
Kubernetes 的资源动态调度设计研究
2022-03-07 06:58罗永安包梓群赵恪振余隆勇
软件导刊 2022年2期
罗永安,包梓群,赵恪振,余隆勇
(浙江理工大学 信息学院,浙江杭州 310018)
0 引言
Google 开源的Kubernetes 是一个大规模容器集群管理系统,它对容器化的应用提供部署运行、资源调度、负载均衡、自动扩容等一系列功能,已成为云平台的主流。Pod 是Kubernetes 集群上的最基本单元,用于存放一组容器及这些容器的共享资源。Kubernetes 的默认资源调度是按照各工作节点的资源使用情况和Pod 创建时请求的资源量进行。当一个Pod 被kubernetes 调度器调度至合适的工作节点上,Pod 都不会在其生命周期结束前发生迁移。但是随着时间的推进和工作节点上资源的变化,在Pod 创建时的调度选择可能不再适用,集群出现负载不均衡、资源利用率低等问题。
在资源调度领域,已经有诸多学者做了大量研究工作。Chang 等提出一种基于资源利用率和应用QoS 度量指标的Kubernetes 资源调度算法,从静态资源的角度提高了调度有效率;杨鹏飞将ARIMA 模型和神经网络模型组合预测系统资源使用量,并基于此设计一种资源借贷的动态调度算法,减少系统资源碎片化,但对集群负载均衡方面考虑较少;唐瑞提出基于Pod 重启策略确定优先级的动态负载均衡策略,没有考虑Pod 迁移时对集群资源的消耗;平凡等提出基于重新调度Pod 实现集群系统负载均衡的调度模型,其对于有状态服务的资源动态调度难以实现。
针对以上问题,本文提出基于Kubernetes 的资源动态调度方法,解决Kubernetes 集群各工作节点长时间运行情况下集群负载不均衡的问题。使用层次分析法(Analytic Hierarchy Process,AHP)从多维度对各节点打分,并以此建立高负载队列。通过滑动窗口从高负载工作节点筛选出待迁移Pod 集合并根据低负载原则为其选取目标工作节点,达到通过减少迁移Pod 数量降低系统消耗的目的。考虑到对有状态服务的支持,最后通过技术迁移(Checkpoint∕Restore In Userspace,CRIU)Pod 实现资源调度。
1 资源动态调度机制设计
Kubernetes 集群是Master-Slave 模型,是由一个Master节点和多个Node 节点构成。Master 节点是Kubernetes 的控制节点,通过API Server 实现对集群的调度和管理。Node是Kubernetes 的工作节点,主要任务是运行Pod 应用,通过kublet 管理和控制Pod。资源动态调度由监控模块、资源动态调度算法、迁移模块组成。监控模块负责监控Node 工作节点和Pod 应用的资源信息,资源动态调度算法负责选取需要重新调度的Pod 应用以及运行待调度Pod 应用的工作节点,迁移模块基于CRIU 技术并通过API Server 控制集群上Pod 应用的迁移。本文基于Kubernetes 资源动态调度机制设计如图1 所示。

