
基于距离和的孤立点检测在质量大数据分析中的应用
2022-03-01 08:41王显贵陈祖汉田留胜
装备制造技术 2022年12期
王显贵,陈祖汉,田留胜
(柳州五菱汽车工业有限公司信息部,广西 柳州 545007)
0 引言
在高等数学的数据集里经常存在一些数据对象,它们不符合数据的一般规律或者数据模型,这样的数据也就成为孤立点(outlier),比如一家公司CEO 的薪酬收入,自然远高于公司内其他雇员的收入,这就是孤立点的最直接的一种感官概念。
多年以来,为了监测产品工艺过程和优化产品质量,企业中部署的各类质量信息管理系统积累了巨大而复杂的质量数据,随着硬件和数据挖掘算法的迭代,对大量数据信息的管理和处理成为了可能。数据挖掘技术是通过算法搜索隐藏于大量的数据中有价值信息的过程。数据挖掘通常通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来价值模式发掘,非常适合用来作为分析质量信息的工具,通过挖掘质量管理信息系统(QMS)中存在的各种控制模型,企业质量知识发现系统和产品质量评价决策系统就建立起来了,将有效解决专家决策系统中的知识瓶颈问题。在当下,零部件制造行业面临着产品交付周期短,节拍快,批量少的大环境挑战,传统的质量检验分析工具正越来越跟不上这种节奏,在逐步提高检验水平,引入更多数字化质量检验监测装备的同时,也需要同步建设对应的结果分析平台,才能将得到的监测数字进行快速的分析,保证产品质量始终处在可控范围之内。
1 质量数据的特点
质量数据贯穿于质量管理体系涵盖的整个制造过程,形式多种多样,具有重复性、可预见性、历史性、详细性和形式结构化(表式)这几个显著特征。制造业的质量信息系统(QMS)记录了大量质量信息,比如产品的技术水平、性能、质量指标、可靠性、安全性、可维修性、耐用性等指标,合格率、废品率、返修率等指标,成本及消耗资料,产品的技术改造规划,市场调查、销售服务及客户反馈的资料,零部件及外协外购件的实用质量资料,产品设计图纸、各种技术文件、档案、使用说明书,新产品、新工艺开发计划,新产品试制、实验、检测、鉴定、小批及批量生产资料等与产品质量有关的信息[1]。
质量系统的质量数据具有异构和层次性的特点,从低到高可以划分为现场级信息、过程级信息、产品级信息和体系级信息4 个层次。按时间顺序采样得到的一系列数值型数据序列,构成了质量管理系统中最重要的信息流。
2 数据挖掘
数据准备、数据挖掘过程、知识评估与表示这3个步骤组成了数据挖掘的一般形式。数据挖掘可描述为如下几个阶段的反复过程,如图1 所示。
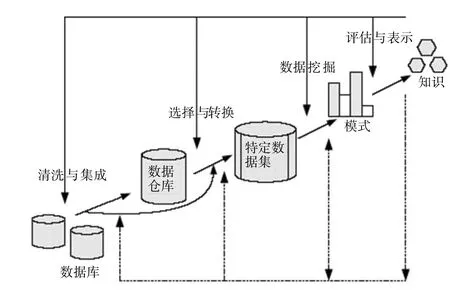
图1 数据挖掘的过程
2.1 数据准备
数据准备阶段可进一步分为3 个步骤:数据集成、数据选取、数据预处理和转换。在数据挖掘中,数据准备阶段大约需要占据整个工作量的80%的时间。
(1)质量数据集成是从不同性质的现场质量数据仓库、文件或记录中提取数据信息再合并处理。
(2)数据选取是指根据数据分析结果所需要的特征信息(比如产品油漆外观凹凸点分布),建立数据分析模型,使用适合的收集方法建立数据仓库,数据选择的重要性甚至超过了算法。
(3)数据的预处理和转换是指在实施挖掘前,对收集到的特征数据进行缩减、降维和转化,剔除冗余数据,保证数据的逻辑一致性等。进行过处理和转化的数据,将有助于提高数据挖掘的效率和质量[2]。
2.2 数据挖掘过程
将收集和处理后的数据通过特定的分析工具进行处理,得到有用的分析信息的过程。
2.3 评估与表示
通过商业智能BI 的各类报表提供的图形化、可视化的工具将数据挖掘所得到的分析结果呈现给用户,也可以将分析结果存入知识库中,供其他应用程序使用。
这几个步骤又被称为ETL 过程,即抽取(Extract)、转换(Transform)、清洗(Cleansing)、装载(Load),按照预定义好的数据模型,将数据加载到质量数据仓库中去,再选择应用挖掘算法,执行相应的挖掘操作,最终得到对应的数据模式。经过数据挖掘呈现的结果一般多是发展趋势,比如顾客问题趋势、合格率趋势等,如图2 所示。实际工作中往往需要钻取发现造成趋势波动影响的因素,需要引入对这些差异点的检测方法。
