
迁移评分模式的跨域学习资源推荐算法
2022-03-07 06:57郭俊宏甘柏青徐林杰丁永刚
软件导刊 2022年2期
郭俊宏,甘柏青,徐林杰,丁永刚
(1.湖北大学 师范学院,湖北 武汉 430062;2.武汉船舶通信研究所,湖北 武汉 430205)
0 引言
网络学习具有个性化、主动式、探究式、协作式、不受时间和地点限制等优点而备受学习者青睐。然而,随着网络学习资源的爆炸式增长,学习者难以快速准确地获取到自己感兴趣的资源,导致学习难度加大、学习时间延长,降低了学习者的学习效率。为了帮助学习者快速准确找到其感兴趣的学习资源,近年来教育技术领域专家和学者致力于在网络学习系统中加入个性化学习资源推荐服务以解决资源过载这一问题。现有的个性化学习资源推荐方法大多基于单领域进行,即仅根据学习者在某一单个领域(如文本资料)的兴趣偏好,向其推荐感兴趣的学习资源。然而,单领域学习资源推荐存在诸多局限性,主要表现为:一是在数据稀疏和冷启动的情况下,无法为学习者提供准确的推荐结果;二是单领域推荐算法在同一领域基于相似群体分类进行推荐,所推荐的学习资源一般是同一类型、同一水平、与已学过知识高度近似的资源,因此无法真正满足学习者的个性化需求,也无法达到挖掘学习者学习兴趣与学习潜力的目的。在实际的网络学习环境下,学习资源多种多样,如文本、声音、图形、图像和视频等(跨多个领域),学习者的学习需求也表现出多样性,而学习者在每一领域的评分数据更加稀疏。显然,单领域推荐算法已很难适应跨领域的学习资源推荐服务。
跨领域信息资源推荐算法的主要思想是由Pan 等在2009 年基于迁移学习的概念而提出,它是解决多领域推荐问题的有效方法,已在电子商务领域广泛应用。近年来,教育技术领域专家和学者也开始致力于将跨域推荐技术应用于跨域教育资源推荐,为学习者提供真正个性化的学习资源推荐服务。现有的跨域推荐算法主要有3 类:一是基于域关联的跨域推荐,如Wang 等通过从学习者访问日志中提取个性化偏好,提出一种基于混合兴趣度的跨域学习资源推荐方法;赵厉宇哲等提出一种融入专业度和用户相似性的跨域推荐算法,实现了图书、音乐、DVD 和影片等资源的跨域推荐;叶佳鑫等利用标签间的关系,提出一种以标签为基础的跨域资源推荐方法;唐路平等通过跨域用户特征信息交互,提出一种有效的迁移学习算法,解决了传统协同过滤算法中的冷启动问题;曹鹤提出基于领域相关度的跨域推荐算法,实现了图书、音乐、光盘和视频等多源跨域学习资源推荐;二是基于隐含特征映射∕转换的跨域推荐,如李宇航等通过共享跨域特征信息,重构评分矩阵实现了电子书、视频和音频等资源的跨域推荐;田靖玉等提出知识聚合和迁移相结合的跨领域推荐算法ATCF,并考虑了群体效应,实现了图书与电影的跨域推荐;吴彦文等提出一种利用GFK 特征映射,联合用户侧重和项目侧重多元迁移模式的领域自适应方法,以应用于跨领域推荐;三是基于评分模式共享的跨域推荐,如陈燕等提出一种基于共享评级迁移的跨域推荐算法SRTCD,对不同领域之间用户对项目的评分模式建立一种关联,再结合迁移模式的跨域方法解决稀疏性问题和冷启动问题;Li等利用矩阵分解技术在聚类层次上将用户的评分模式进行迁移,实现了电影与图书的跨域推荐。