Fig.1 Dynamic resource scheduling mechanism based on Kubernetes图1 基于Kubernetes 动态资源调度机制
Kubernetes 资源动态调度机制的工作流程为:通过Master 节点上的监控模块监控各Node 工作节点的Kubelet,从中获取各工作节点和Pod 应用的资源使用状况。资源动态调度算法首先会根据监控得到的各类资源使用情况对各Node 工作节点进行负载评估,应用迁移算法,根据负载评估得到的结果建立高负载工作节点队列,从高负载队列中选取待迁移Pod 集合,并为其选择合适的目标工作节点,将Pod 应用迁移至目标工作节点,将集群信息更新至Etcd存储器中。
2 资源动态调度算法设计
2.1 负载评估
为了评估和比较各工作节点和Pod 应用的负载状况,使用数学表达式表示工作节点和Pod 应用的资源使用情况。选取CPU 利用率、内存利用率、带宽使用率、磁盘利用率作为工作节点的负载因子,从多维度评估工作节点的负载状况,并通过AHP(Analytic Hierarchy Process,层次分析法)建立模型。构造一个判断矩阵,该判断矩阵用来表示选取的4个负载因子的相对优越程度。采用1~9 将4个负载因子的相对优越程度进行量化,构造出一个两两比较的判断矩阵,其形式如下:
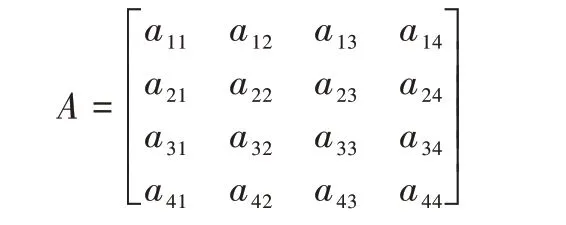
a
表示负载因子,a
表示CPU 利用率,a
表示内存利用率,a
表示带宽利用率,a
表示磁盘利用率。a
表示a
对a
的相对重要程度,通常采用1、3、5、7、9 及其倒数,2、4、6、8 表示第i
个因素相对于第j
个因素的影响介于上述两个相邻的等级之间。通过合法求解矩阵的排序向量得到各负载因子的权重。其步骤如下:
(1)将矩阵A
的列向量归一化: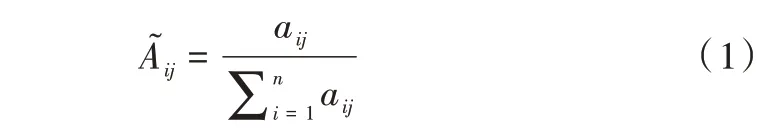
A
按行得到:
W
归一化,得到:
A
的最大特征值。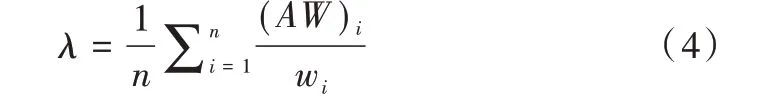
CI
指标衡量矩阵的一致性程度。
CI
的值越大,其判断矩阵的一致性越差,若CI
=0,则该判断矩阵具有完全一致性。为了衡量CI
的大小,又引入随机一致性指标RI
,本文选取4个负载因子,RI
=0.90。其判断矩阵的一致性比率为:
CR
<0.1 时,认为A
的不一致程度在容许范围内,可以通过一致性检验,可用其归一化特征向量作为权向量,否则要重新构造成判断矩阵A
,对a
加以调整。本文将判断矩阵构造如下:
W
=(0.523 7,0.270 8,0.135 3,0.070 2)。其矩阵的最大特征根λ
=4.0019,从而得到CI
和RI
。
由上可知,该判断矩阵满足一致性。
