聚类算法[7],划分使用者特征类别,步骤如下
1)对于|Si,j|个使用者,设定各年龄段中的任意使用者为初始簇中心Cu;
2)对比各簇中心的使用者与其他使用者,求解使用者间距,完成簇划分。假设使用者ue与uf的年龄、性别以及职业等属性特征相似度分别是simH(e,f)、simX(e,f)以及simO(e,f),则基于属性特征相似度simu(e,f)的计算公式如下所示:
simu(e,f)=αsimH(e,f)+βsimX(e,f)
+(1-α-β)simO(e,f)
(12)
式中,α、β取值范围均为[0,1],用于调整综合相似度中各特征的干扰度。
关于性别属性特征值,假设使用者ue与uf的性别分别为Xue、Xuf,则性别属性相似度simX(e,f)的计算公式如下所示

(13)
关于年龄属性特征值,以不同年龄段的使用者为年龄相似度的整体运算对象,设定完全相似值为年龄差不大于5,若使用者ue与uf的年龄分别为Hue、Huf,则年龄属性相似度simH(e,f)的计算公式如下所示
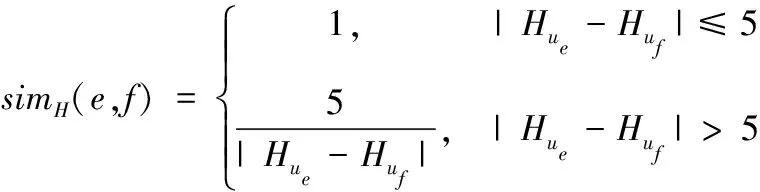
(14)
关于职业属性特征值,设定使用者ue与uf的职业分别为Oue、Ouf,则职业属性相似度simO(e,f)的计算公式如下所示

(15)
3)设定新的簇中心为最近似于簇中心的使用者,按照以下步骤完成簇中心更新,返回第步骤2)进行循环计算:
①求解各类别中全部使用者的平均年龄;
②获取各类别中使用者性别与职业数的极大值;
③将类别的当前簇中心设为平均年龄、性别与职业极大值;
④求解年龄、性别以及职业等属性特征下当前簇中心与类别内全部用户的相似性;
⑤新簇中心即为与当前簇中心具有最小欧几里得距离[8]的使用者。
4)在分类完全全部使用者后,取得使用者类簇。
结合使用者属性相似度simu(e,f)与使用者相似度的预测评分,得到下列基于使用者的综合相似度界定公式
simnew_u(e,f)=μsimPu(e,f)+(1-μ)simu(e,f)
(16)
式中,μ为修正系数[9],负责修正两相似度的互相干扰力度。
综上所述,推导出充分考虑了项目、使用者及其属性的预测评分公式,如下所示
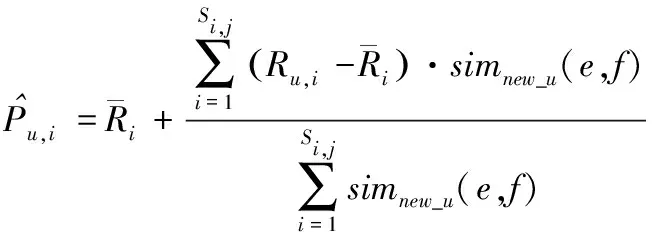
(17)
根据所得预测评分值,与预设评分阈值作对比,若预测分值比阈值大,则该分值对应的数据即为大数据智能化推荐结果,将其推荐给相应使用者。
5 仿真设计与分析
5.1 仿真准备阶段
仿真环节选取Epinions与FilmTrust两个数据集[10],前者包含项目的辅助数据,个数增幅比使用者个数增幅大,而后者则在预处理之后,有关噪声已被去除,得到的文本元素均呈小写形式。表2与表3所示分别为两数据集与实验环境相关参数。
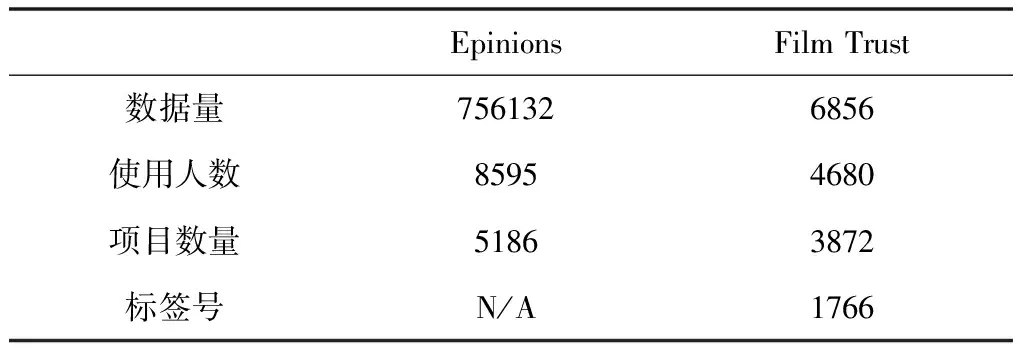
表2 数据集相关参数