以上方法在一定程度上解决了学习资源跨域推荐存在的问题,但是由于其算法的时间和空间复杂度高,在实际应用中很难实现实时有效的推荐。丁永刚等利用码本聚类思想,在评分矩阵中提取用户在不同指标上的评分模式和商品的被评分模式,并将其集成到因子分解机模型,在线性时间复杂度下实现了商品的多指标推荐;Babak等提出基于因子分解机的协同过滤跨域推荐技术,通过提取与合并特定类型项目的用户交互模式,再迁移到目标领域完成推荐,实现了算法的可扩展性和线性时间复杂度。受文献[13]和文献[14]的启发,本文提出一种迁移评分模式的跨域学习资源推荐算法(Migrating User and Item Rating Patterns,MUIRP),该方法首先基于码本聚类思想从学习者的辅助领域评分数据中抽取学习者的评分模式和资源的被评分模式偏好,然后将其迁移到目标领域,以填补学习者在目标领域评分数据的不足,最后利用因子分解机模型能方便集成多个特征向量的特性,将目标领域学习者信息、学习资源信息、评分模式和被评分模式进行统一建模,为学习者提供真正实时有效的个性化学习资源推荐。
1 迁移学习与跨域推荐相关技术
迁移学习主要用来解决推荐系统的数据稀疏和冷启动问题,它首先从辅助领域中获取相关知识或数据,然后将经过处理的信息迁移到目标领域,以填补目标领域数据的不足,从而解决目标域中的数据稀疏和冷启动问题。在学习资源推荐领域,利用学习者在某些领域的知识学习情况,帮助其在其他领域的知识学习,可以最大程度地挖掘出学习者的学习偏好,帮助发现其学习兴趣与学习潜力。这既符合人类自身学习行为的特点,同时也可以降低收集、标记数据的成本,因此具有十分重要的意义。
1.1 码本聚类
码本算法是图像背景建模的常用方法,其基本思想是使用一个码本(CodeBook,CB)来描述一个像素P,而每个码本中包含若干码元(Code Element,CE),这些码元就是该像素点P 的一个聚类。码本算法就是要构建像素的一个个聚类,即码本。实际上,码本算法的图像背景建模是一个统计过程,在构建码本的过程中,码本算法会将某点出现的可能的像素值进行统计,根据码元定义的特征属性,设定阈值进行判断,只有符合条件的像素值才可作为背景像素。因此,码本算法的背景建模具有聚类思想。
基于码本聚类思想,在用户评分矩阵中,可以将用户在学习资源不同分值上的评分频率作为码本,然后基于码本对评分矩阵的行和列重新进行排列,即基于码本进行聚类。由于用户评分模式可以通过用户的评分频率表示,基于码本聚类实际上是将评分模式相似的用户聚成一类,从而形成聚类级的用户评分模式,如图1 所示。类似地,从用户的评分矩阵中,也可以提取出资源的被评分模式,从而将被评分模式相似的资源聚成一类,形成聚类级的资源被评分模式。
1.2 因子分解机
因子分解机是Rendle提出的一种通用分解模型。与经典分解技术中用户与项目的交互使用矩阵表示不同,因子分解机模型使用真值特征向量表示用户与项目的交互。假设评分预测问题的数据集由元组(x
,y
)的集合表示,这里x
=(x
,…,x
)∈R是一个n
维特征向量,则FMs 能够使用分解交互参数对x
的i
个输入变量的所有嵌套交互进行d
维度建模。当d
=2 时,因子分解机模型可以表示如下: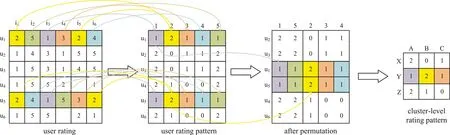
Fig.1 A cluster-level rating model based on codebook图1 基于码本的聚类级用户评分模式
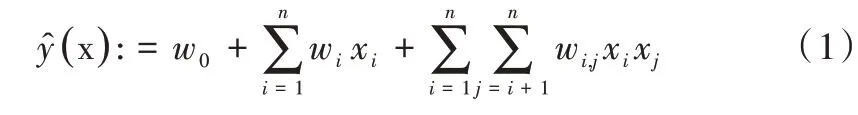
w
是全偏量,w
是输入变量x
的一元交互参数,w
是v
和v