在经计算得到选取的4个负载因子的相对权重基础上,通过监控得到的性能指标向量为a=(a
,a
,a
,a
)。得到节点和Pod 的负载评价度量值R
如下:
R
越大代表该负载越重,反之代表其负载较小,R
的最大值是100。2.2 应用迁移
当某一工作节点的负载评价度量值R
大于触发阈值,说明该工作节点的资源使用将达到临界状态,其触发阈值的公式如下:
R
表示各工作节点的负载评价度量值,i
∈{1,2,…,i
,…,n
},α
为均衡系数决定系统触发阈值大小。为了避免Pod 不停迁移而出现系统抖动,以多次触发阈值为依据建立高负载工作节点队列,然后基于滑动窗口设计选取迁移Pod算法,从高负载工作节点中挑选出待迁移Pod 集合,通过预选和优选选择出合适的工作节点,应用迁移算法总体框架如图2 所示。具体算法流程描述如下:
Step1:输入计算得到的各工作节点的负载评价度量值R
Step2:判断各工作节点的负载评价度量值是否大于其触发阈值T
,如果是则继续进行Step3,如果不是将不会对该工作节点上的Pod 进行迁移。Step3:分析Step2 中的工作节点的历史负载数据,如果其负载值连续3 次都大于触发阈值T
,则认为它是过载的工作节点,将其放入高负载工作节点队列中。Step4:如果高负载工作节点队列不为空,取出队列的头节点,对其Pod 进行迁移。如果高负载工作节点队列为空,则结束这次动态资源调度,等待下一个时间周期的动态资源调度。
Step5:在Step4 中取出的高负载工作节点选取待迁移的Pod 集合。
Step6:对Step5 中选取的Pod 集合选取合适的目标工作节点。如果找到,则对该Pod 进行迁移;如果未找到,不迁移该Pod 等待下一次资源动态调度。直到将Pod 集合全部处理完,则该工作节点处理完毕。继续进行Step4,处理剩下的高负载工作节点。
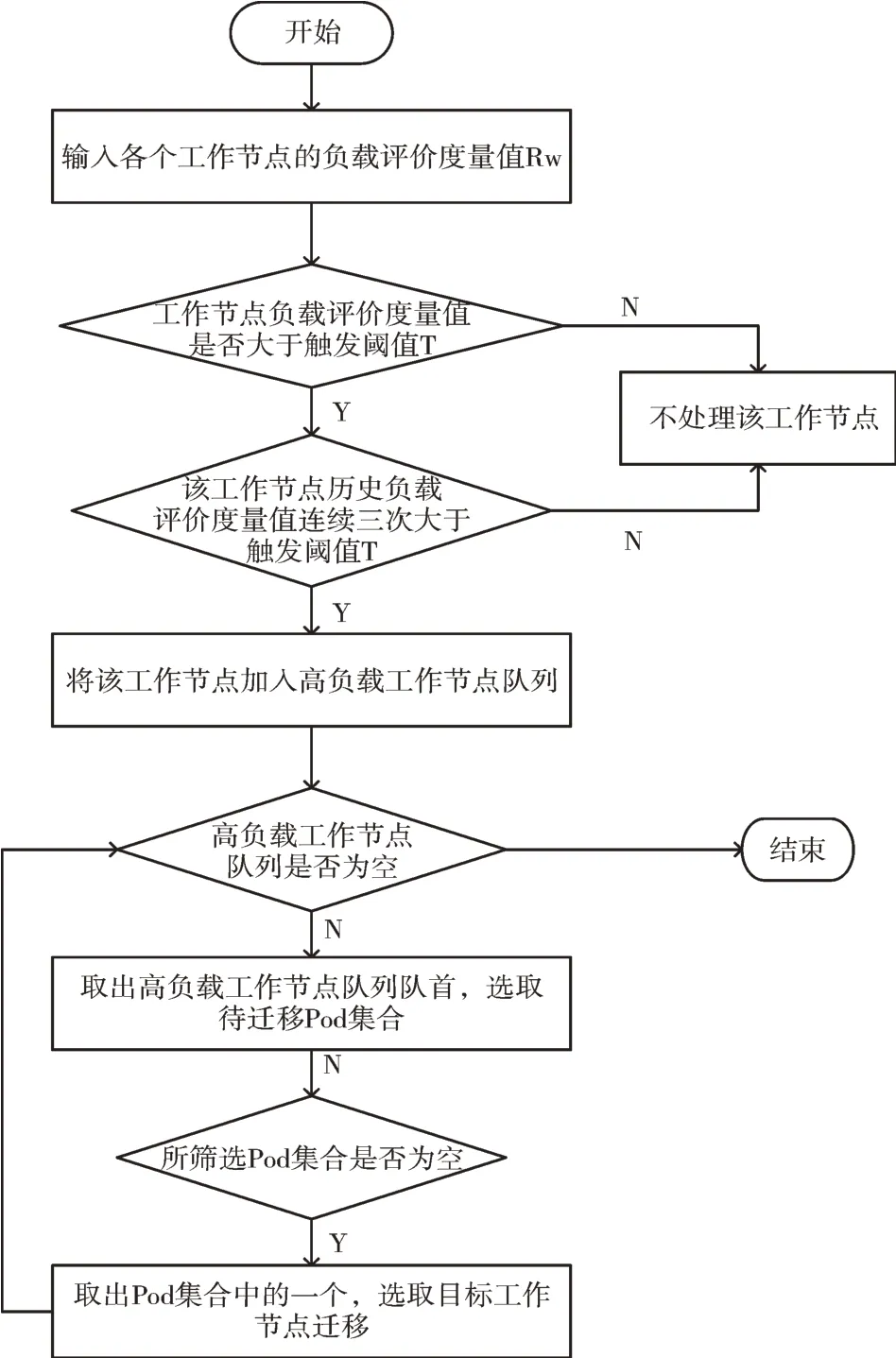
Fig.2 Application migration algorithm overall framework图2 应用迁移算法总体框架
2.2.1 迁移Pod 选取
每一个Pod 迁移都需要消耗集群系统资源,因此需要尽可能选取少量的Pod 进行迁移。每个Pod 的负载均衡度量值按照式(7)计算得到R
。当选取的Pod 的R
过大,可能会找不到合适的工作节点运行该Pod;当选取的Pod 的R
过小,要迁移多个Pod 才可实现负载均衡,降低了集群系统效率。通过将高负载工作节点的负载评价度量值和集群节点的平均负载度量值差值作为滑动窗口大小值,在其窗口内选择迁移数量最少的Pod 进行迁移。通过滑动窗口选取迁移Pod 的算法如下:输入:触发迁移Pod 工作节点上的Pod 集合
输出:待迁移的Pod 集合
Step1:将Pod 集合数组按照负载评价度量值R
从小到大进行排序。Step2:初始化两个指针i
、j