表3 实验环境相关参数
为客观评价本文方法的评分与推荐性能,分别采用均方根误差、平均绝对误差以及归一化折现累计收益等指标进行量化评估,计算公式分别如下所示

(18)
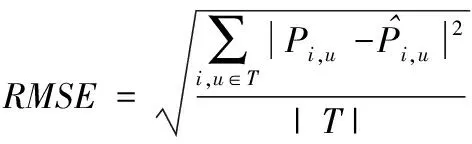
(19)

(20)
式中,T为待预测评分的集合,i,u与Pi,u分别为预测评分结果与实际评分结果,Zk为归一化折现累计收益指标的标准化因子,Pφ为推荐列表中项目i所在位置φ的对应分数。
按一定比例划分Epinions与Film Trust两个数据集,利用五折线交叉验证方法展开多次仿真,求取各指标结果均值后,将其与文献方法进行对比,检验方法有效性。
5.2 均方根误差对比
图1所示为文献方法与本文方法对Epinions与Film Trust两数据集分别给出推荐的均方根误差指标评估结果。由此可以看出,本文方法对比文献方法的推荐均方根误差更小,且Epinions数据集的推荐结果更能满足使用者需求。这是因为从使用者角度出发,构建了信任机制Slope One优化算法,度量了各使用者间的相似性。

图1 均方根误差对比图
5.3 平均绝对误差对比
两数据集在不同推荐方法下的平均绝对误差结果如图2所示。根据图中对比情况可以看出,相较于文献方法,本文方法的平均绝对误差值大幅下降,说明该方法能够相对理想地将目标项目针对性地推荐给使用者。究其原因是针对智能化推荐项目,引入了皮尔森相关系数来改进加权Slope One算法,度量了各项目间的相似程度。

图2 平均绝对误差对比图
5.4 归一化折现累计收益效果对比
经各方法对两数据集展开推荐后,得到图3所示的归一化折现累计收益指标评价结果。通过数值对比可知,相对文献方法,本文方法因融合了使用者相似度Slope One算法与项目相似度Slope One算法的预测结果,并对用户特征类别做了进一步划分,因此指标评估水平始终处于较高标准。
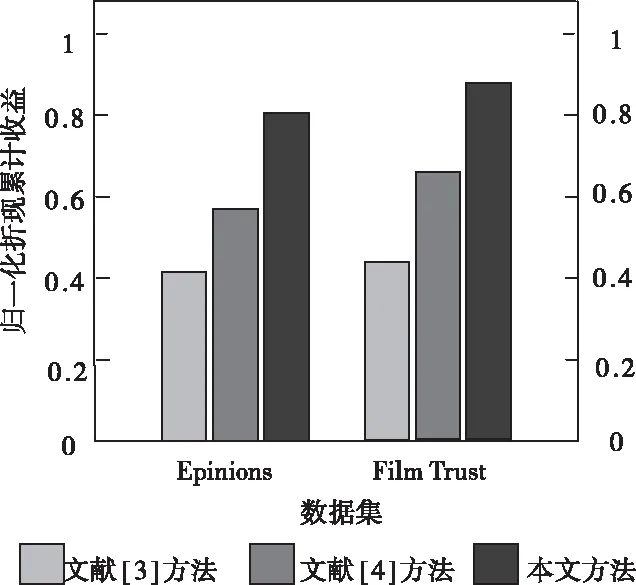
图3 归一化折现累计收益对比图
6 结论
大数据推荐技术为帮助使用者在大规模数据中探索到有用信息提供了一种有效途径。本文构建的大数据智能化推荐方法具有高精度的推荐性能,但仍需针对以下弊端加以改进:根据使用者兴趣与时间的负相关性关系,将使用者兴趣迁移问题作为方法的变量指标,完善推荐性能;下一阶段应针对离线运算能力做深入探究;应尝试结合更新型的推荐技术与算法,研究出推荐更优、运算更快的方法;使用者不同的行为特征也存在一定的隐藏信息,将行为特征考虑在内,有助于提升推荐精准度;在今后的研究中,需编程实现推荐的代码,令方法更高效地运行。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
工业设计(2022年4期)2022-05-17
中国药学药品知识仓库(2021年18期)2021-02-28
好日子(2018年5期)2018-05-30
足球周刊(2017年27期)2018-04-16
桃之夭夭B(2017年2期)2017-02-24
中国新闻周刊(2016年33期)2016-10-27
足球周刊(2016年13期)2016-10-18
高中生·青春励志(2014年11期)2014-11-25
学苑创造·A版(2009年10期)2009-12-09