之间的分解参数,定义为: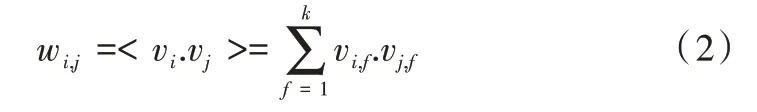
k
是一个定义分解维度的超参数。因子分解机FMs 的一个重要特点是输入特征向量成对交互效果可用低秩矩阵表示,因此输入向量之间的交互不是使用一个独立参数w
进行建模,而是使用分解参数<v
.v
>加以建模。该特点使得FMs 即使在数据稀疏的情况下,也能对高维交互参数进行可靠估计,并且能够在O(k
.m
(x
))的线性时间内进行有效计算(这里m
(x
)是向量x中非0 元素的个数)。2 迁移评分模式的跨域学习资源推荐
针对学习资源推荐存在的数据稀疏和冷启动问题,首先基于码本聚类思想从辅助域的用户评分矩阵中抽取用户的评分模式和学习资源的被评分模式,然后将其迁移到目标域,并利用因子分解机模型能方便集成多个特征向量的特性,将目标领域学习者信息、学习资源信息和评分模式信息进行统一建模,以实现跨域学习资源的精准推荐。
2.1 基于码本聚类的用户评分模式与学习资源被评分模式表示
传统的协同过滤算法基于学习资源评分计算用户或学习资源之间的相似性,实际上,如果将用户—学习资源评分矩阵中用户对学习资源的评分信息进行重构,便可以得到用户对学习资源评分信息的另一种表示形式。Tan等通过对Netflix Prize 数据集进行分析,认为用户—学习资源矩阵中隐含着不同的用户评分模式或学习资源被评分模式信息,而这种评分模式或被评分模式隐式地反映了用户或学习资源之间的相似性。例如,如果一个用户对一些电影都给出较高评分,则隐含着这些被评为高分的电影是相似的;类似地,如果一个电影总是被一些用户给出较高评分,则隐含着这些给出高分的用户是相似的;反之亦然。因此,可以将这些具有相似评分模式的用户或被评分模式的学习资源集聚到同一簇内。如上所述,用户的评分模式或学习资源的被评分模式可以通过用户的评分频率和学习资源的被评分频率加以表示。因此,首先基于码本聚类思想计算用户∕学习资源的评分∕被评分频率,将其表示为用户的评分模式或学习资源的被评分模式,然后使用K-means 聚类算法将相似用户或相似学习资源集聚到同一簇内。
具体地,用户u
的评分模式可以表示成:
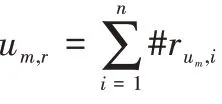
i
的被评分模式可以表示为:
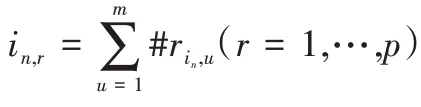
使用用户的评分频率和学习资源的被评分频率表示用户评分模式和学习资源被评分模式,使得没有共同评分但有相同或相似评分频率的用户或被评分频率的学习资源之间也有可能进行相似度计算,从而可以在一定程度上缓解数据稀疏问题。
2.2 基于因子分解机迁移评分模式的跨域输入特征向量构造
假设有两个不同的领域{D1,D2},D1 表示视频领域,D2表示图书领域,其中视频的评分数据比较稀疏,而图书的评分数据比较充足,则可以将用户对图书的评分模式和图书的被评分模式迁移到视频领域,以实现图书的精准推荐。

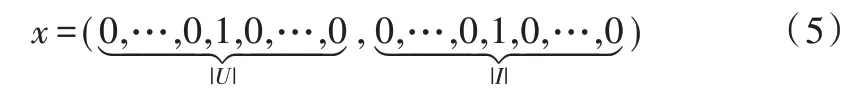
u
和项目i
。该特征向量也可以简化地表示为x
(u
,i
)={(u
,1),(i
,1) }。因子分解机FMs 的最大优点是能够通过构建真值特征向量集成各种附加信息,因此可以基于式(5)将用户和学习资源的评分信息、基于码本聚类的用户评分模式和学习资源的被评分模式集成到FMs 中。