指向排序后Pod 集合数组的第一个元素;初始化num 存放符合条件的Pod 最小个数,其初值为Pod 的个数;
初始化两个指针p
、q
分别存放符合条件的i
、j
指针位置,其初值为空指针;初始化一个sum 存放可能迁移Pod 负载评价度量值总值,初值为第一个元素的负载评价度量值;
初始化一个window 存放应该迁移的Pod 的负载评价度量总值,其初值为该工作节点的负载评价度量值减去集群节点的平均负载度量值。
Step3:当指 针i
指 向的Pod 和指 针j
指向的Pod 为同一个Pod 或者i<j
时进入Step4 循环,否则进入Step5。Step4:sum 值小于0.9window,则指针j
指向下一Pod,sum 加上该Pod 的负载评价度量值;sum 值在0.9window~1.1window 之间,更新num 值,其取值为当前num 值和指针i
、j
之间Pod个数的最小值。若num的值改变,并将p
、q
指针指向当前i
、j
指针。指针j
指向下一个Pod,sum 加上该Pod 的负载评价度量值;sum 值大于1.1sh,则指针i
指向下一个Pod。sum 减去该Pod 的负载评价度量值;Step5:p
、q
指针指向及其之间的Pod 即为待迁移的Pod集合。2.2.2 目标工作节点选取
为待迁移的Pod 选取新的工作节点要通过预选和优选两个阶段。在预选阶段对各工作节点进行检查,按照待迁移Pod 端口是否被工作节点占用、工作节点是否有足够资源运行待迁移Pod、工作节点是否存在储存卷冲突的筛选策略,过滤掉不符合条件的工作节点,筛选出可以运行迁移Pod 的工作节点。优选阶段会对预选出的工作节点按照式(7)进行负载评估得到负载评价度量值,按照负载评价度量值进行优先级排序,负载评价度量值越大优先级越小,反之优先级越大,选出最合适Pod 对象的工作节点。
目标工作节点选取算法如下:
输入:待迁移的Pod 集合资源描述文件,所有工作节点资源描述文件
输出:目标工作节点
Step1:按照待迁移Pod 的负载评价度量值R
将Pod 应用从大到小排成队列,依次为队列中Pod 应用选取目标工作节点。Step2:将所有工作节点按照预选阶段筛选策略过滤得到候选工作节点队列,如果候选工作节点队列为空,选取待迁移Pod 队列中的下一个Pod,重新进行Step2;不为空,进行下一步。
Step3:将Step2 中得到的候选工作节点队列按照负载评价度量值R
将候选工作节点从小到大排成队列。Step4:选取Step3 中负载评价度量值R
最小的工作节点作为目标节点,并且更新该目标工作节点的资源状况。选取待迁移Pod 队列中的下一个Pod,重新进行Step2。3 实验设计与结果分析
3.1 实验环境与实验设计
3.1.1 实验环境
为了验证动态调度资源的有效性和可行性,搭建了一个Kubernetes集群,其中K8s使用1.16版本,Docker使用18.09.06版本。实验在4台不同规格系数的服务器节点上完成。其中,1台作为Master 节点,3台作为Node 节点。其每个虚拟机的具体配置如表1 所示。