图2 QMS 中的各类趋势分析图表
3 孤立点的定义和检测
在统计学,孤立点已被广泛应用,但基于距离的孤立点定义,即使是对等距离的量度函数,对孤立点也有着多种解释,本研究探讨以下几种。
(1)在数据集S中,O是一个孤立点,仅当S中至少有P部分对象与O的距离大于d,这里的距离就是用上面介绍的距离量度函数计算出来的距离。换句话说,如果在d范围内有不多于M 个的数据点,则O是一个带参数P和d的DB(P,d)孤立点。这里M =n×(1 -P)。n为数据对象的个数。
(2)孤立点是数据集中n个到Sth最近距离最大的对象。对于对象P和参数k,令Dk(P)表示k个与P最近的到P点的距离之和。则具有最大值Dk的头n个对象就是孤立点。
(3)孤立点是数据集中n个与其k个最近邻居的平均距离最大的对象。
这里的距离度量函数一般使用绝对距离或欧几里得距离(Euclidean Distance 简称欧式距离)。假定数据对象为区间标度变量类型,则绝对距离可定义为:
欧式距离是最常见的距离量度,其定义为:
数据对象的维数(属性)若定义为m,则表示第i个对象第j属性的值。这两个距离可统一为:
通过分析数据个体间特征差异的大小,评估得到数据的类别和相似性。
3.1 基于距离和的异常挖掘
使用同样的距离函数,例如绝对距离或者欧氏距离,但并不根据p和d来判定孤立点,而是首先计算数据集中对象两两之间的距离,然后计算每个对象与其他对象的距离之和,设M为用户期望的孤立点个数,则距离之和最大的M个对象即被认为是孤立点。
基于距离和的孤立点检测可以描述如下:
对原始数据集进行标准化后,计算n个对象两两之间的距离dij,形成距离矩阵R:
3.2 算法的实现过程
根据距离和的概念和孤立点的检测算法,可以依据如图3 所示的流程步骤实现。

图3 基于距离和的孤立点检测算法实现流程
4 孤立点检测的实际应用
质量管理信息系统(QMS)提供了检验批次合格率、单个质量特性合格率、单个质量特性实测数值、批次不合格品处置意见、检验不合格批次分布、不合格批次占比对比、不合格项汇总信息、不良项目柏拉图、不良供应商柏拉图等多累分析工具,引入孤立点检测算法对各类分布和趋势可以进行再深入的数据钻取,得到各类趋势的分布范围,可以制订针对的应对措施,有效控制制造过程中出现的质量缺陷。比如,QMS已经对采集到的质量特性过程能力进行了量化,为工艺参数CPK 过程能力考评提供支持。通过结合孤立点检测对过程能力量化就可以发现过程控制能力薄弱环节。
5 结语
通过设立数据采集点,动态地实时采集质量信息数据,将质量管理的各个过程用信息化的手段数字化串联起来,成为进行大数据分析的数据池,再对里面的数据进行标准化和分析,最终发现有价值的数据模式,这就是质量管理信息系统(QMS)中的数据挖掘。该企业充分利用QMS 收集到的海量信息为基础,以数据和业务驱动的方式分析在质量管理领域的PDCA 过程(即计划、实施、检查和改进)中记录的质量状况,找出产品质量变化的趋势,发现造成波动的孤立点,从而可以有针对地集中资源进行质量攻关,并将成果应用到制造过程的实时控制,提高了产品的一次性下线合格率,得到了客户方良好的评价。
猜你喜欢
湖南税务高等专科学校学报(2021年4期)2021-08-30
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
小学生导刊(2018年34期)2018-12-18
意林(2018年3期)2018-03-02
厦门理工学院学报(2016年1期)2016-12-01
山东青年(2016年3期)2016-02-28
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
信息通信技术(2015年6期)2015-12-26
母子健康(2015年1期)2015-02-28