迁移评分模式的因子分解机跨域推荐的目标函数可以表示为:

I
是学习资源i
的评分空间,Um
为用户在辅助域上的评分模式信息,In
为项目n
在辅助域的被评分模式信息,R 为评分空间。相应地,该效用函数的输入特征向量构造如下:
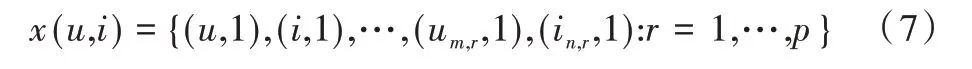
u
是用户m
的评分值为r
的学习资源数目,i
为学习资源n
的被评分值为r
的数目。根据式(7)集成评分模式信息的输入特征向量的构造方法,本文给出输入特征向量的一个实例,该实例将用户、资源、用户评分模式和资源被评分模式作为输入特征向量,将用户的评分值作为特征向量的输出,如图2 所示。

Fig.2 Construction of input elgenvector based on transfer scoring mode of FM图2 基于因子分解机迁移评分模式的输入特征向量构建
3 实验及结果分析
3.1 数据集与评价指标
Amazon product co-purchasing network metadata 包含亚马逊网站中的图书、音乐CD、DVD 和视频4 类资源的用户评分,分值从1(最不喜欢)到5(最喜欢)。本研究选取图书和视频资源分别作为辅助域和目标域。其中,图书域包含4 591 303 条评分记录,有278 269个用户和393 561 本图书;视频域包含450 131条评分记录,有63 369个用户和26 132个视频。为了验证所提出算法在数据稀疏情况下的有效性,过滤掉这两个领域中无评分的资源后得到图书域中有278 269 本图书,评分记录和用户数不变;视频域中有22 359个视频,评分记录和用户数不变。实验选择目标域80%的评分数据作为训练集,20%作为测试集。
实验结果使用均方根误差(RMSE)作为评价指标,计算公式如下:
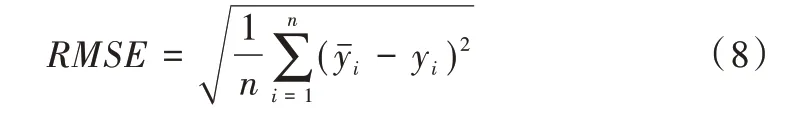
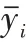
3.2 比较方法
为了评估本文提出的迁移评分模式的跨域学习资源推荐算法(MUIRP)的有效性,选取Amazon product co-purchasing network metadata 作为实验数据,并与基线方法1-3和基于领域相关度或共享评级迁移效果最好的4~6 种模型进行比较。①SDR:基于FM 的单领域资源推荐算法(Single Domain Recommendation,SDR);②MURP:仅迁移用户评分模式的跨域资源推荐算法(Migrating User Rating Patterns,MURP);③MIRP:仅迁移资源被评分模式的跨域资源推荐算法(Migrating Item Rating Patterns,MIRP);④FMMCMC:基于因子分解机的协同过滤跨域推荐算法(Factorization Machines-Markov Chain Monte Carlo,FM-MCMC),该算法将用户在辅助域对商品评分的贡献度迁移到目标域进行推荐;⑤CDFM:基于领域相关度的跨域推荐算法(Correlation Domain Factorization Machines,CDFM),该算法计算用户在辅助域与目标域的评分向量相关度,并基于FM将其迁移到目标域进行推荐;⑥SRTCD:基于共享评级迁移的跨域推荐算法(Shared Ratings Transfer Cross-Domain Recommendation,SRTCD),该算法通过概率矩阵分解提取用户和项目的潜在特征,对用户类别和项目类别分别进行聚类,并将其内积作为共享评级迁移到目标域进行推荐。