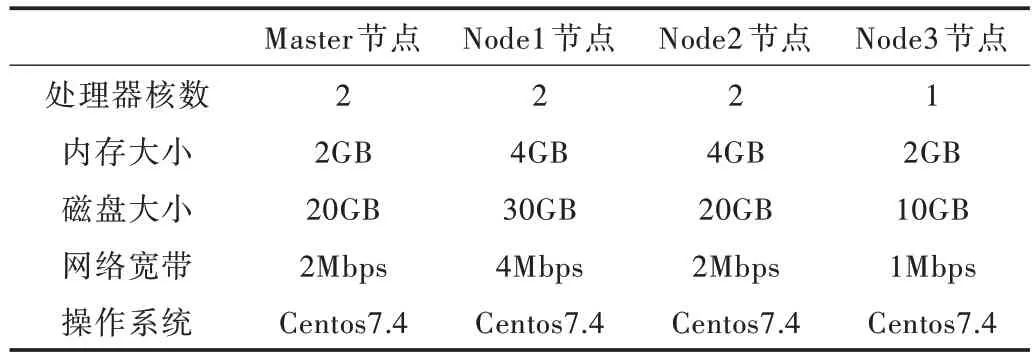
Table 1 Test virtual machine configuration表1 测试虚拟机配置
Pod 应用选取服务器上常见的JavaWeb 应用,其主要需要的程序为Tomcat 和Mysql 数据库,为有状态服务。在Tomcat 上运行Java 程序,并且该程序可以向Mysql 写入数据,并可修改和删除数据,同时可以统计Mysql 中的数据。将Tomcat 和Mysql 两个Docker 放入一个Pod 中,该应用充分利用了服务器的CPU、内存、磁盘以及网络宽带资源。
3.1.2 实验设计分析
除Kubernetes 默认采用的资源调度策略,基于优先级的资源调度也是常见资源调度策略,将待调度队列按照一定优先级排序,将优先级高的先调度,优先级低的后调度,其调度策略可以较好地维持系统负载均衡并提升系统性能。文献[6]中基于Pod 的重启策略确定优先级的资源动态调度策略被广泛应用,本文在其基础上进一步增加了基于优先级的资源调度在负载评估和迁移消耗方面的深入调度策略研究。
为了验证本文所设计的资源调度算法的有效性,在集群上分别运行Kubernetes 默认资源调度,将文献[6]中基于优先级的资源动态调度与本文设计的资源动态调度进行对比实验。在集群中每隔5min 为集群发布20个Pod 应用,共发布100个Pod。使用JMeter 对Kubernetes 集群中的Pod应用发送HTTP 请求,请求数量和请求端口都是随机生成。每次发布应用后,记录集群的负载评价标准差,集群运行4.5min 后再记录一次负载评价标准差,同时记录每次资源动态调度时的Pod 迁移数量。
3.2 性能指标分析
通常衡量资源动态调度性能,主要从负载均衡度和资源消耗两方面考虑。本文通过负载评价标准差和Pod 迁移数量对其进行评价。
(1)负载评价标准差。用Std 标准差衡量集群中所有节点的负载差异:
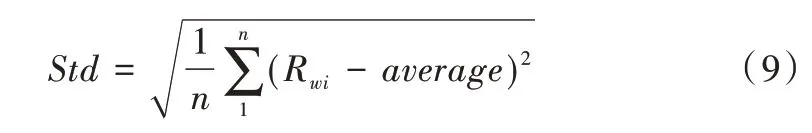
average
为集群的系统平均分,计算公式如下:
std 用来衡量集群中所有节点的负载差异,得分标准差越大,各节点负载差别越大,反之系统更加均衡。
(2)Pod 迁移数量。本文采取CRIU 技术实现Pod 迁移,在内存复制过程中会在源服务器和目标服务器上消耗额外的CPU 资源,还会消耗额外的网络带宽,都会影响集群的资源利用率。Pod 迁移数量越少,集群在资源动态调度时所消耗的资源越少。
3.3 实验结果分析
3 种运行不同资源调度集群的负载评价标准差变化比较如图3 所示。默认的资源动态调度在3、5、7、9 次记录时因调度器集群负载均衡度较好,在第2、4、6、8、10 次采集时,因JMeter 不断请求,节点资源状况发生变化,负载评价标准差大。本文设计的资源动态调度和基于优先级的资源动态调度在前两次采集时因Pod 数量较少,JMeter 的请求可能集中在某个工作节点上而又未能达到动态调度的触发阈值,负载评价标准差较大,随着Pod 数量的增多,触发动态资源调度,在之后的时间里集群负载均衡度较好。系统整体负载评价标准差比基于优先级的资源动态调度低17%,负载均衡度更好,原因是从多维度评估系统负载状况,在资源动态调度时,可以更加精准地实现集群负载均衡。
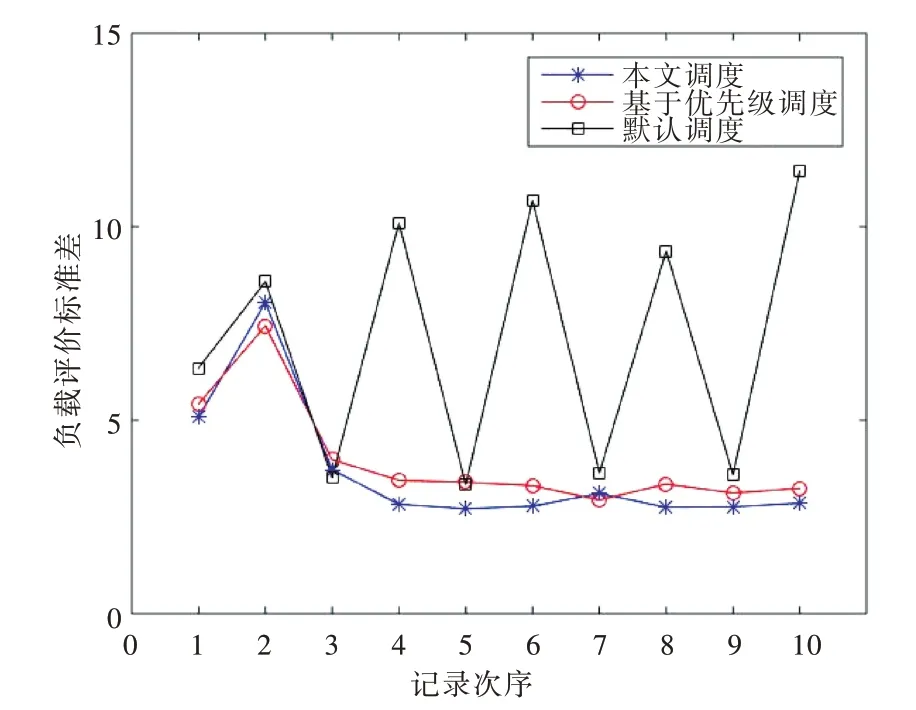
Fig.3 Comparison of changes in load evaluation standard deviation图3 负载评价标准差变化比较
在Pod 迁移数量方面,Kubernetes 默认资源调度Pod 一旦运行就不会发生迁移,采用基于优先级的资源动态调度和本文设计的动态资源调度在实验期间触发了4 次Pod 迁移,其Pod 迁移数量如图4 所示。可以看出,本文设计的动态资源调度迁移Pod 数量相对于优先级资源动态调度平均减少88.3%,降低了系统资源调度时的消耗。由于本文采用滑动窗口根据Pod 的负载状况筛选迁移Pod 集合,在能够实现集群负载均衡的条件下控制Pod 迁移数量。
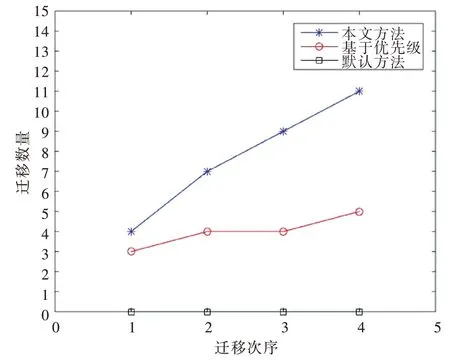
Fig.4 Comparison of changes in the number of Pod migrations图4 Pod 迁移数量变化比较
4 结语
本文在Kubernetes 集群系统上设计了基于Pod 迁移的资源动态调度,实现集群负载均衡。通过监控模块采集各工作节点和Pod 应用的资源信息,使用层次分析法将其转化为比较客观、准确的综合评价结果,在高负载队列中使用滑动窗口筛选出Pod 迁移集合,达到迁移少量Pod 实现资源动态调动的目的。从实验结果可以看出,本文的动态资源调度算法相比与Kubernetes 的默认调度算法更能维护集群的稳定性,相比于基于优先级的资源动态调度所消耗的系统资源更少。考虑到集群上可能运行不同类型的Pod应用,本文将在现有研究基础上,进一步结合资源类型进行深入研究。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
小学生学习指导(低年级)(2020年4期)2020-06-02
数学年刊A辑(中文版)(2019年3期)2019-10-08
军事运筹与系统工程(2019年4期)2019-09-11
军营文化天地(2018年2期)2018-12-15
电子制作(2018年11期)2018-08-04
产品可靠性报告(2017年7期)2017-09-05
中国交通信息化(2017年3期)2017-06-08
中国学术期刊文摘(2016年1期)2016-02-13