3.3 实验结果与分析
3.2.1 与SDR、MURP 和MIRP 推荐算法比较
实验结果如图3 所示。可以看出,与SDR 相比,在各种K 值情况下,MURP、MIRP、MUIRP 方法均显著优于SDR,而MUIRP 方法准确度略高于MURP、MIRP。这说明迁移评分模式或被评分模式确实能解决目标数据的稀疏问题,极大提高推荐准确度;且同时迁移跨域评分模式和被评分模式能够更好地提高推荐准确度。同时,从图3 中还可以看出,MUIRP 方法的性能随K 值变化而变化,当K=20、K=6 或K=18 时,MURP、MIRP、MUIRP 方法的性能分别达到最优。
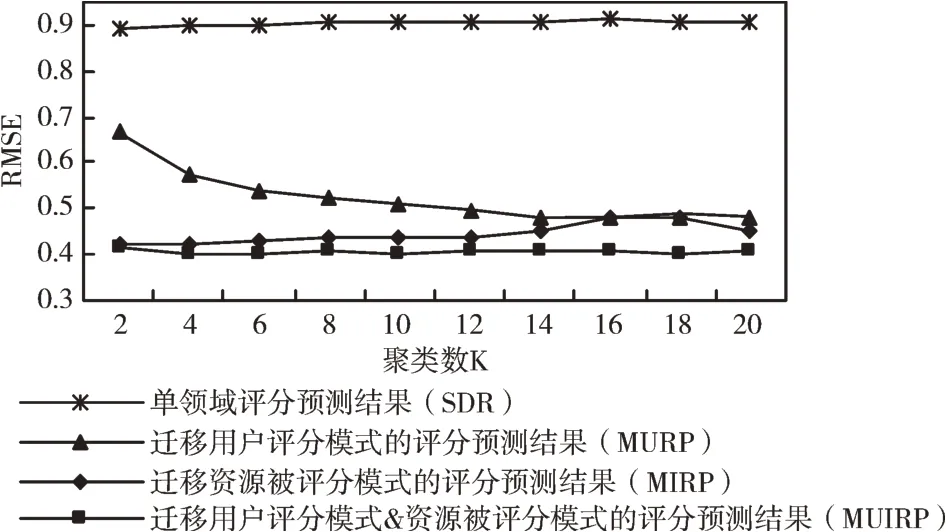
Fig.3 RMSE comparison of MUIRP,SDR,MURP and MIRP under different cluster number K图3 MUIRP 与SDR、MURP、MIRP 在不同聚类数K 下的RMSE 比较
3.2.2 与FM-MCMC、CDFM 和SRTCD 推荐算法比较
实验结果如图4 所示。可以看出,MUIRP 预测评分的最优和最差RMSE 值均优于FM-MCMC、CDFM 和SRTCD,特别是在MUIRP 的最优RMSE 值上,分别降低38%、36%和54%。这说明用户评分模式信息和资源被评分模式信息对提高推荐准确度均起到较大作用。
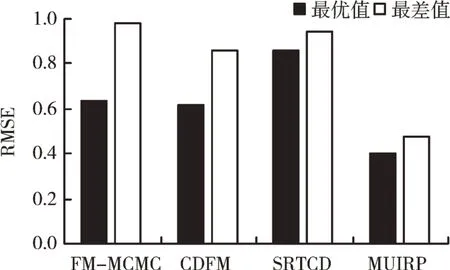
Fig.4 RMSE comparison of MUIRP,FM-MCMC,CDFM and SRTCD on the best and worst index图4 MUIRP 和FM-MCMC、ATCF、CDFM 在最优与最差指标上的RMSE 比较
4 结语
随着网络学习资源形式趋于多样化和海量学习资源不断增加,用户在学习过程中面临着信息过载与信息迷失等问题。本文针对学习者在单一学习资源领域存在评分数据稀疏的问题,提出了迁移评分模式的跨域学习资源推荐算法,并在真实数据集上进行了实验。实验结果表明,所提出的迁移评分模式的跨域学习资源算法在不同聚类下的准确度均优于单领域推荐算法、仅迁移用户评分模式的算法和仅迁移资源被评分模式的推荐算法,同时也优于当前基于领域相关度或共享评级迁移最好的3 种跨域推荐算法。但本文提出的方法在迁移评分模式时没有考虑辅助域评分时间对目标域的影响,下一步将对该问题进行深入研究,以进一步提高推荐准确度。
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
中国民航大学学报(2022年5期)2022-12-19
南京邮电大学学报(自然科学版)(2022年4期)2022-09-20
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
中国民航大学学报(2021年3期)2021-08-04
纯粹数学与应用数学(2018年3期)2018-10-10
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
